This article was published as a part of the Data Science Blogathon.
Introduction to Data Engineering
In recent days the consignment of data produced from innumerable sources is drastically increasing day-to-day. So, processing and storing of these data has also become highly strenuous. Emerging technologies such as Data Engineering, Artificial Intelligence and Machine learning algorithms help us to handle these data intelligently and make them useful for business needs. This article concentrates much on the steps in Data Engineering and how it is performed with Real Life examples. The process of data engineering is to make the data available and accessible to the data-driven jobs and this can be achieved via ETL (extract, transform, and load) pipelines.
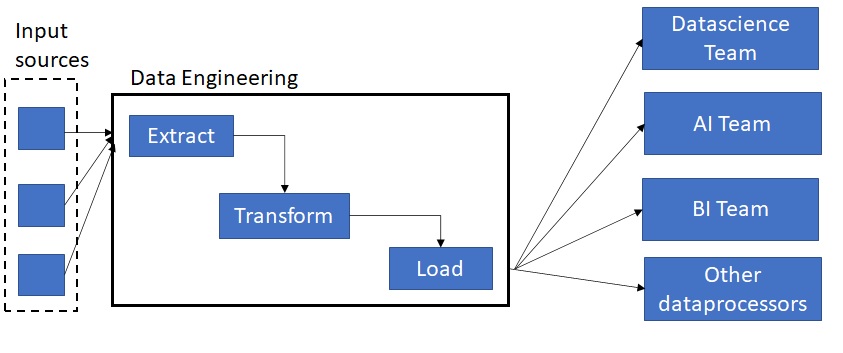
Data Extraction
so, the first step in data engineering is to extract the data from various sources like IoT devices or some batches of videos uploaded periodically or medical reports etc. The data could be of any type but the aim here is to take the data reliably and process it.
Data Transformation
After extraction, we do preprocess the data to convert it to the required format. Because the data from various sources will not always fit for querying and analysis. So, we’re modifying it to make it in a more suitable format. In the Transform stage of the ETL pipeline, we do the following steps usually,
1) Normalization and Modeling
2) Data cleaning
Normalizing the data helps to make it more accessible to the users. Also, this can be achieved in 3 major steps,
· Removing duplicate data.
· Handling and fixing the conflicts in the data.
· Making sure the data is in the specified data model.
Some more steps can also be added here but these are the major steps involved in data normalization.
Then, Data cleaning is associated with data normalization but the main difference here is that data cleaning will include some steps to make the data more uniform and complete while the data normalization focuses only on making the heterogeneous data fit into some data model.
So, below are the some of the major steps involved in data cleaning,
· Typecasting the data if required.
· Keeping all the date and time fields in the same format.
· Elimination of corrupt or unusable data.
· Identifying the missing fields and fill the appropriate data if possible.
Data Storage
After doing the transform, the next step of the ETL pipeline is load. Here we do store the transformed data in a particular location and in a specified format for the better accessibility of the users. These modified data will be stored in Data Lakes and Data Warehouse usually.
Where the data will be stored in data lakes immediately after extraction as raw data. It gives high agility to the data processing as it is not limited to the data warehouse’s fixed configuration. Also, unprocessed data will be used by the data scientists for doing an exploratory data analysis.
On the other hand, a Data warehouse is a central repository where the data is stored in the query-able form. A data warehouse can be able to store both structured and unstructured data which include various file formats like PDFs, images, audio, and video files.
Batch Processing Pipeline
Nowadays data Engineers are mainly using Lambda Architecture for processing real-time data.
Lambda Architecture(LA) helps to support Unified pipelines and real-time data processing. LA is designed based on 3 Layer (Batch Layer, Serving Layer and Speed Layer) that helps to process the real-time data based on batch processing or stream processing method with a hybrid approach.
Batch Layer:
The main work of this layer is to Manage the master Dataset and Pre-compute the batch views. So, whatever data comes will be fed into the batch layer as well as the Speed Layer which will help the real-time processing.
Serving Layer:
This layer takes the near real-time views from the speed layer and the batch views which come from the batch layer and indexes them. These Indexes are queryable formats of the latest batch views.
Speed Layer:
This layer creates a real-time view of recent data to provide a complete view of the data for the user to process.
Stream Data Pipeline
Since the data engineering field has grown significantly, there is a huge demand for engineers to work in the traditional batch processing method. Nowadays many organizations are following multiple batch processing while few organizations started working on stream processing data pipelines. This is mainly because of the complexity of issues involved in the stream processing method to work as expected. These complexities have been overcome with the introduction of powerful and easy-to-use frameworks such as Apache Flink, Apache Spark, etc.
Example:
Let us consider a real-time scenario that helps us get a better understanding of the field of data engineering. For example, we will consider a paid website provider with millions of users who sign in and use the services in their accounts such as Netflix, Amazon Prime, etc. But what if multiple users from different countries use the same account and password, this will lead to a huge loss for the company that is providing the services. So, that company wants to avoid this fraudulent behaviour and also have a track of user behaviour such as login – logout, purchase, create and delete the account, settings change, etc.
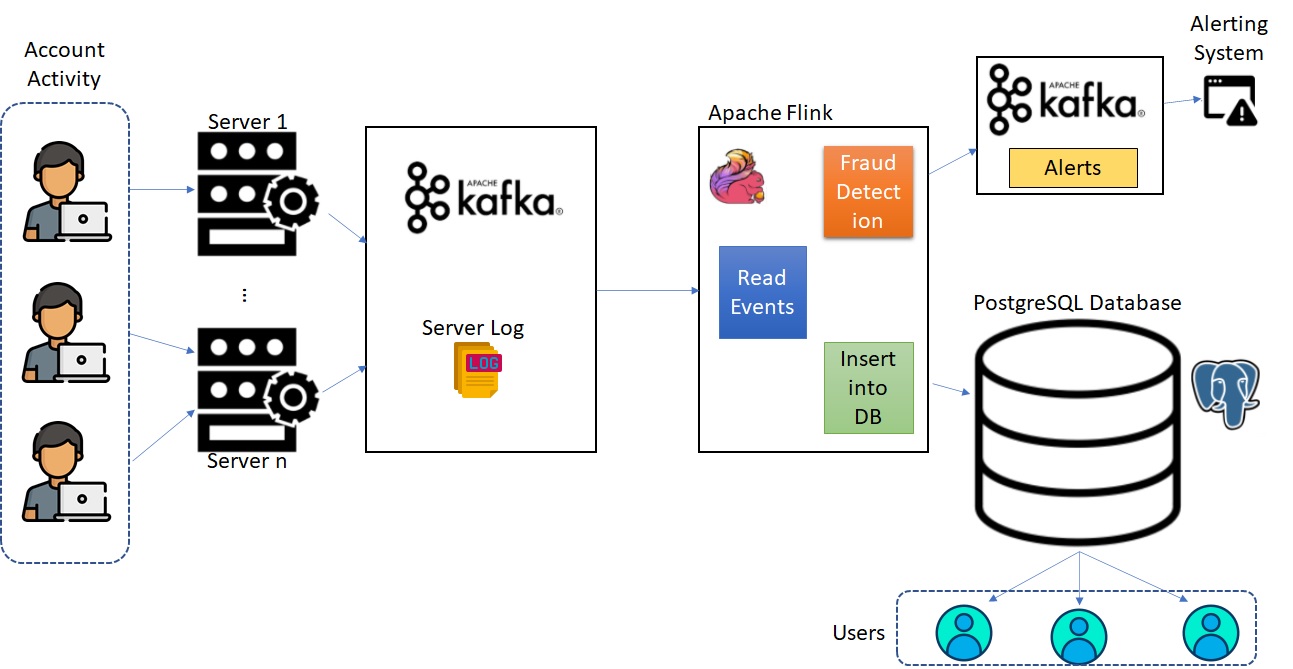
Image: Architecture for Processing Example taken
The proposed system processes the data using,
- Apache Kafka – a cluster of connected machines also called a distributed streaming platform.
- Apache Flink – a distributed processing engine which helps in the stateful processing of data.
Apache Kafka helps to receive data from various sources and store it reliably also it allows different applications to read the data in the same order in which it was received.
Apache Flink will read the events from the Apache Kafka topic and the process is to identify the fraudulent account and user action logging.
Fraudulent Account Detection:
The account can be considered a fraudulent account based on the account login history. Below are the 2 things which need to be considered while monitoring the login activity.
- location
- If one account is logged in from multiple locations at the same time then that will be considered a fraudulent account.
- But implementing this concept has more complexity in real-time because the login time recorded is from the system’s internal clock. So, we have to identify the location first and then take the internet time for that location.
- Login time
- Monitoring only the login location will help to identify if the login happens from different countries
- So, the proposed system also needs to monitor if the same account is logged in from different locations within 5 minutes then that should also be considered fraudulent activity.
So, if the fraudulent activity is found then the alert will be triggered for this event by the alerting system.
On the other hand, the recorded user actions will be loaded into the Database from the Apache Kafka topic for real-time analysis. So, the action will be taken based on the identified behavior after processing the data in Apache Flink.
Conclusion to Data Engineering
From the delineated example, we can understand the importance of data engineering to process the data efficiently and in a secure manner. The main role of data engineers is to design the pipeline in a way that we acquire the data without any loss, clean and optimize it then store it properly and make it accessible to the users from disparate divisions across the organization.
Key Takeaways from the article are listed below,
- Understanding the data engineering pipelines which will explain the steps and various methods involved in acquiring the data, preprocessing and storing it.
- various methods of processing the data from ancient times to the latest trends.
- An illustrated simple example of how data engineering is implemented in real-time.
- An overview of how the Apache Kafka platform and Apache Flink framework have made the data engineering job easier.
- Understanding the need for data engineering in the industry.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





