This article was published as a part of the Data Science Blogathon.
Introduction
The simulation of human intelligence processes by machines, particularly computer systems, is known as artificial intelligence. Expert systems, natural language processing, speech recognition, machine learning, and machine vision are examples of AI applications. For these above tasks, we are using different types of systems in AI. For example, In Artificial intelligence, a computer vision-based model is not able to handle the NLP-related tasks and vice versa. Similarly, a text classification model in machine learning will fail to handle some machine translation problems and vice versa. But have you ever thought about a model which is capable to do all these tasks without any further model architecture change?. Or a single model that can mimic the human brain by doing multiple tasks without any significant external world influence?. If so you are on the right track and you thinking about Artificial General Intelligence (AGI).
An intelligent agent’s ability to understand or learn any intellectual job that a person can is known as Artificial General Intelligence.
Artificial Intelligence (AI) is the concept of creating a machine that can think, act, and learn in the same way that people do. Artificial General Intelligence (AGI) is the intelligence of a machine capable of doing any cognitive task that a human can. A system with Artificial General Intelligence would be capable of understanding the world as well as any human, as well as learning how to do a wide range of activities. It is a key goal of certain artificial intelligence research nowadays, as well as a popular subject in science fiction and futurist studies. The majority of the AI research happening today is trying to obtain at least the minimum level of AGI in the end products.
Recently Deepmind – A British artificial intelligence subsidiary of Alphabet, introduced the latest and most promising AGI model, which is GATO. A large volume of data scientists all over the world suggests that GATO is the world’s first AGI. In this blog, I am trying to introduce the very basic interesting details of the GATO model to you.
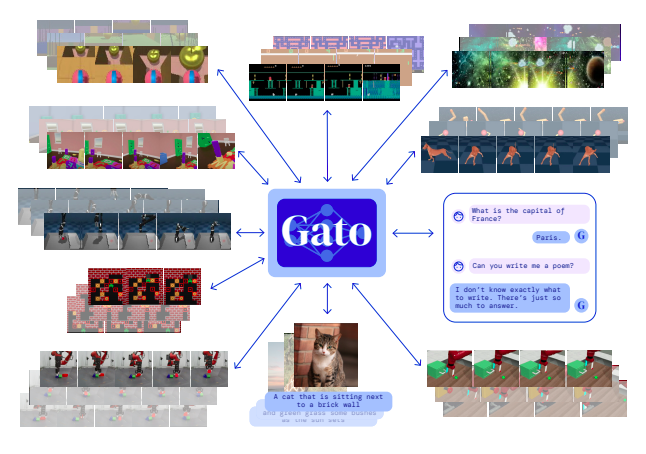
Generalist Artificial Intelligence Agent
Using a single neural sequence model for all tasks has a lot of advantages. It eliminates the need to hand-craft policy models for each area with proper inductive biases. Because the sequence model can consume any data that can be serialized into a flat sequence, it enhances the amount and diversity of training data. Furthermore, even at the cutting edge of data, computation, and model scale, its performance continues to increase. As I mentioned in the introduction section these kinds of neural architecture which can do multiple tasks are known as Multi-model neural networks and these systems are called Artificial General Intelligence agents. There are several multimodal architectures are available today which are showing a minimum level of AGI in nature. Some of them are T5, and GPT-3 models (For more details regarding GPT-3 please check my previous article here).
Deepmind claimed a few days ago that it had developed a generic AI that can perform any task. Google claims that it can accomplish 600 jobs, which is the closest we’ve come to human-level performance in a variety of settings. Deepmind instantiated Gato as a single, large, transformer sequence model. Another important point is that every task done by GATO uses the same weights. Gato can generate captions for photographs, stack blocks with a real robot arm, surpass humans at Atari games, navigate in simulated 3D landscapes, obey directions, and more with just a single set of weights.
Into the World of GATO
Datasets
Gato is trained using a variety of datasets, including agent experience in both simulated and real-world settings, as well as natural language and image datasets. The below tables describes the datasets used for GATO training.
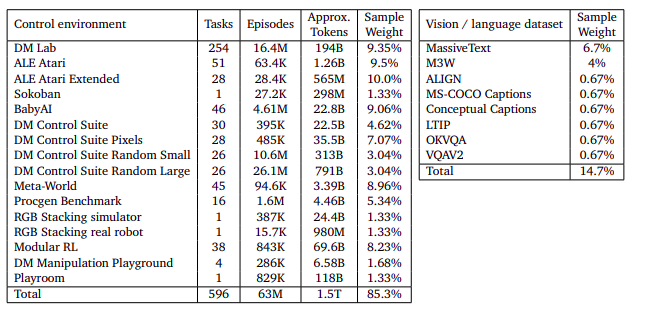
The data contained in the final dataset used to train the GATO model is widely spread in different domains, those are
- Simulated control tasks
- Gato is trained on the datasets taken from the Reinforcement Learning based tasks
- Vision and language
- Gato is trained on MassiveText, a database of big English-language text corpora culled from a variety of sources including web pages, books, news stories, and code.
- Robotics – RGB Stacking Benchmark (real and sim)
- Gato is trained on the observations recorded by taking physical actions in the real world using robotics.
GATO-Training
During the training, data from a variety of jobs and modalities is serialized into a flat sequence of tokens, batched, and processed by a transformer neural network that works in the same way as a big language model. The loss function is only applied on target outputs, such as text and certain actions, due to masking. The training phase of GATO is described in the figure below.
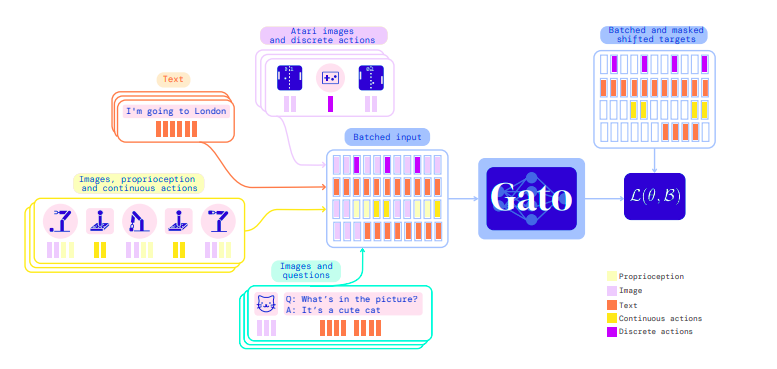
Gato’s main design approach is to train on as much relevant data as possible, such as text, images, and views both discrete and continuous data. To enable the training in multiple nature of data GATO serialize all data into a flat sequence of tokens. This process is called tokenization. There are multiple ways to do tokenization. Some methods are mentioned below.
- Text is encoded through the SentencePiece method
- Images are initially converted into raster order sequences of non-overlapping patches.
- Discrete values are condensed into integer sequences in row-major order.
- Continuous values are first flattened into sequences of floating-point values in row-major order and do the rest of the process
They employ the canonical sequence ordering after transforming data into tokens.
- Text tokens in the same order as the raw input text
- Tokens for image patching in raster order.
- Tensors in row-major order.
- By key, nested structures are arranged in lexicographical order.
- Agent episodes as timesteps in time order
etc
The idea is to organize everything in the same structure, with a certain sequence based on the task as seen in the training phase image.
After tokenization and sequencing, the below operations will perform depending on the nature of the input
- Text tokens, discrete- or continuous-valued observations, or actions for any timestep are embedded into a learned vector embedding space using a lookup table.
- To obtain a vector per patch, tokens pertaining to picture patches for any time step are embedded using a single ResNet block.
The embedding vectors are generated from the 1.2 billion transformers.
Gato uses a 24-layer, 1.2B parameter decoder-only transformer with a 2048 embedding size and an 8196 post-attention feedforward hidden size.
The model remains a linguistic model, predicting the following word based on the sequence. The model is given with all continuous values, proprioceptive inputs, joint torques, and so on as a set of supplementary subwords mapped on top of the text vocabulary range at [32000, 33024]. GATO is one of the methods for converting an RL problem into a conditional sequence modelling problem. Models like GATO use a (big) context window to forecast the next best action rather than approximating state value functions or learning a policy.
GATO-Inference
It is auto-regressively trained, which means it just anticipates what the next input will be. For example, if it receives a text, it will attempt to guess the next statement. Or an action that will occur in the case of games. The model receives an embedding and makes a prediction based on it, which is then carried out in the simulated environment, and the current state is tokenized and embedded again, and sent back to the model to produce another prediction. Check the below image for understanding the prediction process of GATO.
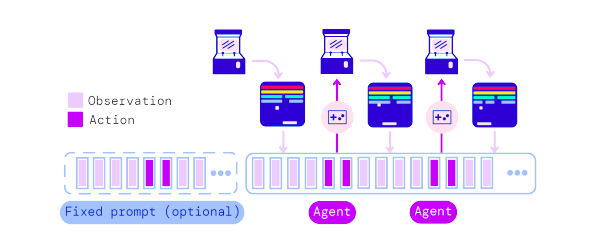
We can see that it also has a Fixed prompt component, which simply tells the model what kind of response we expect for this collection of input – which leads to the multitask behaviour of the model. This means the model is fed a previously recorded token sequence of that specific task rather than a task type id, thereby priming the context window.
Analysis
Now, is the time to showcase the power of GATO. Some of the GATO final results on various activities are shown below
Gato in Image Captioning
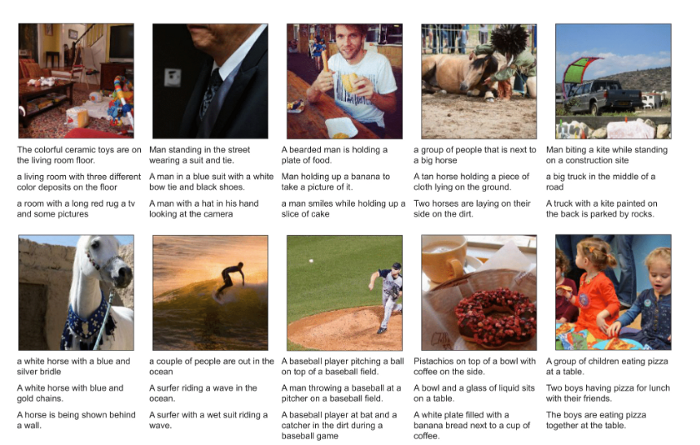
Gato as Conversational Agent
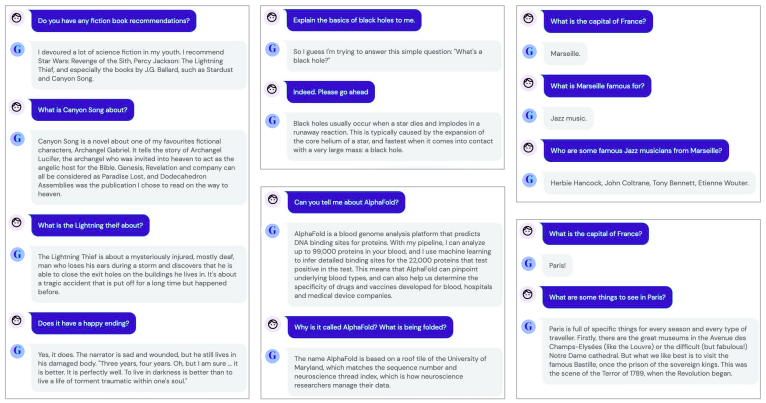
When we observe the GATO results deeply, we can understand that the results are promising to an extent. A single model can able to handle multiple tasks up to an extent is a major breakthrough in the Data science research community even though the obtained results are not meeting the human level. And obviously, GATO is a powerful model, it is still far from a human-level perception. Not only that GATO’s model size scaling curves are highly promising. Although their largest model utilized a 1.2 billion parameter decoder, which is a tiny Transformer nowadays. DALL-E has a param count of 12 billion, while GLIDE has a param count of 3.5 billion. Anyway, this work demonstrates how to add RL tasks to Transformer-based generalist text and image models (Hats off DeepMind🤗).
Conclusion
Nowadays most of the research works in Artificial Intelligence are trying to achieve the Artificial General Intelligence behaviour in their results. In that perspective, GATO is a gamechanger in this domain. Deepmind had put a lot of effort to bring this generalized nature into its behaviour. Gato is a decoder-only model which uses 1.2 Billion parameters in size. Transformer sequence models work well as multi-task multi-embodiment policies in a variety of settings, including real-world text, vision, and robotics. They also show promise in learning a few-shot out-of-distribution assignment. Instead of starting from scratch, such models could be utilized as a default starting point for learning new behaviours by prompting or fine-tuning in the future. Even though it is capable to do multiple tasks, the GATO size is very small when we compare it with other newly published models in AI like GPT-3 and DALL-E. As a result, the GATO multimodel architecture is scalable in a wide range.
In this blog, I tried to explain only the basic properties of the GATO model. For more details kindly check the official base paper here. But at the end of the day, as we see in the evaluation results of GATO, it is sure that we should still wait for the arrival of a new model which can reach up to the human level behaviour in many of the tasks. Let’s hope to meet a new real AGI model soon…!
Happy coding!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A passionate data scientist. I love to explore data and extract insights that can help solve complex problems. With my knowledge of programming languages such as Python, I am proficient in developing models and analyzing large data sets. My passion for learning has led me to continuously expand my skillset and stay up-to-date with the latest trends in the field. I am committed to using data science to make a positive impact on society and believe that the power of data can transform businesses and organizations.

