This article was published as a part of the Data Science Blogathon.
Introduction
When we mention BigData, one of the types of data usually talked about is the Streaming Data. Streaming Data is generated continuously, by multiple data sources say, sensors, server logs, stock prices, etc. These records are usually small and in the order of a few Kilo Bytes, but their character is that they are like a water stream that flows without stopping. On the other hand, say sales data of a company (historical data ) can be processed in batches, and these data are processed through an ETL(extract, transform and load) pipeline into a Data Warehouse for further analysis. But streaming data cannot afford the luxury of batch processing and requires to be processed in real-time.
There are a plethora of software tools to handle streaming data, like Amazon Kinesis, Azure Stream Analytics, Google Cloud DataFlow, Confluent Kafka, etc. I would like to focus on Apache Kafka, a distributed event streaming platform. Kafka was written in Java and Scala, but it has a python API. We will look at the basics of how Apache Kafka handles streaming data through some coding exercises with Kafka-Python.

Relevance of Kafka
An event refers to an action that is a result of a user action or another application. As an example, when we click on check out button of an e-commerce application, it creates an event that may trigger events further downstream.
Earlier, an event generated is generally stored in a database and one application may be writing events onto the database and another may be reading the events from the database and processing it further. The writing on to database and reading from the database was carried out in batches and that meant there is some delay in processing the event. Imagine an event handling banking transactions, where you do some transactions online and the event gets processed with a delay. This is unacceptable today as such critical events need to be handled and processed in real-time and maybe even pushed downstream to another event handling application downstream. These are termed Event-Driven Applications.
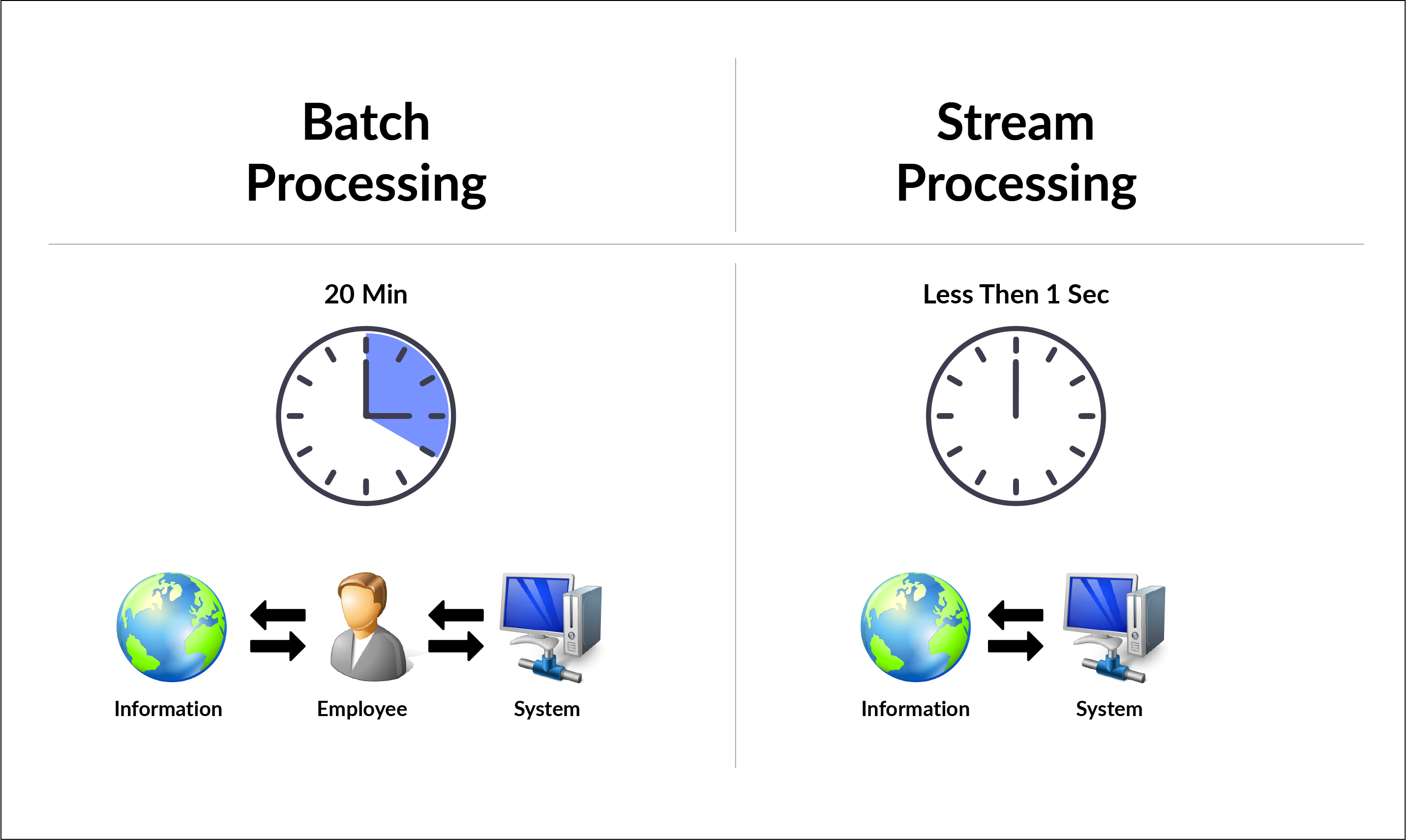
You may have noticed that the moment we place an order on an e-commerce website, we receive an intimation on our mobile device or email that such an event has taken place. Now, this Event could trigger another event-driven application at the vendor’s premise to get it ready for shipment. Apache Kafka is one of the popular open-source tools for handling streaming data.
Core Concepts of Kafka
Kafka is a central messaging system or an event streaming platform. The incoming messages/data come into Kafka and outgoing data is read from Kafka. Kafka is the intermediary between producers and consumers of data.
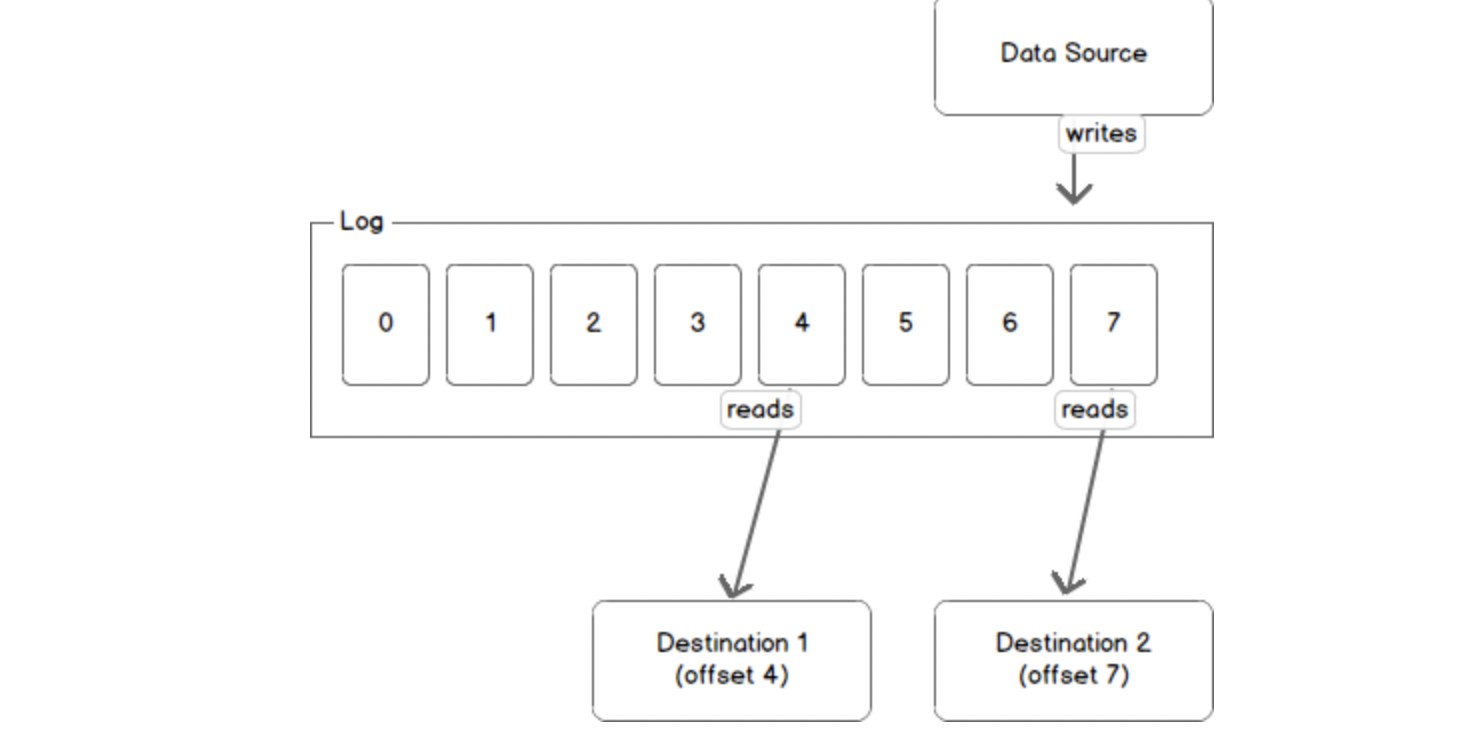
source: https://sookocheff.com/
For a basic understanding, Kafka is a log where data sources send their messages. Messages arrive sequentially in Kafka and can be consumed by multiple consumers. In the above diagram, message 1 arrived before message 2 which arrived before message 3. The messages once published to Kafka cannot be changed. if we want to modify an Event, we have to create a new Event and store it in the log. The Kafka messages are organized into Topics. So a producer sends a message to a topic and a Consumer reads from a topic. We mentioned Kafka as a Distributed System, ie, Kafka runs in a Cluster. A Cluster is a group of computers, each having an instance of a broker. Each node in the Kafka Cluster is called Kafka-Broker. The topics are stored in Kafka Broker.
The messages are stored in more than one broker to provide redundancy and this aspect is referred to as the Replication Factor. A Replication Factor of 3, means the message is stored in 3 brokers.
We had mentioned an Event as an action that has happened in the world or in the context of our business. We write or read data to and from Kafka in form of events. We can conceptualize an Event as data with a key, value, timestamp, and optional metadata headers. Say we have an Event where Bob has withdrawn $200 from an ATM. The Event can look like this,
- Event Key: ‘Bob”
- Event Value: “Withdrew $200 from ATM”
- Event Timestamp: “Jun, 2,2020 at 1000 hrs”
Producers are client applications that publish (write) events to Kafka and Consumers are applications that subscribe (read) these events. The Producer writes to a particular Topic and in our use case, we will write the Producer application using python. The Consumer application reads from Kafka and sends an acknowledgement that I have read Message 0 and am ready to move on to the next Message. Then Kafka moves the Offset to the next Message, thereby keeping track of the Messages being read by the Consumer.
Kafka Partitions
The anatomy of a Kafka Topic indicates, that the topics are divided into partitions. This can be visualized as a topic spread over several buckets located on different brokers. The data in a particular topic is split across multiple brokers, and each partition can be placed on a separate machine. This architecture will enable multiple consumers to read from a topic in parallel and this can result in high message processing throughput. When a new event is published to a topic, it is written to one of the topic’s partitions. Events with the same event key are written to the same partition.
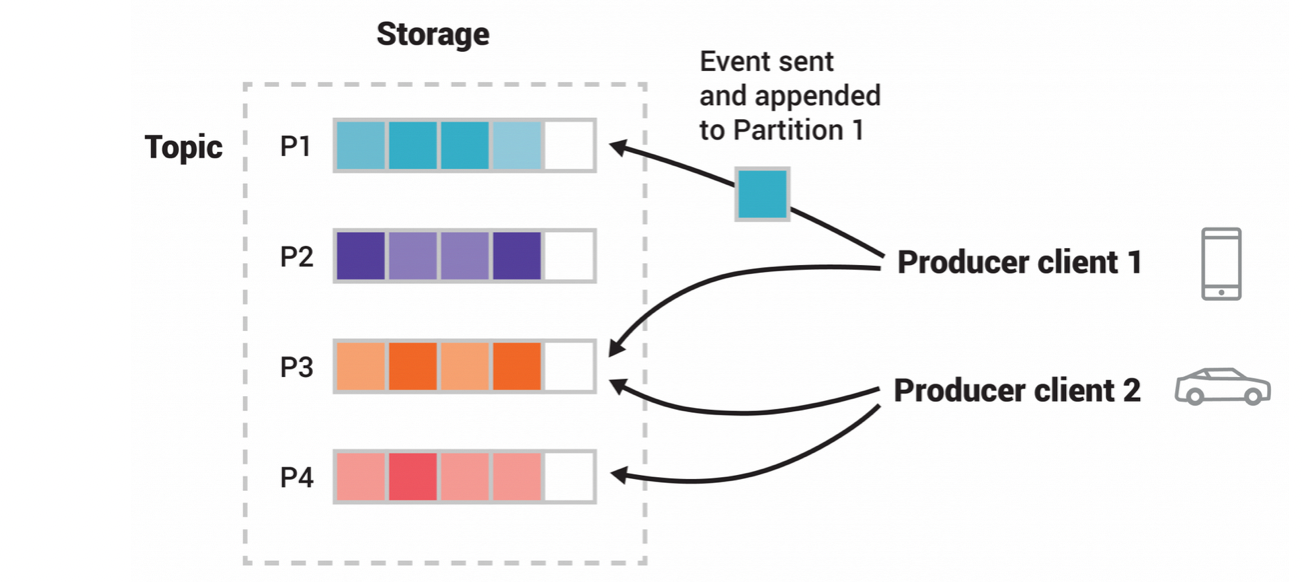
source https://kafka.apache.org/intro
In the figure, the topic has four partitions (p1-p4). Two different producer applications are publishing the same topic independently by writing events to partitions. The producers can write to the same partitions if the Event they are publishing is appropriate to that partition. As we mentioned earlier, each Message within a partition has a unique identifier called offset. The offset is a kind of immutable message ordering sequence maintained by Kafka. We can see that each specific message in a Kafka Cluster is identified by Topic, Partition, and Offset within that partition. Kafka has a component called Zookeeper which manages the Kafka Cluster, the status of nodes, and a list of topics and messages. There have been some discussions on the internet about the Kafka version without a zookeeper, but I understand the release is not yet ready for production.
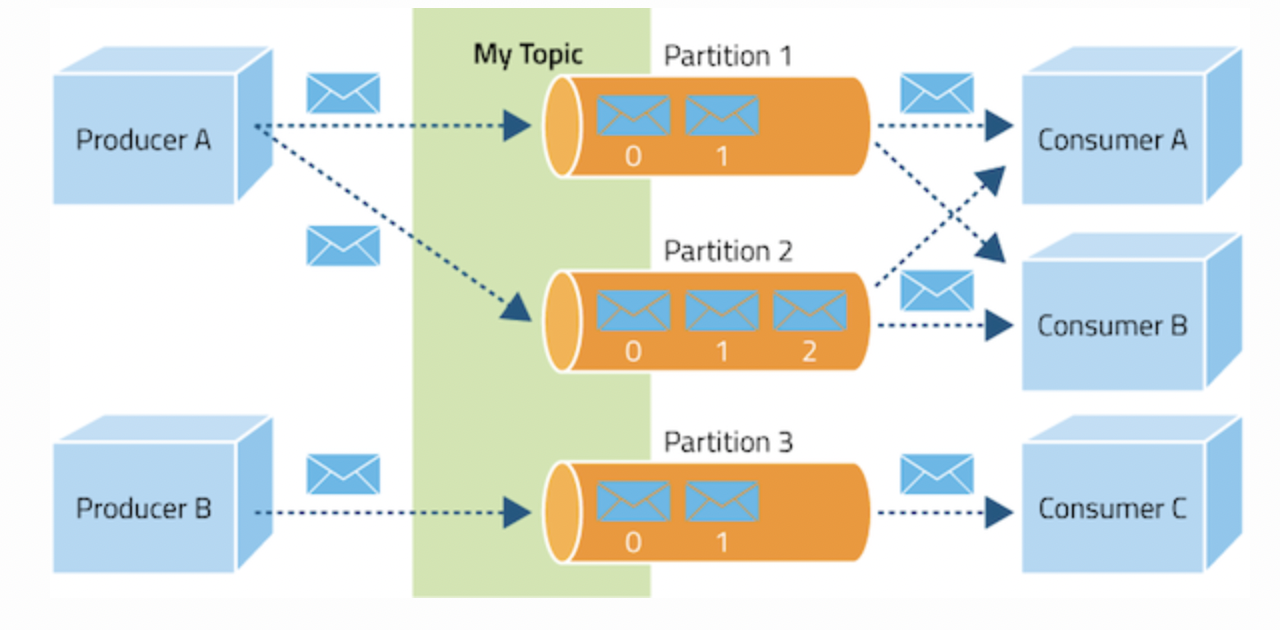
Topic Retentions Policies can be defined, by how much or how long we want to keep data available in Kafka. It is also pertinent to note that Kafka provides a tool called Kafka-connect to other applications, like a PostgreSQL database or a Big Query Table, etc.
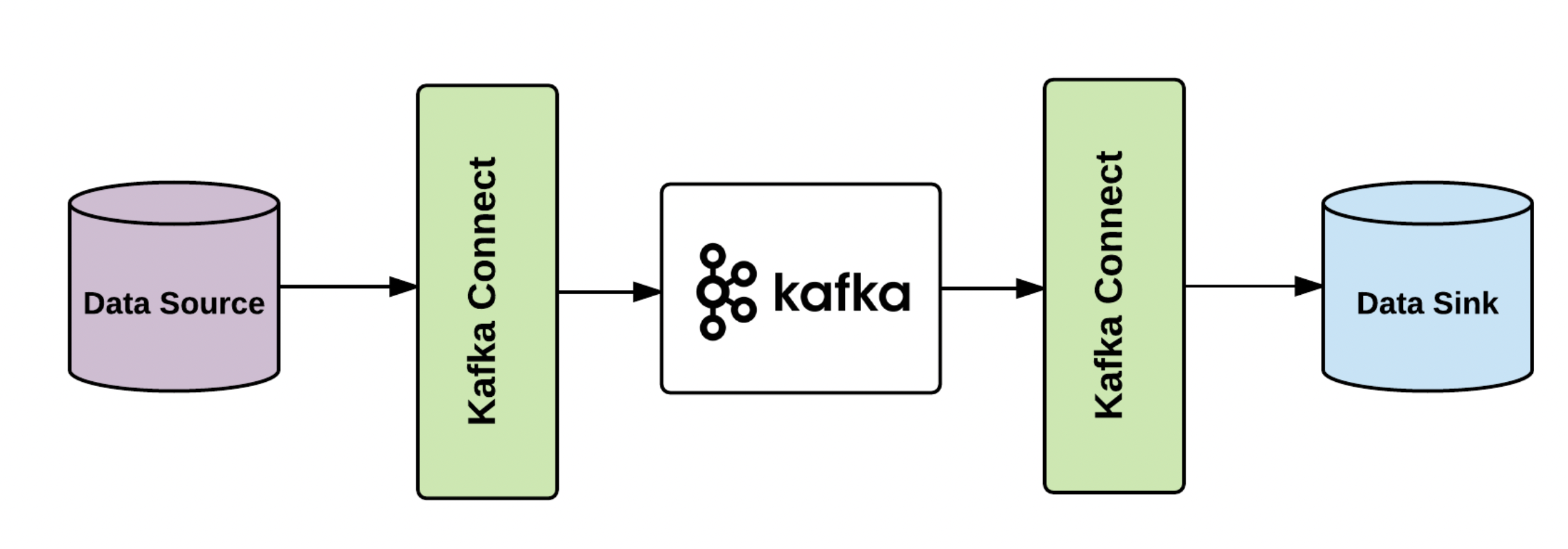
Hands-On Exercise
We will solidify our theoretical understanding of Kafka by getting hands-on experience by writing some simple code in python. The installation of Kafka can vary from OS to OS and one of the easier options available to us is to use Docker to run Kafka on our local machine. We write one docker-compose file which will take care of everything we need to run Kafka. If we have Docker and Docker-Compose installed we can get this running irrespective of the OS we are running on the local machine. Docker is an open-source platform for deploying and managing containerized applications. Docker allows packaging of our application along with dependencies into Containers which simplifies the distribution of applications. I would recommend the installation of Docker-desktop (link provided in the references below).
If you have installed Docker-Desktop, in the settings tab of the dashboard enables docker-compose. Now, go ahead and create a project directory.
mkdir av_blog_kafka cd av_blog_kafka
Now we create a virtual environment for our Kafka project. I have used conda to create my virtual environment, you can use any convenient tool for creating your virtual environment.
conda create --name av_blog_kafka
conda activate av_blog_kafka
This will activate the virtual environment named, av_blog_kafka.
Confirm installation of Docker and docker-compose,
docker --version
docker-compose --version

create a docker-compose.YAML file in the project directory. The contents of the file are as follows,
version: '3'services:zookeeper:image: wurstmeister/zookeepercontainer_name: zookeeperports:- "2181:2181"kafka:image: wurstmeister/kafkacontainer_name: kafkaports:- "9092:9092"environment:KAFKA_ADVERTISED_HOST_NAME: localhostKAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
We are using the images wurstmeister/zookeeper and wurstmeister/kafka to run the Kafka services . You need to ensure that ports 2181 and 9092 are available in the local machine or you may have to look at an alternate Port. We are spinning up two Containers, Zookeeper, and Kafka Containers. The environment variables passed to Kafka where the Kafka and zookeeper are running. Now run the following command on the Terminal in the project folder to get Kafka running on the local machine,
docker-compose up -d
The -d tag will run the Kafka services in the background and the terminal is available for further exploration. Run the following command to check the containers running,
docker ps

We can also check the running containers on the Docker-Desktop dashboard,
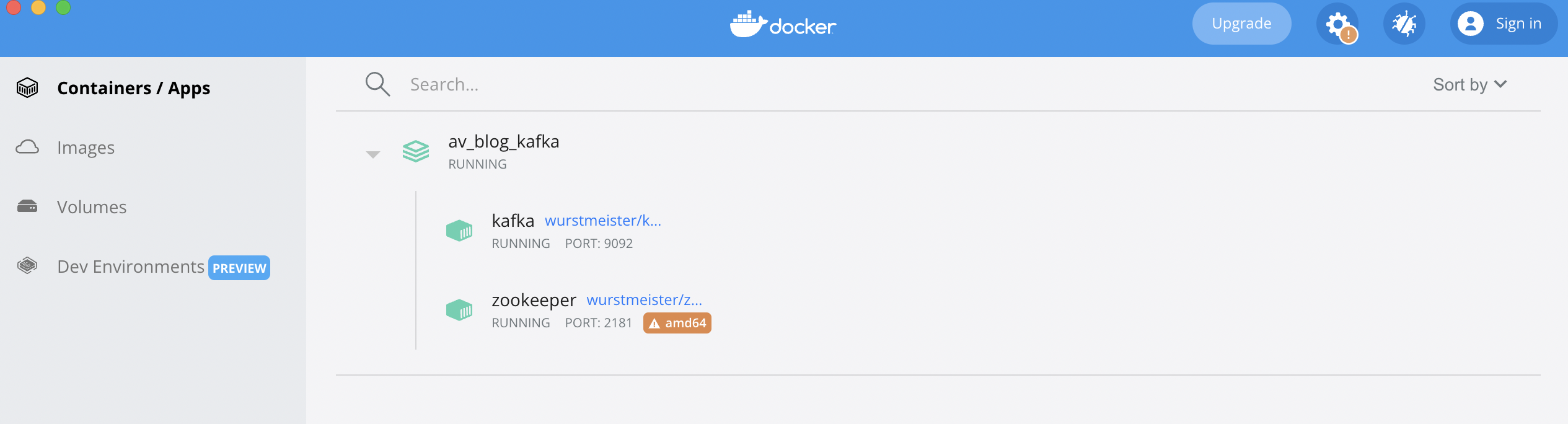
We will use Kafka-python to write a simple producer and consumer application. Use the following command(can use pip or conda) to install Kafka-python in the virtual environment,
pip3 install kafka-python
conda install -c conda-forge kafka-python
we can verify the installation with the following command,
pip3 list | grep Kafka-python
The above command should display the version of Kafka-python installed with pip command.
Now head over to a python editor of your choice(I have used Visual Studio Code) and write the python code for producer and consumer,
from kafka import KafkaProducer
from datetime import datetime
import time
import json
producer = KafkaProducer(bootstrap_servers=['localhost:9092'])
for i in range(1000):
msg = 'Sending Message ' + str(i) +' '+ str(datetime.now().time())
topic_name = 'kafka-demo'
producer.send(topic_name, key=b'Message', value=msg.encode())
print(f"Producing to {topic_name}")
producer.flush()
time.sleep(2)
We start by importing a Kafka producer from Kafka and initialising a new Kafka producer. The argument bootstrap_servers = [‘localhost:9092’] sets the Host and Port.. We will use a simple python for loop to create a series of 1000 messages. The value of the message includes the loop sequence and the timestamp in string format. In the same loop, we send the message to the topic (named Kafka-topic ) using the send method on the producer. The loop takes 2 seconds to break at the end of one iteration.
Similarly, we can write a python script for consumer.py.
from kafka import KafkaConsumer
consumer = KafkaConsumer('kafka-demo',bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest')
for message in consumer:
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value)
We need to import KafkaConsumer from Kafka and initialize a kafkaConsumer . We pass the argument bootstrap_servers as we did for the Producer. The auto_offet_reset parameter indicates where the consumer starts consuming the message in case of a breakdown or interruption. The parameter set to earliest will have the consumer reading at the latest committed offset and the parameter set to latest will have the consumer consuming from the end of the log.
We have used another for loop to print the messages received by the consumer and we print out the Topic, Partition, Offset, key, and value of each message on the Terminal.
We got Kafka set up going, and our producer and consumer script are ready. We can execute the script and see the event streaming running on the terminal. Open two terminals side by side (hint for Mac users: I used a tool called ITerm2 to vertically split the terminal). On one tile, we will run producer.py and in another tile, we will run consumer.py.
python producer.py
python consumer.py

We can see the producer publishing the message and messages being consumed by the consumer. You can interrupt consumer.py (use ctrl+c) for a short while and restart(again use command python consumer.py) to watch at which offset the consumer starts reading after the resumption. This will make the aspect of auto_offset_reset parameter in the Consumer instance clear. The producer and consumer code we used is quite basic and I would recommend to the readers to look at other parameters of producer and Consumer instance from the documentation.
Conclusion
In the current scenario, a large amount of real-time data which needs to be processed in real-time is being generated through sensors, financial markets etc. Kafka is a popular Event Streaming Platform and this article introduces the basic concepts of Kafka. The key learnings in understanding the basics of Kafka are as follows,
- Kafka is a high-performance, durable, scalable distributed system and operates as a cluster
- The three main components of Kafka are broker, producer, and consumer. The producers publish events to Kafka and consumers read messages from Kafka. The messages are stored on the broker in partitions with replication for fault tolerance
- The Apache Kafka provides a python API to write our producer and consumer applications in python
- Docker provides an easy option for running Kafka on the local system
- There are multiple vendors which offer Kafka as a managed service as an alternative to in-house management of Kafka services.
- We also used Docker-Compose to run a single node Kafka Cluster and used python to write a simple producer and consumer applications to run in the above cluster.
References
(1) https://kafka.apache.org/intro
(2) https://www.docker.com/products/docker-desktop/
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A Marine Engineering professional with more than 29 years experience with a passion to leverage data for business solutions. I am a post graduate In Mechanical Engineering with experiences ranging from Operations, Production, Project Management, Quality Management and Data Analytics. I have also completed Advanced Certification in Data Science from Thayer School of Engineering , University of Dartmouth. I strongly believe learning is continuous process for growth in life and sharing knowledge builds a sense of community






