This article was published as a part of the Data Science Blogathon.
Introduction to Pandas
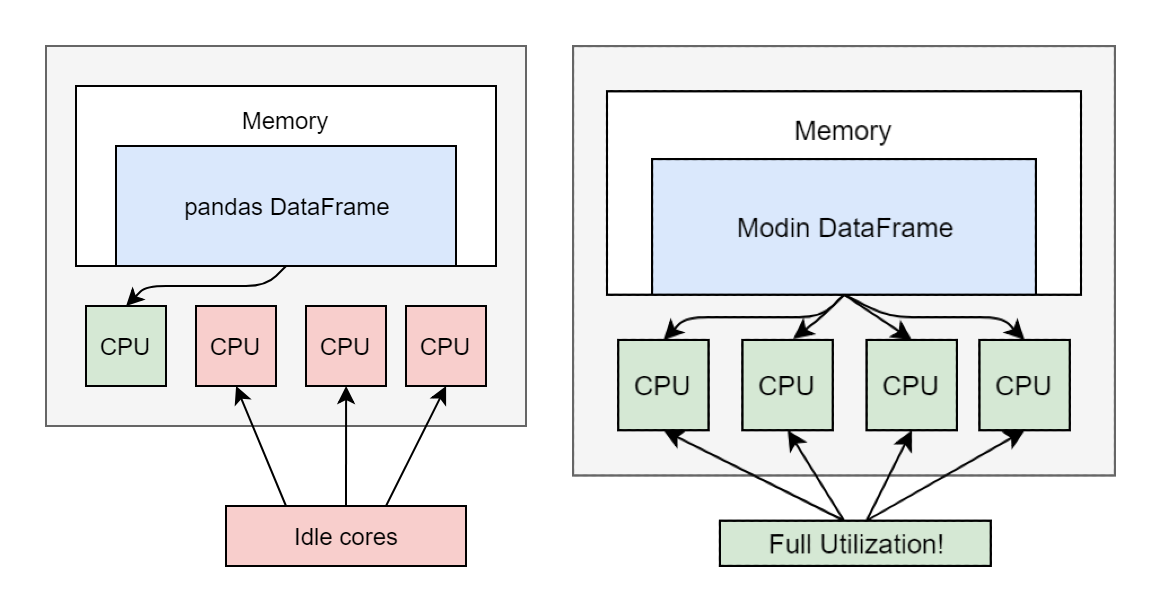
Pandas is a python library that needs no introduction. Pandas provide an easier way to do preprocessing and analysis on our data. However, if we are working on a larger data, pandas takes too much time for data preprocessing. The primary reason for the slowdown is pandas can’t run the program parallelly, and it only uses one CPU core for running the program. We have to shift to distributed computing platforms like Spark for working on large data. But maintaining distributed computing platforms is quite difficult as it involves understanding of it’s computational paradigms and inner workings of the platform.
Moreover, a steep learning curve is required to use distributed computing platforms, and it is challenging for beginners to use them. This is where the Modin comes from. It makes your Pandas code run parallelly by changing just one line of code.
Modin is an open source library developed by UC Berkeley’s RISELab to speed up the computation by distributive computing. Modin uses Ray/Dask libraries in backend to parallelize the code and also we don’t need any distributive computing knowledge to use Modin. Modin Dataframe has a similar API to Pandas. So all we are to do is to continue using Pandas API as was before. Modin provides the speedup of upto 4x on 4 core laptop. Modin can be used for dataset size ranging from 1MB to 1TB.
Installation
Modin can be installed through the pip command and it uses Ray/Dask library as the backend. Modin will automatically detect the ray/dask engine in our computer. In case if Ray/Dask library is not preinstalled on your computer, Modin can be installed with its dependencies by the below commands.
pip install "modin[ray]" # Install Modin dependencies and Ray to run on Ray
pip install "modin[dask]" # Install Modin dependencies and Dask to run on Dask
pip install "modin[all]" # Install all of the above
Modin Architecture
The high-level architecture diagram of Modin can be given below

Currently, we can use Modin with pandas API. SQLite API is in experimental mode with Modin. In the future Modin, developers are planning to come up with separate APIs for Modin but nothing such is developed yet. The Query Compiler layer which is beneath the API layer will compose the query and perform some optimizations based on the format of the data.
Modin will run with Ray/Dask as its backend. We can also make Modin work with our own backend library since it is an open-source library and also even though we can run Modin directly with python without the backend it won’t serve our purpose as Modin can’t run code in a parallel fashion on its own.
Modin Dataframe Architecture
The Modin Dataframe is partitioned along both rows and columns and each partition is a separate pandas dataframe.
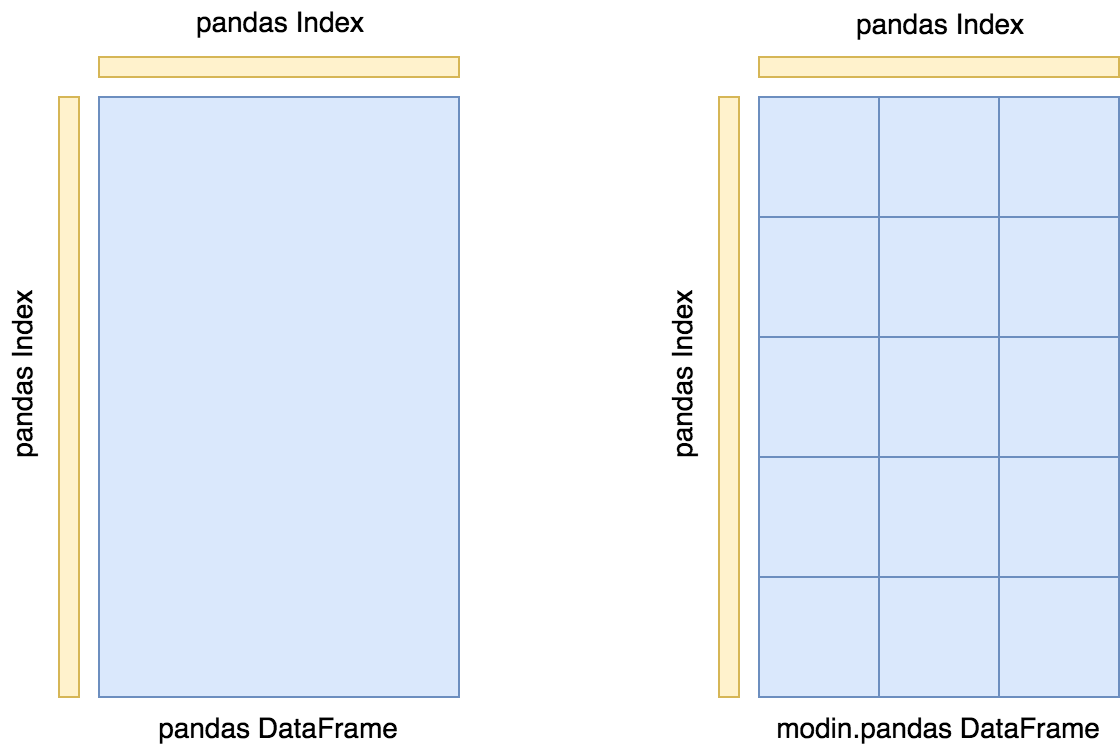
We can change the default partitions in modin by using the repartition() method.
Implementation
We can replace pandas with modin with just one line of code
import modin.pandas as pd
Modin vs Pandas Comparision pd.read_csv()
import modin.pandas as pd import time start_time=time.time() data_modin=pd.read_csv("../input/uwmgi-mask-dataset/train.csv") end_time=time.time() duration=end_time-start_time print("Time taken to run the code "+str(duration))
Time taken to run the code 0.4164540767669678
import pandas import time start_time=time.time() data_pandas=pandas.read_csv("../input/uwmgi-mask-dataset/train.csv") end_time=time.time() duration=end_time-start_time print("Time taken to run the code "+str(duration))
Time taken to run the code 0.6549224853515625
df.fillna()
%%time data_modin.fillna(0)
CPU times: user 7.68 ms, sys: 5.06 ms, total: 12.7 ms Wall time: 10.9 ms
%%time data_pandas.fillna(0) CPU times: user 59.2 ms, sys: 5.38 ms, total: 64.6 ms Wall time: 62.3 ms
Limitations
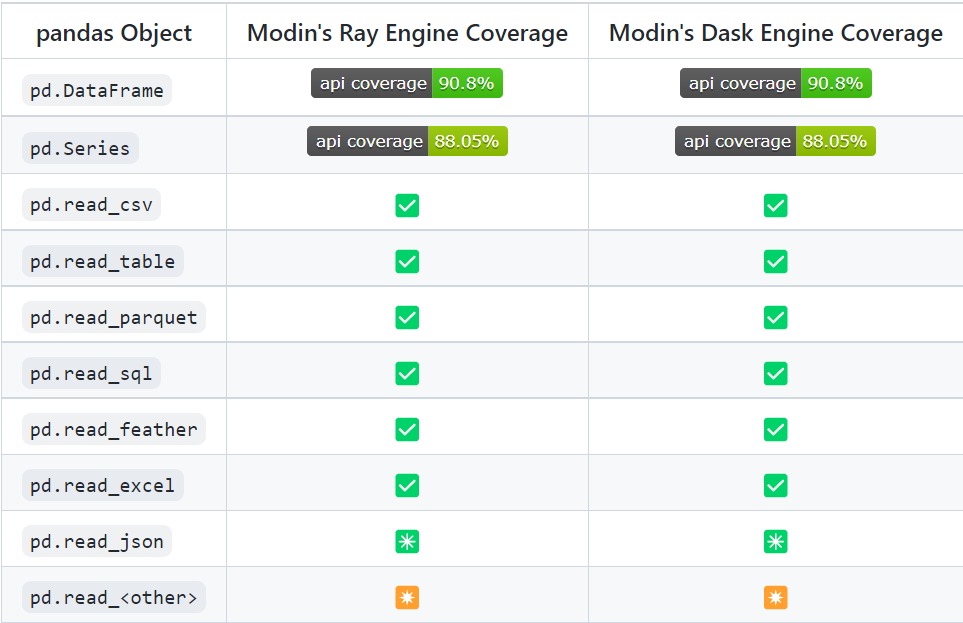
Pandas is a heavy library with a wide collection of APIs. Even though Modin supports popular APIs of Pandas it won’t support all the APIs of Pandas.
 For the functions that are not implemented in Modin, they automatically default to pandas. So for the functions that are not implemented in pandas and for user-defined functions(apply functions in pandas), Modin will convert the Modin DataFrame to Pandas DataFrame and then apply those functions. There will be some performance penalty for converting to Pandas Dataframe.
For the functions that are not implemented in Modin, they automatically default to pandas. So for the functions that are not implemented in pandas and for user-defined functions(apply functions in pandas), Modin will convert the Modin DataFrame to Pandas DataFrame and then apply those functions. There will be some performance penalty for converting to Pandas Dataframe.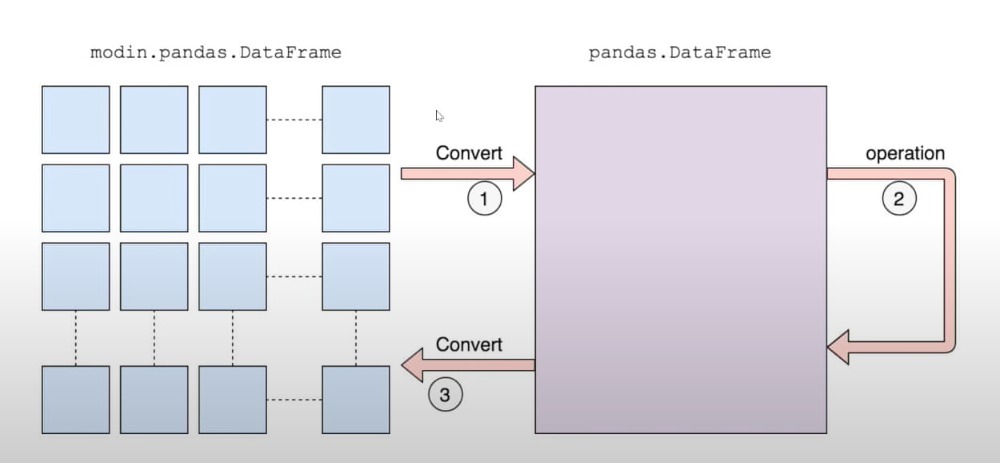
Comparison to Other Libraries
Dask, Vaex, Ray, Cudf and Koalas are some of the popular alternatives to Modin.
Libraries like Dask and Koalas try to resolve the performance issue for large datasets in their own ways but it won’t preserve the Pandas API behaviour and we have to make significant changes to our panda’s code to make it run on dask/Koalas. Also, Dask/Koalas support only row partitioning whereas Modin supports row, column and cell partitioning of dataframe which helps Modin to support a wide variety of Pandas API. Due to the control over partitioning Modin supports pandas’ methods like transpose(). quantile(), and median() which are difficult to apply in the row-based partition of data.
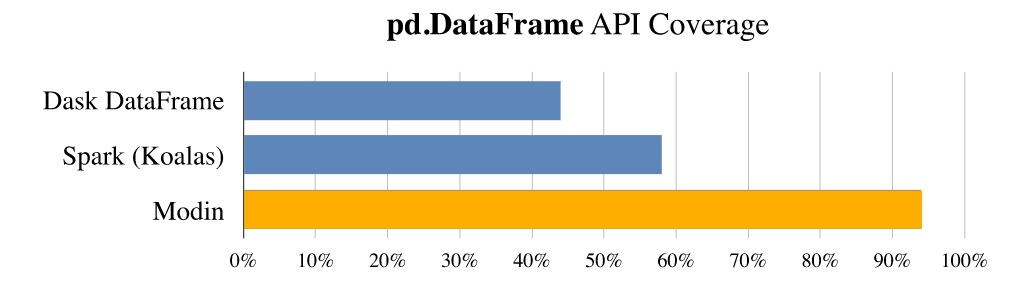
Similarly, libraries like Vaex are designed for data visualization for large datasets but not as a replacement for pandas. So, it’s better to give a try for Vaex for data visualization but for ease of adoption and performance, Modin beats the Vaex library. Also, we can’t compare the libraries like Ray/Cudf with Modin. Ray/Cudf don’t provide any high-level pandas API. Ray/Cudf can be used as the backend support for Modin for optimal performance with fewer code changes.
Also, Dask/Ray uses lazy evaluation which executes the code only when the user explicitly evaluates the result. Even though lazy evaluation decreases time complexity, sometimes it increases space complexity. Unlike Dask/Ray, Modin by default doesn’t execute lazy evaluation. But Modin also supports lazy evaluation with the Omnisci engine.
Conclusion on Pandas Code
Modin is still in its early stages of development. Developers are planning to bring more features into it.
Modin’s core motto is to make users use the same tools for small and large datasets without changing the APIs. In the future developers are planning to integrate Modin with Pyarrow, Sqlite and various other libraries. The key takeaways of the article are
- We understood why pandas are not ideal for large data and how the Modin helps us in dealing with large data.
- We understood the architecture of the Modin.
- We learned how to implement Modin in python.
- We have gone through the limitations of Modin.
- Finally, we compared Modin with its alternatives and discussed its inherent strengths of Modin when compared to its alternatives.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
My name is Uday Kiran, and I am a data engineer with one year of experience. I am a proud graduate of the prestigious Indian Institute of Technology (IIT) Madras, where I earned my Bachelor's degree in Eectrical Engineering.
Throughout my academic and professional career, I have always been passionate about using technology to solve complex problems and improve processes. As a data engineer, I am responsible for designing, implementing, and maintaining data systems and databases that are critical to the success of businesses and organizations. I have experience working with a range of data technologies, including SQL, Python, Hadoop, and Spark, and I am always looking to expand my knowledge and skills in this field.
In addition to my technical expertise, I am a collaborative team player who is committed to delivering high-quality work and meeting project deadlines. I enjoy working with others to identify and solve problems and find innovative solutions to improve processes and efficiency.
Outside of work, I enjoy staying active and engaged in my community. I am an avid sports fan and enjoy playing cricket and badminton. I also volunteer my time with local organizations that work to improve access to education and healthcare for underserved communities.
Overall, I am a dedicated and passionate data engineer with a strong foundation in computer science and a commitment to continuous learning and growth in my field.



