This article was published as a part of the Data Science Blogathon.
Introduction
Apache Flume is a platform for aggregating, collecting, and transporting massive volumes of log data quickly and effectively. It is very reliable and robust. Its design is simple, based on streaming data flows, and written in Java. It features its query processing engine, allowing it to alter each fresh batch of data before sending it to its designated sink. It is designed to be flexible.
The design of Apache Flume is built on streaming data flows, which makes it very simple and easy to use. Apache Flume has several adjustable dependabilities, recovery, and failover features that come to our aid when we need them.
Features of Flume
Apache Flume has many features and lets us have a look at some of the notable and essential elements of Flume:
- Flume efficiently ingests log data from many online sources and web servers into a centralised storage system (HDFS, HBase).
- Flume is also used to ingest massive amounts of event data produced by social networking sites like Facebook and Twitter and e-commerce sites like Amazon and Flipkart and log files.
- Flume can handle many data sources and destinations.
- Flume can handle multi-hop flows, fan-in-fan-out flows, contextual routing, etc.
- The flume may be horizontally scaled.
- We can quickly pull data from many servers into Hadoop using Flume.
Benefits of using Flume
Using Flume has many benefits. Let us have a look at the benefits of using Flume:
- We may store the data in any centralised storage using Apache Flume (HBase, HDFS).
- Flume has a feature called contextual routing.
- Flume transactions are channel-based, with each communication requiring two transactions (one sender and one recipient). It ensures that messages are delivered on time.
- When the incoming data rate exceeds the rate at which it can be written to the destination, Flume works as a middleman between data producers and centralised storage, ensuring a continual flow of data between them.
Apache Flume Architecture
Flume Architecture consists of many elements; let us have a look at them:
- Flume Source
- Flume Channel
- Flume Sink
- Flume Agent
- Flume Event
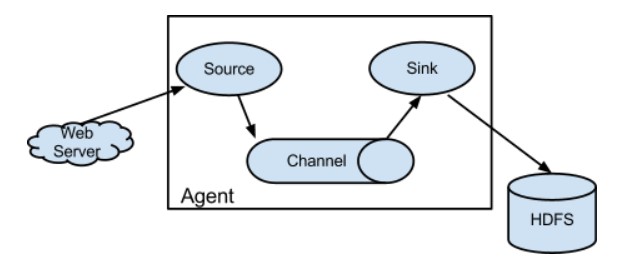
Flume Source
A Flume Source can be found on data producers like Facebook and Twitter. The source gathers data from the generator and sends it to the Flume Channel in the form of Flume Events. Flume supports a variety of sources, including Avro Flume Source, which connects to an Avro port and gets events from an Avro external client, and Thrift Flume Source, which connects to a Thrift port and receives events from Thrift client streams, Spooling Directory Source, and Kafka Flume Source.
Flume Channel
A channel is a transitory storage that receives events from the source and buffers them until sinks consume them. It serves as a link between the authorities and sinks. These channels are entirely transactional and can connect to an unlimited number of sources and sinks.
Flume supports the File channel as well as the Memory channel. The file channel is persistent, which means that once data is written to it, it will not be lost even if the agent restarts. Channel events are saved in memory, and therefore, it is not long-lasting but highly rapid.
Flume Sink
Data repositories such as HDFS and HBase include a Flume Sink. The Flume sink consumes events from Channel and saves them in HDFS or other destination storage. There is no need for a sink to give possibilities to Store; alternatively, we may set it up so that it can deliver events to another agent. Flume works with various sinks, including HDFS Sink, Hive Sink, Thrift Sink, and Avro Sink.
Flume Agent
In Flume, an agent is a daemon process that runs independently. It accepts data (events) from customers or other agents and routes it to the appropriate destination (sink or agent). Flume may contain many agents.
Flume Event
Event is the most straightforward unit of data transferred in Flume. It has a byte array payload that must be delivered from the source to the destination and optional headers.
In its most simple form, a Flume agent is a Java process comprising Source – Channel – Sink. Data is collected from the data generator in the form of Events and then delivered to the Channel. As needed, a Source can supply several Channels. The technique of a single source writing to several channels so that they can provide multiple sinks is known as fan-out.
In Flume, an Event is a unit of data transmission. Channel buffers the data until the Sink absorbs it. Sink collects data from Channel and sends it to a centralised data storage system such as HDFS, or Sink might transfer events to another Flume agent depending on the situation.
Flume supports transactions. Flume achieves reliability by using separate transactions from the source to the channel and the channel to the sink. The transaction is rolled back and later redelivered if events are not delivered.
Data Flow
Flume is a platform for transferring log data into HDFS. Usually, the log server creates events and log data, and these servers have Flume agents running on them. The data generators provide the data to these agents.
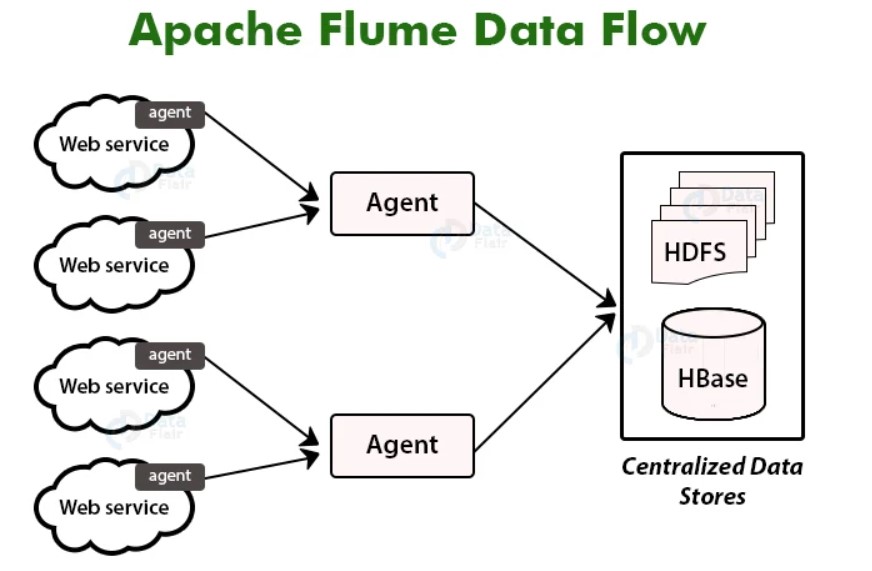
The collector, an intermediary node, will gather the data in these agents. In Flume, there may be several collectors, just like there can be multiple agents. Finally, all of the data from these collectors will be combined and delivered to a centralised storage system like HBase or HDFS.
Three Types of Data Flows in Apache Flume
1) Multi-hop flow
There can be several agents in a Flume Flow. Before arriving at its final destination, the event (data) may pass through several agents. This is a multi-hop flow.
2) Fan-in flow
Flume allows data from various sources to be exchanged over a single channel. Fan-in flow is the term for this type of flow.
3) Fan-out flow
Data moves from a single source to several channels in a fan-out flow. Fan-out flow may be done in two ways. They’re multiplexing and reproducing.
Relevance of Apache Flume
Flume is very useful, and there are many reasons to use Flume. Let us check some of them:
The data loading in Apache Flume is entirely event-driven; this is a significant advantage.
Apache Flume is the best option for transporting large amounts of streaming data from sources such as JMS or Spooling folders.
The events are staged in a channel on each agent, and the possibilities are subsequently transmitted to the following agent in the flow or a final data storage(such as HDFS). When the events have been saved in the next agent’s channel or the data storage server, they are deleted from the channel. This diagram shows how Flume’s single-hop message delivery semantics ensure the flow’s end-to-end dependability.
Flume employs a method based on transactions to ensure that events are correctly delivered. The sources and sinks encapsulate the storing and retrieval of events stored in or given by a transaction provided by the channel in marketing. This makes sure that the sequence of events is appropriately transmitted from a specific point in the flow to the next. In the event of a multi-hop flow, the earlier hop’s sink and the next hop’s source both have transactions going to verify that the data is safely placed in the following hop’s channel.
The events are staged in the channel, which controls failure recovery. Flume includes a durable file channel supported by the local file system. A memory channel saves events in an in-memory queue, which is faster, but the events that stay in the memory channel after an agent dies cannot be retrieved.
Conclusion on Apache Flume
We had a brief overview of the features of Apache Flume. To sum up:
-
Flume is flexible and works with various sources and sinks, including Kafka, Avro, spooling directories, Thrift, and others.
- In Flume, a single source may transmit data to several channels, subsequently sending the data to many sinks, allowing a single reference to send and transfer data to multiple sinks. Fan-out is the name of this process, and Flume allows the fan-out of data.
- Flume maintains a consistent flow of data transmission, which means that the data writing speed will also increase with the data reading speed.
- Although Flume usually publishes data to centralised storage like HDFS or Hbase, we may configure Flume to post data to another agent if necessary. This highlights the flexible nature of Apache Flume.
- Flume is a free and open-source project.
Flume is a highly adaptive, reliable, and scalable platform for sending data to a centralised storage system like HDFS. Its ability to interact with various applications like Kafka, Hdfs, and Thrift makes it a viable solution for data intake.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Prateek is a dynamic professional with a strong foundation in Artificial Intelligence and Data Science, currently pursuing his PGP at Jio Institute. He holds a Bachelor's degree in Electrical Engineering and has hands-on experience as a System Engineer at TCS Digital, where he excelled in API management and data integration. Prateek also has a background in product marketing and analytics from his time with start-ups like AppleX and Milkie Way, Inc., where he was involved in growth campaigns and technical blog management. Recognized for his structured thinking and problem-solving abilities, he has received accolades like the Dr. Sudarshan Chakraborty Award for Best Student Performance. Fluent in multiple languages and passionate about technology, Prateek continues to expand his expertise in the rapidly evolving AI and tech landscape.





