This article was published as a part of the Data Science Blogathon.
Introduction
Hive is a popular data warehouse built on top of Hadoop that is used by companies like Walmart, Tiktok, and AT&T. It is an important technology for data engineers to learn and master. It uses a declarative language called HQL, also known as Hive Query Language, which is almost similar to SQL. Hence, this makes SQL database engineers and newbies with SQL knowledge work on data engineering tasks. Internally, HQL acts as an abstraction to the map-reduce code, which many developers find difficult to write and debug. Since the map-reduce code is replaced with HQL, the development time reduces drastically, which is seen as a major advantage. All the data is stored in a structured format and looks and feels like a normal MySQL database, which simplifies things for developers. As mentioned earlier, Hive is a data warehouse and supports batch processing only. The reason why Hive does not support real-time data processing and tracking is because of the very high latency and humongous amount of data. Also, Hive performs very poorly on small datasets.
In this article, we will explore partitioning and bucketing in Hive and how they can be implemented using HQL.
Partitioning in Hive
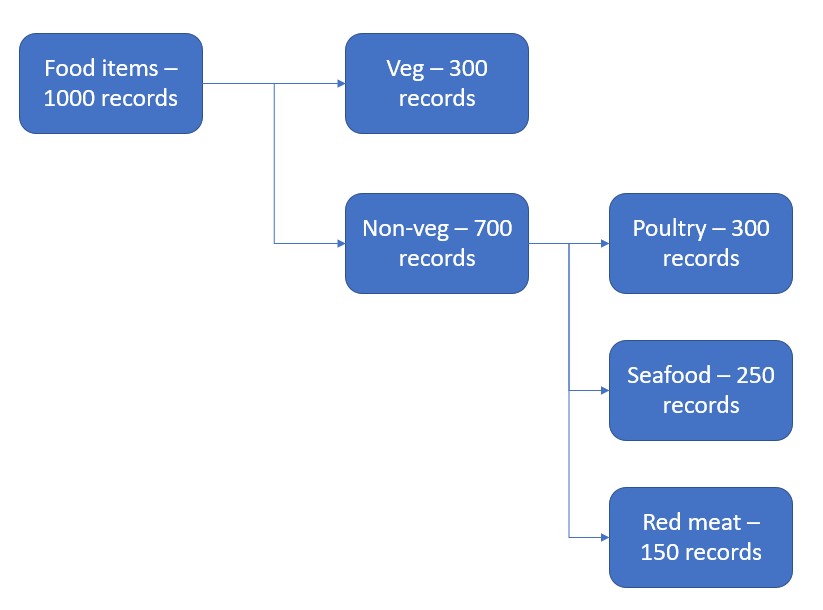
Partitioning is one of the popular strategies to improve the performance of Hive. In essence, partitioning is just a formal way to store data inside multiple folders by segregating them using some specific criteria instead of storing everything inside a single folder. As the data is segregated, querying performance improves by leaps and bounds as the number of records reduces drastically. This also helps in reducing the computational complexity of queries. For example, consider you have a hive table containing 1000 food items and related information and one column named “vegetarian” that specifies if the type of food item is vegetarian or not. Assume that there are 300 vegetarian food items and 700 non-vegetarian food items. Also, assume that for vegetarian food items, the value is “1” and “0” otherwise. If we make a query that is specific to vegetarian food items, the hive server has to scan all the 1000 records in the hive table and return the response to the query. Now, let’s say we have partitioned the table using the “vegetarian” column. The records would have been segregated into two folders, one containing the vegetarian food items and the other containing the non-vegetarian food items, and if we try to run the same query, the hive server would have to scan only the folder containing the vegetarian food items and so the total number of records being evaluated is reduced drastically, that is 300 records. I hope that comparing the number of records scanned before and after partitioning a table gives a better picture of how it helps in improving the performance and also, reduces the computational complexity of the queries. Also, the partitioning can extend up to any level like a hierarchy. To understand this better, in the example explained above, assume that there is a field that specifies the type of meat used in preparing the food item like ‘Red meat’, ‘Seafood’, ‘Poultry’, etc. Now we can further partition the table using this field as well. If done so, there would be folders created inside the non-vegetarian folder named ‘Red meat’, ‘Seafood’, etc. Hence, the hierarchy can keep extending and you can have granular control over the partitions to improve performance.
Hive supports static and dynamic partitioning. In dynamic partitioning, the partitions are created automatically and the data is segregated and loaded in their respective directories by Hive. In static partitioning, the partitions should be created manually by us and the respective data should also be loaded by us. Dynamic partitioning is used when the number of partitions is large, but in terms of loading time, static partitioning performs better. Now that we know what partitioning is, let’s look at some queries for performing dynamic and static partitioning in Hive using HQL.
To enable dynamic partitioning in Hive, we need to run the following command.
$ hive.exec.dynamic.partition=true;
To set the maximum number of dynamic partitions, we need to run the following command. You can set any number of maximum dynamic partitions.
$ hive.exec.max.dynamic.partitions=1000;
At times, Hive does not use the partitions to improve performance and scans across all the records. To make sure that Hive takes the partitioning into account while responding to queries, we need to run the following command.
$ set hive.mapred.mode='strict';
To undo the changes made above, we need to run the following command.
$ set hive.mapred.mode='nonstrict';
$ create table {table_name}({column_name} {data_type}, {column_name} {data_type}, {column_name} {data_type}) partitioned by ({partition_column_name} {data_type}, {partition_column_name} {data_type}, {partition_column_name} {data_type});
The above query is used to create dynamic partitions in Hive. The columns used for partitioning a table should be included inside the create table command as they would be automatically added by Hive.
To view all the partitions on a table in Hive, run the following.
$ show partitions {table_name};
To create partitions statically, we first need to set the dynamic partition property to false.
$ hive.exec.dynamic.partition=false;
Once that is done, we need to create the table and then load the data. To create a hive partition table, run the following query.
$ create table {table_name} ({column_name} {data_type}, {column_name} {data_type}, {column_name} {data_type}) partitioned by ({partition_column_name} {data_type}, {partition_column_name} {data_type}, {partition_column_name} {data_type});
Now, to load the data inside the table, run the following query.
$ insert into {table_name} partition ({partition_col}='condition_1', {partition_col}='condition_2', {partition_col}='condition_3') select {column_name}, {column_name}, {column_name} from {unpartitioned_table_name} where (({partition_col}='condition_1') and ({partition_col}='condition_2') and ({partition_col}='condition_3'));
Bucketing in Hive
Bucketing is another strategy used for performance improvement in Hive. Bucketing is usually applied to columns that have a very high number of unique values. Bucketing segregates records into a number of files or buckets. Internally, a hash value is generated for every unique value in the column used for bucketing. The hash value generated for every record determines the bucket it belongs to. It is designed using the concept of hash table data structure. Bucketing requires us to specify the number of buckets we want the data to be stored in. The preferred number of buckets is generally calculated using the total data size and the size of each block in HDFS, which is 128MB by default.

To perform bucketing on a table, we need to run the following query.
create table {table_name} ({column_name} {data_type}, {column_name} {data_type}, {column_name} {data_type}) clustered by ({bucketing_column_name}) into {n} buckets;
Conclusion
In this article, we covered the following.
- What is Hive?
- What is partitioning in Hive?
- How to partition a table using HQL?
- What is bucketing in Hive?
- How to perform bucketing using HQL?
Hive is being used in major tech companies for data warehousing to store huge amounts of data and has become an important member in the domain of data engineering as it enables developers with SQL backgrounds to write map-reduce code using HQL and improves productivity and reduces the development time. Hive has become a must for data engineers these days. This article discusses only two topics among the lot. If you are interested in data engineering and wish to learn the basics of Hive, refer to this article. For learning advanced concepts in Hive, refer to this article.
That’s it for this article. Hope you enjoyed reading this article and learned something new. Thanks for reading and happy learning!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I love exploring ML, DL, Machine Vision, Databases, and Full-stack Web Development. I've worked on multiple projects with different stacks and I also hold a patent in the domain of machine vision for manufacturing.





