This article was published as a part of the Data Science Blogathon.
Introduction on Preprocessing
Preprocessing is an essential step in machine learning. We underestimate preprocessing but in reality, choosing the right preprocessing for our data is equally important as choosing the right model, if not more. Most of the time we go with some random preprocessing and don’t change it much as it requires a lot of changes in the code. To solve this, we need to make preprocessing organized so that it becomes easier to experiment with different preprocessing.

In this article, I will be implementing preprocessing functions for – Cleaning Data, Encoding Data, Normalizing Data, Train-Val-Test Split, and Performing Preprocessing for the Cars93 Dataset using Pandas Dataframe. After the end of this Article, we will be able to preprocess our data in just four lines in an organized and simple manner. (Jump to Summary to get an Overview)
Objectives
To Make Universal Functions
We want our functions to work for all datasets by passing a pandas dataframe as an input to our function instead of manually having to change the code for each dataframe. Not even once, in any of the functions, we will use anything specific to the dataset we have taken as an example.
To Make a Single Function for Each Preprocessing Task
For each task (cleaning, encoding, normalizing, splitting) we want to make a combined function where we can do the task by just using that single function and playing with the arguments we pass into the function.
To Make Preprocessing as Simple and Flexible as Possible
We want our main function to make it possible to preprocess the data the way we want without having to change anything in the code. We will do this with a smart choice of arguments.
To Make Experimenting with Different Preprocessing Very Easy
Since preprocessing our data will become simple with our functions, we will not feel lazy to try different preprocessing to get our accuracy up. It will save us a lot of time that we would have otherwise spent making changes through the code even for minute changes in preprocessing.
We will be Implementing the following Preprocessing Functions –
I will be explaining them further in the article as we implement them
Cleaning Data
- Removing Missing Data
- Removing Mismatch Data
- Converting Numeric Data Stored as String to Numerical Form.
- Single Function Combining all the above Data Cleaning Step.
Encoding Data
- Label Encoding (with an order)
- Label Encoding (without an order)
- One Hot Encoding
- Single Function Combining all the above Encodings
Normalizing Data
- Divide by Largest
- Divide by Constant
- Divide by Constant x Largest
- Min-Max Normalization
- Mean Normalization
- Single Function Combining all above Normalizations
Splitting Data
- Train-Validation-Test Split (using sklearn)
- Single Function for both Train-Test Split & Train-Validation-Test Split
Link to Dataset – Cars93 Dataset
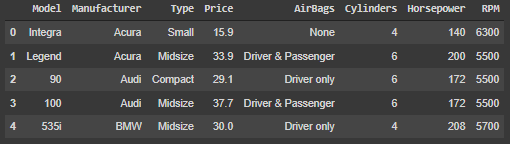
Importing Data
import pandas as pd df = pd.read_csv(path+'Cars93.csv') df = df[['Model','Manufacturer','Type','Price','AirBags','Cylinders','Horsepower','RPM']] # We keep a few features only for our purpose df.head(3)
Cleaning Data
We need to clean the data so that we do not face any issues later when we apply a model to our data.
Removing Missing Data
We need to remove data where the value of any feature is nan or na or empty.
def remove_missing(df) :
remove = []
for i, row in df.iterrows():
if row.isna().values.any() : remove.append(i)
df.drop(remove,axis=0,inplace=True)
Remove Mismatch Data
We need to remove data with mismatches. For eg. a data point with a string value for a numerical feature. For this, we will check what data type is the majority for each feature and remove the data with a different data type for those features.
We also make provision of ‘exceptions’ where we can specify features for which values can have different data types and we don’t want to remove mismatches.
def remove_mismatch(df,exceptions=[]) :
for col in df :
if col in exceptions : continue
df.reset_index(drop=True, inplace=True)
s = [False]*len(df[col])
for i,cell in enumerate(df[col]) :
try : n = int(cell)
except : s[i] = True
t = s.count(True)
f = s.count(False)
st = False
if(t>f) : st = True
remove = [i for i in range(len(df[col])) if s[i]!=st]
df.drop(remove,axis=0,inplace=True)
Converting Numeric Data Stored as String to Numerical Form –
Sometimes Numeric Data (eg. int) is stored as a String, leading to an error when we train our model or normalize our data. We need to identify such cases and convert them to their original numerical form.
def str_to_num(df) :
for col in df :
try : df[col] = pd.to_numeric(df[col])
except : pass
Single Function for Cleaning Data
def clean(df,exceptions_mismatch=[]) : remove_missing(df) remove_mismatch(df,exceptions=exceptions_mismatch) str_to_num(df)
clean(df,exceptions_mismatch=['Model'])
Encoding Data
Label Encoding- Assigning an integer to each unique value of a column/feature.
One Hot Encoding- Converting 1 column to n columns where n is the number of unique values in that column. Each new column represents a unique value in the original column and it contains either 0 or 1. So in each row, only one of the n columns will have the value 1 and the remaining n-1 columns will have the value 0.
We are going to represent the type of encoding we want for each column using a dictionary, where the keys will be the column/feature names and their values will be the type of encoding we want.
labels = {}
labels['AirBags'] = ['None','Driver only','Driver & Passenger'] labels['Type'] = None labels['Manufacturer'] = [] labels['Model'] = []
- ‘None’ will mean One Hot Encoding
- ‘[]’ would mean Label Encoding without a given order
- ‘[a,b,c…]’ would mean Label Encoding with the list being the order
This way experimenting with different encoding will become very easy. For eg., if we want to change the encoding of the ‘Type’ column from One Hot to Label, we can do it by simply changing its value in the labels dictionary from None to [].
Label Encoding
The function takes the column name and order as input.
Lets say, df['col'] = ['b','a','b','c']
order = []
Label Encoding with no given order
df['col'] = [0,1,0,2]
order = ['a','b','c']
Label Encoding with given order
df['col'] = [1,0,1,2]
order = ['a']
By giving only a few values in order we can keep remaining values as 'others'
df['col'] = [-1,0,-1,-1]
def encode_label(df,col,order=[]) :
if(order==[]) : order = list(df[col].unique())
for i,cell in enumerate(df[col]) :
try :
df.at[i,col] = order.index(df[col][i])
except :
df.at[i,col] = -1
One Hot Encoding
The function takes the column name as input. Lets say, df['col'] = ['b','a','b','c'] After One Hot Encoding -
-
df['col_b'] = [1,0,1,0]
-
df['col_a'] = [0,1,0,0]
-
df['col_c'] = [0,0,0,1]
def encode_onehot(df,col) :
k = {}
n = df[col].shape[0]
unique = df[col].unique()
for unq in unique : k[unq] = [0]*n
for i in range(n) :
k[df.at[i,col]][i] = 1
for unq in unique : df[f"{col}_{unq}"] = k[unq]
df.drop(col,axis=1,inplace=True)
Single Function For Encoding Data
def encode(df,cols) :
for col in cols.keys() :
if(cols[col] is None) : encode_onehot(df,col)
else : encode_label(df,col,cols[col])
encode(df,labels)

Normalizing Data
- Divide by Largest: Divide all the values in a column by the largest value in that column
- Divide by Constant: Divide all the values in a column by a constant value (eg. 255 in case of an image)
- Divide by Constant x Largesr: Divide all the values in a column by a given constant x largest value in that column
- Min- Max Normalization: Subtracting the minimum value from all the values in a column and then dividing all the values by the largest value in that column (new min will be 0 and new max will be 1)
- Mean Normalization: Subtracting the mean from all the values in a column and then dividing all the values by (largest-smallest).
# Dividing by largest
def normalize_dbl(df,cols,round=None) :
if(type(cols)!=list) : cols = [cols]
for col in cols :
l = df[col].max()
if round is None : df[col] = df[col].div(l)
else : df[col] = df[col].div(l).round(round)
# Dividing by constant
def normalize_dbc(df,cols,round=None,c=1) :
if(type(cols)!=list) : cols = [cols]
for col in cols :
if round is None : df[col] = df[col].div(c)
else : df[col] = df[col].div(c).round(round)
# Dividing by constant x largest
def normalize_dblc(df,cols,round=None,c=1) :
if(type(cols)!=list) : cols = [cols]
for col in cols :
l = df[col].max() * c
if round is None : df[col] = df[col].div(l)
else : df[col] = df[col].div(l).round(round)
# min-max normalization
def normalize_rescale(df,cols,round=None) :
if(type(cols)!=list) : cols = [cols]
for col in cols :
df[col] = df[col] - df[col].min()
l = df[col].max()
if round is None : df[col] = df[col].div(l)
else : df[col] = df[col].div(l).round(round)
# mean normalization
def normalize_mean(df,cols,round=None) :
if(type(cols)!=list) : cols = [cols]
for col in cols :
mean = df[col].mean()
l = df[col].max() - df[col].min()
df[col] = df[col] - mean
if round is None : df[col] = df[col].div(l)
else : df[col] = df[col].div(l).round(round)
Single Function for Normalizing Data
def normalize(df,cols=None,kinds='dbl',round=None,c=1,exceptions=[]) :
if(cols is None) :
cols = []
for col in df :
if(pd.api.types.is_numeric_dtype(df[col])) :
if(max(df[col])>1 or min(df[col])<-1) :
if(col not in exceptions) : cols.append(col)
if(type(cols)!=list) : cols = [cols]
n = len(cols)
if(type(kinds)!=list) : kinds = [kinds]*n
for i,kind in enumerate(kinds) :
if(kind=='dbl') : normalize_dbl(df,cols[i],round)
if(kind=='dbc') : normalize_dbc(df,cols[i],round,c)
if(kind=='dblc') : normalize_dblc(df,cols[i],round,c)
if(kind in ['min-max','rescale','scale']) : normalize_rescale(df,cols[i],round)
if(kind=='mean') : normalize_mean(df,cols[i],round)
We can vastly vary the overall normalizations by easily making changes in the parameters of this function when we call it. This helps in experimenting with different normalizations.
Some examples of various ways in which we can normalize our data using this function –
If we want to normalize all columns (it detects numeric columns) –
normalize(df)
If we want to normalize and round to 3 decimal places –
normalize(df,round=3)
If we want to normalize all columns by a kind other than dividing by largest –
normalize(df,kinds='mean')
If we want to normalize some columns with a kind and some columns with other kind –
normalize(df,['Price','Horsepower'],'dbl') normalize(df,['AirBags','Cylinders'],'min-max') normalize(df,['RPM'],'dblc',c=1.25)
or
normalize(df,['Price','AirBags','Cylinders','Horsepower','RPM'],['dbl','min-max','min-max','dbl','dblc'],c=1.25)
If we want to normalize all columns except a few –
normalize(df,kinds='min-max',exceptions=['AirBags','RPM'],round=4)
Splitting Data
We will use sklearn and make a function to split data where we won’t even need to mention if we are splitting our data into 2 or 3 portions.
We also need to reset the index of x_train, x_test, etc., otherwise, we can face problems while iterating over them in the future.
from sklearn.model_selection import train_test_split x = df.drop(['Price'], axis=1) y = df.loc[:,'Price']
Way Split
def train_test(x,y,train_size=-1,test_size=-1) : if(train_size==-1) : train_size = 1-test_size x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=train_size,random_state=101) x_train.reset_index(drop=True,inplace=True) x_test.reset_index(drop=True,inplace=True) y_train.reset_index(drop=True,inplace=True) y_test.reset_index(drop=True,inplace=True) return x_train,x_test,y_train,y_test
Way Split
def train_val_test(x,y,train_size=-1,val_size=-1,test_size=-1) : if(train_size==-1) : train_size = 1-val_size-test_size if(val_size==-1) : val_size = 1-train_size-test_size x_train,x_val,y_train,y_val = train_test_split(x,y,train_size=train_size,random_state=101) x_val,x_test,y_val,y_test = train_test_split(x_val,y_val,train_size=(val_size/(1-train_size)),random_state=101) x_train.reset_index(drop=True,inplace=True) x_val.reset_index(drop=True,inplace=True) x_test.reset_index(drop=True,inplace=True) y_train.reset_index(drop=True,inplace=True) y_val.reset_index(drop=True,inplace=True) y_test.reset_index(drop=True,inplace=True) return x_train,x_val,x_test,y_train,y_val,y_test
Single Function for Splitting Data
If we pass two sizes in the function (eg. train_size & val_size) then it will be a three-way split, if we pass one size (eg. train_size) it will be a two-way split.
def split(x,y,train_size=-1,val_size=-1,test_size=-1) :
if(train_size==-1 and val_size==-1) : return train_test(x,y,train_size=1-test_size)
if(train_size==-1 and test_size==-1) : return train_test(x,y,train_size=1-val_size)
if(val_size==-1 and test_size==-1) : return train_test(x,y,train_size=train_size)
return train_val_test(x,y,train_size,val_size,test_size)
Train Validation Test Split
x_train,x_val,x_test,y_train,y_val,y_test = split(x,y,train_size=0.7,val_size=0.15)
Train-Test Split :
x_train,x_test,y_train,y_test = split(x,y,train_size=0.75)
Conclusion on Preprocessing
In this article, we implemented preprocessing functions for Cleaning, Encoding, Normalizing, and Splitting Data. We saw how organized preprocessing makes our job easier.
Join our course “How to Preprocess Data” to master these essential techniques and streamline your data preparation process!
After Importing the data, we can preprocess it as per our needs in 4 lines. We can keep modifying the parameters to experiment with different preprocessing.

import pandas as pd
df = pd.read_csv(path+'Cars93.csv')
df = df[['Model','Manufacturer','Type','Price','AirBags','Cylinders','Horsepower','RPM']]clean(df,exceptions_mismatch=['Model'])
encode(df,{'AirBags':['None','Driver only','Driver & Passenger'],'Type':None,'Manufacturer':[],'Model':[]})
normalize(df,['Price','AirBags','Cylinders','Horsepower','RPM'],'min-max')
x_train,x_test,y_train,y_test = split(df.drop(['Price'],axis=1),df.loc[:,'Price'],train_size=0.8)Key Takeaways
- Organized Preprocessing saves time and helps us preprocess different datasets and try different preprocessing without much code change.
- Data Cleaning: We need to remove (or replace) rows with na/nan values, remove rows with the wrong datatype for any feature, and convert numeric data stored as string format in the CSV/excel file back to its original form.
- Data Encoding: We need to encode data as most ML models require numeric data. We implemented label encoding and one hot encoding.
- Data Normalization: It helps in reducing bias towards a feature, and sometimes reduces computation time. We implemented 5 normalization techniques.
- Data Splitting: We need to split our data into the train portion (for fitting the model) and the testing portion (for evaluating the model). Sometimes, we also split into a third portion – validation, which we use to find optimal parameters for our model.
I hope this tutorial helped you. Other than preprocessing too, it’s good to keep our code organized, it helps in making changes later. We should also try to make universal functions taking the dataset as an argument rather than making hardcoded functions that will work only for the dataset we are using at that time.



