This article was published as a part of the Data Science Blogathon.

Need For Storage Solutions
What are AWS S3 practicals?
Amazon Simple Storage Service, thus the name S3, is an Object Level Storage service provided by AWS. The idea is to store different file types in a bucket and access them independently. This allows for reducing storage space and better access & security.
An Analogy
In simple terms, you can think of your C/D drive as buckets and files stored as objects. You can have many files, and each can be accessed independently along with the security on each file. Also, you can specify which person can use which drive (think administrator!)
A Difference
Although both have a lot of similarities, one thing that separates them is how S3 handles new files. When a new file is uploaded, it simply creates a new version of it rather than updating the old file (pretty much as git).
Features Of AWS S3
Now have a gist of what S3 is and what are its features?
There are a lot, but here are a few hand-picked ones that do an excellent service:
- Storage – The files uploaded are stored in buckets, and the max file/object size that can be uploaded is 5TB. New buckets can be created as per required.
- Security – Multiple versions of an object can be created to reduce accidental loss + users can define custom permission on who can read/modify the objects(S3 BUCKET POLICY).
- Life Cycle Policy – The user decides what will happen to the object after a fixed time. They can even define a policy for the same to self-move them around different storage classes.
- Accessibility – Easy deviation of files from any location around the world.
- Cost Friendly – Much cheaper than buying an SSD.
And much more.
Image from Thorias.com
AWS S3 Storage Classes
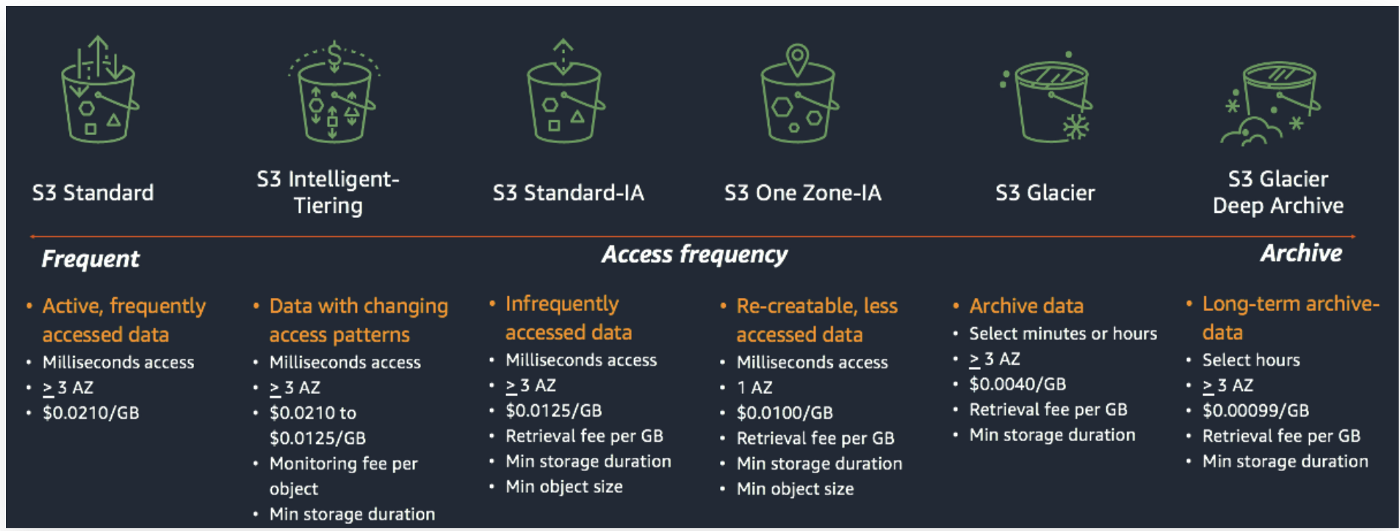
S3 has 6 types of storage classes, each having its own merits and demerits. So let’s briefly review each of them.
S3 Standard
- The most premium storage is offered.
- Suitable for frequently accessed data workloads.
- 99.9% durable (no issues with data deletion).
- Stores data in 3 Availability (AV) zones.
- A bit on the high side compared to other storage classes. – demerits
S3 Standard Infrequent Access
- Suitable for storage where data is not frequently accessed.
- Have high durability.
- Stores data in 3 AV zones.
- Low storage price.
- Bit high retrieval price as data is retrieved rarely. – demerits
S3 One-Zone Infrequent Access
- Again an infrequent access class.
- Lower Storage cost than S3- IA
- Stores data in a single AV zone.
- Less Durable as an object stored in a single location – demerits
S3 Intelligent Tiering
- Workloads with changing request patterns. For, e.g., low requests in one month and very high in another.
- Monitors the object access patterns and adjusts accordingly
- It can be thought of as an AI wrapper around all those mentioned above and cost accordingly
S3 Glacier
- Long-time preservation system.
- Suitable for storing old files, e.g., customer records and project files (old versions).
- Archives the object to reduce storage space.
- Low storage cost.
- Object retrieval time from a few min to hours; is usually based on object size and requests. – demerits
S3 Glacier – Deep Archive
- Suitable for longest-time preservation of data .- access only 1 or 2 times a year.
- Lowest Storage Cost.
- Accessing takes up to 12 hours.
To learn more, refer here.
S3 Bucket Policy
As defined earlier, each bucket has a set of associated rules, which allows defining predefined or custom sets of policies called S3 bucket policies.
It’s a JSON file containing the selected bucket’s rules. It’s an excellent way to apply security at the object level. One can even define a policy on a single object within a bucket!.
A simple example could be; access to a particular object from defined IP only. (Practical)
IAM Roles With S3
Sometimes admin users don’t want to allow excessive use of resources as a cost/ integrity security measure. In that case, IAM roles are significant as it offers the flexibility to switch back and forth between different permissions.
IAM stands for Identity Access Manager and is a service that allows the host’s account to create sub-accounts with special privileges. An example could be a company with multiple teams handling different tasks, let’s say only S3 and EC2 instances. (Practical)
In simple terms, S3 has these IAM permissions and can be invoked at any time.
Hands-On Practical
Enough talk. Let’s now look at the practical / implementation aspect of S3. Here is a quick overview of whatever we will be doing:
- Creating an S3 bucket (regular and CLI).
- Defining Bucket Policy (non-code).
- Define Lifecycle policy.
- Add IAM roles to S3.
So let’s move on, assuming you already have an AWS account created – regular/free tier.
Creating an S3 Bucket
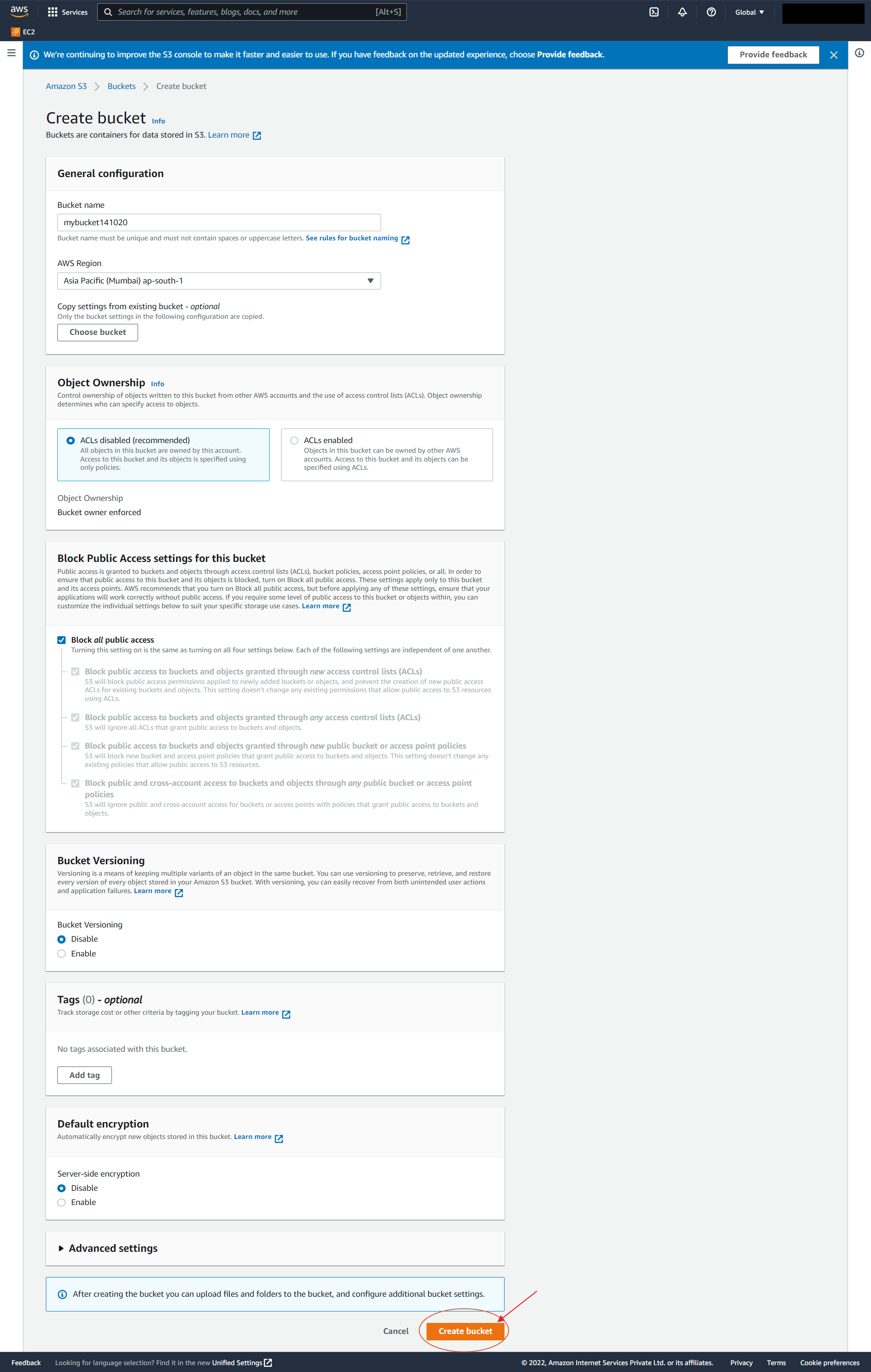
Before anything, one needs to have an S3 bucket, and creating it is a 4 step process:
Normal
1. Head over to the AWS console and search S3. After finding click on it and press Create Bucket.
2. A new page will open with the following details;
- Bucket name – Unique Identifier.
- AWS Region – Region where files will be stored.
- Object Ownership – Ownership of bucket objects allowed from different AWS accounts? – ACL’s
- Block Public Access – Block the access through the public IP? (Yes – default)
- Bucket Versioning – Allow different versions of objects to be created (paid service).
- Tags – References to keep track of different S3 buckets.
- Default encryption – Allow server-sided encryption to defend from attacks.
- Advanced settings – Set object to write once, read many modes to prevent the thing from deletion.
Fill in the required details and click Create Bucket.
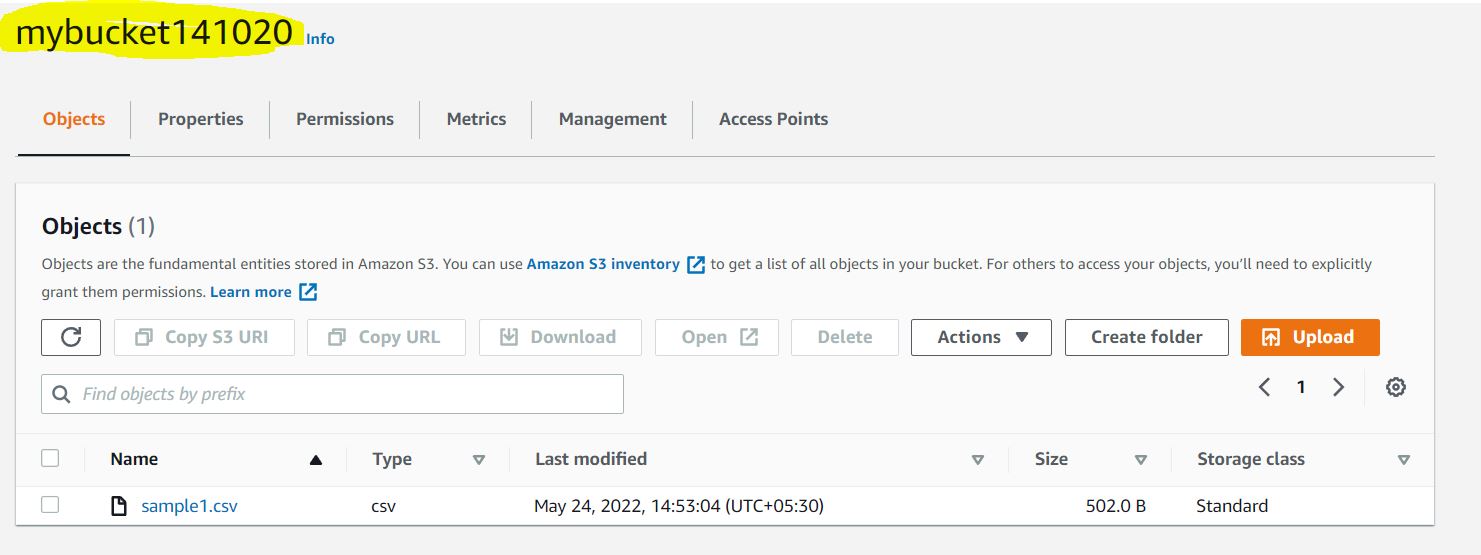
3. A new dashboard opens. Click created bucket under the objects tab and press Upload. In the new tab, drag and drop files/folders and click upload. For this case, let’s use a CSV file.
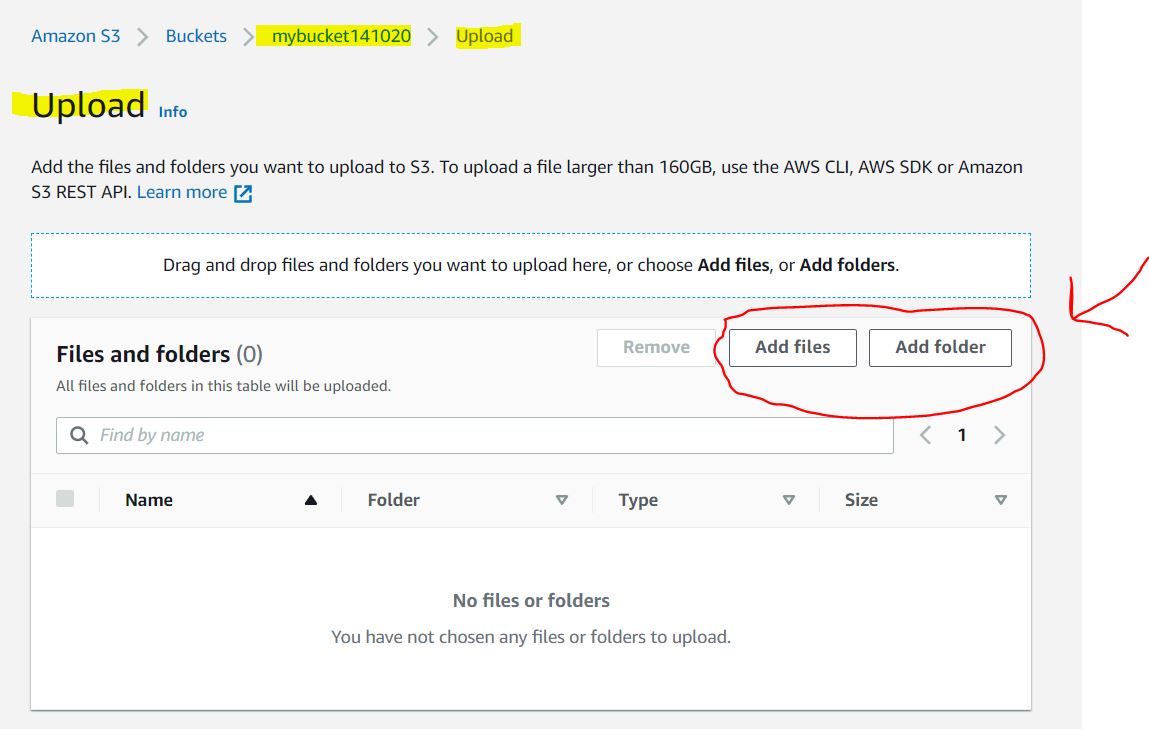
Note: While uploading extra permissions like the destination(file path), permission (public / private access), and properties (storage-class, checksum, encryption, tags & metadata ) can be defined.
After Upload:
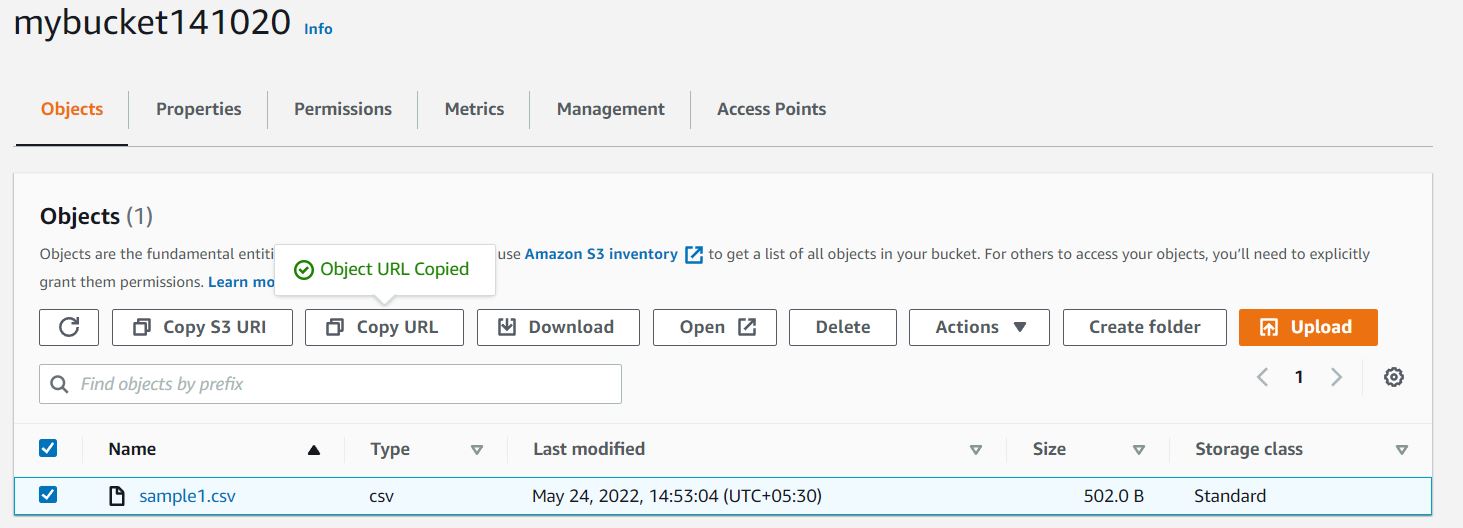
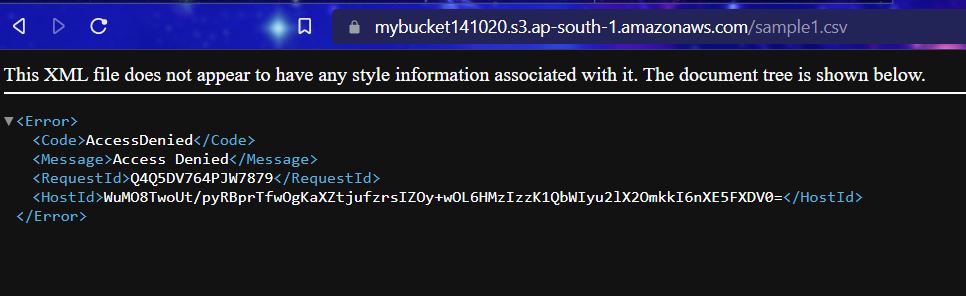
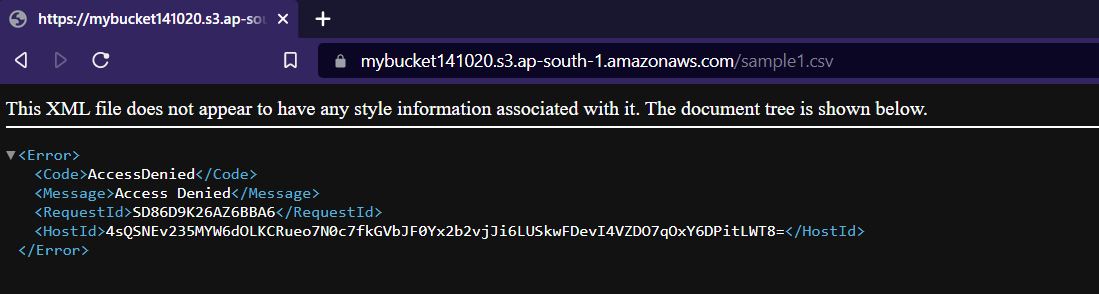
4 Click on the given destination path to access the files. Though Url Access is Blocked. (Public Access Denied.)
Do note that the name of the file is the key, not enabling versioning will override the existing file. Upload files with different names.
If public access is blocked one can download the file only from the destination path console.
CLI Method
Sometimes users are more comfortable using a command-line interface. Generally, the case with Linux and Mac users. So AWS provides a way to configure S3 using the command line – 9 step process.
1. Create an ec2 instance and ssh into the terminal or use the local machine. For the same, you can refer to this article.
2. Login with AWS credentials and download AWS CLI support using the below command (copy-paste)
For Linux:
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"

For Windows
(download MSI installer) / use :
C:>msiexec.exe /i https://awscli.amazonaws.com/AWSCLIV2.msi
For Mac:
(no CLI download support). Use the package manager.
For simplicity, this tutorial aims at using the Linux shell. The process remains the same for others.
3. Unzip the file :
unzip awscliv2.zip

press A and all files will be extracted!
4. Install :
sudo ./aws/install

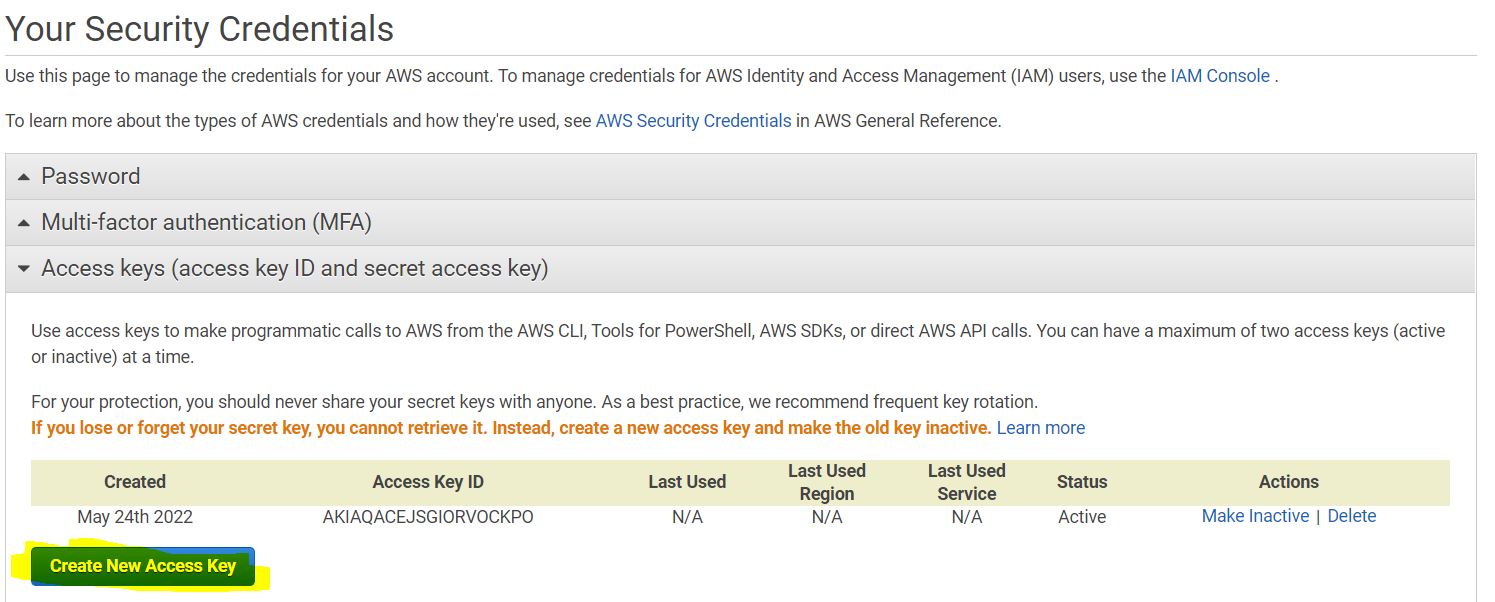
5. Get Credentials by visiting account -> Security Credentials -> Access Keys -> Create New Access Key -> Download the file.
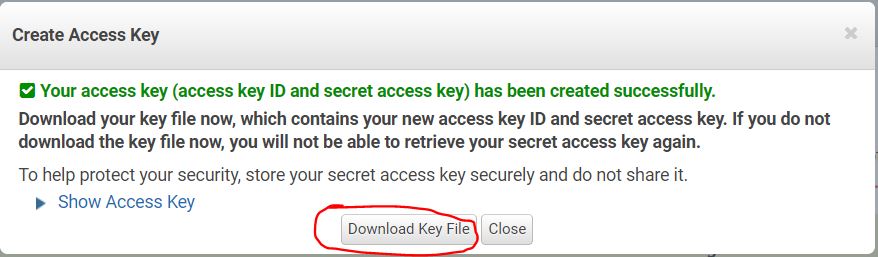
6. Once done, log in to your account :
aws configure
It asks for AWSAccessKeyId & AWSSecretKey. Fill in those details.

7. Check for existing bucket:
aws s3 ls
8. Get inside the bucket:
aws s3 ls "bucket name"
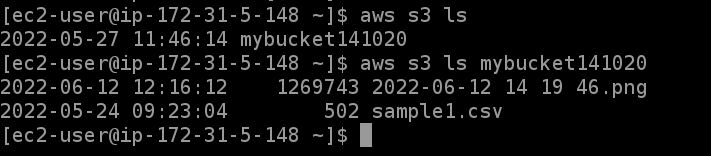
9. Download the files using the URI path (from the S3 dashboard).
aws cp s3 "URI" "download/path"
If you have paid attention to, we are downloading the file from same s3 console, so file download will not be restricted and inverted commas are essentials
Adding Bucket Policy
Sometimes users want to be more specific on who can access the buckets, common scenarios at private companies where data is very precious. Here bucket/custom policies can come in handy.
Here is how to add it:
1. Visit the S3 console(search S3) and select the S3 bucket, which needs a custom policy.
2. Click the Permission tab on top and navigate where it says Bucket policy. Then click Edit.
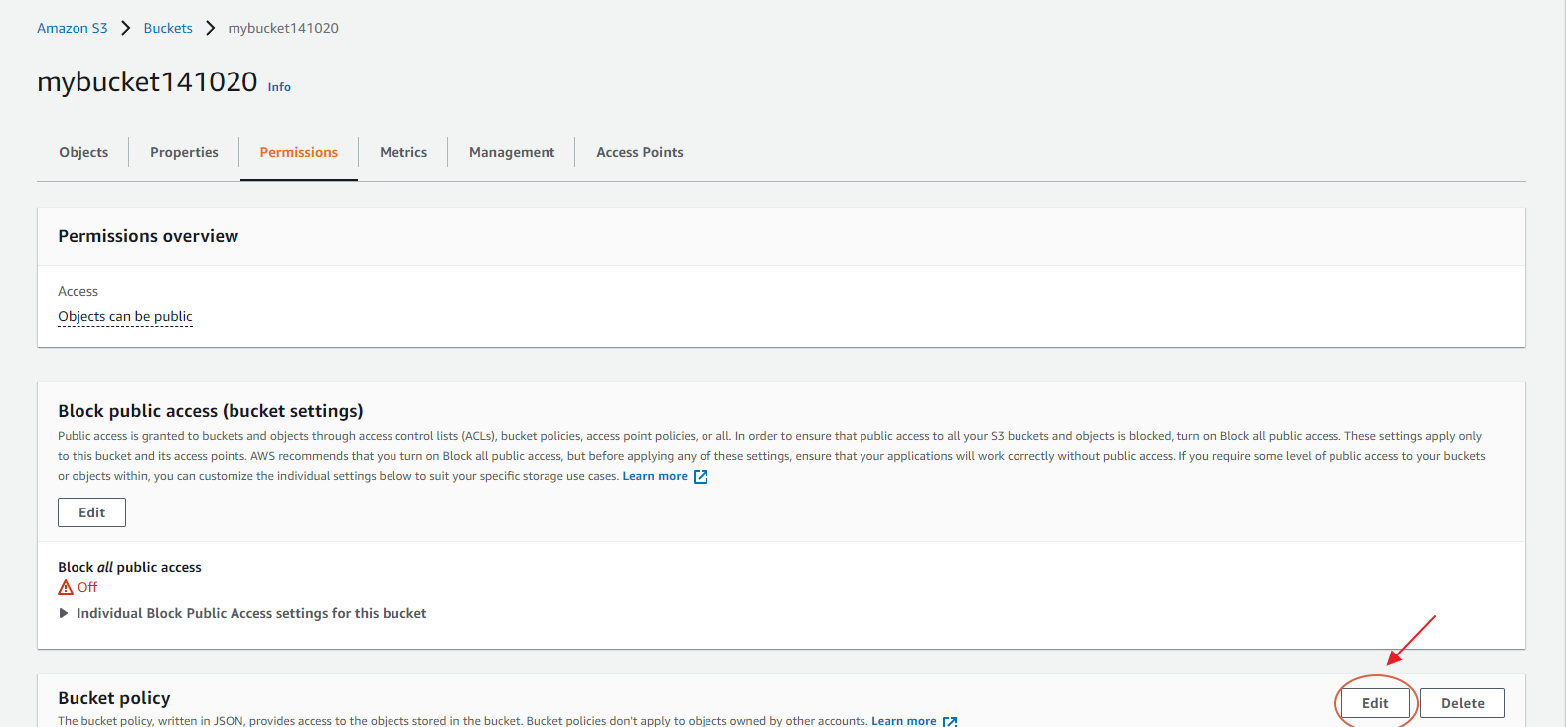
3. Click Policy Generator on the newly opened tab. This allows the creation of new rules with simple statements (no code!).
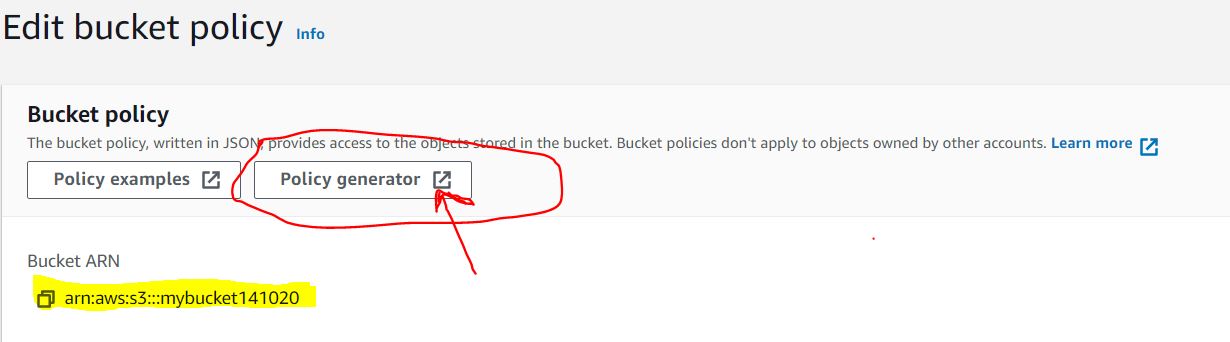
Note down the bucket policy no as it will be required
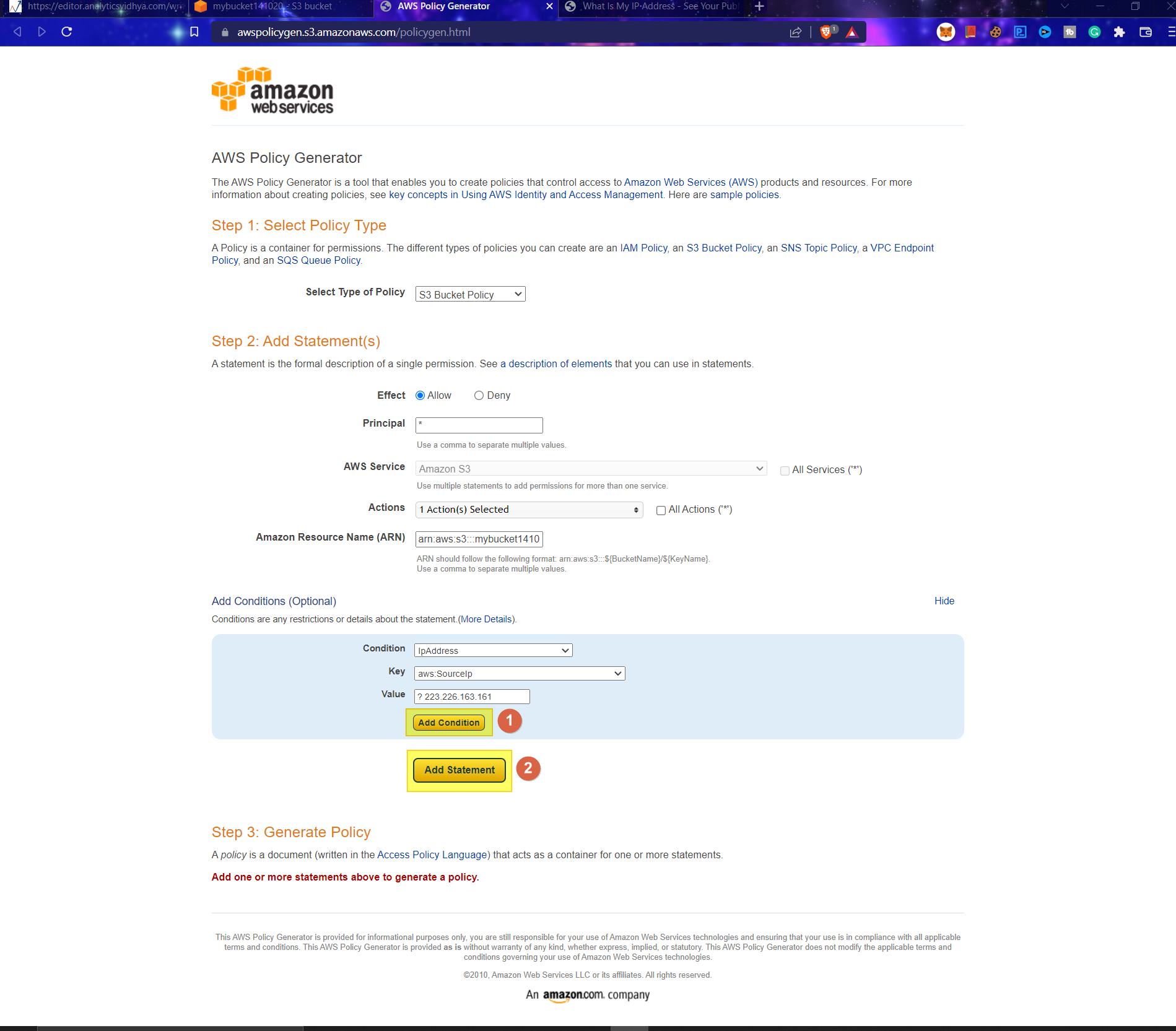
4. Now AWS Policy Generator page opens up, and new policy rules can be added by filling the fields:
- Policy Type: Define policy type. (SNS, S3, VPC, SQC, IAM)
- Effect: Whether to allow or deny the service
- Principal: What resources are to be used. * – all
- AWS Service: Service to use – auto select based on the policy type.
- Actions: Select actions to perform based on resources to be utilized
- Amazon Resource Name (ARN): The Bucket ARN
- Add Condition (Optional): Add conditions for advanced usability
- Condition: Select Condition based on the use case. P
- Key: What key value should be pinpointed to (resource arn name/id)
- Value: Value for which condition needs to be checked
Once done, click Add conditions(1) and Add statement.
This is a simple snapshot of all above for the created bucket, with the policy only accessible through the user-defined IP addresses.
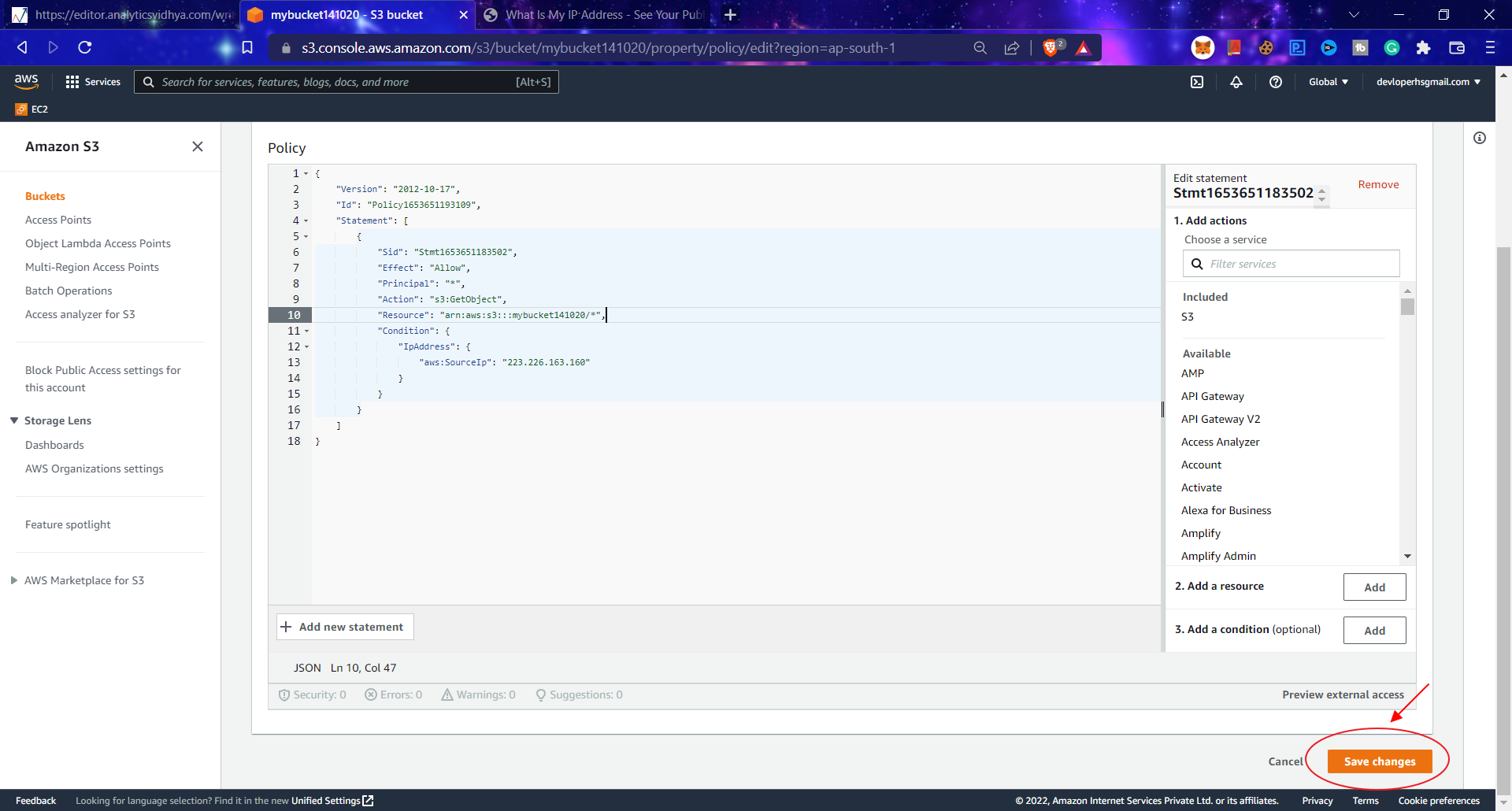
5. Click on Generate Policy, copy all the code it returns, paste it into the Edit Bucket Policy code editor window, and click Save changes.
Generated policy example:
{ "Id": "Policy1653651419222", "Version": "2012-10-17", "Statement": [ { "Sid": "Stmt1653651183502", "Action": [ "s3:GetObject" ], "Effect": "Allow", "Resource": "arn:aws:s3:::mybucket141020/*", "Condition": { "IpAddress": { "aws:SourceIp": "223.226.163.160" } }, "Principal": "*" } ] }
Don’t forget to add Principal value (*) in the Resource statement as bucket_arn/*:
"Resource": "arn:aws:s3:::mybucket141020/*",
Image:
6. To confirm it works, one can access the file URLs using the defined IP address or another (change wifi connections).
Defining Lifecycle Policy – Storage Classes
Lifecycle policies are ways to preserve objects for extensive durations while saving on costs. It works by moving bucket objects to storage tiers after the user-defined threshold(days!).
Let’s look at the implementation steps.
1. Head to the S3 console and navigate the Management tab.
2. In Lifecycle rules, click Create lifecycle rules button.
3. In the new tab, fill out the following fields :
- Lifecycle Rule Configuration
- Lifecycle rule name: Name of the rule. Use some contextualized words.
- Rule scope: What scope to apply. Limit to some specific object or for all.
- Filter type-Prefix: Specify the prefix if a particular file is only needed.
- Object tags: Add tags for better sorting.
- Object size: Define minimum or maximum object size as per requirements.
- Lifecycle Rule Actions
- Requires versioning to be enabled.
- Select the Desired type based on needs
- Move current versions of objects between storage classes
-
Expire recent versions of things.
- Transition Settings – Use add transitions to add more:)
- Storage class transitions: Storage class to move to.
- Days after object creation: Threshold after which objects will be moved.
- Expiration date: Days after which objects are entirely deleted. Part of Expires current working of object section.
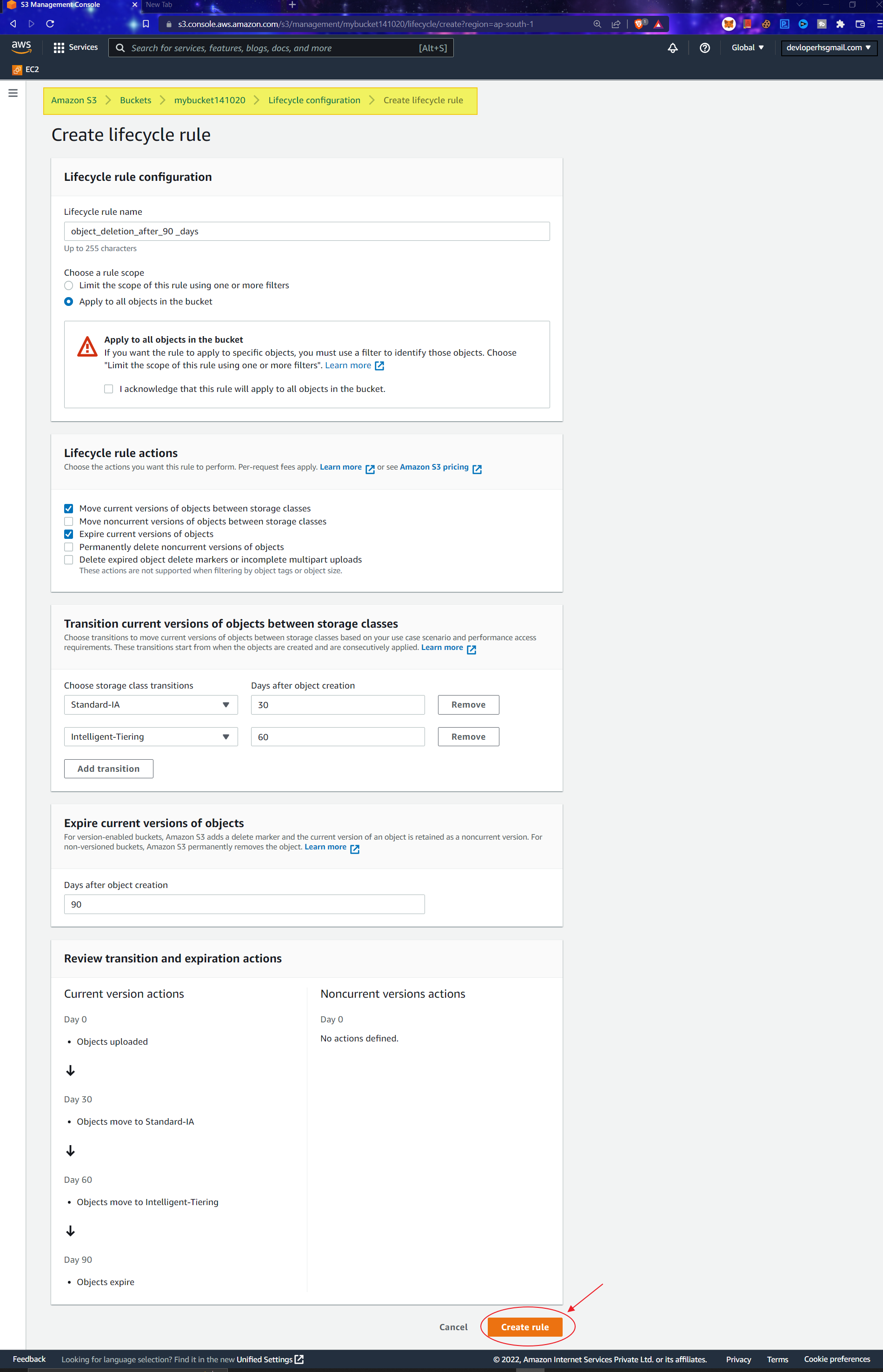
4. Review all the details and click on Create rule. It incurs costs as versioning is paid service.
Adding IAM S3 Roles
Companies are concerned with user permissions between different departments in the corporate world. So they define IAM Roles as a simple way to give limited access to additional services within AWS Infrastructure.
Generally, an admin can create roles and assign them to different departs. For example, Account departments can access only Databases, EC2, and S3.
So here is how one can create an IAM restricted S3 access(primary).
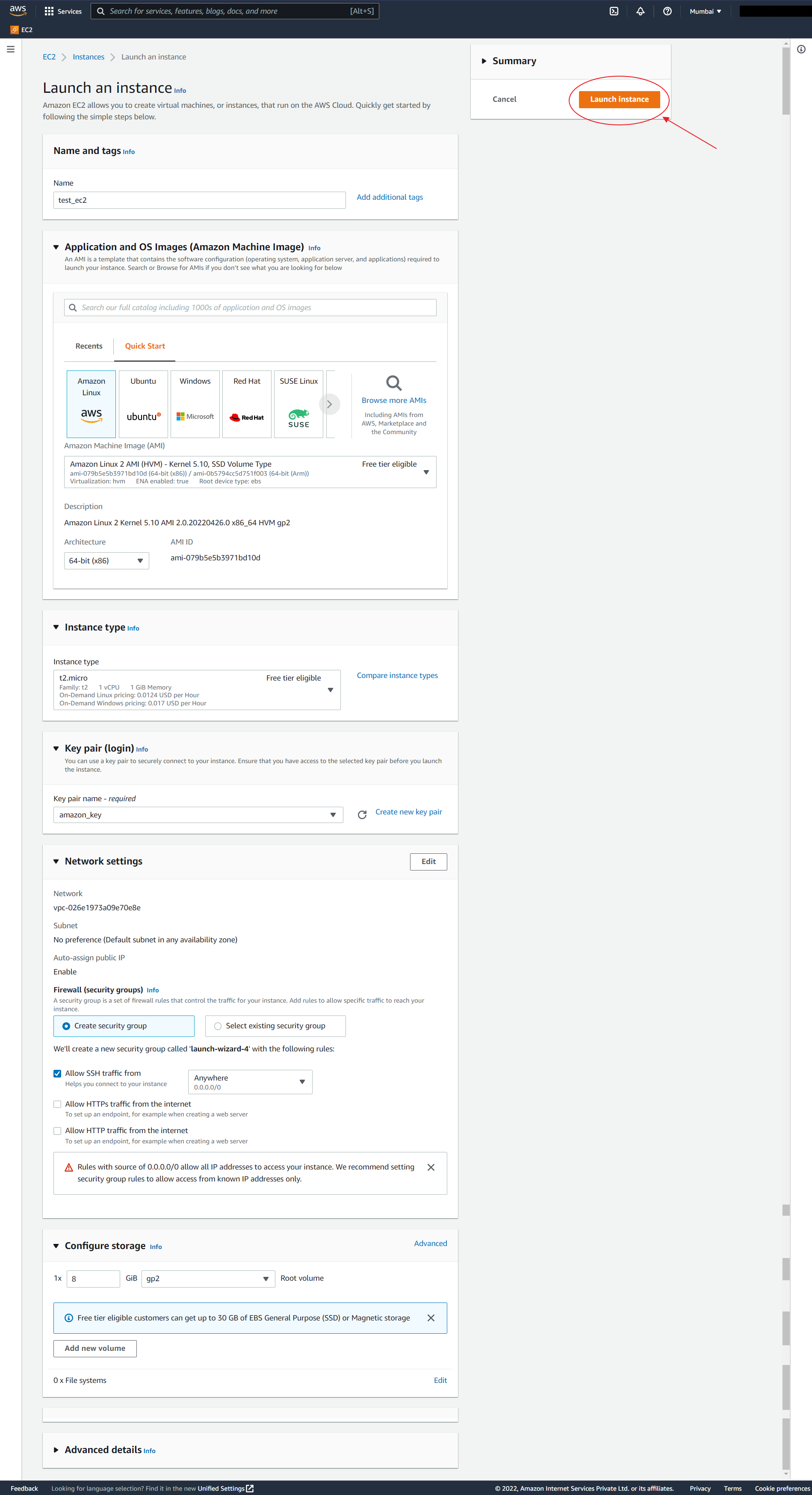
1. Create an EC2 instance
- Visiting EC2 dashboard.
- Launch a new instance.
- Select default configuration and give a unique Name.
- In the keys section, create new key pair and download it.
- Done.
2. Create an IAM role
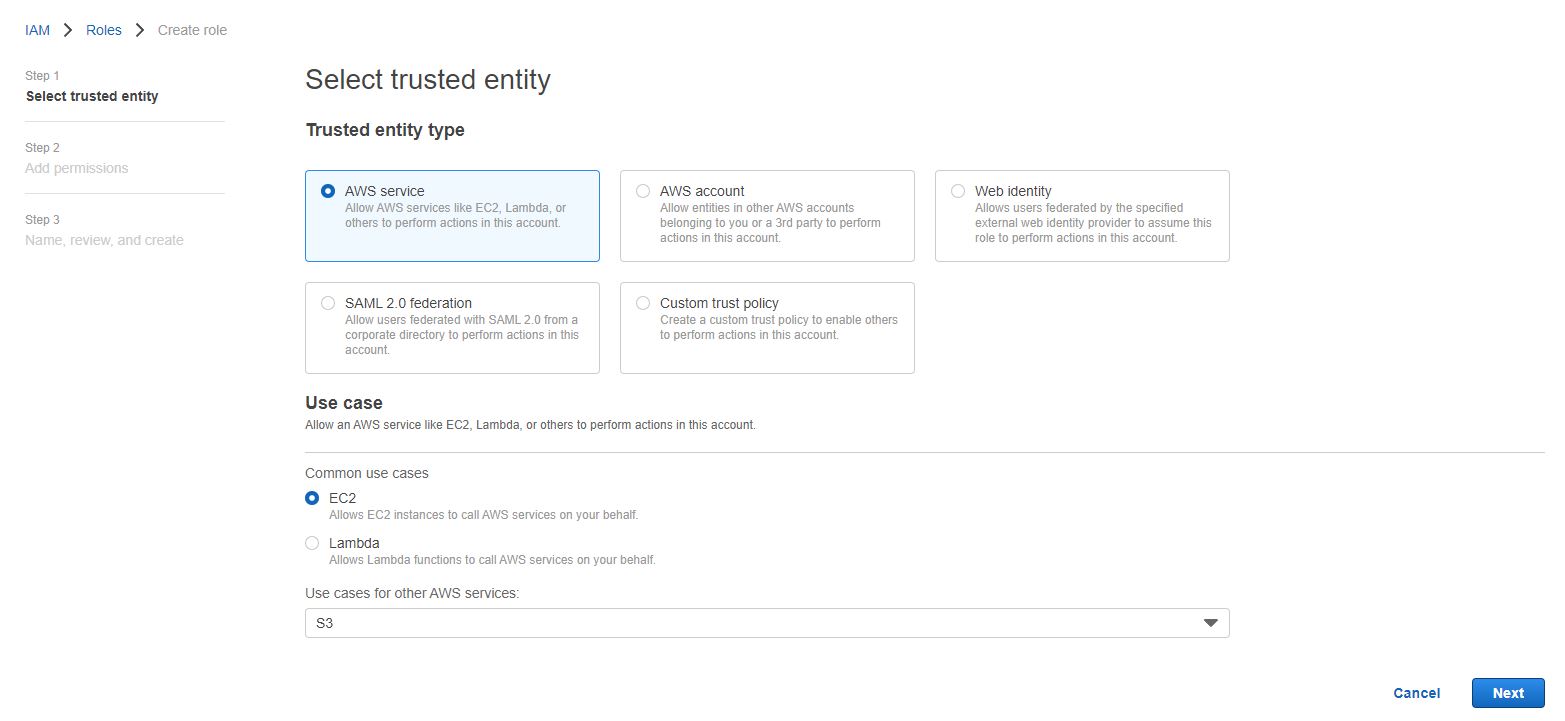
- Search IAM roles and visit the page.
- Select roles in the left menu.
- Click Create role.
- Add Use case – EC2
- Select AWS Service as S3 and click Next.
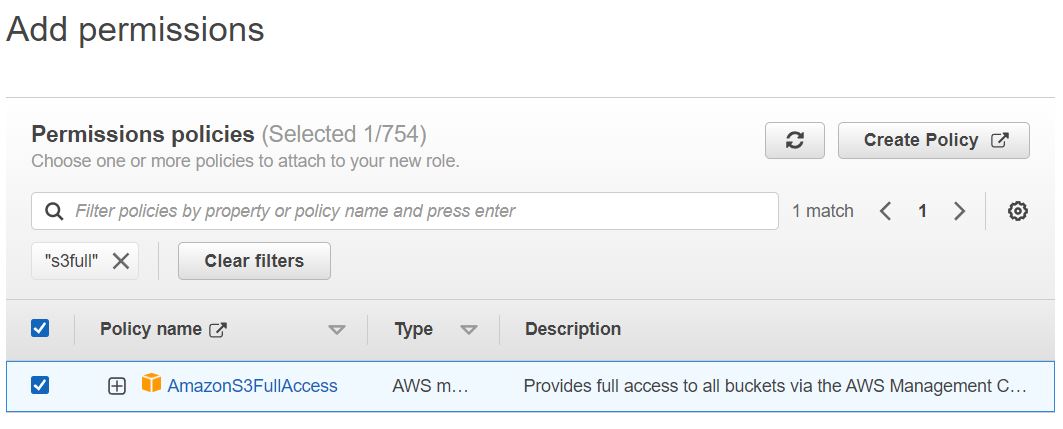
- In the new tab, search S3full and select AmazonS3Full access(from results).
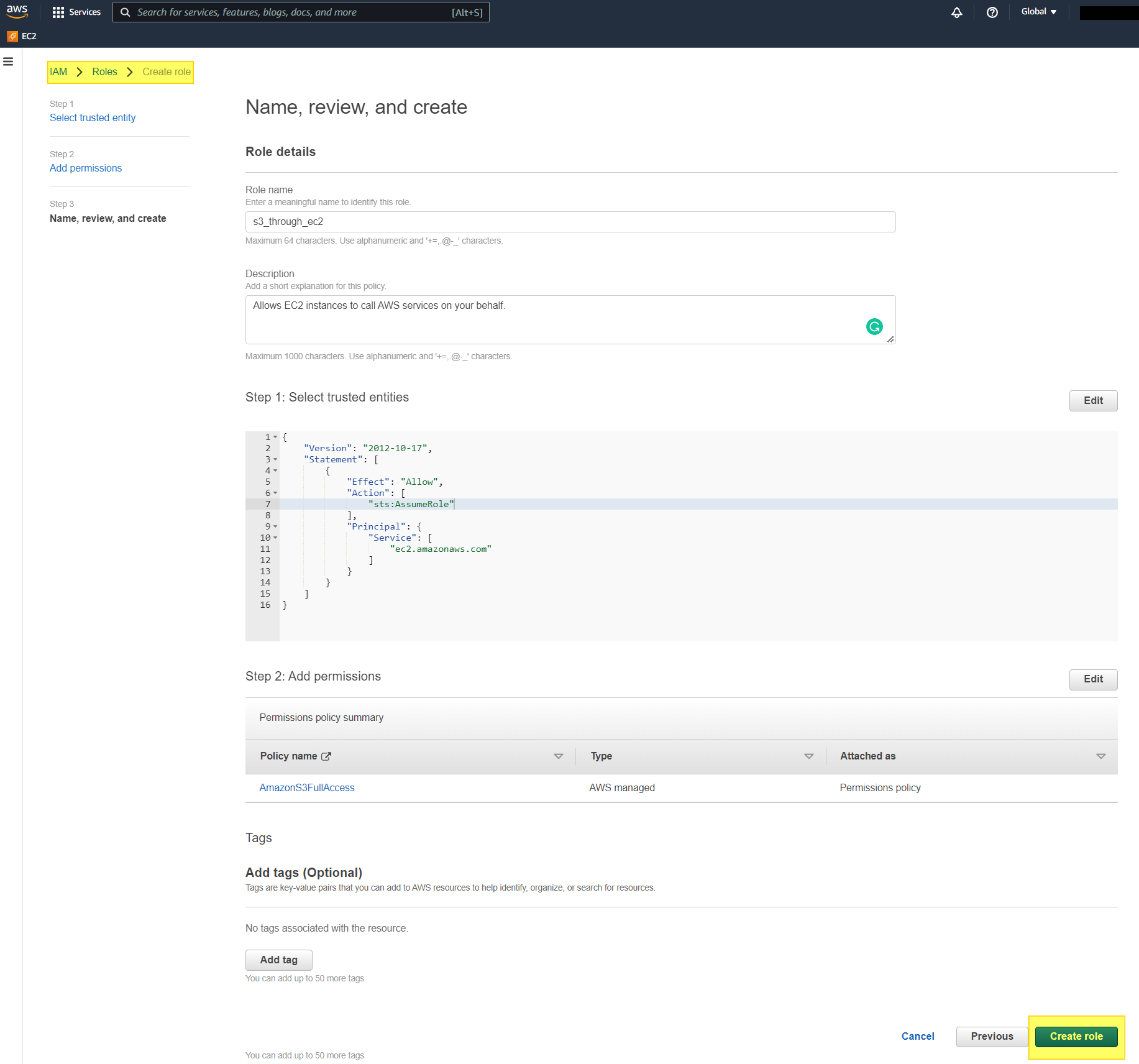
- Add :
- Role Name: – Name of Role – Descriptive.
- Role Description – Description of role – Descriptive will be better.
- Rest auto-add
- Click create.
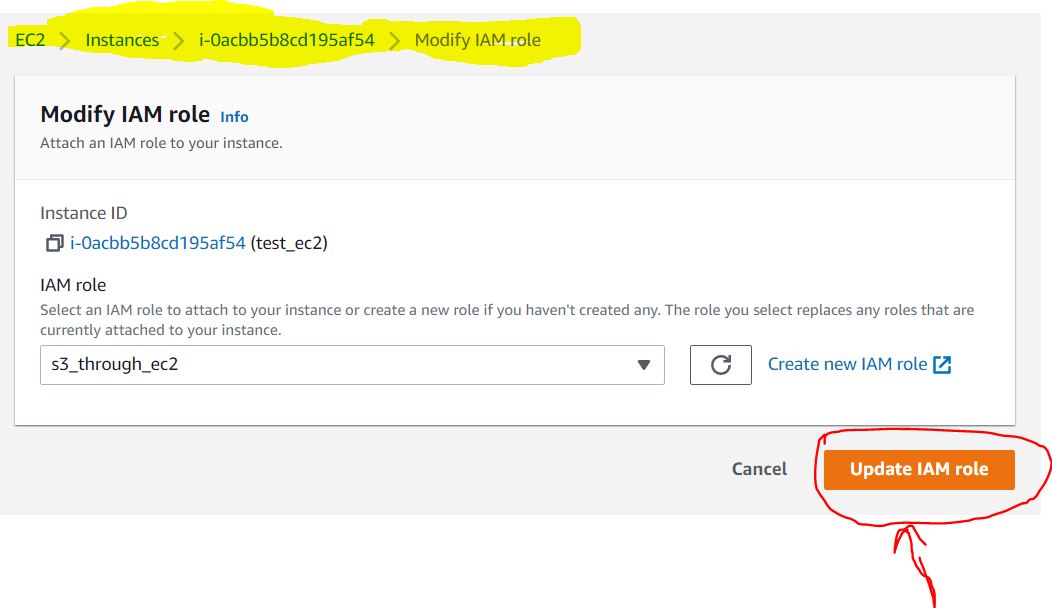
3. Modify EC2 Instance Permissions
- Head back to the EC2 console.
- Click on the instance required.
- Click on Actions -> Security -> Modify IAM role.
- Select the name of the role created on the new page.
- Update IAM r
- Done!.
One can verify if everything works smoothly by visiting the ec2 instance and following steps:
In the command line, add the following:
aws s3 ls
Image:
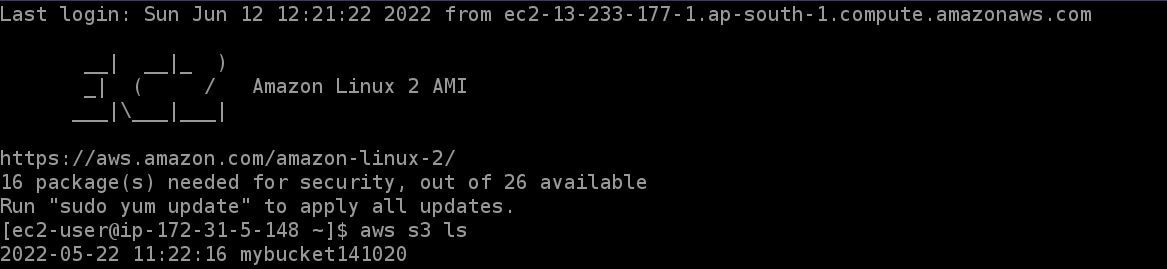
In general, without IAM roles, this will result in Credential Errors. After IAM, the same command will return files in buckets!
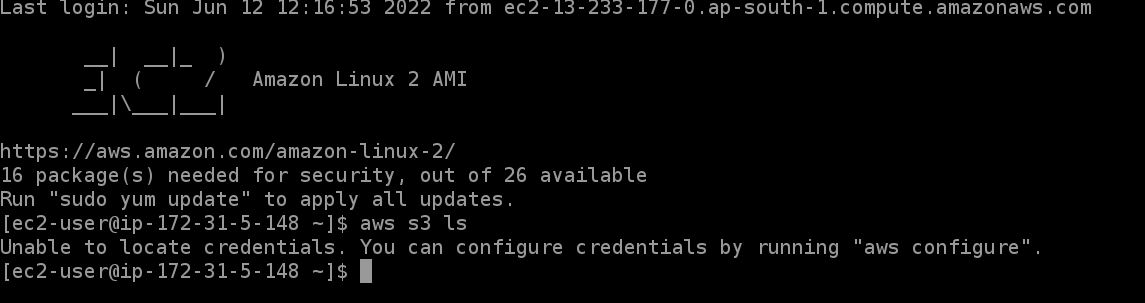
Error!
Conclusion
If you have made it to this end, then congrats. You are ready to get started with AWS S3. In this guide, we learned the following:
- Looked into what AWS S3 is and what it has to offer as a solution to individuals, startups, and corporates for their day-to-day workloads.
- Learned how S3 works and how it cleverly solves the data storage and retrieval problems.
- Saw different S3 classes AWS offers, their merits, demerits, and particular use cases.
- Understood different features that s3 incorporates for increased usability and reliability. Some essentials are policies IAM and Bucket, Buckets ideology, and security using user-defined controls.
- Have a hands-on practice on how to?
- Create an S3 bucket.
- Add Bucket Policy
- Define Lifecycle Policy
- Add IAM S3 Roles
- and some quick tips for productizing your workflow
Hope you liked the article. If you have any concerns or suggestions, ping me on LinkedIn, Twitter, and Author Page. Do check out my other projects on my GitHub Profile.
Some Extra Storage Services
Although the guide covers everything required to get started with s3, sometimes people may require to use additional services provided by AWS as per their needs. Here is the list of a few that can be used even by beginners:
- AWS Dynamo DB: A No SQL-based system that runs on key-value pairs. It can operate faster than s3 at small levels and is
scalable.
- AWS Redshift: A Data Warehousing service that allows columnar data storage architecture and fast
inference speed. Good for large chunks of databases.
- AWS Outposts: The local processing service
offered by Amazon has 42 units rack, and one can get up to 96 racks, ensuring very low latency. Good for client-user experience apps.
- AWS Snow Family: Set of hardware devices that
can be ordered. Once arrived, data can be loaded and stored in
AWS data warehouses. Good For MNCs or Billion Dollar Evaluation companies
where data is crucial.

Resources
All though we have covered everything required to get started. Still, in case you are interested to learn, here are a couple of resources to get you an in-depth knowledge of AWS S3:
1. Amazon Documentation on S3
2. S3 Pricing
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A dynamic and enthusiastic individual with a proven track record of delivering high-quality content around Data Science, Machine Learning, Deep Learning, Web 3.0, and Programming in general.
Here are a few of my notable achievements👇
🏆 3X times Analytics Vidhya Blogathon Winner under guides category.
🏆 Stackathon by Winner Under Circle API Usage Category - My Detailed Guide
🏆 Google TensorFlow Developer ( for deep learning) and Contributor to Open Source
🏆 A Part Time Youtuber - Programing Related content coming every week!
Feel free to contact me if you wanna have a conversation on Data Science, AI Ethics & Web 3 / share some opportunities.





