This article was published as a part of the Data Science Blogathon.
Introduction
Big Data is everywhere, and it continues to be a gearing-up topic these days. And Data Ingestion is a process that assists a group or management to make sense of the ever-increasing volume and complexity of data and provide useful insights. This article elucidates which cloud-based ETL tool to leverage for the data ingestion process. If you are a beginner or new to AWS and would like to explore the high-level workflow of data ingestion then keep reading!
Why AWS?
AWS is an on-demand cloud computing platform that provides several services(over 200) globally and can easily load diverse data at a rapid pace and generate cost-effective and scalable solutions for the business.
Considering the broad range of services provided by AWS, learning & gaining experience in all the services would take a lot of effort and time. So let’s talk over a few utmost priority services which are useful for data engineers to tackle today’s data challenges and complete the day-to-day tasks that cover databases, storage, analytics, and many more.
The list of topics that will be covered in three phases is as follows:
- Data sources.
- Data Ingestion.
- Data Lake.
Data Sources
Modern-day applications use and store petabytes of data. These applications should have the ability to process numerous requests and contain features like low latency, and high availability.
AWS fulfills the above needs of an application through its Database Service(DBaaS). It provides two different data sources, “Relational database services” and “Non-relational database services” which can be custom-built according to the application requirements.
Initially, the databases are set up and accessed through AWS CLI and software development kits. Later, the databases are migrated to the cloud with minimal downtime. The below table discusses the examples & advantages of each Amazon database.
| Amazon Relational Database Service(Amazon RDS) | Amazon Non- Relational Database Service |
| SQL Server, Postgre SQL, Amazon Aurora, etc. | Dynamo DB. |
| RDS is highly available in the cloud. | Unlimited throughput & storage. |
| Scalability is very simple in RDS. | Provides encryption & IAM policies. |
| RDS is accessed through the AWS console. | It is Serverless. |
| Takes frequent snapshots for backup. | Highly Durable. |
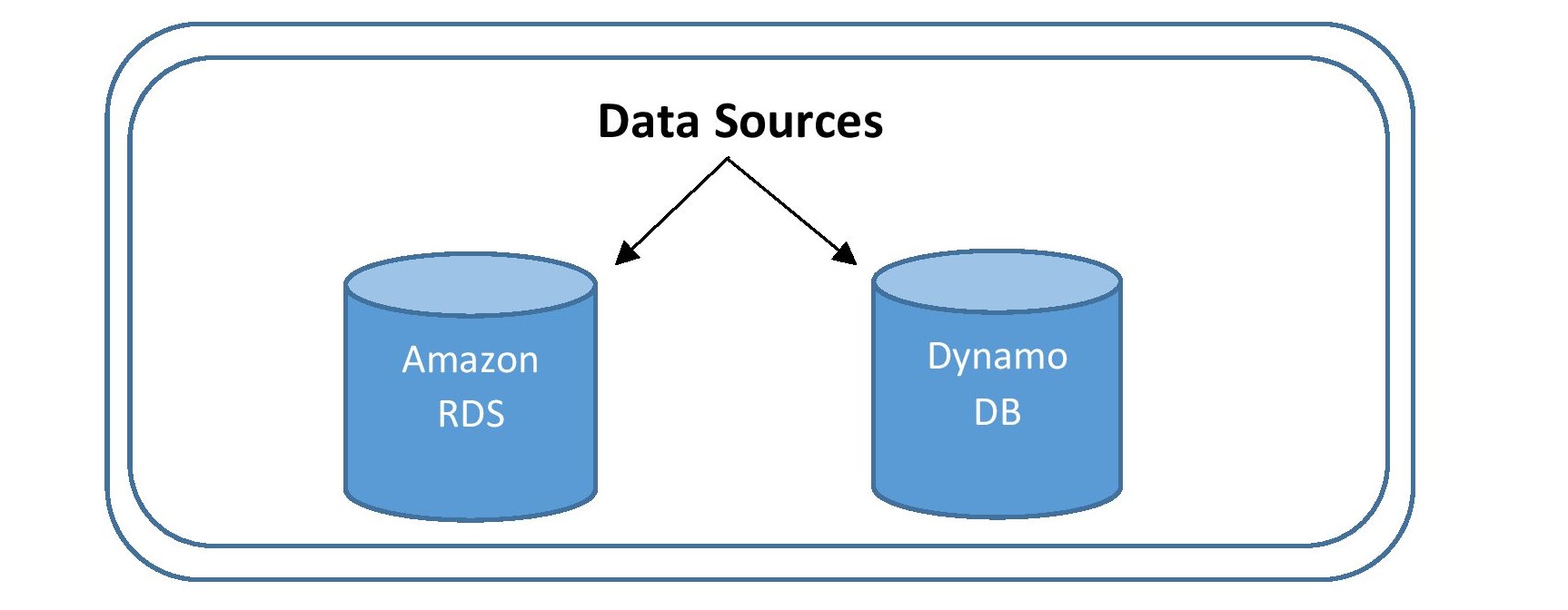
Based on the business application, the source data from the application databases are either combined or individually ingested into a central repository location for further analysis.
Here comes our next phase which is ingesting the data by a pipeline approach.
Data Ingestion
There are full of applications that generate large amounts of data today, every action of ours in the digital world will leave a trace. Considering the different types of source data, we can build two main types of data ingestion pipelines to complete the ingestion activity. They are “Batch Data Pipelines” and “Streaming Data pipelines“.
- Batch Data Pipeline: We can orchestrate, ingest, and build batch data pipelines using EMR clusters, AWS Glue, and Lambda functions.
- Streaming Data Pipeline: We can capture, and store continuous(real-time) generation of data and build stream data pipelines using AWS Kinesis.
Let’s learn about one of the widely used services from above.
Elastic Map Reduce(EMR) for Batch Data
Amazon EMR runs on dynamically scalable EC2 clusters and provides a managed Hadoop ecosystem. EMR can move data in and out of Amazon databases and data stores like Amazon S3 and Dynamo DB.
EMR in Detail, Clusters, and Nodes:
Amazon EMR follows a master-slave architecture that involves clusters and nodes. Here master refers to the “Master Node” and slaves are the “Core nodes”.
Let’s dive into the concept.
Now, What are clusters and nodes?
A cluster is a collection of multiple EC2 instances & each EC2 instance is described as a node. There are three types of nodes, each is different depending on its role.
>> Master Node: This node is for storing data in HDFS and assigning the tasks to core nodes. There will be only a single Master node.
>> Core Node: This node is equipped with certain software components that run and store data to HDFS. There should be at least one core node in a cluster.
>> Task Node: This node is similar to core nodes but does not store data to HDFS and is an optional node.
Cluster life cycle:
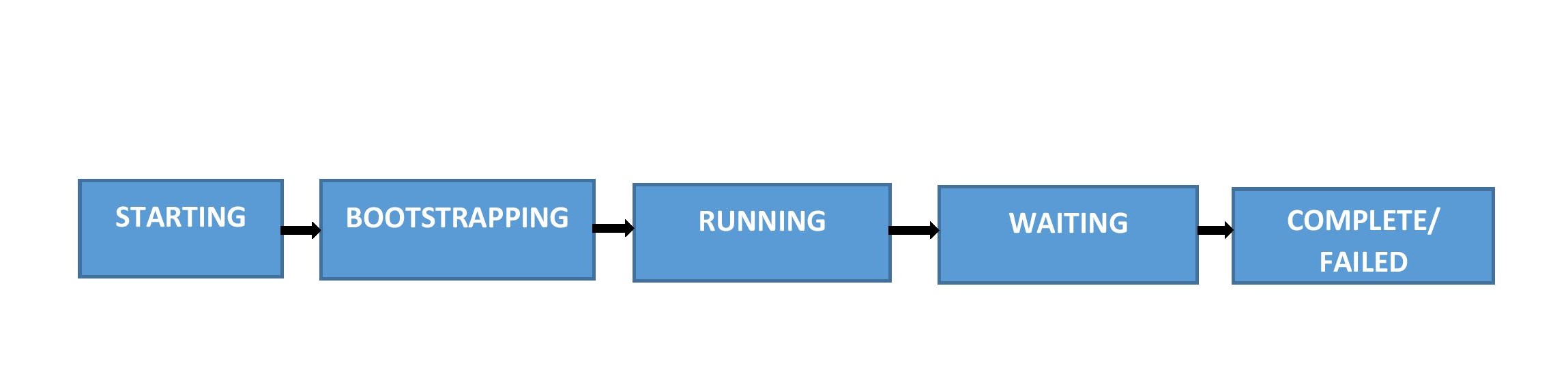
Lifecycle of a cluster on EMR.
Amazon EMR Security:
Elastic Map Reduce provides several ways to secure the EMR clusters and data by:
a.) IAM Policies: By creating IAM users and assigning policies you can restrict the access to users from performing unnecessary actions.
b.) IAM Roles: Using these roles we can enable or restrict EMR access to other services in AWS.
c.) Data Encryption: Data in S3, cluster instance, and in-transit data can be encrypted using your keys or AWS-provided encryption.
AWS Kinesis for Stream Data
Analyzing the data in real-time and producing insights is a better service to the user by knowing the user behavior and trends. This data is so massive that TBs per hour is generated and is to be processed, stored, and analyzed. AWS Kinesis is such a platform that helps in working with streaming data.
Kinesis in Detail:
>> Kinesis is a fully managed service that does not involve taking care of underlying infrastructure.
>> Processing can be started once the data stream has begun, instead of waiting for the data to be accumulated.
>> Processed records(data) are sent to dashboards and used to generate alerts, and dynamically change pricing.
Let’s discuss the types of AWS Kinesis and their capabilities to achieve different tasks.
a.) Kinesis Data Streams: A data streaming technology that allows a user to ingest, process, store and analyze high volumes of high-velocity data from a variety of sources in real-time.
b.) Kinesis Data Firehose: This service is used to load massive streaming data into services like S3, elastic search, Splunk, and Redshift.
c.) Kinesis Data Analytics: Due to the growth of devices and internet usage the data is being streamed at a rapid pace. So, by looking into real-time data, you can monitor your business quickly and leverage new opportunities. To serve this we have kinesis data analytics.
d.) Kinesis Video streams: Helps you to stream videos in real-time from hundreds of camera devices to the AWS cloud, where you can watch, store ML operations, real-time analytics, and get insights.
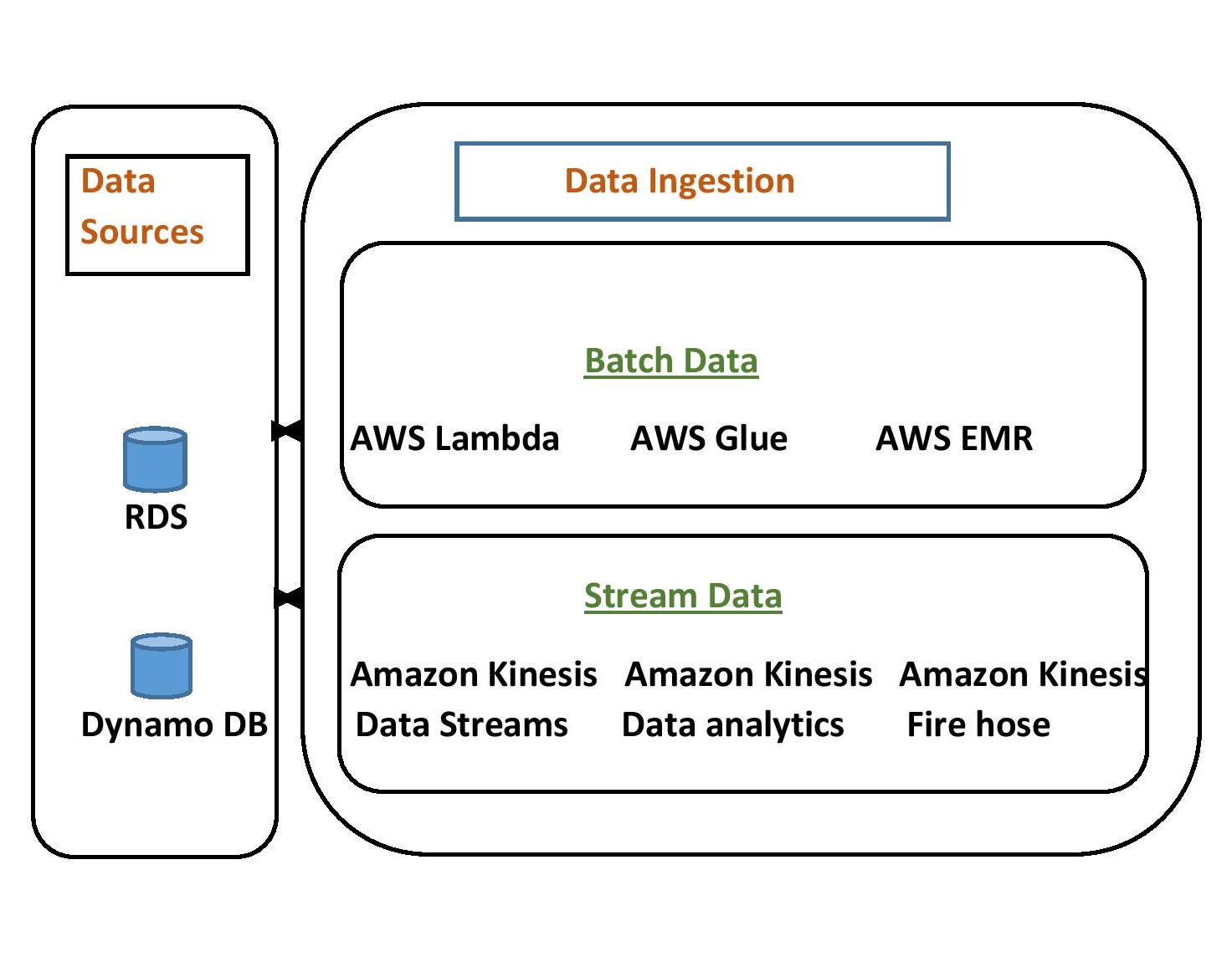
Data Ingestion Process workflow
Till now we have discussed what services are used to ingest the data, let’s move to the next phase and talk about the services that are used to store the data.
Data Lake
As the concept of a data lake emerges, we use a storage service named Amazon S3 to categorize and maintain data in a data lake.
Amazon Simple Storage Service (Amazon S3):
Amazon S3 can be described as an object storage(every file loaded in S3 is served as an object) service that stores and retrieves any amount of data from anywhere on the web.
To store the data in S3, you work with two resources called “Buckets” and “Objects“.
What is a Bucket & Object?
A bucket is defined as the storage of objects. An object is a file and metadata that describes the file.
Steps for storing & processing the data:
Step 1 – Firstly, data is stored as “Raw” in a single bucket. The Raw Bucket has the original data which is not ready for analysis. We can call this region a Raw Layer.
Step 2 – Then you have to query the data to clean up, find and remove the duplicates, and check for the missing records with the help of several services like AWS Lambda, EMR, and AWS glue to process the data further.
Step 3 – After the processing is finished the data is written back into a “Processed” bucket which is ready to perform the analysis. This region can be named Processed Layer.
Step 4 – Finally the datasets are transferred to a central catalog named “Glue catalog”. This can be achieved by making use of glue crawlers or code depending on the application. Glue catalog keeps track of where the datasets in object location, S3, schema information, and bio classification.
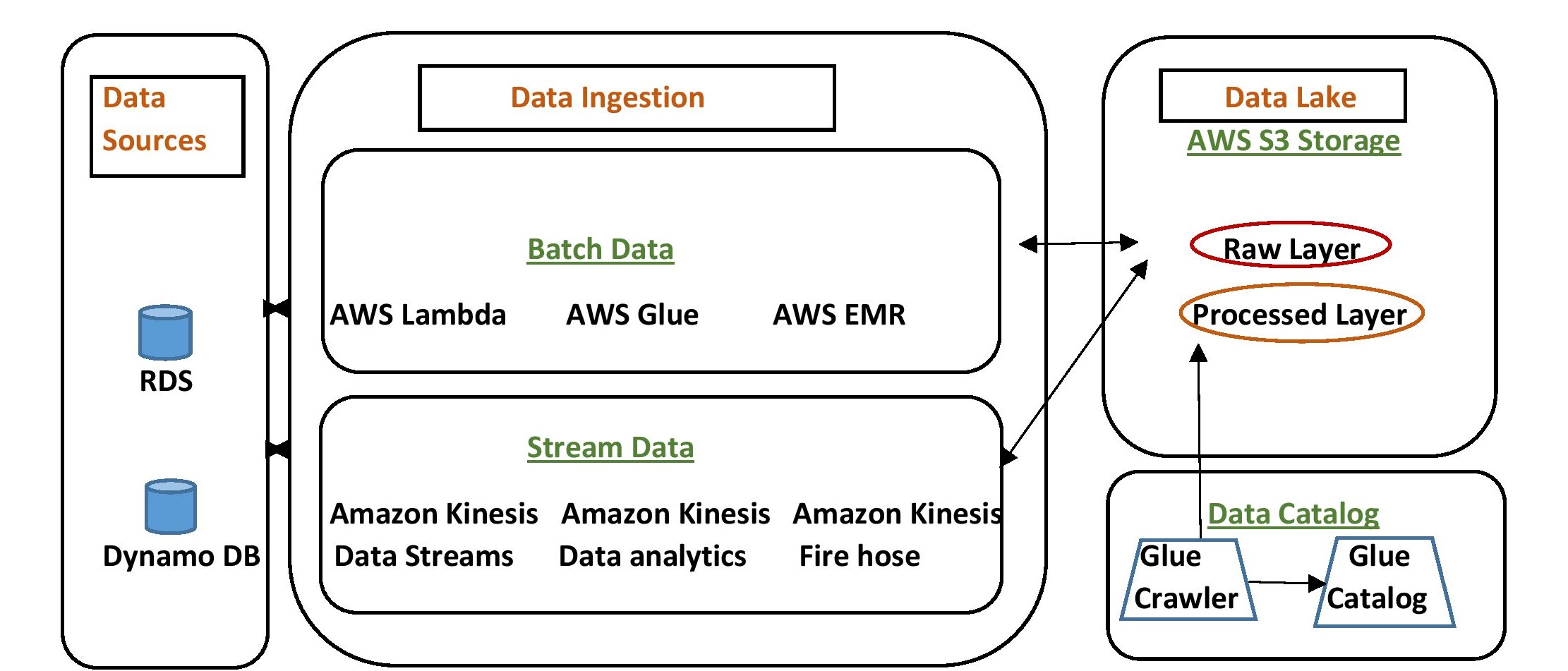
Follow the best practices mentioned below while creating a bucket of a particular data lake built on Amazon S3.
a.) Buckets names must be unique with partitions.
b.) Should be compliant with DNS naming conventions.
c.) Use a different AWS account to store production S3 Buckets.
d.) Enable the versioning to protect from deletions.
e.) Create separate buckets for replicated data.
Miscellaneous Definitions
>> EC2: A service that provides a scalable capacity to compute in the cloud.
>> AWS Lambda: A Serverless compute service which is used to run the background tasks.
>> AWS Glue: A data integration service that makes it simple and cost-effective to categorize and clean the data from several sources.
>> Glue Crawler: You run the Glue crawlers periodically to populate the updated data(tables) into Glue Catalog.
>> IAM: Identity and Access management provides access control across all the services and resources.
Conclusion
To implement the ingestion solution, the above compute and storage services like Amazon RDS, Amazon Dynamo DB, Amazon EMR, and Amazon S3 are employed without having to pay large sums of money.
A few key takeaways for data ingestion:
> DynamoDB outweighs RDS in terms of table storage size.
> EMR helps in scaling the running clusters depending on the workloads.
> We can manually spin up and terminate a cluster or schedule the provisioning.
> Use the right Kinesis service according to its capability
> Once the objects in the buckets are cleaned(deleting all the versions of objects), it cannot be undone.
> Ensure you have a backup of the incoming data and provide bucket data access only to the owners by using Amazon IAM.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Pursuing a Master's in Data Analytics Engineering from Northeastern University. With a Bachelor's in Computer Science, I possess a strong foundation in programming, data structures, and software engineering. I have professional experience as an Assistant Data Engineer at Tata Consultancy Services, where I maintained ETL pipelines, automated workflows, and ensured high uptime of AI tools on AWS with Agile Management. I have also completed several data-driven projects leveraging machine learning algorithms and data visualization techniques. With excellent problem-solving skills and attention to detail, I strive to contribute to data-driven solutions that make a positive impact on society.





