This article was published as a part of the Data Science Blogathon.
Introduction
With the exponential surge in the availability of digital content and the increasing number of internet users, a potential challenge of information overload has been created, whereby the timely and suitable access to information or items of interest is being hindered on the internet. To solve the increasing plethora, information retrieval digital platforms have attempted to partially solve the problem by developing “intelligent systems” that would map the available content to users’ choices and preferences. These “intelligent systems” are recommender systems, which is the topic of discussion for the rest of this post!

Image Source: http://surl.li/cfhoc
Recommender systems can be defined as a tool that helps users search through a history of knowledge that is related to his or other user’s preferences and choices. Thus they serve as a means to assist and augment the social process of using recommendations of others to make choices when there is no firsthand knowledge or experience of the possible alternatives available. These systems thus serve as information filtering routes to help tackle the problem of information overload by filtering the vital information out of the vast network of information available for the interests and preferences of other digital users. Because of having the inherent capability of predicting whether a particular product or service would be preferable to the user based on the user’s profile – recommendation systems are beneficial to both the user and service provider. From the service provider’s perspective, they help increase the conversion rate by allowing the customers to find their desired products. They also help the company increase sales by suggesting the customers’ other products on their wishlist. This helps improve customer loyalty and helps create a value-added relationship between the customer and the company.
Contemporary Examples of Recommender Systems
In today’s world, recommendation systems have found their usability in many areas. Video streaming platforms like Youtube, Netflix, and Amazon use it to provide video recommendations to their users. Google uses these systems to deliver relevant ads to the users, which serve as the primary source of their revenue. Music streaming platforms like Spotify leverage these to provide music recommendations and, based on their tastes, suggests a new weekly playlist to their user, one of their most popular features. E-Commerce giants like Flipkart and Amazon use these as targeted marketing tools and provide customized product recommendations that the user would like to buy based on the similar products they had purchased earlier. Social networking sites like Facebook and Instagram provide friend/connection recommendations using these. Thus the applications of these recommender systems are many. Still, at its core, it uses either of the two approaches- content-based or collaborative filtering, details of which are discussed in the following sections.
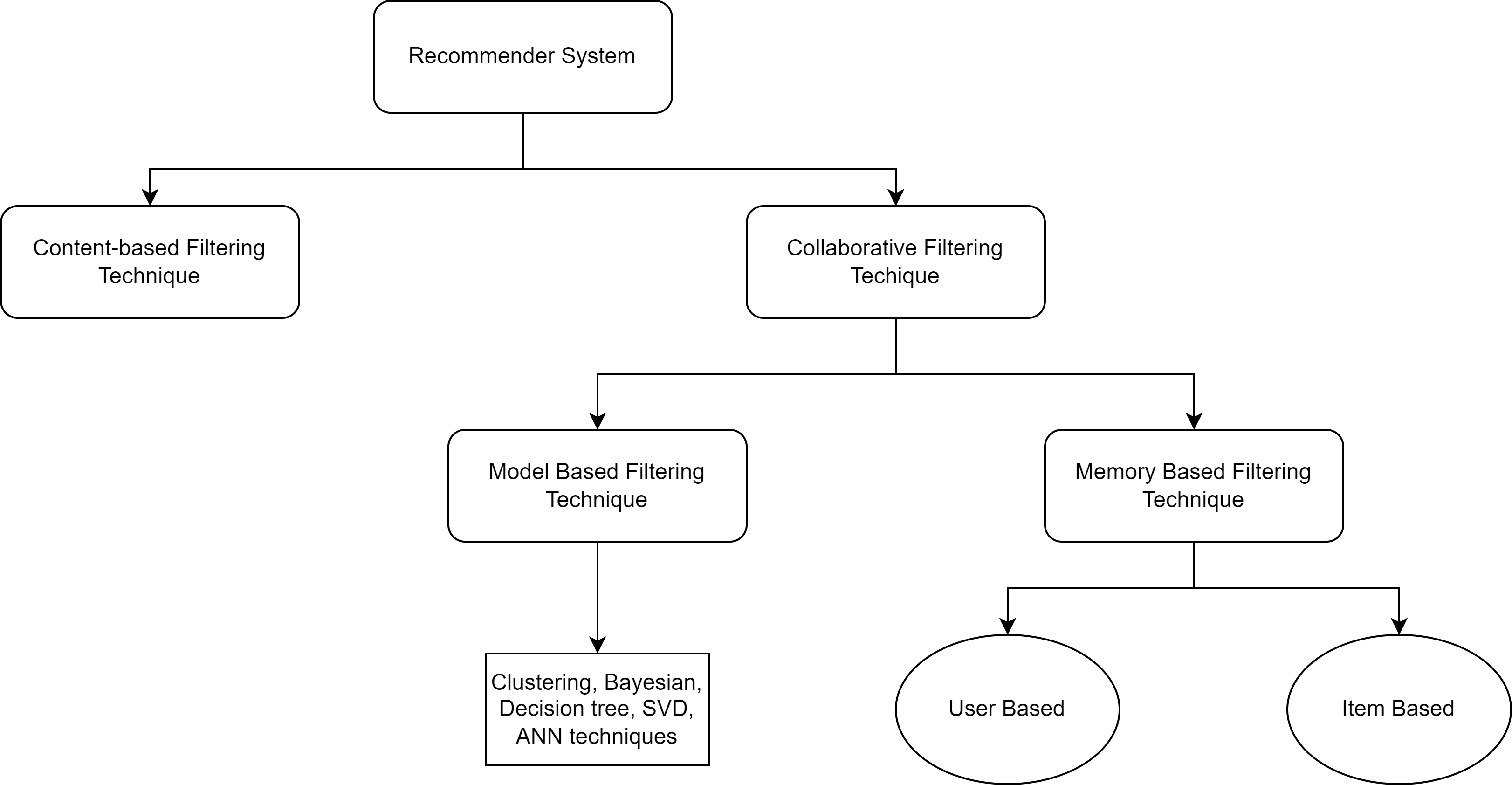
Schematic representation of the different classifications of recommendation systems
Content-Based Filtering
The algorithm behind the content-based approach is domain-dependent, and to make the predictions; it emphasizes more on the analysis of the attributes of the items. The recommendations of such an approach are based on a profile it creates for each user. Features are extracted from the content of the items the user has used in the past. Items that are mostly related to the positively rated items by the user are recommended. Content-Based Filtering (CBF) mostly can use Vector Space Models (like Term Frequency or Inverse Document Frequency) or Probabilistic Models (like Naive Bayes Classifier, Decision Trees) or Neural Networks to learn the underlying similarities between the different contents with the entire corpus of information.
In CBF, profiles of other users are redundant since they do not influence the recommendations. CBF can easily handle any preferences by the user profile within a short time and adjust its recommendations accordingly. They can recommend new items even if the database does not contain user preferences. Thus the need for sharing user profiles is obviated, which ensures privacy. However, CBF suffers from various drawbacks. Firstly the approach requires rich metadata with detailed descriptions of items and user profiles to make suitable recommendations. This limited the effectiveness, and users are often restricted from getting recommendations similar to items from their profiles. This limits the diversity of the choices.
Collaborative Filtering
Collaborative Filtering (CF) is free from the knowledge of the domain. It is beneficial for content that cannot be quickly and entirely described by the metadata, like movies and music. The main advantage of CF over CBF is domain independence, and it can address data aspects that are often masked and challenging to profile using CBF. How the CF works is that it creates a matrix of user-item data of preferences of each item for each user. It then matches users with relevant interests and preferences by calculating the similarity between their profiles to make recommendations. Such users build a collection called a neighborhood. A user can get recommendations that have not been positively rated by them but have been positively rated by their neighborhood. The two primary areas of CF are model-based techniques and memory-based techniques.
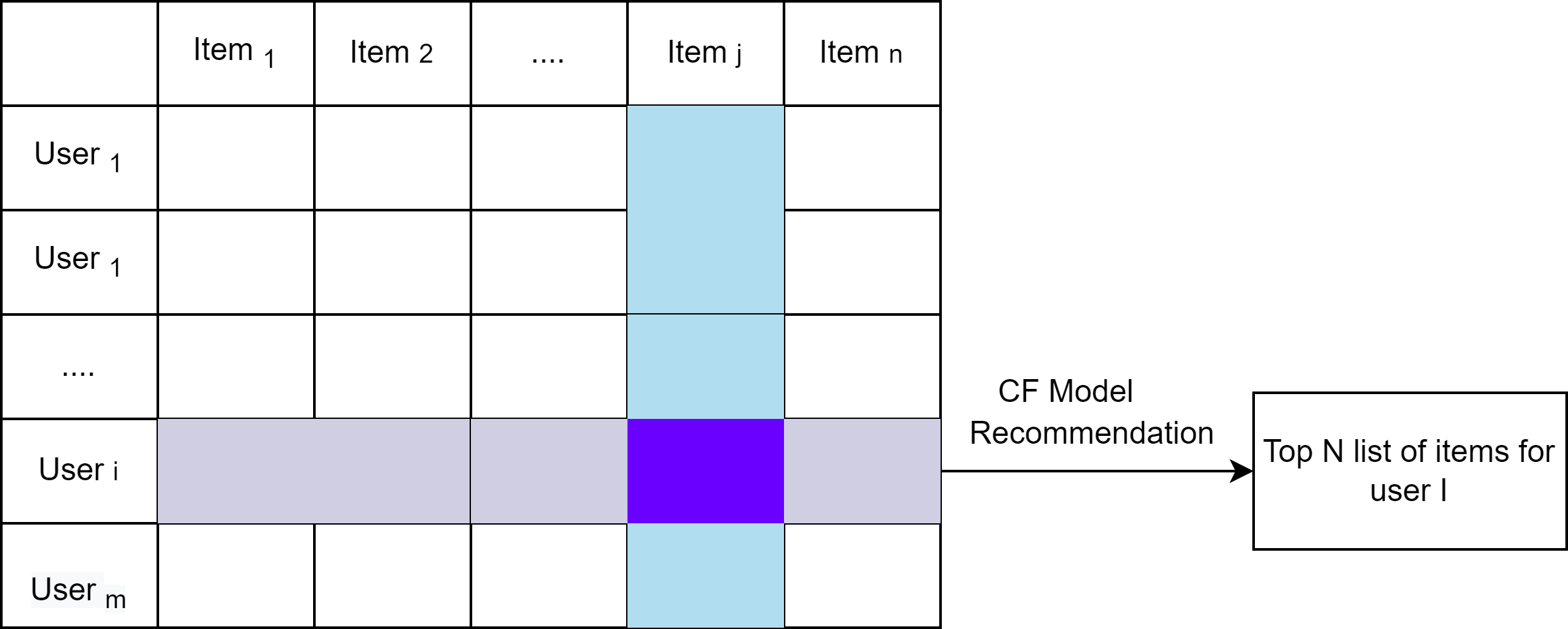
Schematic representation of the CF technique based on the User-Item matrix
Memory-Based Techniques
In this technique, the algorithm tries to find users who shared the appreciation with the same item that a user has rated positively in the past. Once the neighbors are defined, different algorithms can be used to combine the preferences of the neighbors to generate recommendations. This approach can be achieved in two ways: user-based and item-based techniques.
- User-based CF first calculates the similarity between the users based on the comparative rating on the same item, and then produces the predicted recommendation for a user as a weighted average of the ratings of the items by a user similar to the active user. Here the weights are decided by the similarities of the user with the target item.
- Item-based CF computes the recommendations based on the similarities between the items by building a model of item similarities. Similarities of all the rate items by a user are retrieved from the user-item matrix. It then determines how similar the retrieved items are to the target items and then recommends k best items.
Model-Based Techniques
- This technique uses machine learning or data mining-based models to learn previous ratings and improve the performance of the CF technique. The models are pre-computed, so they can quickly recommend a set of items. They leverage the inherent relations of the user-item matrix data and utilize those relations to compute the list of top N recommendations. Techniques like Singular Value Decomposition (SVD), Latent Semantic Methods, Naive Bayesian Classifiers, Regression, Clustering, Decision Tree, and Artificial Neural Networks (ANNs) find utility in this approach.
- While CF enjoys a significant advantage over CBF algorithms, they suffer from the “cold-start problem” due to their inability to address the systems’ new products and users.
Evaluation Matrices for Recommendation Systems
The quality of recommendation algorithms is evaluated using different measurements covering accuracy and coverage. The matric used depends on the algorithm used for the filtering technique. Mean Absolute Error (MAE) and Root Mean Square Error(RMSE) is the most common accuracy metric. Other accuracy matrices often include Receiver Operating Characteristics (ROC), Precision, Recall, and F-score. User discretion is necessary for selecting the suitable error matrice with the algorithm used.
Conclusion
In this article, a vivid idea of the theory of recommended systems has been provided. Starting with the concept of recommender systems, the idea of using these systems in the contemporary world has been discussed, thereby portraying the usefulness and necessity of such systems. Then the recommender systems were discussed from the theoretical perspective of the algorithms utilized for building them and the pros and cons of each approach. Finally, the evaluation matrices used to validate the models were discussed briefly.
I hope reading the article up to this point must have ignited your enthusiasm to try and develop one such recommendation system. Here is what you can try to build.
Movie Recommendation System: Available dataset – Movielens 25M Dataset, Netflix Prize Dataset
Song Recommendation System: Available dataset – Million Song dataset, Spotify Music Dataset
Go quick and try your hands at recommender systems with these datasets!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Advancing language model research by day and writing about my work online by night. I explore AI breakthroughs and transform complex studies into clear, engaging insights that empower professionals and enthusiasts alike.
Thanks for stopping by my profile!






