This article was published as a part of the Data Science Blogathon.
Introduction
Data science interviews consist of questions from statistics and probability, Linear Algebra, Vector, Calculus, Machine Learning/Deep learning mathematics, Python, OOPs concepts, and Numpy/Tensor operations. Apart from these, an interviewer asks you about your projects and their objective. In short, interviewers focus on basic concepts and projects.
This article is part 1 of the data science interview series and will cover some basic data science interview questions. We will discuss the interview questions with their answers:
What is OLS? Why, and Where do we use it?
OLS (or Ordinary Least Square) is a linear regression technique that helps estimate the unknown parameters that can influence the output. This method relies on minimizing the loss function. The loss function is the sum of squares of residuals between the actual and predicted values. The residual is the difference between the target values and forecasted values. The error or residual is:
Minimize ∑(yi – ŷi)^2
Where ŷi is the predicted value, and yi is the actual value.
We use OLS when we have more than one input. This approach treats the data as a matrix and estimates the optimal coefficients using linear algebra operations.
What is Regularization? Where do we use it?
Regularization is a technique that reduces the overfitting of the trained model. This technique gets used where the model is overfitting the data.
Overfitting occurs when the model performs well with the training set but not with the test set. The model gives minimal error with the training set, but the error is high with the test set.
Hence, the regularization technique penalizes the loss function to acquire the perfect fit model.
What is the Difference between L1 AND L2 Regularization?
L1 Regularization is also known as Lasso(Least Absolute Shrinkage and Selection Operator) Regression. This method penalizes the loss function by adding the absolute value of coefficient magnitude as a penalty term.
Lasso works well when we have a lot of features. This technique works well for model selection since it reduces the features by shrinking the coefficients to zero for less significant variables.
Thus it removes some features that have less importance and selects some significant features.
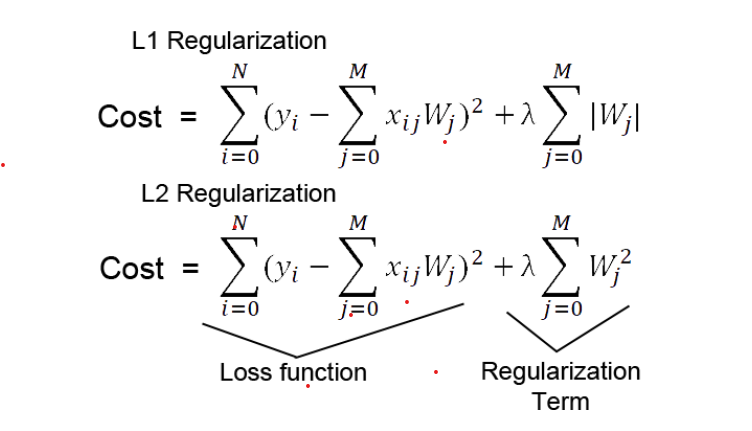
L2 Regularization( or Ridge Regression) penalizes the model as the complexity of the model increases. The regularization parameter (lambda) penalizes all the parameters except intercept so that the model generalizes the data and does not overfit.
Ridge regression adds the squared magnitude of the coefficient as a penalty term to the loss function. When the lambda value is zero, it becomes analogous to OLS. While lambda is very large, the penalty will be too much and lead to under-fitting.
Moreover, Ridge regression pushes the coefficients towards smaller values while maintaining non-zero weights and a non-sparse solution. Since the square term in the loss function blows up the outliers residues that make the L2 sensitive to outliers, the penalty term endeavors to rectify it by penalizing the weights.
Ridge regression performs better when all the input features influence the output with weights roughly equal in size. Besides, Ridge regression can also learn complex data patterns.
What is R Square?
R Square is a statistical measure that shows the closeness of the data points to the fitted regression line. It calculates the percentage of the predicted variable variation calculated by a linear model.

The value of R-Square lies between 0% and 100%, where 0 means the model can not explain the variation of the predicted values around its mean. Besides, 100% indicates that the model can explain the whole variability of the output data around its mean.
In short, the higher the R-Square value, the better the model fits the data.
Adjusted R-Squared
The R-square measure has some drawbacks that we will address here too.
The problem is if we add junk independent variables or significant independent variables, or impactful independent variables to our model, the R-Squared value will always increase. It will never decrease with a newly independent variable addition, whether it could be an impactful, non-impactful, or insignificant variable. Hence we need another way to measure equivalent RSquare, which penalizes our model with any junk independent variable.
So, we calculate the Adjusted R-Square with a better adjustment in the formula of generic R-square.

What is Mean Square Error?
Mean square error tells us the closeness of the regression line to a set of data points. It calculates the distances from data points to the regression line and squares those distances. These distances are the errors of the model for predicted and actual values.
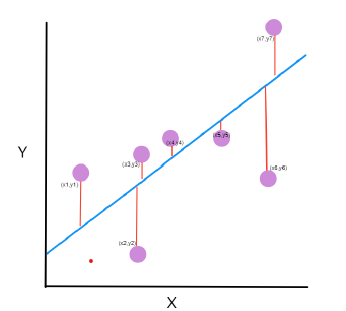
The line equation is given as y = MX+C
M is the slope, and C is the intercept coefficient. The objective is to find the values for M and C to best fit the data and minimize the error.
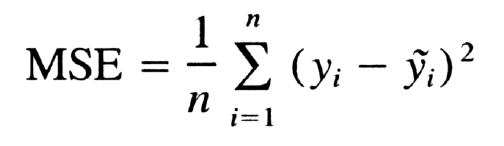
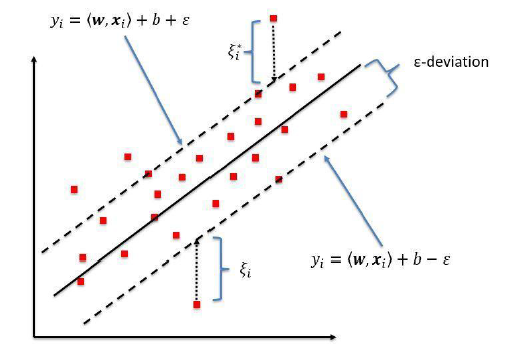
Why Support Vector Regression? Difference between SVR and a simple regression model?
The objective of the simple regression model is to minimize the error rate while SVR tries to fit the error into a certain threshold.
Main Concepts:
- Boundary
- Kernel
- Support Vector
- Hyper-plane
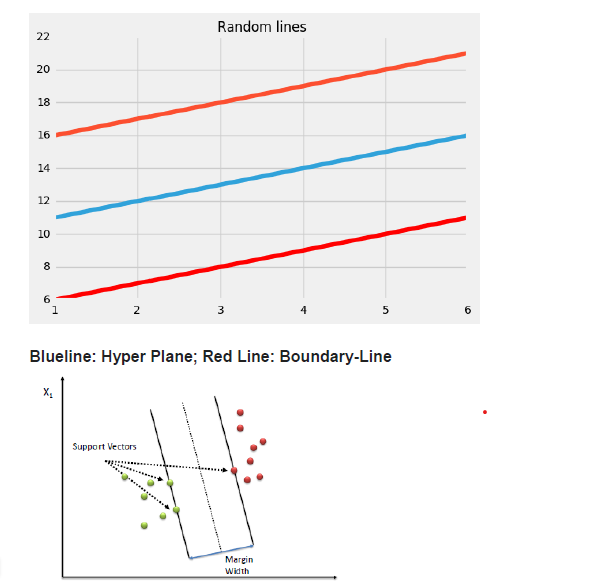
The best fit line is the line that has a maximum number of points on it. The SVR attempts to calculate a decision boundary at the distance of ‘e’ from the base hyper-plane such that data points are nearest to that hyper-plane and support vectors are within that boundary line.
Conclusion
We have covered a few basic data science interview questions around Linear regression. You may encounter any of these questions in an interview for an entry-level job. Some key takeaways from this article are as follows:
- The ordinary least squares technique estimates the unknown coefficients and relies on minimizing the residue.
- L1 and L2 Regularization penalizes the loss function with absolute value and square of the value of the coefficient, respectively.
- The R-square value indicates the variation of response around its mean.
- R-square has some drawbacks, and to overcome these drawbacks, we use adjusted R-Square.
- Mean square error calculates the distance between points on the regression line to the data points.
- SVR fits the error within a certain threshold instead of minimizing it.
However, some interviewers might dive deeper into any of the questions. If you want to dive deep into the mathematics of any of these concepts, feel free to comment or reach me here. I will try to explain that in any of the further data science interview question articles.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.






