This article was published as a part of the Data Science Blogathon.
Introduction to Hypothesis Testing
Every day we find ourselves testing new ideas, finding the fastest route to the office, the quickest way to finish our work, or simply finding a better way to do something we love. The critical question, then, is whether our idea is significantly better than what we tried previously.
These ideas that we come up with on such a regular basis – that’s essentially what a hypothesis is. And testing these ideas to figure out which one works and which one is best left behind, is called hypothesis testing.

The article is structured in a manner that you will get examples in each section. You’ll get to learn all about hypothesis testing, p-value, Z test, t-test and much more.
Fundamentals of Hypothesis Testing

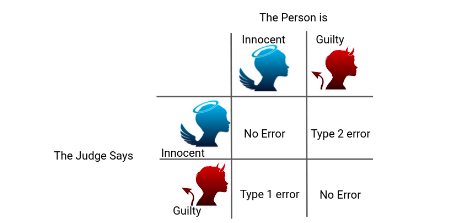
Let’s take an example to understand the concept of Hypothesis Testing. A person is on trial for a criminal offence and the judge needs to provide a verdict on his case. Now, there are four possible combinations in such a case:
- First Case: The person is innocent and the judge identifies the person as innocent
- Second Case: The person is innocent and the judge identifies the person as guilty
- Third Case: The person is guilty and the judge identifies the person as innocent
- Fourth Case: The person is guilty and the judge identifies the person as guilty
Source:- https://courses.analyticsvidhya.com/courses/
As you can clearly see, there can be two types of error in the judgment – Type 1 error, when the verdict is against the person while he was innocent and Type 2 error, when the verdict is in favour of the Person while he was guilty.
According to the Presumption of Innocence, the person is considered innocent until proven guilty. That means the judge must find the evidence which convinces him “beyond a reasonable doubt”. This phenomenon of “Beyond a reasonable doubt” can be understood as Probability (Judge Decided Guilty | Person is Innocent) should be small.
The basic concepts of Hypothesis Testing are actually quite analogous to this situation.
We consider the Null Hypothesis to be true until we find strong evidence against it. Then, we accept the Alternate Hypothesis. We also determine the Significance Level (⍺ ) which can be understood as the Probability of (Judge Decided Guilty | Person is Innocent) in the previous example. Thus, if ⍺ is smaller, it will require more evidence to reject the Null Hypothesis. Don’t worry, we’ll cover all of this using a case study later.

Source:- https://courses.analyticsvidhya.com/courses/
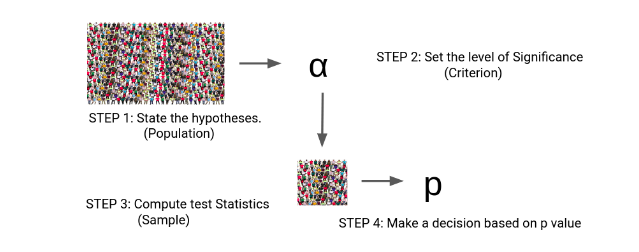
Steps to Perform for Hypothesis Testing
There are four steps to performing Hypothesis Testing:
- Set the Hypothesis
- Compute the test statistics
- Make a decision
Source:- https://courses.analyticsvidhya.com/courses/
1. Set up Hypothesis (NULL and Alternate): Let us take the courtroom discussion further. The defendant is assumed to be innocent (i.e. innocent until proven guilty) and the burden is on a prosecutor to conduct a trial to show evidence that the defendant is not innocent. This is the Null Hypothesis.
Keep in mind that, the only reason we are testing the null hypothesis is that we think it is wrong. We state what we think is wrong about the null hypothesis in an Alternative Hypothesis.
In the courtroom example, the alternate hypothesis can be – the defendant is not guilty. The symbol for the alternative hypothesis is ‘H1’.
2. Set the level of Significance – To set the criteria for a decision, we state the level of significance for a test. It could 5%, 1% or 0.5%. Based on the level of significance, we make a decision to accept the Null or Alternate hypothesis.
Don’t worry if you didn’t understand this concept, we will be discussing it in the next section.
3. Computing Test Statistic – Test statistic helps to determine the likelihood. A higher probability has a higher likelihood and enough evidence to accept the Null hypothesis.
We’ll be looking into this step in later lessons.
4. Make a decision based on p-value – But What does this p-value indicate?
We can understand this p-value as the measurement of the Defense Attorney’s argument. If the p-value is less than ⍺ , we reject the Null Hypothesis or if the p-value is greater than ⍺, we fail to reject the Null Hypothesis.
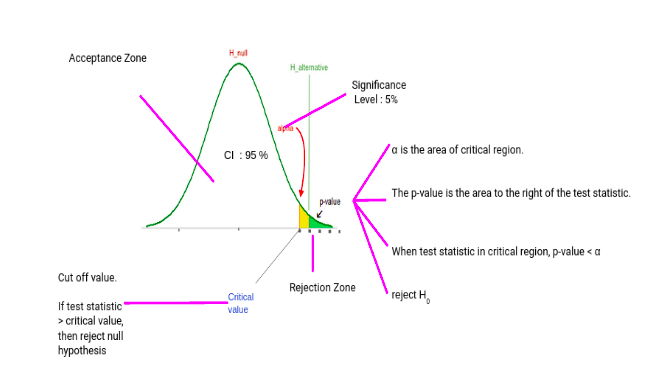
Critical Value (p-value)
We will understand the logic of Hypothesis Testing with the graphical representation for Normal Distribution.
Typically, we set the Significance level at 10%, 5%, or 1%. If our test score lies in the Acceptance Zone we fail to reject the Null Hypothesis. If our test score lies in the critical zone, we reject the Null Hypothesis and accept the Alternate Hypothesis.
Critical Value is the cut off value between Acceptance Zone and Rejection Zone. We compare our test score to the critical value and if the test score is greater than the critical value, that means our test score lies in the Rejection Zone and we reject the Null Hypothesis. On the opposite side, if the test score is less than the Critical Value, that means the test score lies in the Acceptance Zone and we fail to reject the null Hypothesis.
But why do we need a p-value when we can reject/accept hypotheses based on test scores and critical values?
Source:- https://courses.analyticsvidhya.com/courses/
p-value has the benefit that we only need one value to make a decision about the hypothesis. We don’t need to compute two different values like critical values and test scores. Another benefit of using a p-value is that we can test at any desired level of significance by comparing this directly with the significance level.

Source:- https://courses.analyticsvidhya.com/courses/
This way we don’t need to compute test scores and critical values for each significance level. We can get the p-value and directly compare it with the significance level.
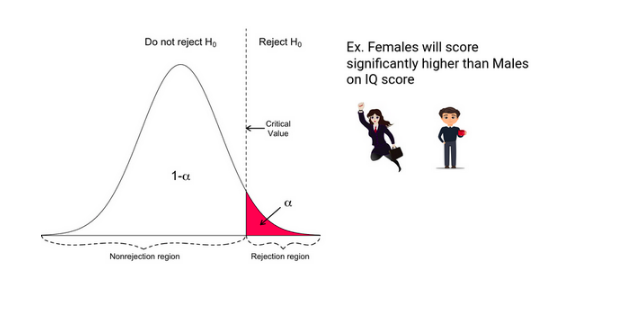
Directional Hypothesis
Great, You made it here! Hypothesis Testing is further divided into two parts –
- Direction Hypothesis
- Non-Direction Hypothesis
In the Directional Hypothesis, the null hypothesis is rejected if the test score is too large (for right-tailed and too small for left tailed). Thus, the rejection region for such a test consists of one part, which is right from the centre.
Source:- https://courses.analyticsvidhya.com/courses/
Non-Directional Hypothesis
In a Non-Directional Hypothesis test, the Null Hypothesis is rejected if the test score is either too small or too large. Thus, the rejection region for such a test consists of two parts: one on the left and one on the right.
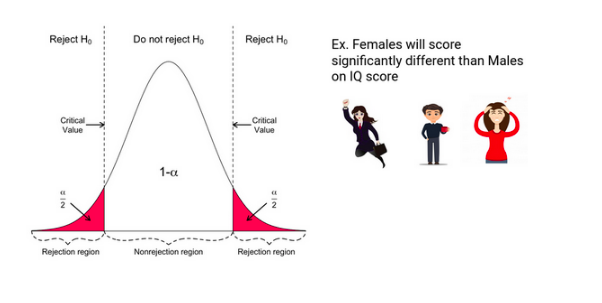
Source:- https://courses.analyticsvidhya.com/courses/
What is Z test?
z tests are a statistical way of testing a hypothesis when either:
- We know the population variance, or
- We do not know the population variance but our sample size is large n ≥ 30
If we have a sample size of less than 30 and do not know the population variance, then we must use a t-test.
One-Sample Z test
We perform the One-Sample Z test when we want to compare a sample mean with the population mean.
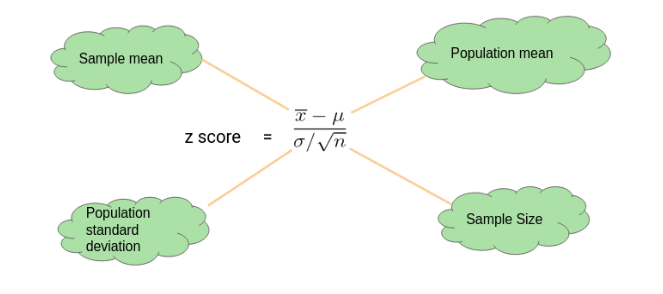
Example:
Let’s say we need to determine if girls on average score higher than 600 in the exam. We have the information that the standard deviation for girls’ scores is 100. So, we collect the data of 20 girls by using random samples and record their marks. Finally, we also set our ⍺ value (significance level) to be 0.05.

In this example:
- The mean Score for Girls is 641
- The size of the sample is 20
- The population mean is 600
- The standard Deviation for the Population is 100

Source:- https://courses.analyticsvidhya.com/courses/
Since the P-value is less than 0.05, we can reject the null hypothesis and conclude based on our result that Girls on average scored higher than 600.
Two- Sample Z Test
We perform a Two-Sample Z test when we want to compare the mean of two samples.
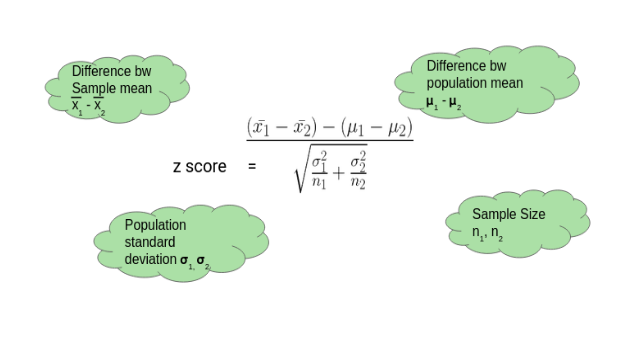
Source:- https://courses.analyticsvidhya.com/courses/
Example:
Here, let’s say we want to know if Girls on average score 10 marks more than the boys. We have the information that the standard deviation for girls’ Scores is 100 and for boys’ scores is 90. Then we collect the data of 20 girls and 20 boys by using random samples and record their marks. Finally, we also set our ⍺ value (significance level) to be 0.05.

Source:- https://courses.analyticsvidhya.com/courses/
In this example:
- The mean Score for Girls (Sample Mean) is 641
- The mean Score for Boys (Sample Mean) is 613.3
- The standard Deviation for the Population of Girls is 100
- The standard deviation for the Population of Boys is 90
- The Sample Size is 20 for both Girls and Boys
- The difference between the Mean Population is 10

Source:- https://courses.analyticsvidhya.com/courses/
Thus, we can conclude based on the P-value that we fail to reject the Null Hypothesis. We don’t have enough evidence to conclude that girls on an average score of 10 marks more than the boys. Pretty simple, right?
What is a T-Test?
In simple words, t-tests are a statistical way of testing a hypothesis when:
- We do not know the population variance
- Our sample size is small, n < 30
One-Sample T-Test
We perform a One-Sample t-test when we want to compare a sample mean with the population mean. The difference from the Z Test is that we do not have the information on Population Variance here. We use the sample standard deviation instead of the population standard deviation in this case.
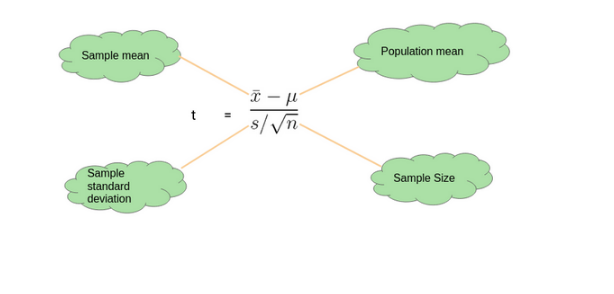
Source:- https://courses.analyticsvidhya.com/courses/
Eaxmple:
Let’s say we want to determine if on average girls score more than 600 in the exam. We do not have the information related to variance (or standard deviation) for girls’ scores. To a perform t-test, we randomly collect the data of 10 girls with their marks and choose our ⍺ value (significance level) to be 0.05 for Hypothesis Testing.

Source:- https://courses.analyticsvidhya.com/courses/
In this example:
- The mean Score for Girls is 606.8
- The size of the sample is 10
- The population mean is 600
- The standard deviation for the sample is 13.14

Source:- https://courses.analyticsvidhya.com/courses/
Our P-value is greater than 0.05 thus we fail to reject the null hypothesis and don’t have enough evidence to support the hypothesis that on average, girls score more than 600 in the exam.
Two-Sample T-Test
We perform a Two-Sample t-test when we want to compare the mean of two samples.
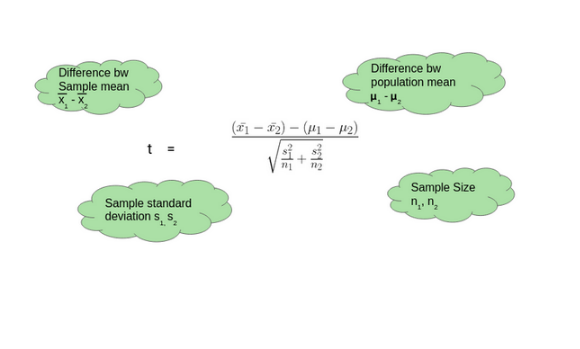
Source:- https://courses.analyticsvidhya.com/courses/
Example:
Here, let’s say we want to determine if on average, boys score 15 marks more than girls in the exam. We do not have the information related to variance (or standard deviation) for girls’ scores or boys’ scores. To perform a t-test. we randomly collect the data of 10 girls and boys with their marks. We choose our ⍺ value (significance level) to be 0.05 as the criteria for Hypothesis Testing.

Source:- https://courses.analyticsvidhya.com/courses/
In this example:
- The mean Score for Boys is 630.1
- The mean Score for Girls is 606.8
- Difference between Population Mean 15
- The standard Deviation for Boys’ scores is 13.42
- The standard Deviation for Girls’ scores is 13.14

Source:- https://courses.analyticsvidhya.com/courses/
Thus, P-value is less than 0.05 so we can reject the null hypothesis and conclude that on average boys score 15 marks more than girls in the exam.
Deciding between Z Test and T-Test
So when we should perform the Z test and when we should perform the t-Test? It’s a key question we need to answer if we want to master statistics.
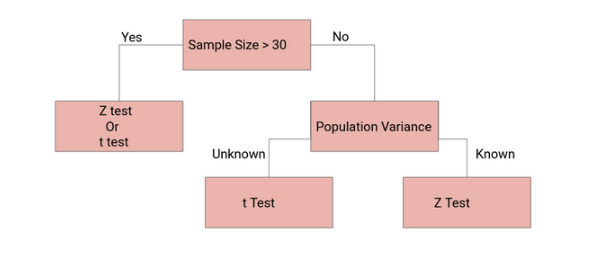
Source:- https://courses.analyticsvidhya.com/courses/
If the sample size is large enough, then the Z test and t-Test will conclude with the same results. For a large sample size Sample Variance will be a better estimate of Population variance so even if population variance is unknown, we can use the Z test using sample variance.
Similarly, for a Large Sample, we have a high degree of freedom. And since t-distribution approaches the normal distribution, the difference between the z score and t score is negligible.
Conclusion
In this article, we learn about a few important techniques to solve the real problem such as:-
- what is hypothesis testing?
- steps to perform for hypothesis testing
- p-value
- directional hypothesis
- Non- directional hypothesis
- what is Z-test?
- One-sample Z-test with example
- Two-sample Z-test with example
- what is a t-test?
- One-sample t-test with example
- Two-sample t-test with example
If you want to read my previous blogs, you can read Previous Data Science Blog posts from here.
Thanks for reading! I hope that you have enjoyed the article. If you like it, share it with your friends also. Please feel free to comment if you have any thoughts that can improve my article writing.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hi, I am Kajal Kumari. have completed my Master’s from IIT(ISM) Dhanbad in Computer Science & Engineering. As of now, I am working as Machine Learning Engineer in Hyderabad.
hope that you have enjoyed the article. If you like it, share it with your friends also. Please feel free to comment if you have any thoughts that can improve my article writing.
If you want to read my previous blogs, you can read Previous Data Science Blog posts here. Connect with me





