This article was published as a part of the Data Science Blogathon.
Introduction
A few days ago, HuggingFace announced a $100 million Series C funding round, which was big news in open source machine learning and could be a sign of where the industry is headed. Two days before the HuggingFace funding announcement, open-source machine learning platform MetaSpore released a demo based on the HuggingFace Rapid deployment pre-training model.
As deep learning technology makes innovative breakthroughs in computer vision, natural language processing, speech understanding, and other fields, more and more unstructured data are perceived, understood, and processed by machines. These advances are mainly due to the powerful learning ability of deep learning. Through pre-training of deep models on massive data, the models can capture the internal data patterns, thus helping many downstream tasks. With the industry and academia investing more and more energy in the research of pre-training technology, the distribution warehouses of pre-training models such as HuggingFace and Timm have emerged one after another. The open-source community release pre-training significant model dividends at an unprecedented speed.
In recent years, the data form of machine modeling and understanding has gradually evolved from single-mode to multi-mode, and the semantic gap between different modes is being eliminated, making it possible to retrieve data across modes. Take CLIP, OpenAI’s open-source work, as an example, to pre-train the twin towers of images and texts on a dataset of 400 million pictures and texts and connect the semantics between pictures and texts. Many researchers in the academic world have been solving multimodal problems such as image generation and retrieval based on this technology. Although the frontier technology through the semantic gap between modal data, there is still a heavy and complicated model tuning, offline data processing, high performance online reasoning architecture design, heterogeneous computing, and online algorithm be born multiple processes and challenges, hindering the frontier multimodal retrieval technologies fall to the ground and pratt &whitney.
DMetaSoul
DMetaSoul aims at the above technical pain points, abstracting and uniting many links such as model training optimization, online reasoning, and algorithm experiment, forming a set of solutions that can quickly apply offline pre-training model to online. This paper will introduce how to use the HuggingFace community pre-training model to conduct online reasoning and algorithm experiments based on MetaSpore technology ecology so that the benefits of the pre-training model can be fully released to the specific business or industry and small and medium-sized enterprises. And we will give the text search text and text search graph two multimodal retrieval demonstration examples for your reference.
Multimodal semantic retrieval
The sample architecture of multimodal retrieval is as follows:
Our multimodal retrieval system supports both text search and text search application scenarios, including offline processing, model reasoning, online services, and other core modules:
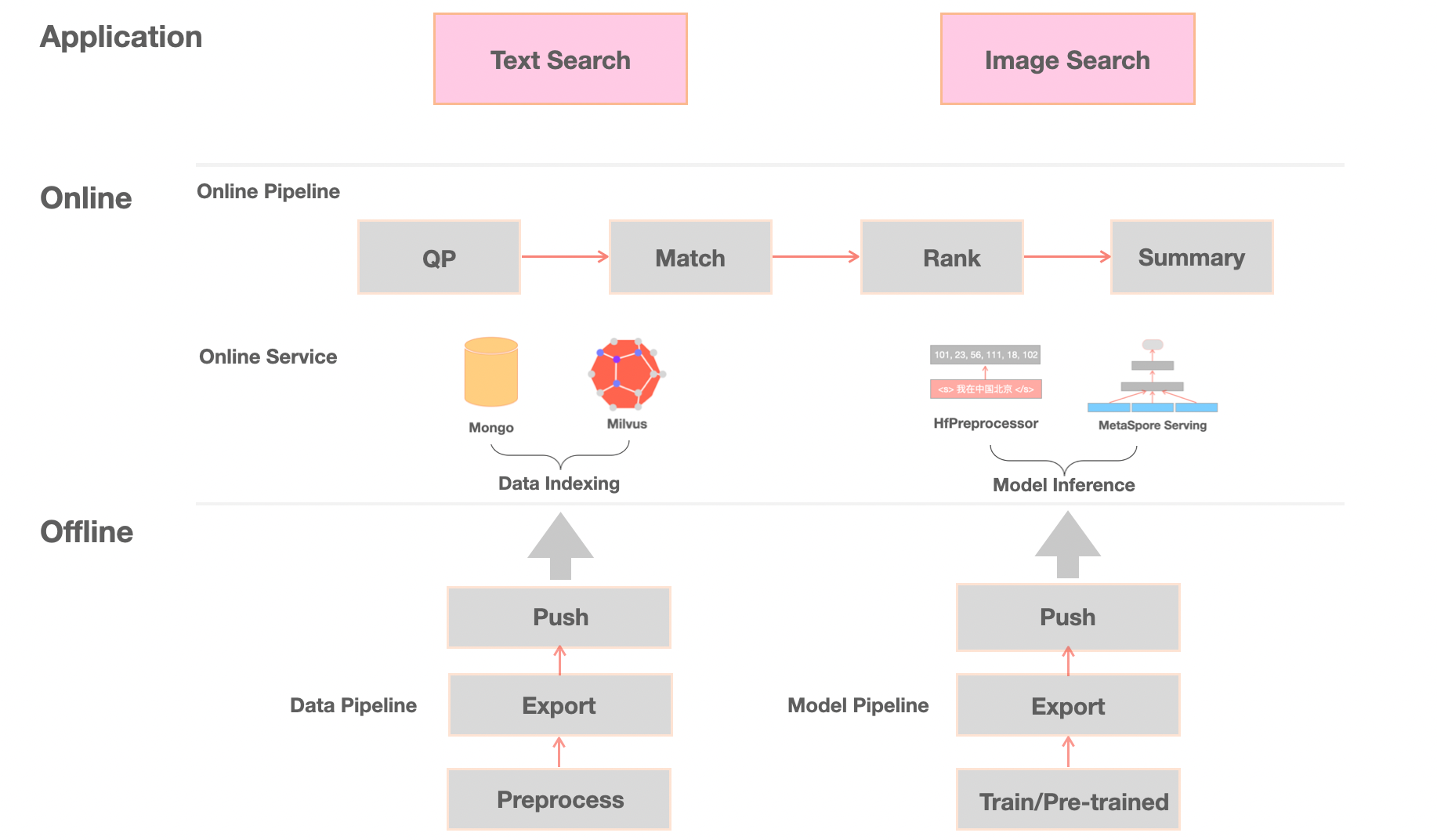
- Offline processing, including offline data processing processes for different application scenarios of text search and text search, including model tuning, model export, data index database construction, data push, etc.
- Model inference. After the offline model training, we deployed our NLP and CV large models based on the MetaSpore Serving framework. MetaSpore Serving helps us conveniently perform online inference, elastic scheduling, load balancing, and resource scheduling in heterogeneous environments.
- Online services. Based on MetaSpore’s online algorithm application framework, MetaSpore has a complete set of reusable online search services, including Front-end retrieval UI, multimodal data preprocessing, vector recall and sorting algorithm, AB experimental framework, etc. MetaSpore also supports text search by text and image scene search by text and can be migrated to other application scenarios at a low cost.
The HuggingFace open source community has provided several excellent baseline models for similar multimodal retrieval problems, which are often the starting point for actual optimization in the industry. MetaSpore also uses the pre-training model of the HuggingFace community in its online services of searching words by words and images by words. Searching words by words is based on the semantic similarity model of the question and answer field optimized by MetaSpore, and searching images by words are based on the community pre-training model.
These community open source pre-training models are exported to the general ONNX format and loaded into MetaSpore Serving for online reasoning. The following sections will provide a detailed description of the model export and online retrieval algorithm services. The reasoning part of the model is standardized SAAS services with low coupling with the business. Interested readers can refer to my previous post: The design concept of MetaSpore, a new generation of the one-stop machine learning platform.
Offline Processing
Offline processing mainly involves the export and loading of online models and index building and pushing of the document library. You can follow the step-by-step instructions below to complete the offline processing of text search and image search and see how the offline pre-training model achieves reasoning at MetaSpore.
Search text by text
Traditional text retrieval systems are based on literal matching algorithms such as BM25. Due to users’ diverse query words, a semantic gap between query words and documents is often encountered. For example, users misspell “iPhone” as “Phone,” and search terms are incredibly long, such as “1 ~ 3 months old baby autumn small size bag pants”. Traditional text retrieval systems will use spelling correction, synonym expansion, search terms rewriting, and other means to alleviate the semantic gap but fundamentally fail to solve this problem. Only when the retrieval system fully understands users’ query terms and documents can it meet users’ retrieval demands at the semantic level. With the continuous progress of pre-training and representational learning technology, some commercial search engines continue to integrate semantic vector retrieval methods based on symbolic learning into the retrieval ecology.
Semantic Retrieval Model
This paper introduces a set of semantic vector retrieval applications. MetaSpore built a set of semantic retrieval systems based on encyclopedia question and answer data. MetaSpore adopted the Sentence-Bert model as the semantic vector representation model, which fine-tunes the twin tower BERT in supervised or unsupervised ways to make the model more suitable for retrieval tasks. The model structure is as follows:
The query-Doc symmetric two-tower model is used in text search and question and answer retrieval. The vector representation of online Query and offline DOC share the same vector representation model, so it is necessary to ensure the consistency of the offline DOC library building model and online Query inference model. The case uses MetaSpore’s text representation model Sbert-Chinese-QMC-domain-V1, optimized in the open-source semantically similar data set. This model will express the question and answer data as a vector in offline database construction. The user query will be expressed as a vector by this model in online retrieval, ensuring that query-doc in the same semantic space, users’ semantic retrieval demands can be guaranteed by vector similarity metric calculation.
Since the text presentation model does vector encoding for Query online, we need to export the model for use by the online service. Go to the q&A data library code directory and export the model concerning the documentation. In the script, Pytorch Tracing is used to export the model. The models are exported to the “./export “directory. The exported models are mainly ONNX models used for wired reasoning, Tokenizer, and related configuration files. The exported models are loaded into MetaSpore Serving by the online Serving system described below for model reasoning. Since the exported model will be copied to the cloud storage, you need to configure related variables in env.sh.
Build Library Based on Text Search
The retrieval database is built on the million-level encyclopedia question and answer data set. According to the description document, you need to download the data and complete the database construction. The question and answer data will be coded as a vector by the offline model, and then the database construction data will be pushed to the service component. The whole process of database construction is described as follows:
- Preprocessing, converting the original data into a more general JSonline format for database construction;
- Build index, use the same model as online “sbert-Chinese-qmc-domain-v1” to index documents (one document object per line);
- Push inverted (vector) and forward (document field) data to each component server.
The following is an example of the database data format. After offline database construction is completed, various data are pushed to corresponding service components, such as Milvus storing vector representation of documents and MongoDB storing summary information of documents. Online retrieval algorithm services will use these service components to obtain relevant data.
Search by text
Text and images are easy for humans to relate semantically but difficult for machines. First of all, from the perspective of data form, the text is the discrete ID type of one-dimensional data based on words and words. At the same time, images are continuous two-dimensional or three-dimensional data. Secondly, the text is a subjective creation of human beings, and its expressive ability is vibrant, including various turning points, metaphors, and other expressions, while images are machine representations of the objective world. In short, bridging the semantic gap between text and image data is much more complex than searching text by text. The traditional text search image retrieval technology generally relies on the external text description data of the image or the nearest neighbor retrieval technology and carries out the retrieval through the image associated text, which in essence degrades the problem to text search. However, it will also face many issues, such as obtaining the associated text of pictures and whether the accuracy of text search by text is high enough. The depth model has gradually evolved from single-mode to multi-mode in recent years. Taking the open-source project of OpenAI, CLIP, as an example, train the model through the massive image and text data of the Internet and map the text and image data into the same semantic space, making it possible to implement the text and image search technology based on semantic vector.
CLIP Graphic Model
The text search pictures introduced in this paper are implemented based on semantic vector retrieval, and the CLIP pre-training model is used as the two-tower retrieval architecture. Because the CLIP model has trained the semantic alignment of the twin towers’ text and image side models on the massive graphic and text data, it is particularly suitable for the text search graph scene.
Due to the different image and text data forms, the Query-Doc asymmetric twin towers model is used for text search image retrieval. The image-side model of the twin towers is used for offline database construction, and the text-side model is used for the online return. In the final online retrieval, the database data of the image side model will be searched after the text side model encodes Query, and the CLIP pre-training model guarantees the semantic correlation between images and texts. The model can draw the graphic pairs closer in vector space by pre-training on a large amount of visual data.
Here we need to export the text-side model for online MetaSpore Serving inference. Since the retrieval scene is based on Chinese, the CLIP model supporting Chinese understanding is selected. The exported content includes the ONNX model used for online reasoning and Tokenizer, similar to the text search. MetaSpore Serving can load model reasoning through the exported content.
Build Library on Image Search
You need to download the Unsplash Lite library data and complete the construction according to the instructions. The whole process of database construction is described as follows:
- Preprocessing, specify the image directory, and then generate a more general JSOnline file for library construction;
- Build index, use OpenAI/Clip-Vit-BASE-Patch32 pre-training model to index the gallery, and output one document object for each line of index data;
- Push inverted (vector) and forward (document field) data to each component server. Like text search, after offline database construction, relevant data will be pushed to service components, called by online retrieval algorithm services to obtain relevant data.
Online Services
The overall online service architecture diagram is as follows:
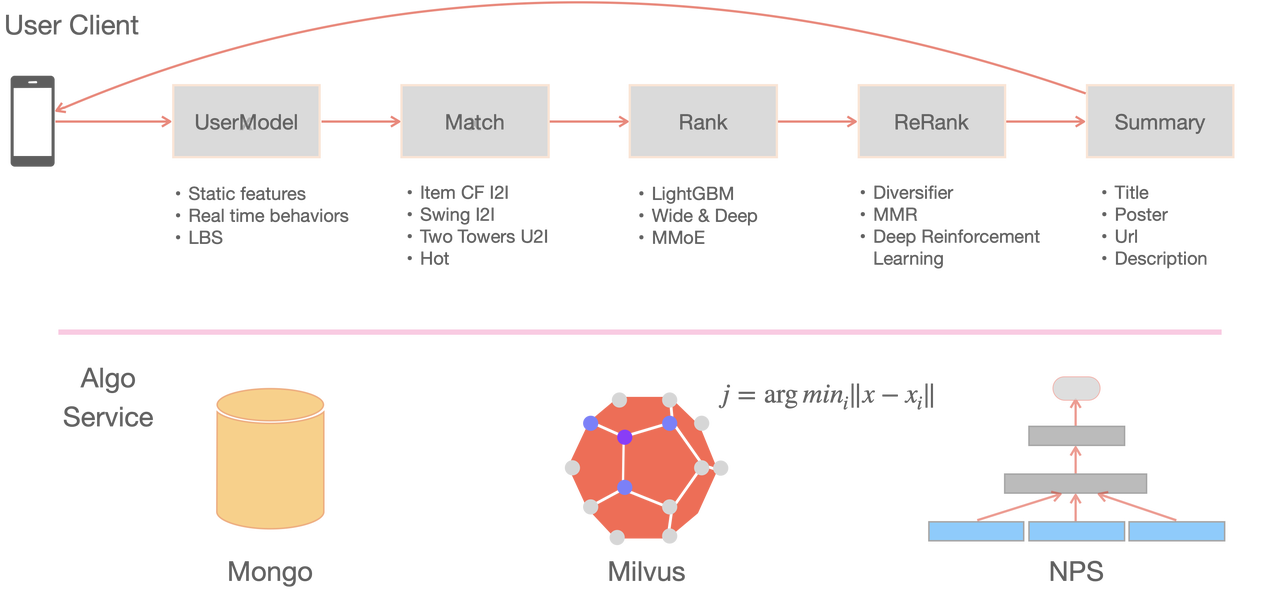
Multi-mode search online service system supports application scenarios such as text search and text search. The whole online service consists of the following parts:
- Query preprocessing service: encapsulate preprocessing logic (including text/image, etc.) of pre-training model, and provide services through gRPC interface;
- Retrieval algorithm service: the whole algorithm processing link includes AB experiment tangent flow configuration, MetaSpore Serving call, vector recall, sorting, document summary, etc.;
- User entry service: provides a Web UI interface for users to debug and track down problems in the retrieval service.
From a user request perspective, these services form invocation dependencies from back to front, so to build up a multimodal sample, you need to run each service from front to back first. Before doing this, remember to export the offline model, put it online and build the library first. This article will introduce the various parts of the online service system and make the whole service system step by step according to the following guidance. See the ReadME at the end of this article for more details.
Query preprocessing service
Deep learning models tend to be based on tensors, but NLP/CV models often have a preprocessing part that translates raw text and images into tensors that deep learning models can accept. For example, NLP class models often have a pre-tokenizer to transform text data of string type into discrete tensor data. CV class models also have similar processing logic to complete the cropping, scaling, transformation, and other processing of input images through preprocessing. On the one hand, considering that this part of preprocessing logic is decoupled from tensor reasoning of the depth model, on the other hand, the reason of the depth model has an independent technical system based on ONNX, so MetaSpore disassembled this part of preprocessing logic.
NLP pretreatment Tokenizer has been integrated into the Query pretreatment service. MetaSpore dismantlement with a relatively general convention. Users only need to provide preprocessing logic files to realize the loading and prediction interface and export the necessary data and configuration files loaded into the preprocessing service. Subsequent CV preprocessing logic will also be integrated in this manner.
The preprocessing service currently provides the gRPC interface invocation externally and is dependent on the Query preprocessing (QP) module in the retrieval algorithm service. After the user request reaches the retrieval algorithm service, it will be forwarded to the service to complete the data preprocessing and continue the subsequent processing. The ReadMe provides details on how the preprocessing service is started, how the preprocessing model exported offline to cloud storage enters the service, and how to debug the service.
To further improve the efficiency and stability of model reasoning, MetaSpore Serving implements a Python preprocessing submodule. So MetaSpore can provide gRPC services through user-specified preprocessor.py, complete Tokenizer or CV-related preprocessing in NLP, and translate requests into a Tensor that deep models can handle. Finally, the model inference is carried out by MetaSpore, Serving subsequent sub-modules.
Presented here on the lot code: https://github.com/meta-soul/MetaSpore/compare/add_python_preprocessor
Retrieval algorithm services
Retrieval algorithm service is the core of the whole online service system, which is responsible for the triage of experiments, the assembly of algorithm chains such as preprocessing, recall, sorting, and the invocation of dependent component services. The whole retrieval algorithm service is developed based on the Java Spring framework and supports multi-mode retrieval scenarios of text search and text search graph. Due to good internal abstraction and modular design, it has high flexibility and can be migrated to similar application scenarios at a low cost.
Here’s a quick guide to configuring the environment to set up the retrieval algorithm service. See ReadME for more details:
- Install dependent components. Use Maven to install the online-Serving component
- Search for service configurations. Copy the template configuration file and replace the MongoDB, Milvus, and other configurations based on the development/production environment.
- Install and configure Consul. Consul allows you to synchronize the search service configuration in real-time, including cutting the flow of experiments, recall parameters, and sorting parameters. The project’s configuration file shows the current configuration parameters of text search and text search. The parameter modelName in the stage of pretreatment and recall is the corresponding model exported in offline processing.
- Start the service. Once the above configuration is complete, the retrieval service can be started from the entry script. Once the service is started, you can test it! For example, for a user with userId=10 who wants to query “How to renew ID card,” access the text search service.
User Entry Service
Considering that the retrieval algorithm service is in the form of the API interface, it is difficult to locate and trace the problem, especially for the text search image scene can intuitively display the retrieval results to facilitate the iterative optimization of the retrieval algorithm. This paper provides a lightweight Web UI interface for text search and image search, a search input box, and results in a display page for users. Developed by Flask, the service can be easily integrated with other retrieval applications. The service calls the retrieval algorithm service and displays the returned results on the page.
It’s also easy to install and start the service. Once you’re done, go to http://127.0.0.1:8090 to see if the search UI service is working correctly. See the ReadME at the end of this article for details.
Multimodal system demonstration
The multimodal retrieval service can be started when offline processing and online service environment configuration have been completed following the above instructions. Examples of textual searches are shown below.
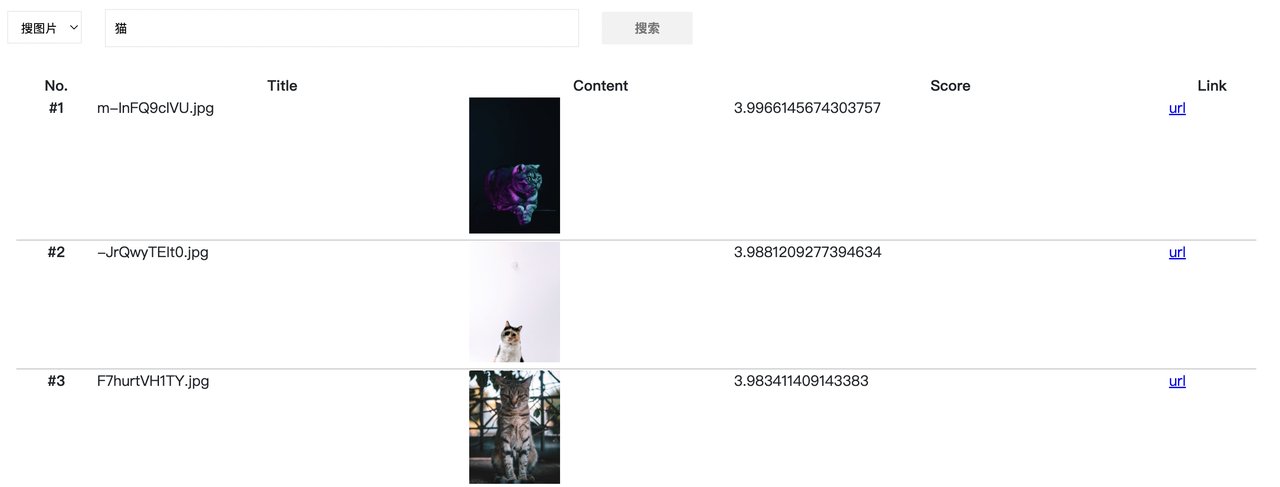
Enter the entry of the text search map application, enter “cat” first, and you can see that the first three digits of the returned result are cats:
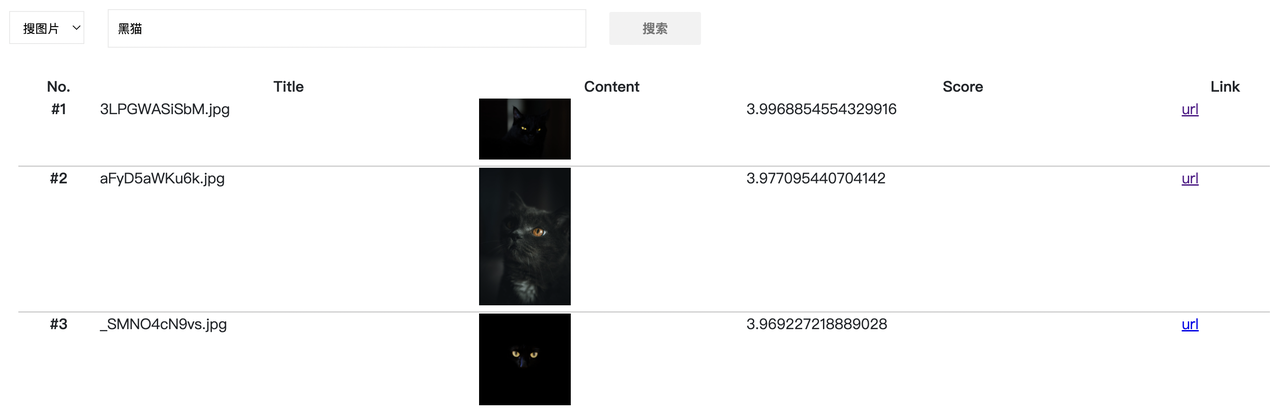
If you add a color constraint to “cat” to retrieve “black cat,” you can see that it does return a black cat:
Further, strengthen the constraint on the search term, change it to “black cat on the bed,” and return results containing pictures of a black cat climbing on the bed:
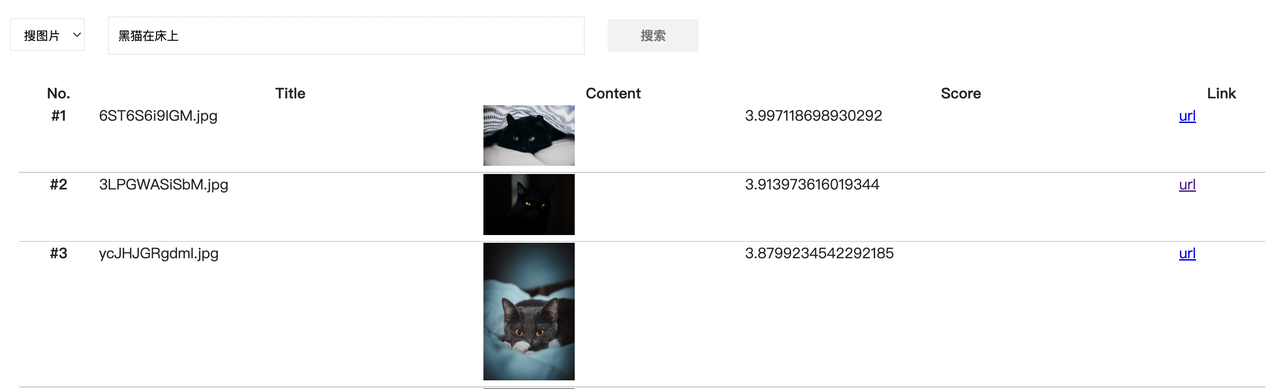
The cat can still be found through the text search system after the color and scene modification in the above example.
Conclusion
The cutting-edge pre-training technology can bridge the semantic gap between different modes, and the HuggingFace community can greatly reduce the cost for developers to use the pre-training model. Combined with the technological ecology of MetaSpore online reasoning and online microservices provided by DMetaSpore, the pre-training model is no longer mere offline dabbling. Instead, it can truly achieve end-to-end implementation from cutting-edge technology to industrial scenarios, fully releasing the dividends of the pre-training large model. In the future, DMetaSoul will continue to improve and optimize the MetaSpore technology ecosystem:
- More automated and wider access to HuggingFace community ecology. MetaSpore will soon release a common model rollout mechanism to make HuggingFace ecologically accessible and will later integrate preprocessing services into online services.
- Multi-mode retrieval offline algorithm optimization. For multimodal retrieval scenarios, MetaSpore will continuously iteratively optimize offline algorithm components, including text recall/sort model, graphic recall/sort model, etc., to improve the accuracy and efficiency of the retrieval algorithm. For related code and reference documentation in this article, please visit https://github.com/meta-soul/MetaSpore/tree/main/demo/multimodal/online.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





