Creating a collaborative, data-driven culture is one of the most important goals of many modern organizations. A data-driven culture is when data is used to make decisions at every level of the organization. A data-driven culture is about replacing the gut feeling to make decisions with facts.
However, access to the data and data processing tools remain restricted to the selected few technical users or upper management echelons.
“On average, people should be more skeptical when they see numbers. They should be more willing to play around with the data themselves.” — Nate Silver, founder, and editor in chief of FiveThirtyEight.
Data-driven culture cannot exist without the democratization of the data. Data democratization certainly does not mean unrestricted access to all the organizational data. The aim of data democratization is that the data that can help an employee make an effective business decision should be available to them in a usable format, fast enough to access, and not require them to be a technical data expert to make sense of it.
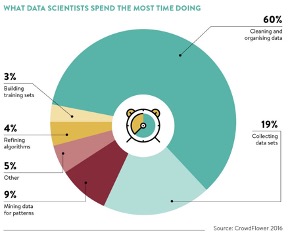
Below is the survey result of where do data scientists spend most of their time:
On average, data scientists spend almost 80% of their time in data preparation. Is it a good use of their time, though?
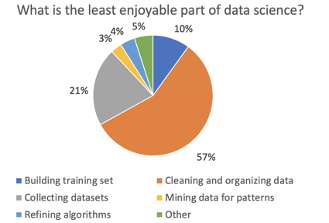
Despite spending most of their time on the data preparation tasks, most data scientists find these tasks the least enjoyable part of their job. This observation is coming from one of the most technically advanced communities of data users. Understandably, people want insights from the data but have to spend too much time in data preparation itself, thus hindering the propagation of a data-driven culture.
Can centralized Data Engineering Services help in Data Democratization?
To overcome this issue, traditionally, organizations have tasked a centralized data engineering team to create an enterprise-level data warehouse or a data lake. Analysts can then plug into this central data store to get insights. However, this model of data delivery is currently under strain. Let me paint a situation for you:
Just imagine that one needs an additional metric to complete their data analysis. However, to this metric requires additional data to be processed in the data warehouse.
To get this serviced by a centralized data engineering team employee need to wait for their turn even if it is a minor change that the they are capable to write themselves
There are three main issues with the centralized data engineering services:
- The tailor-made design and delivery model is not scalable
- When a centralized team has to write business logic within data pipelines, the ownership of the business logic gets diluted.
- As data pipelines are supposed to extract data from the source and also need to transform the data based on the business rules, these pipelines can become highly susceptible to the changes happening at both the source and the target ends. This tight coupling between source and target pushes up the maintenance cost of the data pipelines many times.
How can the Data Engineering Teams Achieve Scale?
Interestingly, the solution to the scalability of the tailor-made delivery model also comes from the same fashion industry — Readymade garments.
Fashion companies produce readymade garments in various standard fits and sizes as ready products. However, if a customer still needs minor customization, she can always get it done at a fraction of the cost and the time compared to a bespoke solution from scratch.
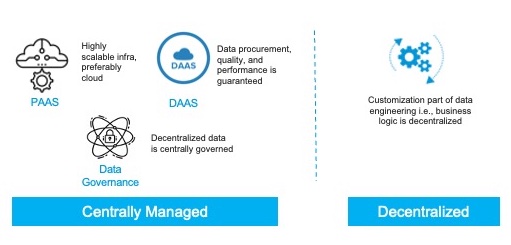
Building on a similar analogy, Data engineering teams too can achieve scale by centrally managing the heavy-technical aspects while establishing technology, process, and people practices for enabling the minor customizations to be done by the business users in the self-service model. Let us see what the components which can be centrally delivered as a managed service are:
- Platform-As-A-Service (PAAS/ SAAS) — The infrastructure to create data pipelines and perform analytics is centrally managed. It should ideally include the tools and applications as well. The platform should be highly scalable and should preferably be cloud-based
- Data-As-A-Service (DAAS) — Data procurement, data quality, and the performance are managed centrally by creating a centralized Data Lakehouse as a product
- Data Governance — Data governance takes a much more central stage in the decentralized delivery model because every governance lapse can be amplified by the number of users who can also directly manipulate the data. The data engineering team needs a renewed focus on quality, access, lineage, cataloging, etc., before the access to the data can be opened up for the whole organization.
The only component that we plan to decentralize is the business-logic component of the previous data pipelines. The domain-specific business logic component should be decentralized to handle the technical users closer to the domain, such as data analysts and data scientists.
Conclusion
Organizations struggle to propagate data-driven culture due to below significant challenges:
- Access to the data is limited
- If access is available, then it is in the read-only format via reports, etc., thus limiting the playing-with-data aspect, which is essential for data democratization.
- Access to the raw data does not democratize it as too much time is spent in the repetitive and redundant tasks of data preparation itself.
- Centralized data engineering teams suffer scalability challenges due to tailor-made delivery models.
One way to promote data-driven culture can be by promoting a hybrid data delivery model. The hybrid delivery model can promote data democratization by providing self-service of business logic while centrally managing the heavy-lifting of the data preparation.
The modern data stack is the driving force behind this concept of the hybrid data-delivery model. We will look into the technical details on how to achieve this by leveraging the right tool and the architecture in the upcoming articles.
“We are now into an era where big data is the starting point, not the end” – Pearl Zhu, Digital Master Series
With the modern data stack, we are
at the inflection point where end-user enablement is the necessity and not just a wishlist for a truly data-driven culture.
Please reach out to me on Linkedin for further conversations.
If you enjoyed reading this article, don’t forget to follow me. Feedback is welcome!
Many thanks!
Reference:
- https://www.linkedin.com/pulse/20141118145642-24928192-predictably-inaccurate-big-data-brokers/
- https://visit.figure-eight.com/rs/416-ZBE-142/images/CrowdFlower_DataScienceReport_2016.pdf
- https://www.researchgate.net/figure/Time-consuming-activities-of-data-science-5_fig1_343441512
- https://aryng.com/blog/blogmain/what-is-data-driven-culture-and-how-to-develop-it/#:~:text=But%20what%20is%20data%2Ddriven,decisions%20with%20facts%20and%20assumptions.
- https://www.goodreads.com/work/quotes/43583663-digital-master
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Aman is a Senior Data Engineering Manager at Akamai, responsible for Enterprise Data Warehouse and enabling BI and analytics. He talks about Data democratization, Data-driven culture, and Engineering Management.
Aman is a data democratization enthusiast and advocates the enablement of citizen data analysts through modern technologies.