This article was published as a part of the Data Science Blogathon.
Introduction on SQL
The SQL (Structured Query Language) programming language is used to store, manipulate, and query information that is stored in relational databases. SQL first appeared in 1974 when a group at IBM created a prototype for a relational database. Relational Software (later known as Oracle) released the first commercial relational database.
There are standards for SQL. However, there are different flavors of SQL that can be used on each major RDBMS today. In part, this is due to two factors:
1) the SQL command standard is fairly complex, and it is not practical to implement the entire standard.
2) each database vendor needs a way to differentiate its product.
With the advent of Big Data, SQL has become even more versatile. At first, Big Data technology was geared toward programmers. Eventually, however, Big Data vendors realized they needed to provide a SQL-like layer to enable analysts to query the data set, and they started developing their own versions of SQL.
One of the biggest differences between these types of SQL and SQL that runs on relational databases is the latter does not have the ability to manage data at the row level. It is not possible, for instance, to update an individual row.
This database language is mainly designed for maintaining the data in the relational database management system.
SQL is the standard language for accessing and manipulating databases.
Why You Should Learn SQL? – Advantages
Without training, people view SQL and other coding languages as too difficult to learn. This is one of the reasons employers value SQL-trained workers.
SQL plays a pivotal role in most database management, thus even if an employer isn’t familiar with it, workers can easily explain why it’s important to know it.
In so doing, workers are often able to increase their desirability to employers by developing SQL skills. Here are some of the most common positions that require SQL expertise:
- Back-end developer: This role involves managing the code that ensures that web applications work properly.
- Database administrator: This position ensures that data is stored and managed appropriately.
- Data analyst: Those in this position are responsible for analyzing data for relevant trends to improve the operation of other departments
- Data Scientist: These roles are tasked with handling data in vast amounts.
In Data Science – common tasks that use SQL will be.
- Querying & exploring data to extract useful business insights
- Gathering & aggregating data for business reporting
- Selecting data for a specific treatment, e.g., selecting customers to receive a targeted promotion
- Extracting data for Machine Learning tasks or other predictive modeling
What You Can Do with SQL?
There are lot more things you can do with SQL:
- You can create a database.
- You can create tables in a database.
- You can query or request information from a database.
- You can insert records into a database.
- You can update or modify records in a database.
- You can delete records from the database.
- You can set permissions or access control within the database for data security.
- You can create views to avoid typing frequently used complex queries.
An effective way to think about what we can be using SQL is with the acronym C.R.U.D.

While this might seem like a slightly informal acronym it is actually a really effective way to describe the core functions or operations that can be performed on a relational database…
Let us take a Look!
- CREATE: We can design and create databases and schemas (which almost act as a partition to help organize everything) and of course, we can create tables.
- READ: This is mainly about querying the data, so essentially grabbing the relevant rows and columns from tables that will provide us with the information we need
- UPDATE: We can add more rows & columns to tables that already exist, as well as modify records within tables
- DELETE: This is kind of what you would expect – we can delete specific rows and columns, or we can delete whole tables, schemas, and even databases!
Key Terminologies Used in SQL
- Database: Tables are used to store a specific set of structured data. A table consists of rows, also referred to as records or tuples, and columns also referred to as attributes
- Schema: A schema is a way of organizing the data in a way that grouping of tables and other objects, including views, relations, etc so they can be found by name.
- Tables: The table consists of columns and rows that hold our data. Columns are regarded as ‘attributes’, whereas rows are entries that represent values for said attributes. In a column, all values must be of the same type.
- SQL Index: Indexes are special lookup tables. It is used to retrieve data from the database amazingly fast.
- Clause: By using a clause in SQL, you can customize how your data is queried or how you filter it.
- Aggregate Function: Function is a mathematical computation that returns a single value expressing the importance of the accumulated data from which it is derived
- Windows Function: In a window function, a calculation is made across a set of table rows that have some relationship to the current row. Essentially, this is similar to the type of calculation that can be done with an aggregate function.
- Operators: A unique word or character used to carry out tasks These tasks may range from complex comparisons to simple arithmetic operations. Consider a SQL operator to be analogous to how the various buttons on a calculator work
- Normalization: In the table, normalization eliminates redundancy and enhances data integrity. It also facilitates data organization in the database. The process involves transforming the data into tabular form and removing duplicates from relational tables
- Joins: A JOIN clause is used to join rows from two or more tables based on a common column.
- Subquery: A Subquery is a query within another SQL query and embedded within the WHERE clause.
- Keys: There can be either one column (or attribute) or a group of columns that uniquely identifies rows of tuples within a table
What is a Relational Database?
A relational database consists of logical units called tables, where tables are related to one another within a database. With relational databases, data can be divided into logical, smaller, and more manageable units for easier maintenance and better performance.
In a relational database system, tables are linked through common keys or fields, so if the desired data is in more than one table, you can easily join them together to get a combined data set using a single query.
Normalization in SQL
 Normalization is the process of minimizing redundancy from a relation or set of relations. Redundancy in relation may cause insertion, deletion, and update anomalies. So, it helps to minimize the redundancy in relations. Normal forms are used to eliminate or reduce redundancy in database tables.
Normalization is the process of minimizing redundancy from a relation or set of relations. Redundancy in relation may cause insertion, deletion, and update anomalies. So, it helps to minimize the redundancy in relations. Normal forms are used to eliminate or reduce redundancy in database tables.
Why do We Need Normalization?
The main reason for normalizing the relations is to remove these anomalies. Failure to eliminate anomalies leads to data redundancy and can cause data integrity and other problems as the database grows. Normalization consists of a series of guidelines that helps to guide you in creating a good database structure.
Data Modification Anomalies can be Categorized into three types
Insertion Anomaly: Insertion Anomaly refers to when one cannot insert a new tuple into a relationship due to a lack of data.
Deletion Anomaly: The delete anomaly refers to the situation where the deletion of data results in the unintended loss of some other important data.
Updatation Anomaly: The update anomaly is when an update of a single data value requires multiple rows of data to be updated.
- First Normal Form: If a relation contains a composite or multi-valued attribute, it violates the first normal form, or the relationship is in the first normal form if it does not contain any composite or multi-valued attribute. A relation is in its first normal form if every attribute in that relation is singled valued attribute.
- Second Normal Form: To be in the second normal form, a relation must be in the first normal form and the relation must not contain any partial dependency. A relation is in 2NF if it has No Partial Dependency, i.e., no non-prime attribute (attributes that are not part of any candidate key) is dependent on any proper subset of any candidate key of the table.
Partial Dependency: If the proper subset of candidate keys determines a non-prime attribute, it is called partial dependency.
- Third Normal Form: A relation is in the third normal form if there is no transitive dependency for non-prime attributes as well as it is in the second normal form. A relation is in 3NF if at least one of the following conditions holds in every non-trivial function dependency X –> Y
Note
X is a super key.
Y is a prime attribute (each element of Y is part of some candidate key).
- Boyce-Codd Normal Form (BCNF): A relation R is in BCNF if R is in Third Normal Form and for every FD, LHS is super key. A relation is in BCNF if in every non-trivial functional dependency X –> Y, X is a super key.
- Fourth Normal Form: If no database table instance contains two or more, independent and multivalued data describing the relevant entity, then it is in the 4th Normal Form.
- Fifth Normal Form: A table is in the 5th Normal Form only if it is in 4NF and it cannot be decomposed into any number of smaller tables without loss of data.
- Sixth Normal Form: 6th Normal Form is not standardized, however, it is being discussed by database experts for some time. Hopefully, we would have a clear & standardized definition for the 6th Normal Form in the near future.
Managing Keys for Existing Tables
We can specify our keys after the table has been created if we do not specify them at table creation time. SQL tables support the following key types:
- Primary Key: One or more fields/columns that uniquely identify a record in the table wherein nulls and duplicate values are not permitted.
- Candidate Key: Candidate keys are like sets of non-committed Primary Keys; these keys only accept unique values but cannot be used in place of a Primary Key. In contrast to Primary Keys, there can be more than one Candidate Key per table.
- Alternate Key: This identifies a single Candidate Key (which can fulfill the function of a Primary Key if needed).
- Composite/Compound Key: Combining values from multiple columns, whose sum will always result in a unique value. In one table, multiple Candidate Keys can exist. Each Candidate Key functions as a Primary Key.
- Unique Key: A collection of one or more table fields/columns that uniquely identify a record in a database table. It is similar to the primary key, but it can only accept one null value and cannot have duplicate values.
- Foreign Key: Foreign keys are fields that serve as the primary key for another table. Foreign keys are useful for establishing connections between tables. While a foreign key is required in the parent table where they are primary, foreign keys in tables intended to relate to the other table can be null or empty.
Quick Look into SQL Commands
For communicating with the database, SQL commands are used. By using basic SQL commands, you can do everything from creating a table and adding data to modifying a table and setting user permissions.
Database management systems such as Oracle Database, MySQL, Microsoft SQL Server, PostgreSQL, and MariaDB are some of the most popular options.
There are five types of SQL commands: DDL, DML, DCL, TCL, and DQL.
Data Definition Language
The Data Definition Language is a set of SQL commands that are used to create a database schema. DDL is a set of SQL commands that create, modify, and delete database structures without affecting the data. It deals with descriptions of the database schema and is used to create and modify database objects in the database. In most cases, a general user would not use these commands, rather they would use an application to access the database.
Here are some commands that come under DDL:
CREATE
ALTER
DROP
TRUNCATE
- CREATE: This command creates the database or its objects (such as a table, index, function, view, store procedure, and trigger).
Syntax:
CREATE TABLE TABLE_NAME (COLUMN_NAME DATATYPES[,....]);
Example:
CREATE TABLE STUDENT(Name VARCHAR2(20), Email VARCHAR2(100), DOB DATE);
- ALTER: This command alters the structure of the database. It is used to alter the structure of the database. This change could be either to modify the characteristics of an existing attribute or probably to add a new attribute.
Syntax:
To add a new column in the table
ALTER TABLE table_name ADD column_name COLUMN-definition;
To modify the existing column in the table:
ALTER TABLE table_name MODIFY(column_definitions....);
Example :
ALTER TABLE STUDENT_DETAILS ADD(ADDRESS VARCHAR2(20)); ALTER TABLE STUDENT _DETAILS MODIFY (NAME VARCHAR2(20));
- DROP: This command is used to delete objects in the database. It is used to delete both the structure and record stored in the table.
Syntax
DROP TABLE table_name;
Example
DROP TABLE STUDENT;
- TRUNCATE: This operation removes all records from a table, as well as all the spaces allocated for the records.
Syntax:
TRUNCATE TABLE table_name;
Example:
TRUNCATE TABLE STUDENT;
DML (Data Manipulation Language)
The SQL commands which manipulate the data in the database belong to DML, or Data Manipulation Language, which includes the majority of SQL statements. It is the part of a SQL statement that controls access to data and to the database. They are usually grouped together with DML statements.
Here are some commands that come under DML:
INSERT
DELETE
UPDATE
- INSERT: This is a method of inserting data into the row of a table.
Syntax:
INSERT INTO TABLE_NAME (col1, col2, col3,.... col N) VALUES (value1, value2, value3, .... valueN);
Or
INSERT INTO TABLE_NAME VALUES (value1, value2, value3, .... valueN);
Example:
INSERT INTO SQLJOINT (Author, Subject) VALUES ("Roger", "DBMS");
- DELETE: This method is used to delete one or more rows from a table from a database table.
Syntax:
DELETE FROM table_name [WHERE condition];
Example:
DELETE FROM SQLJOINT WHERE Author=" Roger ";
- UPDATE: This function is used to update or modify the value of a column in the existing data within a table
Syntax:
UPDATE table_name SET [column_name1= value1,...column_nameN = valueN] [WHERE CONDITION]
Example:
UPDATE employee SET User_Name = ' Roger ' WHERE Emp_Id = '5'
DCL (Data Control Language)
Data control language, DCL, is a way to manage data that is stored on databases. It includes commands such as GRANT and REVOKE which mainly deal with the rights, permissions, and other controls of the data.
DCL can be used to grant or revoke access to tables in a database from any database user. The grant command gives users or groups access to specific tables while the revoke command takes away their permissions.
Here are some commands that come under DCL:
Grant
Revoke
- GRANT: Command is used when you want someone else (or some group) to have access to your data in a database
Example
GRANT SELECT, UPDATE ON MY_TABLE TO SOME_USER, ANOTHER_USER;
- REVOKE: Command is used when you want someone else (or some group) not to have access any longer
Example
REVOKE SELECT, UPDATE ON MY_TABLE FROM USER1, USER2;
TCL (Transaction Control Language)
TCL commands can only use with DML commands like INSERT, DELETE and UPDATE only.
These operations are automatically committed in the database that’s why they cannot be used while creating tables or dropping them.
Commands that come under TCL:
- Commit: Command is used to save all the transactions to the database.
Syntax:
COMMIT;
Example:
DELETE FROM USERS WHERE AGE = 22; COMMIT;
- Rollback: Command is used to undo transactions that have not already been saved to the database.
Syntax:
ROLLBACK;
Example:
DELETE FROM USERS WHERE AGE = 22; ROLLBACK;
- SAVEPOINT: It is used to roll the transaction back to a certain point without rolling back the entire transaction.
Syntax:
SAVEPOINT SAVEPOINT_NAME;
DQL (Data Query Language)
DQL is used to fetch the data from the database.
It uses only one command:
SELECT
- SELECT: This is the same as the projection operation of relational algebra. It is used to select the attribute based on the condition described by the WHERE clause.
Syntax:
SELECT expressions FROM TABLES WHERE conditions;
Example:
SELECT emp_name FROM employee WHERE age > 20;
Types of SQL Clauses
- GROUP BY: The SQL GROUP BY statement is used to group identical data into groups. With the SQL SELECT statement, the GROUP BY statement is used. In a SELECT statement, the GROUP BY clause follows the WHERE clause and precedes the ORDER BY clause. Aggregation is performed with the GROUP BY statement.
Syntax :
SELECT column
FROM table_name
WHERE conditions
GROUP BY column
ORDER BY column
- HAVING: The
Having clause specifies a search condition for a group or aggregate. Having is
used in a GROUP BY clause. Using the HAVING function instead of the GROUP BY clause is
like using a WHERE clause
Syntax:
SELECT column1, column2 FROM table_name WHERE conditions GROUP BY column1, column2 HAVING conditions ORDER BY column1, column2;
- ORDER BY: In the ORDER BY clause, the result set is sorted ascending or descending. Records are sorted by default in ascending order. The DESC keyword is used to sort the records in descending order.
Syntax:
SELECT column1, column2 FROM table_name WHERE condition ORDER BY column1, column2... ASC|DESC;
Where:
ASC: It is used to sort the result set in ascending order by expression.
DESC: It sorts the result set in descending order by expression.
Types of SQL Aggregate Function

- AVG Function: The AVG function is used to calculate the average value of the numeric type. AVG function returns the average of all non-Null values.
Syntax :
AVG() or AVG( [ALL|DISTINCT] expression )
- MIN Function: MIN function is used to find the minimum value of a certain column. This function determines the smallest value of all selected values of a column.
Syntax :
MIN() or MIN( [ALL|DISTINCT] expression )
- MAX Function: MAX function is used to find the maximum value of a certain column. This function determines the largest value of all selected values of a column.
Syntax :
MAX() or MAX( [ALL|DISTINCT] expression )
- SUM Function: The sum function is used to calculate the sum of all selected columns. It works on numeric fields only.
Syntax :
SUM() or SUM( [ALL|DISTINCT] expression )
- Count Function: The count function is used to count the number of rows in a database table. It can work on both numeric and non-numeric data types. It uses the COUNT(*) that returns the count of all the rows in a specified table. COUNT(*) considers duplicate and Null.
Syntax :
COUNT(*) or COUNT( [ALL|DISTINCT] expression )
Types of SQL Windows Function
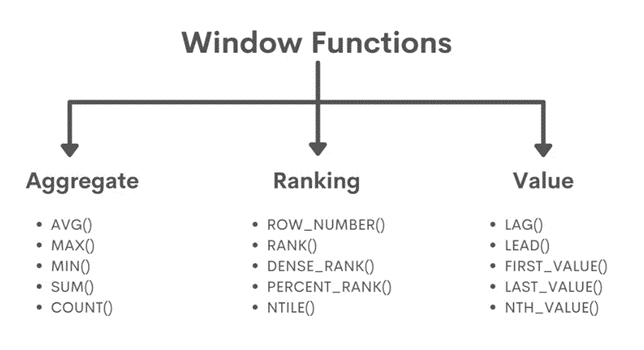
Window functions apply to aggregate and ranking functions over a particular window (set of rows). OVER clause is used with window functions to define that window. OVER clause does two things :
- Partitions rows into form set of rows. (PARTITION BY clause is used)
- Orders rows within those partitions into a particular order. (ORDER BY clause is used)
Note :
If partitions are not done, then ORDER BY orders all rows of the table.
Syntax :
SELECT coulmn_name1,
window_function(cloumn_name2),
OVER([PARTITION BY column_name1] [ORDER BY column_name3]) AS new_column
FROM table_name;
window_function= any aggregate or ranking function
column_name1= column to be selected
coulmn_name2= column on which window function is to be applied
column_name3= column on whose basis partition of rows is to be done
new_column= Name of new column
table_name= Name of table
- Aggregate Window Function : Various aggregate functions such as SUM(), COUNT(), AVERAGE(), MAX(), MIN() applied over a particular window (set of rows) are called aggregate window functions.
Example :
Find the average salary of employees for each department and order employees within a department by age.
SELECT Name, Age, Department, Salary,
AVERAGE(Salary) OVER( PARTITION BY Department ORDER BY Age) AS Avg_Salary
FROM employee
- Ranking Window Functions : Ranking functions are, RANK(), DENSE_RANK(), ROW_NUMBER()
RANK(): As the name suggests, the rank function assigns a rank to all the rows within every partition. Rank is assigned such that rank 1 is given to the first row and rows having the same value are assigned the same rank. For the next rank after two same rank values, one rank value will be skipped.
DENSE_RANK(): It assigns a rank to each row within a partition. Just like the rank function first row is assigned rank 1 and rows having the same value have the same rank. The difference between RANK() and DENSE_RANK() is that in DENSE_RANK(), for the next rank after two same ranks, the consecutive integer is used, and no rank is skipped.
ROW_NUMBER(): It assigns consecutive integers to all the rows within a partition. Within a partition, no two rows can have the same row number.
Note :
ORDER BY() should be specified compulsorily while using rank window functions.
Values Window Functions :
- LAG: Provide access to a row at a given physical offset that comes before the current row.
- LEAD: Provide access to a row at a given physical offset that follows the current row.
- FIRST_VALUE: Get the value of the first row in an ordered partition of a result set.
- LAST_VALUE: Get the value of the last row in an ordered partition of a result set.
- NTILE: Distribute rows of an ordered partition into a number of groups or buckets
Types of SQL Joins
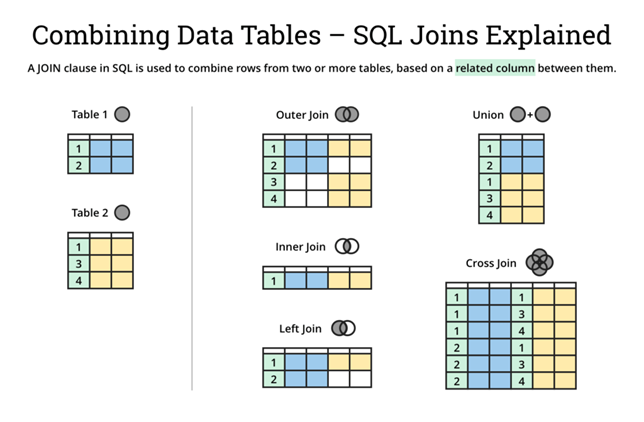
A SQL Join is used to fetch or combine data (rows or columns) from two or more tables based on the defined conditions
- INNER JOIN: The INNER JOIN keyword selects all rows from both the tables as long as the condition is satisfied. This keyword will create the result-set by combining all rows from both the tables where the condition satisfies i.e., the value of the common field will be the same.
Syntax :
SELECT table1.column1,table1.column2,table2.column1,.... FROM table1 INNER JOIN table2 ON table1.matching_column = table2.matching_column;
table1: First table.
table2: Second table
matching_column: Column common to both the tables.
Note: We can also write JOIN instead of INNER JOIN. JOIN is the same as INNER JOIN.
- LEFT JOIN: This join returns all the rows of the table on the left side of the join and matches rows for the table on the right side of the join. For the rows for which there is no matching row on the right side, the result-set will contain null. LEFT JOIN is also known as LEFT OUTER JOIN.
Syntax :
SELECT table1.column1,table1.column2,table2.column1,.... FROM table1 LEFT JOIN table2 ON table1.matching_column = table2.matching_column;
table1: First table.
table2: Second table
matching_column: Column common to both the tables.
Note: We can also use LEFT OUTER JOIN instead of LEFT JOIN, both are the same.
- RIGHT JOIN: RIGHT JOIN is similar to LEFT JOIN. This join returns all the rows of the table on the right side of the join and matching rows for the table on the left side of the join. For the rows for which there is no matching row on the left side, the result-set will contain null. RIGHT JOIN is also known as RIGHT OUTER JOIN
Syntax :
SELECT table1.column1,table1.column2,table2.column1,.... FROM table1 RIGHT JOIN table2 ON table1.matching_column = table2.matching_column;
table1: First table.
table2: Second table
matching_column: Column common to both the tables.
Note:
We can also use RIGHT OUTER JOIN instead of RIGHT JOIN, both are the same
- FULL JOIN: FULL JOIN creates the result-set by combining results of both LEFT JOIN and RIGHT JOIN. The result-set will contain all the rows from both the tables. The rows for which there is no matching, the result-set will contain NULL values
Syntax :
SELECT table1.column1,table1.column2,table2.column1,....
FROM table1
FULL JOIN table2
ON table1.matching_column = table2.matching_column;
table1: First table.
table2: Second table
matching_column: Column common to both the tables.
CROSS JOIN: It is also known as CARTESIAN JOIN, which returns the Cartesian product of two or more joined tables. The CROSS JOIN produces a table that merges each row from the first table with each second table row. It is not required to include any condition in CROSS JOIN.
Syntax:
Select * from table_1 cross join table_2; Or, Select column1, column2, column3 FROM table_1, table_2;
- SELF JOIN: It is a SELF JOIN used to create a table by joining itself as there were two tables. It makes the temporary naming of at least one table in an SQL statement.
Syntax:
Select column1, column2, column(s) FROM table_1 Tbl1, table_2 Tbl2 WHERE condition;
Conclusion
The article discusses the importance of SQL in data analysis. A brief explanation of SQL and how it facilitates the analysis of data in business processes is provided.
SQL is used in every data-driven sector, emphasizing the importance of big data processing.
Data scientists, Data analysts, and developers must access data from databases, so SQL has become a regular part of any data-driven enterprise.
Key Takeaways!
Databases are managed using SQL. Data analysts use SQL to query tables of data and gain insights. Similarly, data scientists use SQL to load data into models. Using SQL, data engineers and database administrators can ensure that everybody in their organization has easy and intuitive access to their data.
Almost every website has a SQL backend, which stores everything from user details to engagement across a particular app.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
||📊Lead Technical Analyst at HP||Connecting data to dollar||📋Certified - Data Scientist||SAP ERP||Microsoft Data Analyst,LSS Yellow Belt||🥇3*MVP,1*APAC Champion@HP||🏆Blogathon Winner’22@Xebia,2*AVCC||AVCC Member’22||





