This article was published as a part of the Data Science Blogathon.
Introduction on Quechua
In this article, we will create an app for translating Spanish Audio transcriptions to Quechua. We will leverage the Gradio Python package for creating a web interface for the model and deploy our app on Hugging Face Spaces.
With the advent of the internet, everything is getting urbanized, which has its pros, but like anything else, has its drawbacks too. As the new generation becomes fluent in the language of the internet, the languages on the verge of extinction will be greatly impacted. To solve this, digital solutions for indigenous languages be developed in time; otherwise, given the rate of progress and global change, revitalizing indigenous languages will be challenging. With these factors in mind, we must develop solutions that will aid in the revitalization and protection of indigenous languages. To get around this, here is an attempt to devise an app for translating Spanish audio transcriptions to Quechua.

Tools
- Hugging Face pipeline function
- Model for ASR
- Model for translating Spanish transcript to Quechua
- Hugging Face Spaces
- Gradio
Why is it Important to Protect and Revitalize Indigenous Languages?
A language is a tool for communicating and uniting people. Usually, the people who have the same language and cultural identity as them tend to bond more closely/easily. If a language dies, so does one of the incentives for people to communicate with one another. Also, not only will the language perish, but we will also lose access to a wealth of traditional information that may be beneficial. Furthermore, because indigenous language preservation may indeed be the means to eradicating discrimination against indigenous peoples and strengthening the link between culture, language, and identity, it becomes even more important to preserve and revitalize them.
Core Idea
The key concept is that we will feed audio (speech) input into the ASR module (Module1), which will transform Spanish speech into text. The resulting audio transcription will then be transmitted to the Quechua translator module (Module 2), which will translate the Spanish audio transcription to Quechua (Refer to Figure 1).
Module 1 (ASR Module)
For converting speech to the corresponding text we will be leveraging “jonatasgrosman/wav2vec2-xls-r-1b-spanish” pre-trained model from the Hugging Face hub which has been trained and contributed by Jonatas Grosman. This model is a fine-tuned version of facebook/wav2vec2-xls-r-1b on the Spanish Common Voice 8.0 dataset. For using this model one needs to ensure that the speech input is sampled at 16 kHz.
Module 2 (Quechua Translator)
For converting Spanish audio transcriptions we will be utilizing the t5-small-finetuned-spanish-to-quechua-model. This model was fine-tuned by Sara Benel and Jose Vílchez on the Spanish to Quechua dataset.
Furthermore, we will utilize Gradio‘s Interface class to establish a UI for the machine learning model(s) and deploy our app on Hugging Face Spaces.
Step-by-step Implementation
The steps below will walk you through developing a Gradio app for Spanish ASR and then translating the resulting transcription to Quechua.
Step 1: Building a Hugging Face account and repository for the Gradio app
If you don’t already have a Hugging Face account, please visit the website and create one. After you’ve created a Hugging Face account, go to the top-right side of the page and click on the profile icon, and then the ‘New Space’ button. Then you’ll be directed to a new page where you’ll be asked to name the repository you want to create. Give the space a name, and then choose ‘Gradio’ from the SDK options before clicking the ‘create new space’ button. As a result, the repository for your app will be created. For your convenience, I’ve provided a demonstration video below.
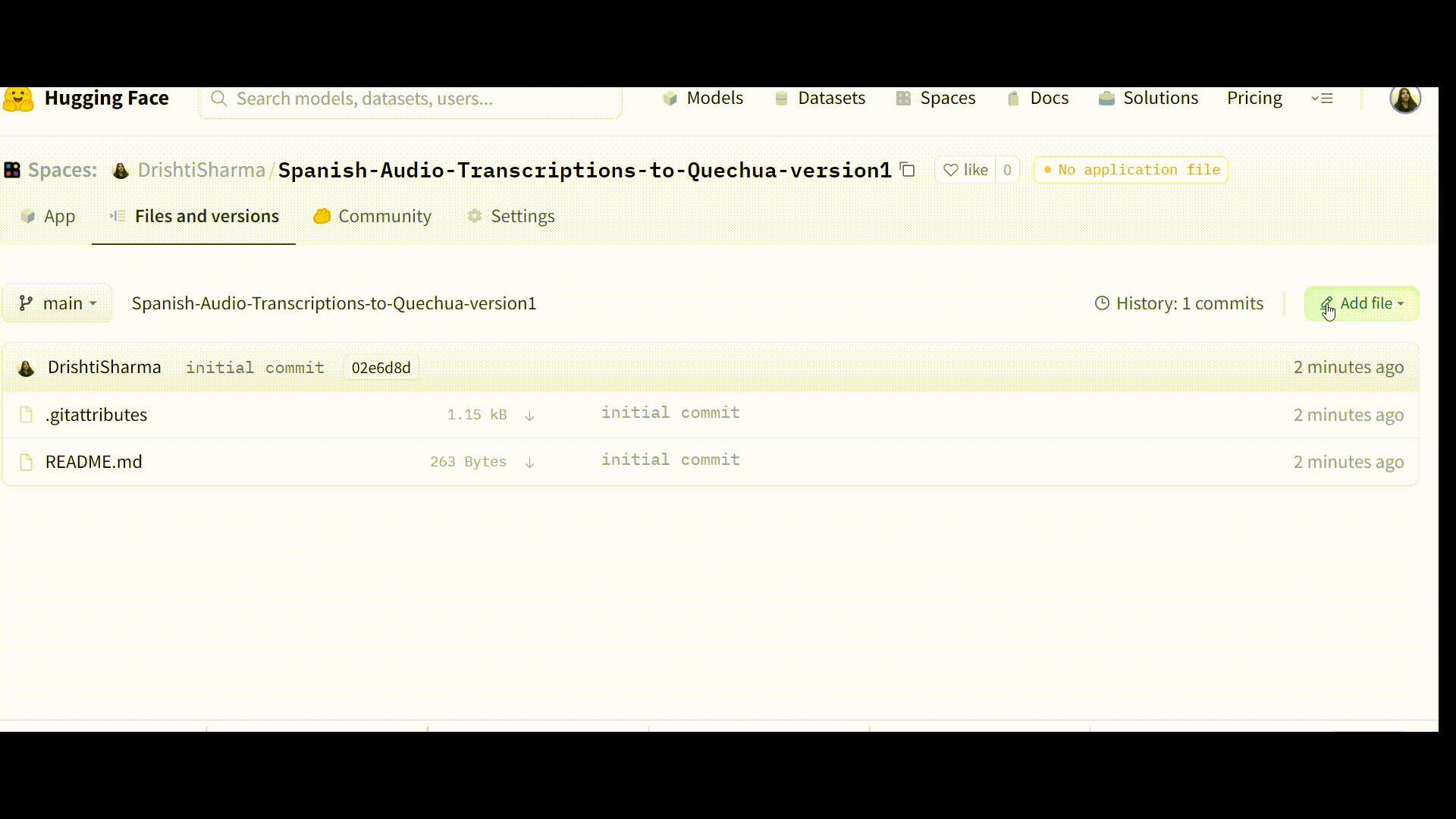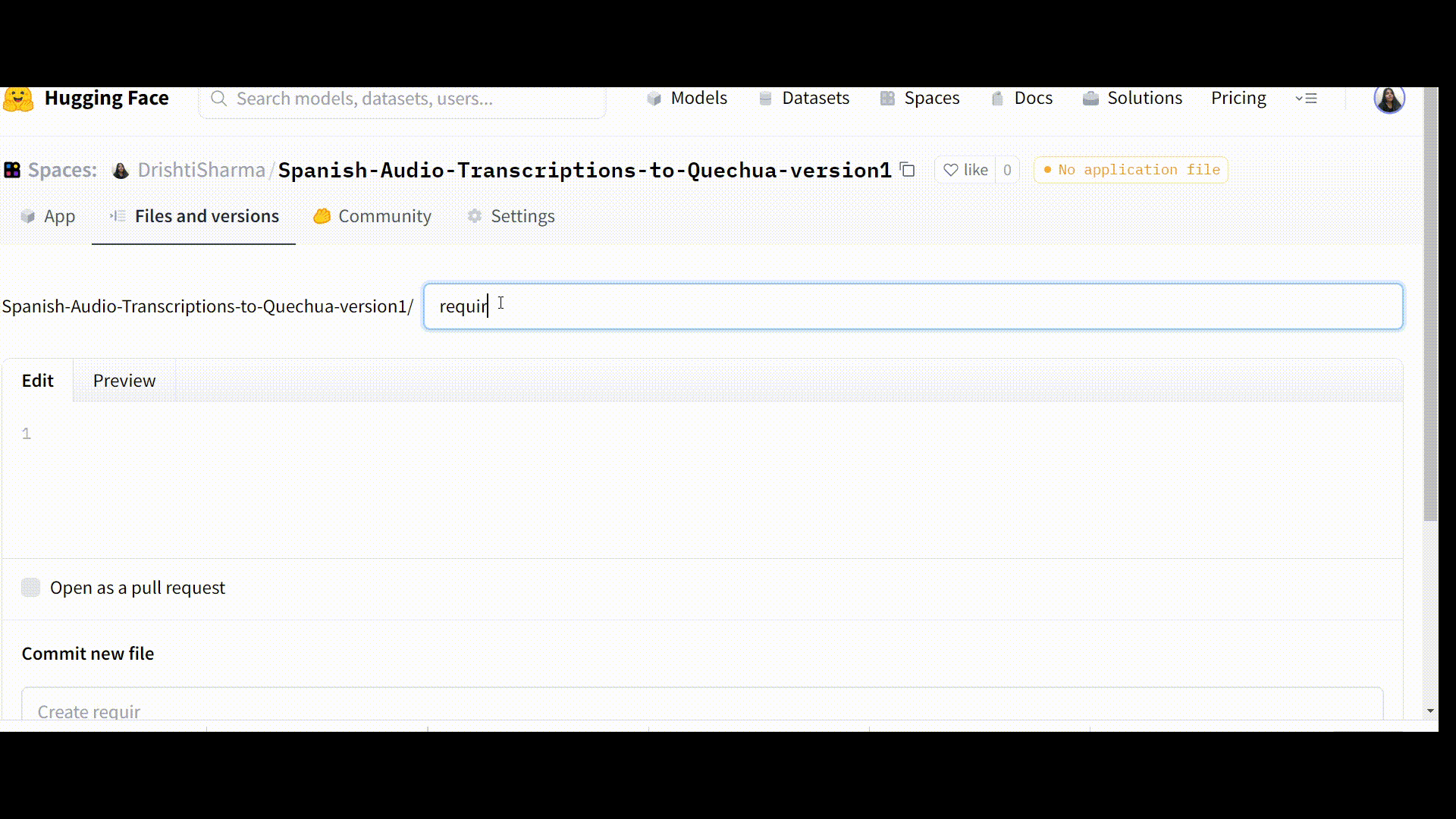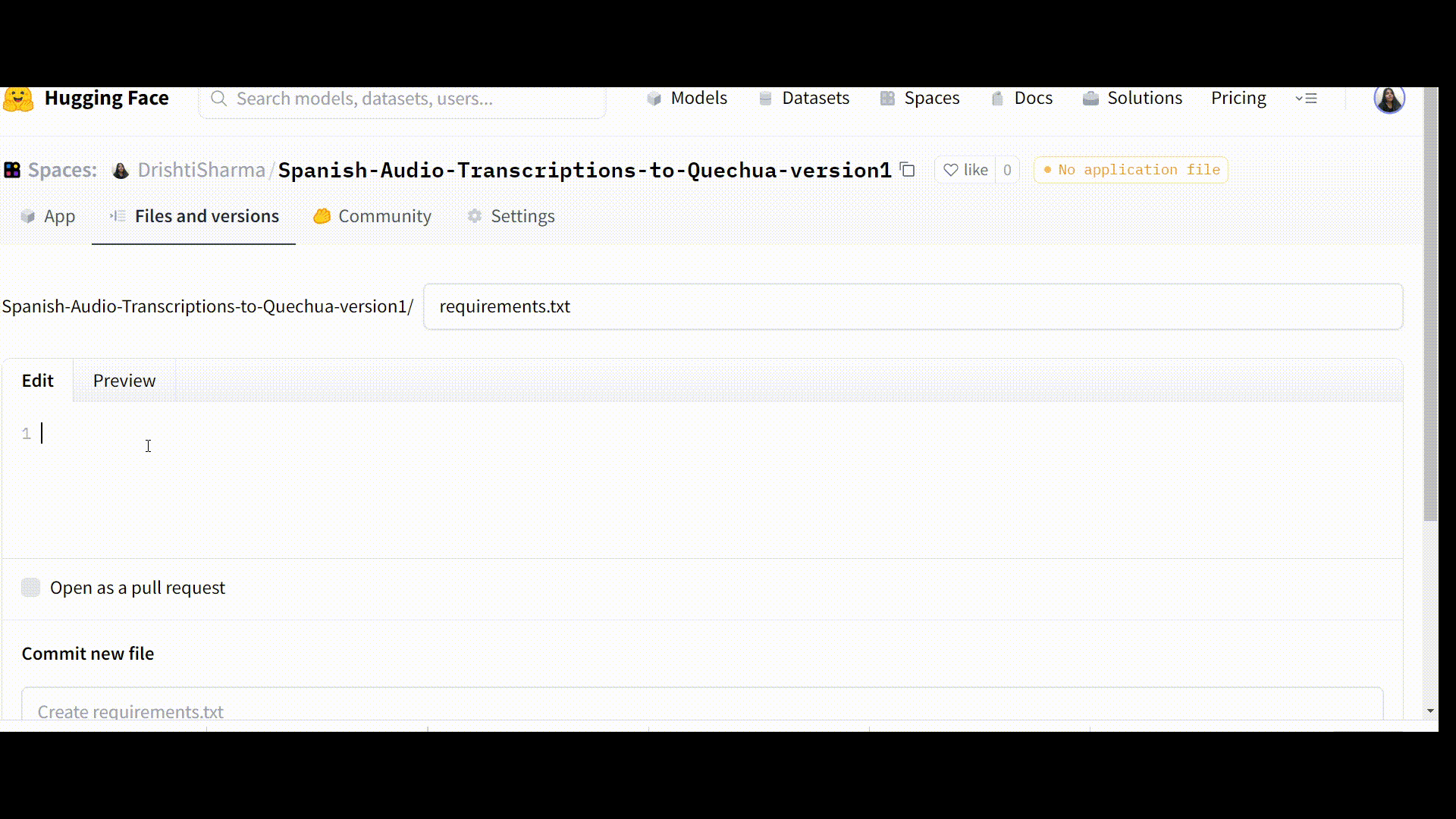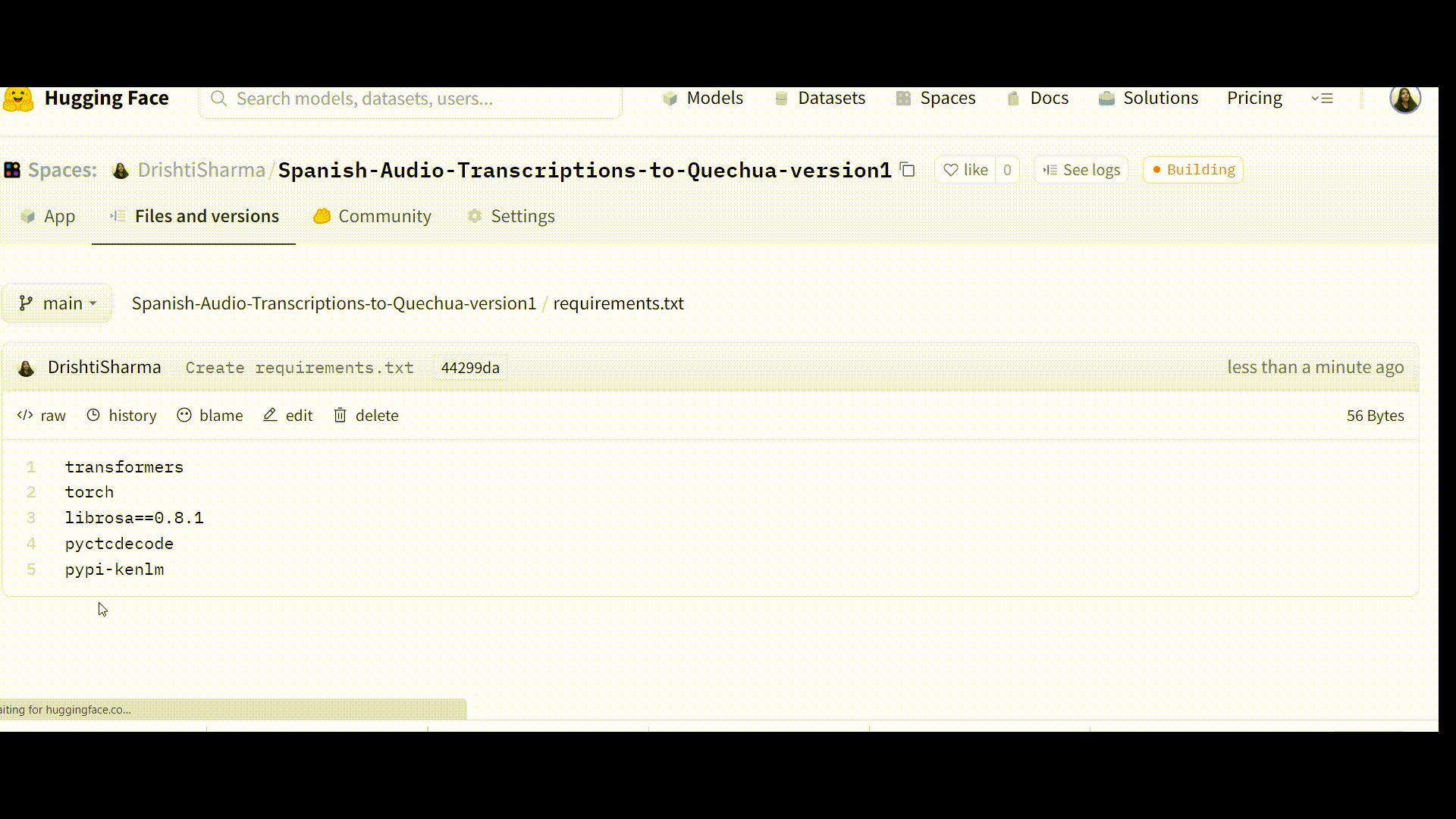
Step 2: Creating a Requirements.txt File
Now we will create a requirements.txt file in which we will list the Python packages for our app to run successfully. Those dependencies will be installed with the help of pip install -r requirements.txt.
We will need to add transformers, torch, librosa==0.81, pyctcdecode, and pypi-kenlm.
Step 3: Creating app.py File
For the sake of clarity and to make things easier to understand, I’ve broken the code into sections. We’ll go over each code block one by one.
1. Import Necessary Libraries
We will start with importing the required libraries.
import gradio as gr import librosa from transformers import AutoFeatureExtractor, AutoModelForSeq2SeqLM, AutoTokenizer, pipeline
2. Defining a Function that Makes Sure that the Speech Input has a Sampling Rate of 16kHz
Now we will define a function that makes sure that the speech input has a sampling rate of 16 kHz
def load_and_fix_data(input_file, model_sampling_rate):
speech, sample_rate = librosa.load(input_file)
if len(speech.shape) > 1:
speech = speech[:, 0] + speech[:, 1]
if sample_rate != model_sampling_rate:
speech = librosa.resample(speech, sample_rate, model_sampling_rate)
return speech
3. Specifying the Model Name, Loading the Feature Extractor, and Setting Up the Pipeline for ASR
For converting the Spanish speech to text, we will be leveraging “jonatasgrosman/wav2vec2-xls-r-1b-spanish” model. We will also be downloading the feature extractor via AutoFeatureExtractor class and will calculate the sampling rate. Then, as illustrated below, we’ll instantiate a pipeline by calling pipeline() for automatic speech recognition:
#Loading the model and feature extractor for ASR
model_name1 = "jonatasgrosman/wav2vec2-xls-r-1b-spanish"
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name1)
sampling_rate = feature_extractor.sampling_rate
asr = pipeline("automatic-speech-recognition", model=model_name1)
4. Loading the Model and Tokenizer for Translating Spanish Transcription to Quechua
#Loading the model for Spanish-to-Quecua translation model_name2 = 'hackathon-pln-es/t5-small-finetuned-spanish-to-quechua' model = AutoModelForSeq2SeqLM.from_pretrained(model_name2) tokenizer = AutoTokenizer.from_pretrained(model_name2)
new_line = 'nnn'
5. Defining a Function for ASR
#Defining a functionfor ASR
def speech_to_text(input_file):
speech = load_and_fix_data(input_file, sampling_rate)
transcribed_text = asr(speech, chunk_length_s=15, stride_length_s=1)
transcribed_text = transcribed_text["text"]
return transcribed_text
6. Defining a Function for Translating Spanish Audio Transcription to Quechua
#Defining a function for translating the Spanish audio transcription to Quechua
def translation(transcribed_text):
input = tokenizer(transcribed_text, return_tensors="pt")
output = model.generate(input["input_ids"], max_length=40, num_beams=4, early_stopping=True)
output = tokenizer.decode(output[0], skip_special_tokens=True)
return output
7. Defining a Function that will Generate a Spanish Audio Transcript and Translate that to Quechua
Finally, we’ll write a function that outputs the generated transcript for the Spanish input audio, as well as the translated transcript in Quechua.
def translate_spanish_transcription(input_file):
transcribed_text = speech_to_text(input_file)
output = translation(transcribed_text)
return f"Spanish Audio Transcription: {transcribed_text} {new_line} Quechua Translation: {output}"
8. Creating a UI For Model Using Gr.Interface
Next, we will utilize Gradio’s Interface class to establish a UI for the machine learning model by providing (1) the function, (2) the desired input components, and (3) the desired output components, which will allow us to quickly prototype and test our model. In our case, the function is translate_spanish_transcription. For providing the audio input, we will use a microphone or drop an audio file via a file path. In this regard, we will use this code: for providing input. And since the intended output is a string we will use outputs = gr.outputs.Textbox(label=”Output Text”) for displaying the string output. Finally, to launch the demo, call the launch() method.
⚠️If you wish to test audio files stored locally, ensure sure they’ve been uploaded and the location to them is listed in the examples (as shown in the code snippet below). It’s worth mentioning that the components can be specified as either instantiated objects or string shortcuts.
To upload audio files, simply click on the following tabs in the order listed here: “Files and versions” –> “Contribute” –> “Upload Files”
inputs = [gr.inputs.Audio(source="microphone", type="filepath", label="Record your audio")] outputs = [gr.outputs.Textbox()] examples = [["sunny_day.wav"], ["travel.wav"], ["sample_audio.wav"]] title="Spanish Audio Transcriptions to Quechua" description = """ This is a Gradio demo of Spanish Audio Transcriptions to Quechua Translation. To use this, simply provide an audio input (audio recording or via microphone), which will subsequently be transcribed and translated to the Quechua language. The pre-trained model used for Spanish ASR: [jonatasgrosman/wav2vec2-xls-r-1b-spanish](https://huggingface.co/jonatasgrosman/wav2vec2-xls-r-1b-spanish) The pre-trained model used for translating Spanish audio transcription to the Quechua language: [t5-small-finetuned-spanish-to-quechua](https://huggingface.co/hackathon-pln-es/t5-small-finetuned-spanish-to-quechua) """
gr.Interface(
translate_spanish_transcription,
inputs=inputs,
outputs=outputs,
examples=examples,
title=title,
description = description,
layout="horizontal",
theme="huggingface").launch()
Step 4: Debugging
If you get an error, please go to the “See log” tab, which is right next to the spot where Runtime Error is shown, take a cue from the error log and fix the error.
Once the Space is up and running error-free, it should work like this:
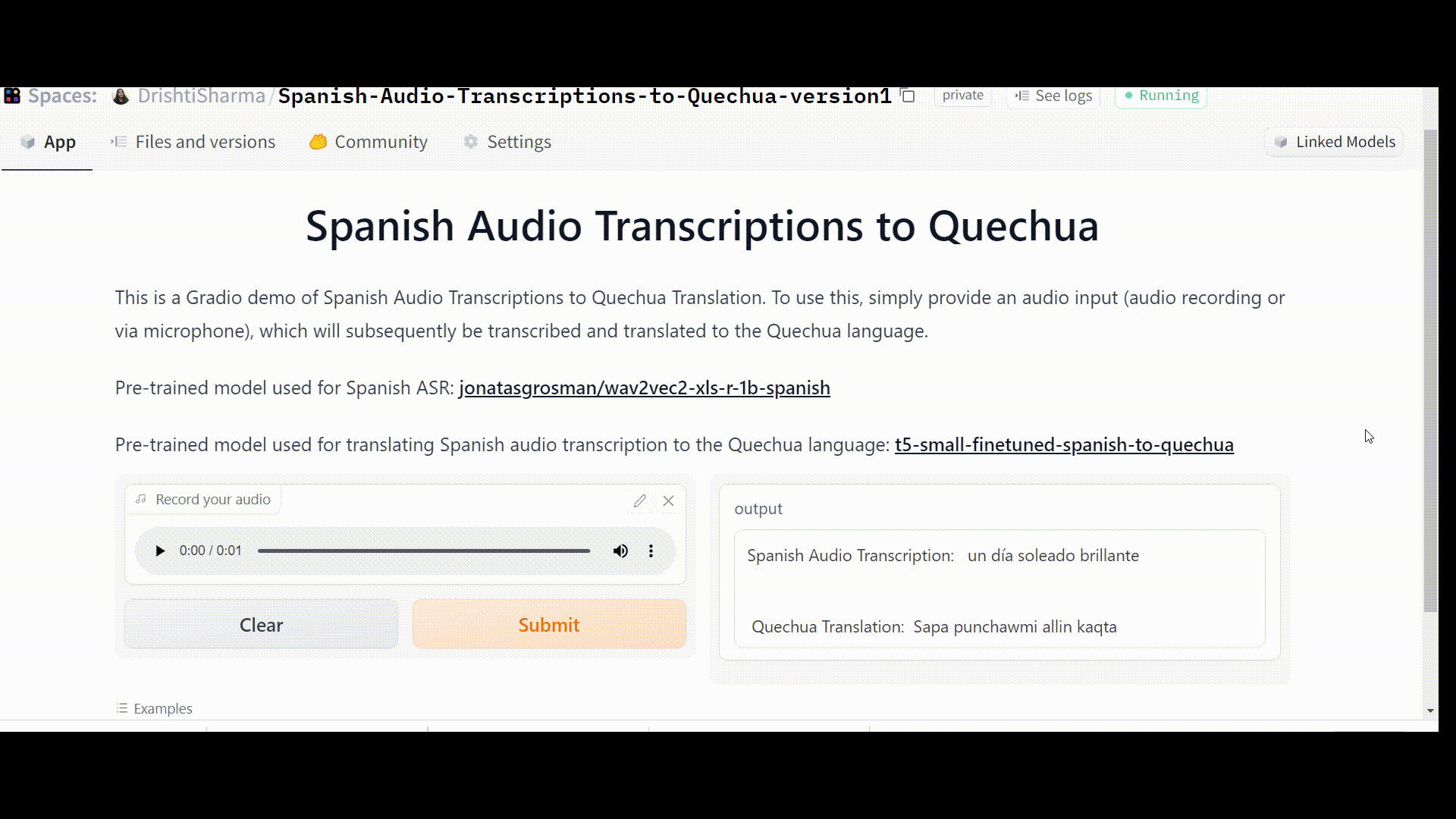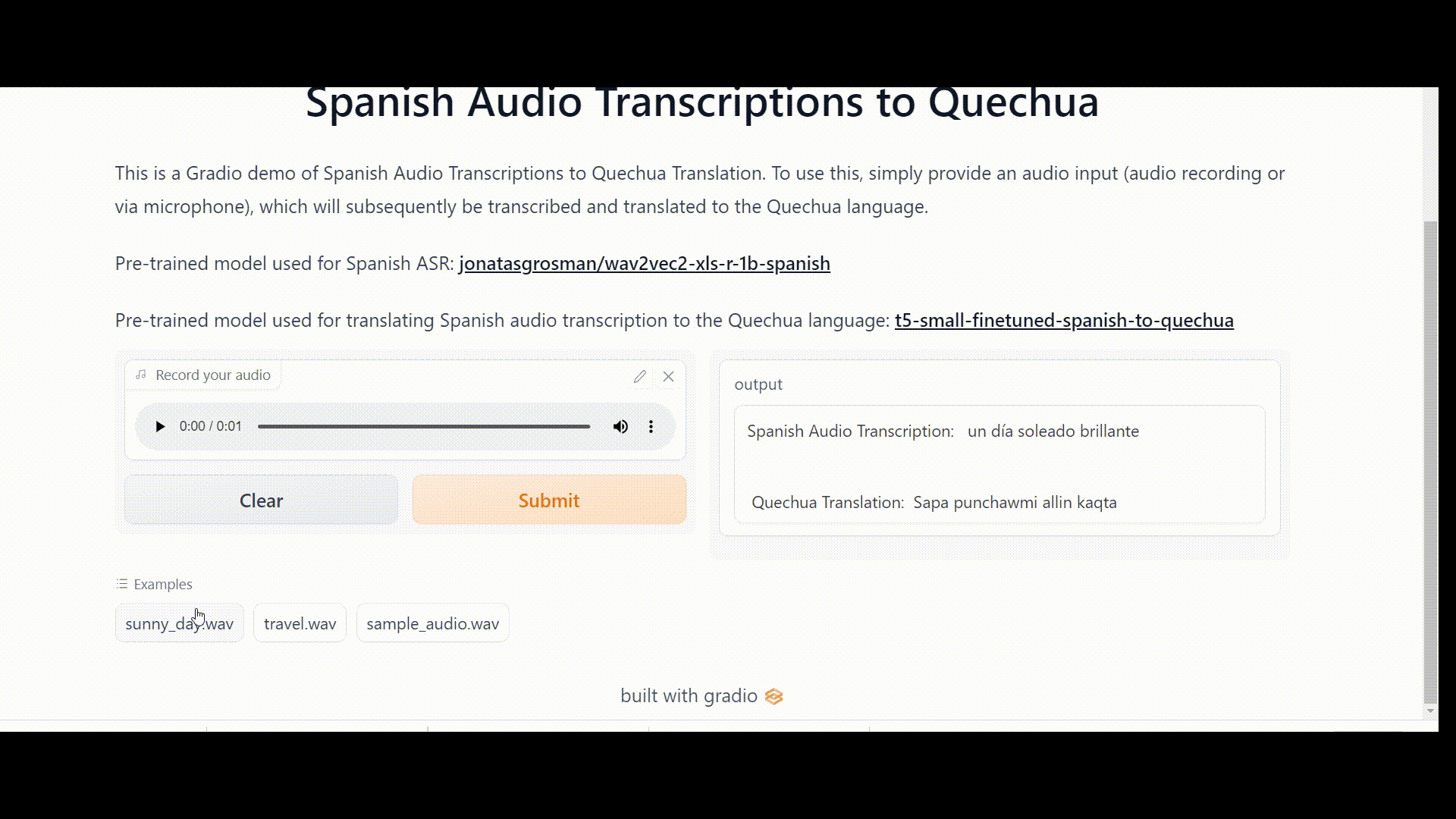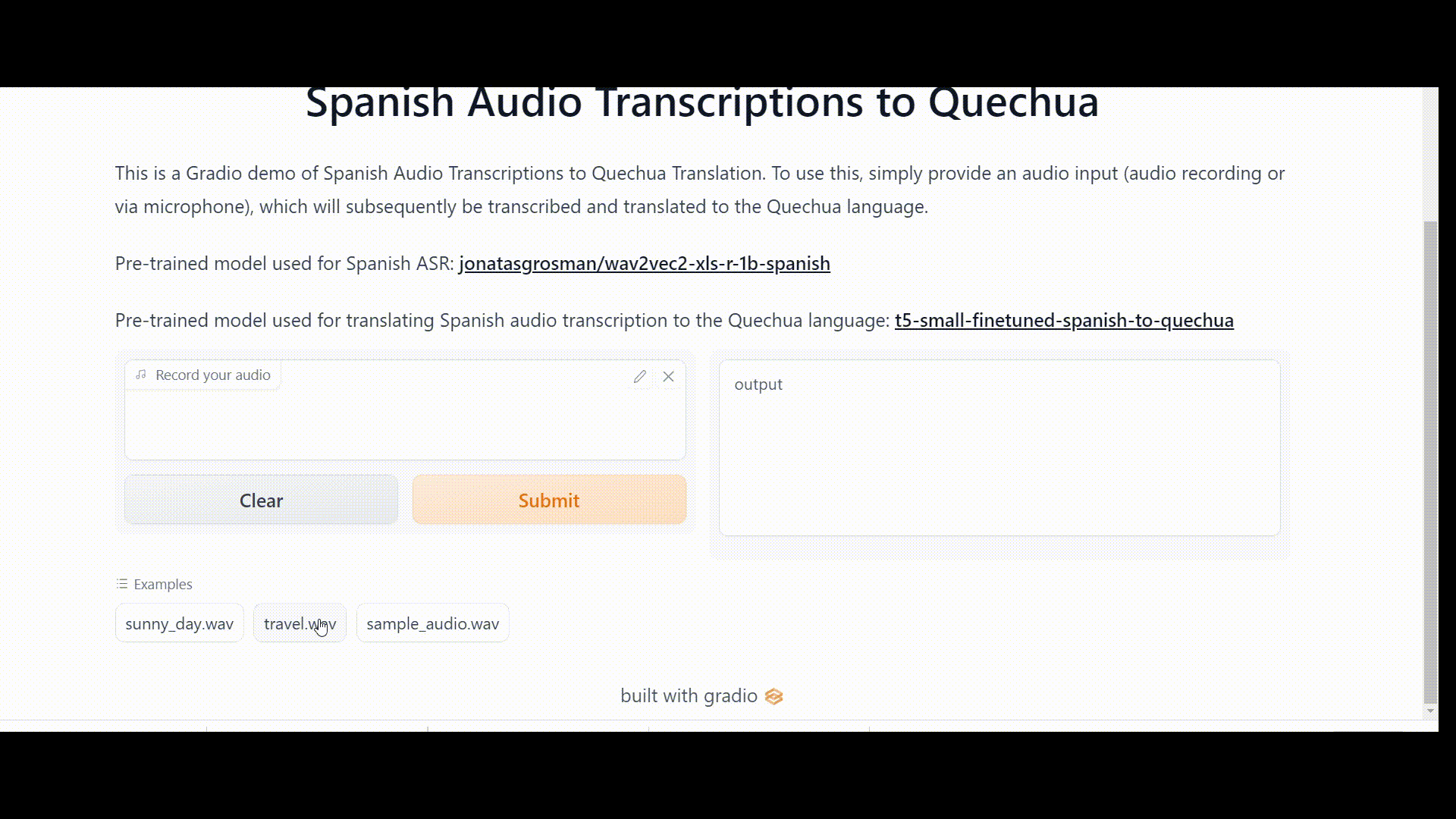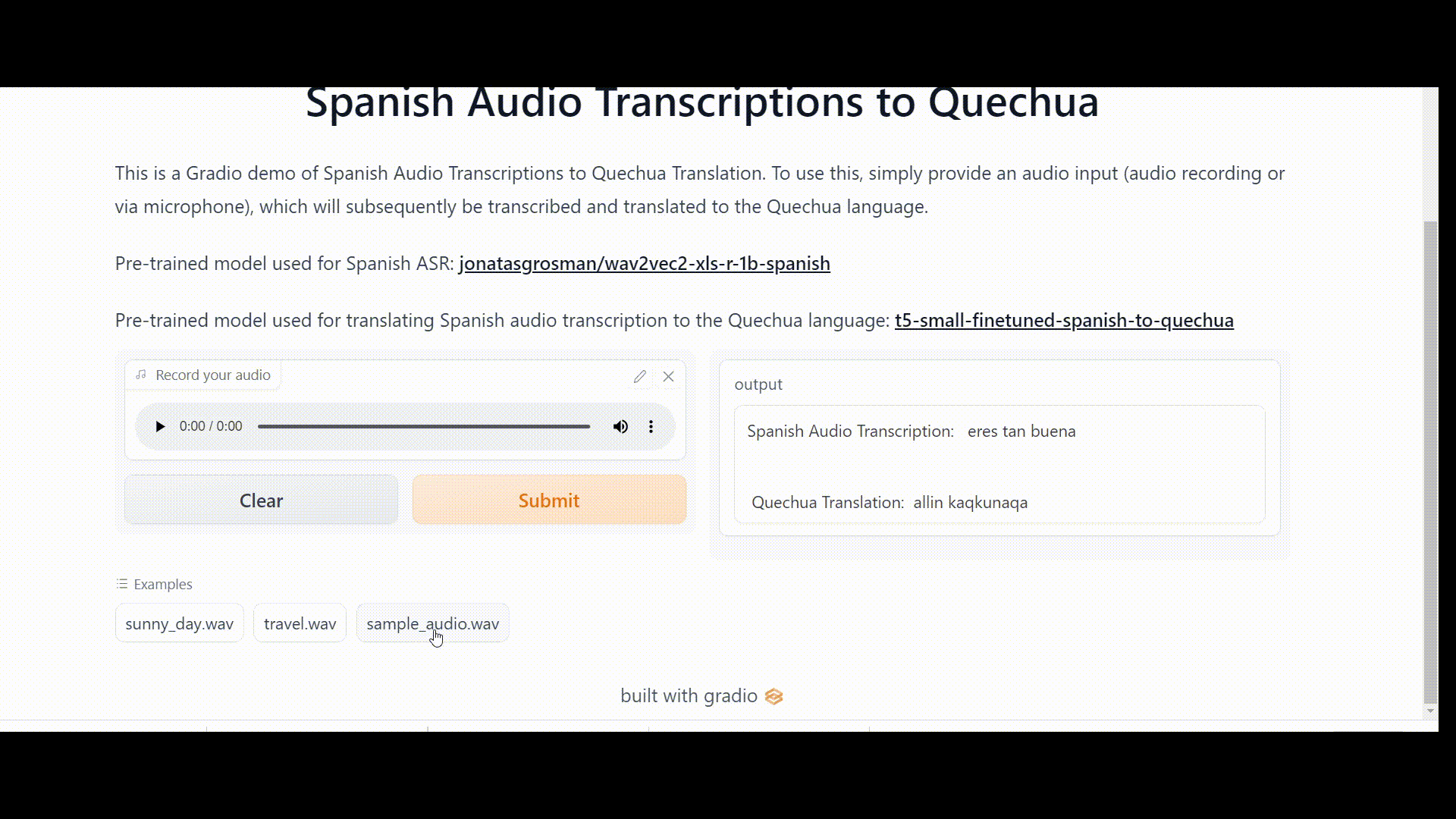
Link to the Space: https://huggingface.co/spaces/DrishtiSharma/Spanish-Audio-Transcriptions-to-Quechua-version1
Challenges
- The pre-trained model used for ASR (Module 1) is trained on the Common Voice dataset, which consists primarily of audio captured in a studio setting with professional artists as contributors. Although this model performs wonderfully in most circumstances, it may suffer in a noisy setting or with audio input that contains background audio or noise.
- Structured data in Quechua is scarce, making it difficult to train a model for translation jobs. In addition to that, there are multiple varieties of Quechua, which makes this task even more difficult.
- Challenging audio – this could be due to a variety of reasons such as low pitch, audio with low SNR, etc.
- Data protection – consent and privacy
- Different phonation styles and dialects
- Speech Modality
- Demographic bias
Limitations and Solutions
a) Limitation associated with Module 1: The pre-trained model for ASR plays a critical role; if the audio isn’t accurately detected, the transcription will be wrong, and there is a good chance that the output of the Quechua translator module will be erroneous. Although the pre-trained model for ASR (Module 1) functions excellently in the usual scenarios, however, it may struggle when confronted with a wide variety of voice patterns (different accents, pitches, play speed, and background audio conditions).
👉Solution to the aforementioned limitation: To get around this limitation, the pre-trained ASR model should be further trained on example audios that closely reflect the auditory environment in which the app will be used/tested to meet the needs.
b) Limitation associated with Module 2: This app can translate Spanish transcription to Quechua of Ayacucho since the dataset used for training the Quechua translator module ( Module 2) was derived from biblical texts in Quechua of Ayacucho.
👉Solution to the aforementioned limitation: Accumulating more diverse data and further training the pre-trained model available for Quechua of Ayacucho.
Applications
It could be used to devise solutions that require Spanish ASR and/or resulting translated audio transcription in Quechua.
Conclusion
To sum it up, in this blog post we learned:
1. How to create a Gradio app for translating Spanish audio transcripts to Quechua?
2. What are the challenges encountered in developing robust ASR solutions and text-to-text translation for indigenous languages?
3. How certain limitations could be circumvented?
4. What are the potential applications?
Thanks for reading. If you have any questions or concerns please post them in the comments section below. Happy learning!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]





