This article was published as a part of the Data Science Blogathon.
Introduction
Organizations with a separate transactional database and data warehouse typically have many data engineering activities. For example, they extract, transform and load data from various sources into their data warehouse. Sources include customer transactions, data from Software as a Service (SAAS) offerings, and third-party data that could be useful for analyzing customer behavior. Such ETL jobs are managed using ETL frameworks that help organize appointments into ordered workflow graphs, track them, and monitor service level agreements.
.png)
Airflow has excellent scheduling capabilities, and a graph-based execution flow makes it a great alternative for running ETL jobs. This post will help you learn the basics of Airflow and perform an ETL job to transfer data from Amazon S3 to Redshift.
Apache Airflow
The flagship project of the Apache Software Foundation has already inspired many companies. The highly scalable solution makes the platform suitable for any size of company, from startups to large corporations.

Image source – DataValley.com
Workflows are defined, planned and executed using simple Python codes. Even complex data channels with numerous internal dependencies between tasks in the workflow are defined quickly and robustly. Because data engineering challenges do not end there, Airflow brings a rich command-line interface, an extensive web interface and an extended REST API, starting with the new major version of Apache-Airflow 2.0. Several features make monitoring and troubleshooting much more accessible. Airflow can be extended with numerous plugins, macros and user-defined classes depending on the requirements.
The status of workflow runs and associated log files are available with a click. Important meta data such as interval and time of the last run are visible in the main view. While Apache Airflow ETL workflows run independently, you are well informed about the current status. However, viewing the web interface is not mandatory, as Airflow optionally sends a notification via email or Slack in case of a failed attempt. The application spectrum focuses on the ETL area, where Apache Airflow machine learning workflows are also optimally coordinated.
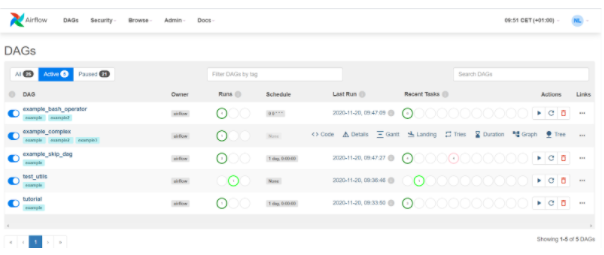
Image source – apache.airflow.com
Apache Airflow web interface ETL Apache Airflow web interface. The status of workflow runs is visible on the left (Running).
The status of the most recent workflow tasks is visible on the right (Recent Tasks).
In the second workflow (example_complex), the context menu is activated.
To get a better overview of the possible use cases of Apache Airflow, we have summarized different use cases for you. In addition to classic application ideas, here you will find inspiration on how to enrich your data channels with state-of-the-art functions.
- Classical
- Ambitious
- (I’m)possible
Classical
The basic idea of workflow management systems is buried in classic use cases: Tasks – especially in ETL – should be performed reliably and on time. In addition, external and internal dependencies must be considered before running the job. For example, an external dependency is a file to process that the sales department provides. Internal dependencies describe a conditional sequence of tasks between each other.
- Cron alternative
Cron jobs are often used when tasks such as cleaning the database, sending newsletters or evaluating log files are performed regularly. If these tasks are taken into Airflow instead, you stay on top of many jobs and benefit from the traceability of status information.
- Conditional, modular workflows
Complex dependencies can be implemented easily with Airflow. Integrated concepts such as branching and Task Groups make it low maintenance possible to create complex workflows. Branching allows conditional execution of multiple alternatives, and Task Groups allow smaller parts of a workflow to be reused.
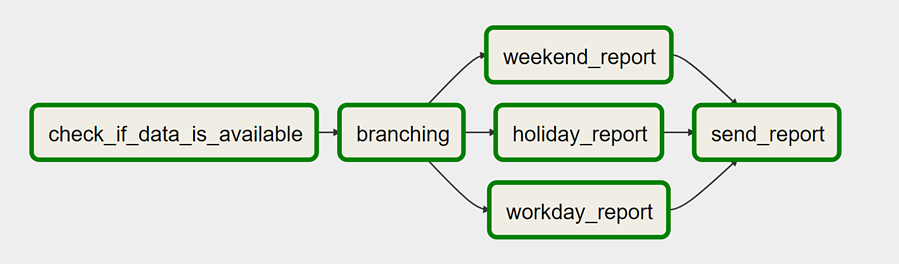
Image source – DataValley.com
- Data processing directly after generation
When several systems work together, waiting situations often occur. For example, a Bash task should run directly after sending a file. However, the exact delivery time is unknown. Therefore, airflow will pause the workflow with the sensor job class until this file exists.
Ambitious
The more workflows run on Airflow, the faster ideas for particular use cases emerge. As a power user, you want to go beyond Apache Airflow’s best practices and fully utilize its capabilities. Some advanced use cases only require customizing the configuration file. Others are implemented using custom plugins and task types (operators) or macros. Overall, there are many ways to adjust airflow to meet emerging needs.
- Flexible working procedures
Although many aspects of the workflow are predefined in Python files, some flexibility can be built into some areas. Context variables such as execution date are available at runtime. This can be used in SQL statements, for example. Additional (encrypted) variables can be created using the CLI, API or web GUI. This can be used, for example, to make file paths flexible for uploads.
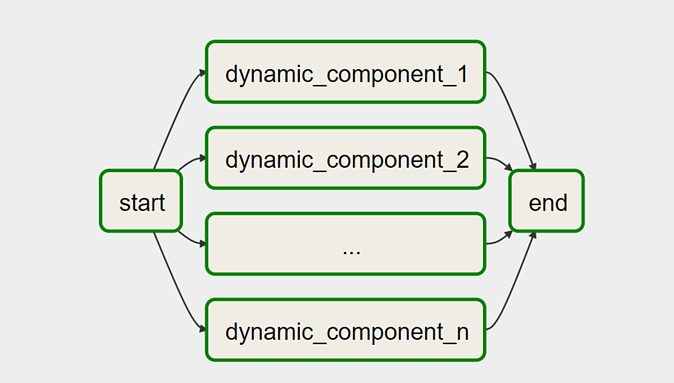
Image source – DataValley.com
Last but not least, the workflow structure itself can be dynamic. For example, the number of job instances for a variable number of records in the database can be set using variables. Likewise, dynamic_component_# components are created using a variable in graphics.
- Big Data – Horizontal Scaling with Airflow
Horizontally scaled Airflow can process up to 10,000 automated tasks per day. At the same time, several terabytes flow through the data channels every day. For example, Spark transformations and data warehouse downloads are managed by Airflow in the Big Data space. With Airflow, execution errors and inconsistencies are reliably detected, and a response can be implemented as quickly as possible.
For example, suppose the data scheme changes unannounced or the volume of data increases due to exceptional circumstances. In that case, the result is visible in the monitoring, and the notification of responsible persons can be automated.
- REST API
As a unique feature, Airflow includes an extensive REST API. This can be used to get information about the status of workflow runs, to pause or start workflows, and to store variables and connection information in the backend. Context variables can optionally be passed when the workflow is activated via the interface. Authentication ensures security here. Airflow can also be connected to SAP BW via REST API.
(I’m)possible
Airflow limitations must also be considered to judge which application ideas are possible and which are not. At its core, Airflow is a large-scale batch scheduler mainly used to manage third-party systems. In the basic idea of work procedures
• Workflows without repair plans
Executing a workflow on multiple arbitrary dates cannot be set in motion without additional effort. The web interface and CLI do not offer any functionality for this. The solution provides a REST API or manual workflow execution at the desired time via a web interface.
• Data exchange between workflows
One of the primary applications is the design of data pipelines. With XCOM, at least the metadata is exchangeable between functions. Here, for example, the location of data in the cloud can be handed over to a downstream task. The maximum metadata size is currently limited to the size of a BINARY LARGE OBJECT (BLOB) in the metadata database.
Conclusion
The mentioned points are often the reason for own plug-ins and macros to extend the functionality of Airflow. However, to date, Airflow has proven to be a reliable and well-designed workflow management platform that addresses many challenges of modern data engineering. Airflow is also ideal for training machine learning models coupled with the Anaconda environment.
- Airflow brings a rich command-line interface, an extensive web interface and an extended REST API, starting with the new major version of Apache-Airflow 2.0.
- Complex dependencies can be implemented easily with Airflow. Integrated concepts such as branching and Task Groups make it low maintenance possible to create complex workflows.
- With Airflow, execution errors and inconsistencies are reliably detected, and a response can be implemented as quickly as possible.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a Machine Learning Enthusiast. Done some Industry level projects on Data Science and Machine Learning. Have Certifications in Python and ML from trusted sources like data camp and Skills vertex. My Goal in life is to perceive a career in Data Industry.





