SQL stands for Structured Query Language. It’s a programming language to interact/query and manage RDBMS (Relational Database Management Systems). SQL skills are highly preferred and required as it’s used by many organizations in many software applications. So, as a fresher or experienced candidate, if you are planning for an upcoming SQL interview, you must ensure that you are prepared well for all sorts of conceptual, theoretical, coding, and SQL interview questions. This article consists of 80 real-time scenario-based SQL coding interview questions to help you test your SQL skills and boost your confidence.
NOTE: All the SQL queries used here are compatible with Oracle database versions like 11g, 12c, 18c, etc.
This article was published as a part of the Data Science Blogathon.
Table of contents
Top 70 SQL Coding Interview Questions
Q1. What is SQL and its significance in databases?
Answer. SQL stands for Structured Query Language. It is a programming language used for managing and manipulating relational databases. SQL is essential for tasks like querying data, updating records, and defining the structure of databases.
Q2. Differentiate between SQL and MySQL.
Answer. SQL, a language for managing and manipulating relational databases, serves as the foundation for MySQL, a relational database management system (RDBMS).
Q3. Explain the basic structure of an SQL query.
Answer. The basic structure of an SQL query consists of a SELECT clause (specifying columns), a FROM clause (specifying tables), and optional clauses like WHERE (specifying conditions) and ORDER BY (sorting results).
Q4. What is normalization, and what are its types?
Answer. Normalization is organizing data in a database to reduce redundancy and dependency. The primary goals of normalization are to eliminate data anomalies, ensure data integrity, and minimize the chances of data redundancy. Break down larger tables into smaller, related tables and define their relationships.
There are several normal forms (NF) that represent different levels of normalization, and each normal form has specific rules to achieve the desired database structure. The most common normal forms are:
- First Normal Form (1NF):
- Each column in a table must contain atomic (indivisible) values, and each row must be unique.
- Second Normal Form (2NF):
- The table must be in 1NF, and all non-key attributes must be fully functionally dependent on the primary key. This means that if a table has a composite primary key, each non-key attribute must be dependent on the entire composite key, not just part of it.
- Third Normal Form (3NF):
- The table must be in 2NF, and no transitive dependencies should exist. In other words, non-key attributes must not be dependent on other non-key attributes.
- Boyce-Codd Normal Form (BCNF):
- Similar to 3NF but stricter. It states that a table is in BCNF if, for every non-trivial functional dependency, the determinant is a superkey.
- Fourth Normal Form (4NF):
- It addresses multi-valued dependencies. A table is in 4NF if it has no non-trivial multi-valued dependencies.
- Fifth Normal Form (5NF):
- Deals with cases where a table has overlapping multi-valued dependencies.
Normalization is an iterative process, and not all databases need to be normalized to the same degree. The level of normalization depends on the specific requirements of the application and the trade-offs between data redundancy and the complexity of database operations. In practice, many databases are normalized up to the third normal form (3NF) to strike a balance between simplicity and data integrity.
Q5. What is denormalization?
Answer. Denormalization is the process of intentionally introducing redundancy into a database by adding redundant data to one or more tables. This is done to improve query performance and simplify data retrieval at the cost of increased storage space and potential data integrity challenges. Denormalization is often applied in situations where the performance of read operations is more critical than the performance of write operations.
Q6. What is a primary key? How is it different from a foreign key?
Answer. A primary key uniquely identifies each record in a table and must have unique values. On the other hand, a foreign key establishes a link between two tables, referencing the primary key of another table.
Q7. What is an index, and why is it used in databases?
Answer. An index is a data structure that improves the speed of data retrieval operations on a database table. It is used to quickly locate and access the rows that match a particular column value.
Q8. Describe the difference between INNER JOIN and LEFT JOIN.
Answer. INNER JOIN returns only the rows with a match in both tables, while LEFT JOIN returns all rows from the left table and the matched rows from the right table.
Q9. How do you add a new record to a table?
Answer. INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);
Q10. What are the subsets of SQL?
Answer. SQL can be broadly categorized into several subsets based on the types of operations or tasks they address. Here are some common subsets of SQL:
- DDL (Data Definition Language):
- DDL includes SQL commands that define and manage the structure of the database. Common DDL commands include:
CREATE: Used to create database objects such as tables, indexes, and views.ALTER: Used to modify the structure of existing database objects.DROP: Used to delete database objects.
- DDL includes SQL commands that define and manage the structure of the database. Common DDL commands include:
- DML (Data Manipulation Language):
- DML comprises SQL commands that interact with the data stored in the database. Common DML commands include:
SELECT: Retrieves data from one or more tables.INSERT: Adds new rows of data into a table.UPDATE: Modifies existing data in a table.DELETE: Removes rows of data from a table.
- DML comprises SQL commands that interact with the data stored in the database. Common DML commands include:
- DCL (Data Control Language):
- DCL deals with the permissions and access control of the database. Common DCL commands include:
GRANT: Provides specific privileges to database users.REVOKE: Removes specific privileges from database users.
- DCL deals with the permissions and access control of the database. Common DCL commands include:
- TCL (Transaction Control Language):
- TCL includes commands related to transactions within a database. Common TCL commands include:
COMMIT: Commits a transaction, making changes permanent.ROLLBACK: Rolls back a transaction, undoing changes made during the transaction.SAVEPOINT: Sets a point within a transaction to which you can later roll back.
- TCL includes commands related to transactions within a database. Common TCL commands include:
- Data Query Language (DQL):
- DQL is a subset of SQL specifically focused on querying and retrieving data. The primary command for DQL is
SELECT, which is used to retrieve data from one or more tables.
- DQL is a subset of SQL specifically focused on querying and retrieving data. The primary command for DQL is
- Procedural Extensions (PL/SQL, T-SQL):
- Some database systems extend SQL to include procedural programming constructs. For example:
- PL/SQL (Procedural Language/Structured Query Language) is used in Oracle Database.
- T-SQL (Transact-SQL) is used in Microsoft SQL Server.
- Some database systems extend SQL to include procedural programming constructs. For example:
- OLAP (Online Analytical Processing):
- SQL extensions for working with multidimensional data and performing complex analytical queries. These might include extensions like
CUBE,ROLLUP, and window functions.
- SQL extensions for working with multidimensional data and performing complex analytical queries. These might include extensions like
- OLTP (Online Transaction Processing):
- SQL commands optimized for transactional processing, typically involving simple CRUD (Create, Read, Update, Delete) operations.
Q11. Explain database white box testing and black box testing.
White box testing and black box testing are two different testing methodologies used in the context of databases, including SQL databases. These methodologies focus on different aspects of testing, and they are applicable to various levels of the software development life cycle.
| White Box Testing | Black Box Testing |
| White box testing, also known as structural or glass box testing, is a testing method that examines the internal logic and structure of the database system. Testers have knowledge of the internal workings, code, and implementation details of the database. The objective is to ensure that all paths and branches of the code are executed and that the database functions correctly at the code level. | Black box testing, also known as functional or behavioral testing, is a testing method where the tester has no knowledge of the internal workings of the database. Testers focus on verifying the external behavior and functionality of the database without looking at the code or internal implementation details. The goal is to assess whether the database meets the specified requirements and behaves as expected. |
Q12. How can you create empty tables with the same structure as another table?
In SQL, you can create an empty table with the same structure as another table using the CREATE TABLE statement along with the AS clause. This approach is commonly known as creating a table based on another table. Here’s the basic syntax:
CREATE TABLE new_table AS
SELECT * FROM existing_table WHERE 1 = 0;This syntax involves creating a new table (new_table) because of a SELECT statement that doesn’t retrieve any rows from the existing table (existing_table). The WHERE 1 = 0 condition ensures that no rows are selected from the existing table, creating an empty table with the same structure.
Q13. What is the difference between the DROP and TRUNCATE commands?
Answer. In SQL, DROP is used to permanently delete a table and its structure, releasing occupied space. TRUNCATE removes all data from a table, retaining the structure but not releasing space. DROP is irreversible, while TRUNCATE is faster and safer for data removal, especially in production.
Q14. What are the benefits of SQL database over NoSQL database?
Answer. SQL databases offer structured data management with predefined schemas, enforcing data consistency and integrity through ACID properties. They excel in complex querying, supporting joins, and providing strong consistency. SQL databases scale vertically by adding resources to a single server, making them suitable for applications with intricate relationships between entities. The mature SQL ecosystem offers a wide range of tools and support. In contrast, NoSQL databases prioritize schema flexibility, horizontal scalability, and eventual consistency for distributed systems. They are well-suited for unstructured or semi-structured data and high write loads. The choice between SQL and NoSQL depends on specific application requirements, data structures, and scalability needs. SQL databases excel in scenarios that demand data integrity, complex queries, and transaction support.
Q15. What is a primary key?
In SQL, a primary key is a field or a combination of fields in a table that uniquely identifies each record in that table. The primary key has two main characteristics:
- Uniqueness:
- Every value in the primary key column (or columns) must be unique across all records in the table. This ensures that each record can be uniquely identified based on its primary key value.
- Non-Nullability:
- The primary key column (or columns) cannot contain NULL values. Each record must have a non-null value in the primary key column, emphasizing its role as a unique identifier.
Q16. What is meant by table and field in SQL?
In SQL, a table is a structured representation of data organized in rows and columns. It is the fundamental storage unit within a relational database to store and organize related information. Each table consists of columns (also known as fields) and rows.
| TABLE | FIELD |
| – A table is a collection of related data entries organized in rows and columns. – Each row in a table represents a record, and each column represents a specific attribute or field of that record. – Tables are named and must have a unique name within the database. | – A field, also referred to as a column, is a specific attribute or property of the data stored in a table. – Each column has a data type that defines the kind of data it can store (e.g., INT for integers, VARCHAR for variable-length character strings). – Fields hold the actual data values for each record in the table. |
Q17. What is a constraint, and why use constraints?
In SQL, a constraint is a rule applied to a table column to ensure data integrity and enforce specific conditions. Types of constraints include primary key (ensures uniqueness), foreign key (establishes relationships), unique (enforces uniqueness), check (validity checks), and NOT NULL (avoids NULL values). Constraints play a vital role in maintaining data accuracy, relationships, and adherence to business rules, providing a robust foundation for reliable database management.
Q18. What is a subquery?
In SQL, a subquery is a nested query enclosed within parentheses that is used to retrieve data based on the results of another query. It can be employed in various SQL statements, such as SELECT, INSERT, UPDATE, and DELETE. Subqueries enhance the flexibility of queries by allowing operations and decisions to be based on the outcome of another query.
Q19. What is a SQL operator?
In SQL, operators are symbols or keywords used for various operations. Types include arithmetic (e.g., +, -, *), comparison (e.g., =, <, >), logical (e.g., AND, OR, NOT), concatenation (e.g., ||), IN, LIKE, IS NULL, and BETWEEN. Operators are vital for constructing queries to perform calculations, comparisons, and string manipulations in a relational database.
Q20. What is an alias?
In SQL, an alias is a temporary name assigned to a table or column in a query. It improves readability and provides a shorter reference. For example, table aliases (e.g., “e” for “employees”) and column aliases (e.g., “increased_salary” for a calculated column) are commonly used. Aliases are specified using the AS keyword but are often optional for column aliases.
Q21. What is the purpose of the GROUP BY clause in SQL?
Answer. The GROUP BY clause groups rows with the same values in specified columns into summary rows, like finding the total sales per category.
Q22. Explain the concept of a subquery and provide an example.
Answer. A subquery is a query embedded within another query. Example: SELECT * FROM employees WHERE department_id IN (SELECT department_id FROM departments WHERE location = 'New York');
Q23. How can you prevent SQL injection in your queries?
Answer. Use parameterized queries or prepared statements, which allow the database to distinguish between code and data, preventing malicious SQL injection.
Q24. What are stored procedures, and how are they different from functions?
Answer. Stored procedures are precompiled SQL queries stored in the database. Functions return a value and can be used in SQL statements like expressions, while procedures do not return values directly.
Q25. Describe the ACID properties in the context of database transactions.
Answer. ACID stands for Atomicity, Consistency, Isolation, and Durability. These properties ensure the reliability of database transactions by maintaining data integrity and consistency.
Q26. Explain the use of the HAVING clause in SQL.
Answer. The HAVING clause is used with the GROUP BY clause to filter the results of aggregate functions based on specified conditions.
Q27. Differentiate between UNION and UNION ALL.
Answer. UNION combines and returns unique rows from two or more SELECT statements, while UNION ALL returns all rows, including duplicates.
Q28. What is the purpose of the COALESCE function?
Answer. The COALESCE function returns the first non-null expression in a list. It often replaces null values with a default or alternative value.
Q29. How do you perform a self-join in SQL?
Answer. A self-join is performed by joining a table with itself. Example: SELECT e1.name, e2.name FROM employees e1 INNER JOIN employees e2 ON e1.manager_id = e2.employee_id;
Q30. Explain the concept of database transactions.
Answer. A transaction is a sequence of one or more SQL statements that are executed as a single unit. It ensures the consistency and integrity of the database by either committing changes or rolling back to the previous state.
Q31. What is the purpose of the window functions in SQL?
Answer. Window functions perform calculations across a set of rows related to the current row. Examples include ROW_NUMBER(), RANK(), and LEAD().
Q32. Explain the differences between clustered and non-clustered indexes.
Answer. A clustered index determines the physical order of data in a table, while a non-clustered index does not affect the physical order but provides a separate structure to improve query performance.
Q33. How does the SQL Server optimizer work?
Answer. The SQL Server optimizer generates and evaluates various execution plans to choose the most efficient one based on factors like indexes, statistics, and query complexity.
Q34. What are common table expressions (CTEs), and when would you use them?
Answer. CTEs are named temporary result sets defined within the scope of a SELECT, INSERT, UPDATE, or DELETE statement. They are used to simplify complex queries and improve readability.
Q35. Discuss the concept of materialized views in databases.
Answer. Materialized views are precomputed and stored result sets, updated periodically based on the underlying data. They improve query performance by reducing the need to recalculate results.
Q36. How can you optimize a query’s performance in SQL?
Answer. Query performance can be optimized by using indexes, avoiding SELECT *, optimizing joins, and ensuring up-to-date statistics.
Q37. Explain the purpose of the OLAP and OLTP database systems.
Answer. OLAP (Online Analytical Processing) databases are designed for complex queries and reporting, while OLTP (Online Transaction Processing) databases focus on quick, transactional data processing.
Q38. What is the difference between a view and a table?
Answer. A table is a physical storage structure, while a view is a virtual table created by a SELECT query. Views provide a way to simplify complex queries and control access to data.
Q39. Describe the process of database sharding.
Answer. Database sharding involves breaking an extensive database into smaller, more manageable pieces called shards. Each shard is stored on a separate server, improving scalability and performance.
Q40. Explain the use of the APPLY operator in SQL.
Answer. The APPLY operator invokes a table-valued function for each row returned by an outer table expression. It is handy for joining with functions that take parameters.
Q41. How to update a table?
Use the below syntax to update a table:
UPDATE table_name
SET col_1 = value_1, column_2 = value_2
WHERE condition;Q42. How do you sort records in a table?
To sort records in a table in SQL, you can use the ORDER BY clause in your SELECT statement. The ORDER BY clause allows you to specify one or more columns by which the result set should be sorted. The sorting can be done in ascending (ASC) or descending (DESC) order.
Here is the basic syntax for sorting records in a table:
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...;
SELECT: Specifies the columns you want to retrieve.FROM: Specifies the table from which to retrieve data.ORDER BY: Specifies the columns by which to sort the result set.ASC: Optional keyword for ascending order (default if not specified).DESC: Keyword for descending order.
Q43. What is the DISTINCT statement, and how do you use it?
The DISTINCT keyword in SQL is used to eliminate duplicate rows from the result set of a SELECT query. It returns only unique values for the specified columns.
Here’s the basic syntax for using the DISTINCT statement:
SELECT DISTINCT column1, column2, ...
FROM table_name;SELECT DISTINCT: Specifies that only distinct (unique) values should be returned.column1, column2, ...: Specifies the columns for which you want to retrieve distinct values.FROM table_name: Specifies the table from which to retrieve data.
Example: Consider a “students” table with columns “student_id” and “course_id.” If you want to retrieve a list of unique course IDs from this table, you can use the DISTINCT keyword:
SELECT DISTINCT course_id
FROM students;This query returns only distinct values from the “course_id” column in the “students” table.
Q44. What are entities? Give some examples.
Answer. In the context of SQL and databases, an “entity” typically refers to a table or an object that can be uniquely identified and is used to store and represent data. Entities are fundamental building blocks in database design and correspond to real-world objects or concepts.
Q45. What scalar functions do you know?
Scalar functions in SQL are functions that operate on a single value and return a single value. These functions can be used within SQL queries to perform operations on individual columns or literals. Here are some commonly used scalar functions in SQL:
- String Functions:
- UPPER(str): Converts a string to uppercase.
SELECT UPPER('hello') AS result; -- Result: 'HELLO'
- LOWER(str): Converts a string to lowercase.
SELECT LOWER('Hello') AS result; -- Result: 'hello' - CONCAT(str1, str2, …): Concatenates two or more strings.
SELECT CONCAT('John', ' ', 'Doe') AS full_name; -- Result: 'John Doe' - LENGTH(str): Returns the length of a string.
SELECT LENGTH('apple') AS str_length; -- Result: 5
- UPPER(str): Converts a string to uppercase.
- Numeric Functions:
- ABS(num): Returns the absolute value of a number.
SELECT ABS(-10) AS absolute_value; -- Result: 10 - ROUND(num, decimals): Rounds a number to the specified number of decimal places.
SELECT ROUND(3.14159, 2) AS rounded_value; -- Result: 3.14 - SQRT(num): Returns the square root of a number.
SELECT SQRT(16) AS square_root; -- Result: 4 - RAND(): Returns a random number between 0 and 1.
SELECT RAND() AS random_number; -- Result: (random value between 0 and 1)
- ABS(num): Returns the absolute value of a number.
- Date and Time Functions:
- NOW(): Returns the current date and time.
SELECT NOW() AS current_datetime; -- Result: 'YYYY-MM-DD HH:MI:SS' - DATE_FORMAT(date, format): Formats a date according to the specified format.
SELECT DATE_FORMAT(NOW(), '%Y-%m-%d') AS formatted_date; -- Result: 'YYYY-MM-DD' - DATEDIFF(date1, date2): Returns the difference in days between two dates.
SELECT DATEDIFF('2022-01-01', '2022-01-10') AS date_difference; -- Result: -9
- NOW(): Returns the current date and time.
- Mathematical Functions:
- POWER(base, exponent): Returns the result of raising a number to a specified power.
SELECT POWER(2, 3) AS result; -- Result: 8 - CEIL(num): Returns the smallest integer greater than or equal to a number.
SELECT CEIL(4.3) AS result; -- Result: 5 - FLOOR(num): Returns the largest integer less than or equal to a number.
SELECT FLOOR(4.8) AS result; -- Result: 4
- POWER(base, exponent): Returns the result of raising a number to a specified power.
These are just a few examples of scalar functions in SQL. Different database systems may have variations in syntax or additional functions, so it’s important to refer to the documentation of the specific database you are working with.
Q46. How do we prevent duplicate records when making a query?
To prevent duplicate records when making a query in SQL, you can use the DISTINCT keyword in the SELECT statement. The DISTINCT keyword filters out duplicate rows from the result set, ensuring that only unique values are returned. Here’s the basic syntax:
SELECT DISTINCT column1, column2, ... FROM table_name WHERE conditions;
Q47. How do you add a record to a table?
In SQL, you use the INSERT statement to add a new record or row to a table. The basic syntax for the INSERT statement is as follows:
INSERT INTO table_name (column1, column2, ..., columnN) VALUES (value1, value2, ..., valueN);
Q48. What are SQL operators?
SQL operators are symbols or keywords that perform operations on one or more expressions in SQL queries. They are used to perform mathematical operations, comparison operations, logical operations, and other manipulations on data within the database. SQL operators can be broadly categorized into several types:
Arithmetic Operators:
- Addition (
+):- Adds two numbers.
SELECT salary + bonus AS total_income FROM employees; - Subtraction (
-):- Subtracts the right operand from the left operand.
SELECT total_sales - expenses AS profit FROM financial_data; - Multiplication (
*):- Multiplies two numbers.
SELECT quantity * unit_price AS total_cost FROM orders; - Division (
/):- Divides the left operand by the right operand.SELECT revenue / num_customers AS average_revenue FROM sales_summary;
- Modulus (
%):- Returns the remainder of the division of the left operand by the right operand.
SELECT order_id % 1000 AS short_order_id FROM orders;
Comparison Operators:
- Equal to (
=):- Tests if two expressions are equal.
SELECT * FROM products WHERE category_id = 1; - Not equal to (
<>or!=):- Tests if two expressions are not equal.
SELECT * FROM customers WHERE country_code <> 'US'; - Greater than (
>):- Tests if the left operand is greater than the right operand.
SELECT * FROM employees WHERE salary > 50000; - Less than (
<):- Tests if the left operand is less than the right operand.
SELECT * FROM products WHERE unit_price < 10; - Greater than or equal to (
>=):- Tests if the left operand is greater than or equal to the right operand.
SELECT * FROM orders WHERE order_date >= '2022-01-01'; - Less than or equal to (
<=):- Tests if the left operand is less than or equal to the right operand.
SELECT * FROM customers WHERE registration_year <= 2020;
Logical Operators:
- AND (
AND):- Combines two conditions. Returns true if both conditions are true.
- SELECT * FROM products WHERE category_id = 1 AND stock_quantity > 0;
- OR (
OR):- Combines two conditions. Returns true if at least one condition is true.
SELECT * FROM employees WHERE department_id = 1 OR department_id = 2; - NOT (
NOT):- Negates a condition. Returns true if the condition is false, and vice versa.
SELECT * FROM customers WHERE NOT country_code = 'US';
Other Operators:
- LIKE (
LIKE):- Compares a value to a pattern using wildcard characters.
SELECT * FROM products WHERE product_name LIKE 'Apple%'; - IN (
IN):- Tests if a value matches any value in a list.
SELECT * FROM orders WHERE customer_id IN (101, 102, 103); - BETWEEN (
BETWEEN):- Tests if a value is within a specified range.SELECT * FROM employees WHERE salary BETWEEN 40000 AND 60000;
These operators are fundamental to constructing SQL queries and expressing various conditions and calculations within the database. They play a crucial role in filtering, sorting, and manipulating data.
Q49. What do you mean by data integrity?
Answer. Data integrity in SQL refers to the accuracy, consistency, and reliability of data stored in a relational database. It ensures that the data remains valid and reliable throughout its lifecycle, from the point of entry into the database to its retrieval and modification. Maintaining data integrity is crucial for making informed decisions based on accurate and consistent information.
Q50. Why is the FLOOR function used in SQL Server?
The FLOOR function in SQL Server is used to round a numeric value down to the nearest integer that is less than or equal to the original value. It essentially removes the decimal part of a numeric value and returns the largest integer less than or equal to the input.
The basic syntax of the FLOOR function is as follows:
FLOOR(numeric_expression)
numeric_expression: The numeric value that you want to round down to the nearest integer.
Consider the student table as shown below for question no. 1, 2, and 3.
51. Write a query to extract the username(characters before @ symbol) from the Email_ID column.
Answer:
SELECT SUBSTR(Email_ID, 1, INSTR(Email_ID, '@') - 1) FROM STUDENT;Extract the position of @ from the email id first using INSTR() function then pass this position(after subtracting 1) as an argument for length in SUBSTR() function.
Output –

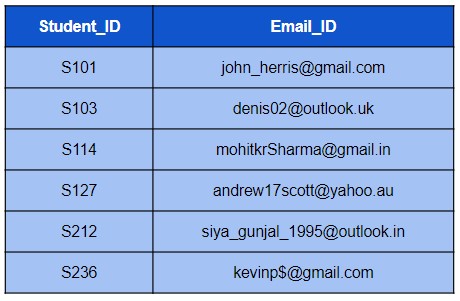
Q52. Write a query to extract domain name like .com, .in, .au etc. from the Email_ID column.
Answer:
SELECT SUBSTR(Email_ID, INSTR(Email_ID, '.')) FROM STUDENT; Extract the position of . (dot character) from the email id first using INSTR() function then pass this position as an argument for starting position in SUBSTR() function.
Output –
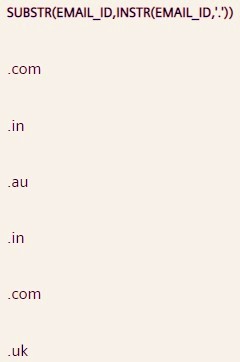
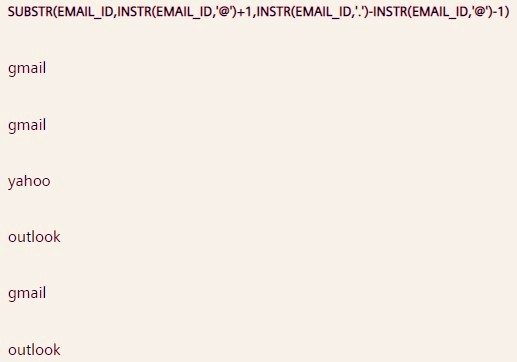
Q53. Write a query to extract email service provider names like google, yahoo, outlook, etc. from the Email_ID column.
Answer:
SELECT SUBSTR(Email_ID, INSTR(Email_ID, '@') + 1, INSTR(Email_ID, '.') - INSTR(Email_ID, '@') - 1) FROM STUDENT; Extract the position of @ from the email id first using INSTR() function, and pass it (after adding 1) as an argument for starting position in SUBSTR() function.
Now extract this position of . (dot character) and subtract it from the earlier extracted @ position and pass it (after subtracting 1) as an argument for length in SUBSTR() function.
Output –
Q54. What is(are) the output of the following query?
SELECT CEIL(-12.43), FLOOR(-11.92) FROM DUAL;
a. -13, -12
b. -12, -12
c. -12, -11
d. -13, -11
Answer: b
CEIL() function returns the smallest integer number that is greater than or equal to the given number. So if we pass -12.43 in ceil, it returns the smallest integer value that is >= -12.43 i.e. -12.
FLOOR() function returns the largest integer number that is less than or equal to the given number. So if we pass -11.92 in floor, it returns the largest integer value that is <= -11.92 i.e. -12.
Output –

Q55. Write a query to extract all the consonants present in your name.
SELECT TRANSLATE('Narendra', 'xaeiou', 'x') FROM DUAL;First, extract the consonants from the input name as extracted above, then concatenate these consonants with the character ‘a’ in from_string argument to remove the consonants by not specifying corresponding characters in to_string argument. So if we pass Narendra as the name in the above query, it returns vowels (a, e, a).
Output –

Q56. Write a query to extract all the vowels present in your name.
Answer:
SELECT TRANSLATE('Narendra', 'a' || TRANSLATE('Narendra', 'xaeiou', 'x'), 'a') FROM DUAL;First, extract the consonants from the input name as extracted above, then concatenate these consonants with character ‘a’ in from_string argument to remove the consonants by not specifying corresponding characters in to_string argument. So if we pass Narendra as the name in the above query, it returns vowels (a, e, a).
Output:

Refer to the emp table as shown below for question no. 7 to 14.

Q57. Write a query to extract the employees’ details who joined in the year 1981.
SELECT * FROM EMP WHERE TO_CHAR(HIREDATE, 'YY') = 81;Use TO_CHAR() to extract the year part from the hiredate column and select all the employees who were hired in 1981 by using WHERE clause.
Output –

Q58. Write a query to find the hiked salary for each employee after adding the commission.
SELECT EMPNO, ENAME, NVL2(COMM, SAL+COMM, SAL) AS HIKEDSAL FROM EMP;Since the commission column contains null values so directly adding it to salary will return null wherever the commission is null.
Use NVL2() function to determine hiked salary based on whether the commission is null or not null. If COMM (expr1) is not null then it returns SAL+COMM (expr2). If COMM is null then it returns SAL (expr3).
Output –

Q59. Write a query to find out the employees drawing a higher salary than their managers.
SELECT E.EMPNO, E.ENAME, E.SAL, M.EMPNO, M.ENAME, M.SAL FROM EMP E, EMP M WHERE E.MGR = M.EMPNO AND E.SAL > M.SAL;Self join the emp table with itself to compare employees’ salary with their manager’s salary.
Output –

Q60. Write a query to find out the subordinates (reportees) who joined the organization before their managers.
SELECT E.EMPNO, E.ENAME, E.HIREDATE, M.EMPNO, M.ENAME, M.HIREDATE FROM EMP E, EMP M WHERE E.MGR = M.EMPNO AND E.HIREDATE < M.HIREDATE;Self join the emp table with itself to compare employees hiredate with their manager’s hiredate.
Output –

Q61. Write a query to find out the employees who don’t have any subordinates (reportees) i.e. the employees who are not the managers.
Answer:
SELECT * FROM EMP WHERE EMPNO NOT IN (SELECT DISTINCT NVL(MGR, 0) FROM EMP);
Using simple subquery first find out the list of distinct managers EMPNOs, then select the EMPNO which does not belong to managers EMPNOs.
Output –

Q62. Write a query to find out 2nd senior-most employee i.e. who joined the organization second as per hire date.
Answer:
SELECT * FROM EMP E WHERE 2 = (SELECT COUNT(DISTINCT M.HIREDATE) FROM EMP M WHERE E.HIREDATE >= M.HIREDATE);Using correlated subquery we can get 2nd senior-most employee by comparing the inner query output against 2 in WHERE clause.
Output –

Q63. Write a query to find out the 5th maximum salary.
SELECT * FROM EMP E WHERE 5 = (SELECT COUNT(DISTINCT M.SAL) FROM EMP M WHERE E.SAL <= M.SAL);Using correlated subquery we can get the 5th maximum salary by comparing the inner query output against 5 in WHERE clause.
Output

Q64. Write a query to find out the deviation from average salary for the employees who are getting more than the average salary.
Note – Round the average salary, salary difference up to two digits.
Answer:
SELECT ENAME, SAL, ROUND((SELECT AVG(SAL) FROM EMP),2) AS AVG, ROUND(SAL - (SELECT AVG(SAL) FROM EMP),2) AS DIFF FROM EMP WHERE SAL > (SELECT AVG(SAL) FROM EMP);First, select the employees who are getting more than the average salary, then calculate the deviation from average salary for such employees.
Output :

Refer to the dept table along with the above emp table for question no. 15 and 16.

Q65. Write a query to find out the employees who are getting the maximum salary in their departments.
SELECT * FROM EMP WHERE SAL IN (SELECT MAX(SAL) FROM EMP GROUP BY DEPTNO);Using simple subquery first get a list of maximum salary for each department using group by operation, then select the employees who are getting salary as per that list.
Output–

Q66. Write a query to find out department-wise minimum salary, maximum salary, total salary, and average salary.
SELECT D.DEPTNO, MIN(SAL), MAX(SAL), SUM(SAL), AVG(SAL) FROM EMP E, DEPT D WHERE E.DEPTNO = D.DEPTNO GROUP BY D.DEPTNO;First inner join employee and department table then group by DEPTNO to find out minimum, maximum, total and average salary for each department.
Output –

Q67. Consider the present table structure and desired table structure of the customer table as shown below.

Q68. Choose the correct statement(s) that will result in the desired table.
a. ALTER TABLE CUSTOMER RENAME CustName to Name;
b. ALTER TABLE CUSTOMER RENAME COLUMN CustName to Name;
c. ALTER TABLE CUSTOMER ADD Email VARCHAR2(35);
d. ALTER TABLE CUSTOMER MODIFY Email VARCHAR2(35);
e. ALTER TABLE CUSTOMER DROP FamilySize;
f. ALTER TABLE CUSTOMER DROP COLUMN FamilySize;
Answer: b, d, e
Rename CustName column as Name using –
ALTER TABLE CUSTOMER RENAME COLUMN CustName to Name;
Modify Email column datatype from VARCHAR2(25) to VARCHAR2(35) using –
ALTER TABLE CUSTOMER MODIFY Email VARCHAR2(35);
Drop FamilySize column using –
ALTER TABLE CUSTOMER DROP FamilySize;
Q69. Consider the following table schema and data for the transaction table.

Choose the valid UPDATE statement(s)
a. UPDATE TRANSACTION SET PrimeStatus = ‘Yes’ WHERE TransactionID = 1102348
b. UPDATE TRANSACTION SET PrimeStatus = ‘VALID’ WHERE CustName = ‘John’
c. UPDATE TRANSACTION SET TransactionID = NULL WHERE CustName = ‘John’
d. UPDATE TRANSACTION SET ShoppingDate = NULL WHERE TransactionID = 1102348
Answer: d
CHECK constraint allows only a set of predefined values so here only Y or N is allowed for PrimeStatus column.
NOT NULL constraint does not allow NULL values so TransactionID can’t be set to NULL.
We can insert NULL values in ShoppingDate Column.
Output –
UPDATE TRANSACTION SET ShoppingDate = NULL WHERE TransactionID = 1102348;

Q70. What is(are) the output of the following SQL statement?
SELECT TRANSLATE('AWESOME', 'WOE', 'VU') FROM DUAL;a. AVESUME
b. AVSOM
c. AVSUM
d. AWESUME
Answer: c
For an input string, TRANSLATE() function replaces characters specified in from_string argument by their corresponding characters in to_string argument. If there are no corresponding characters in to_string argument then the extra characters present in from_string argument are removed from the input string.
SELECT TRANSLATE('AWESOME', 'WOE', 'VU') FROM DUAL;Output –

Q 71. Consider the emp and insurance table as shown below.

How do you get the following output?

a. SELECT * FROM EMP1 LEFT JOIN INSURANCE ON (EMP1.INSURANCETYPE = INSURANCE.INSURANCETYPE);
b. SELECT * FROM EMP1 JOIN INSURANCE ON (EMP1.INSURANCETYPE = INSURANCE.INSURANCETYPE);
c. SELECT * FROM EMP1 RIGHT JOIN INSURANCE ON (EMP1.INSURANCETYPE = INSURANCE.INSURANCETYPE);
d. SELECT * FROM EMP1 FULL JOIN INSURANCE ON (EMP1.INSURANCETYPE = INSURANCE.INSURANCETYPE);
Answer: c, d
Right join returns all the records from the right table along with the matched records from the left table.

Here, since all the emp (left) table’s insurance types are present in the insurance (right) table so full outer join will also return the same output.
NOTE – While analyzing the outputs, focus on the record values rather than their sequence in the output.

Conclusion
In conclusion, mastering SQL interview questions is essential for anyone seeking a database management or data analytics role. Whether navigating the fundamentals for beginners, tackling intermediate challenges involving joins and subqueries, or demonstrating advanced optimization and performance tuning skills, a solid understanding of SQL is a key asset. The ability to confidently answer interview questions showcases technical expertise and reflects problem-solving skills crucial in the dynamic world of data-driven decision-making.
A Data Science professional with 7.5 years of experience in data science, machine learning, and programming. Hands-on experience in different domains like data analytics, deep learning, big data, and natural language processing.






I completely agree with your statement that SQL skills are highly preferred and required in the current job market. With the rise of data-driven decision-making, the demand for professionals who can effectively interact, query, and manage relational databases has significantly increased. I appreciate these coding interview questions. It's always nice to read as a refresher.
I agree with you that SQL skills are highly sought after in the current job market. With the rise of data-driven decision-making, the demand for professionals who can effectively interact, query, and manage relational databases has significantly increased. I appreciate these coding interview questions. It’s always nice to read as a refresher.