This article was published as a part of the Data Science Blogathon.
Introduction
YARN is an open-source project for Apache representing “Yet Another Resource Negotiator”. Hadoop Collection Manager is responsible for sharing resources (such as CPU, memory, disk, and network), and organizing and monitoring tasks throughout the Hadoop collection. Previous versions of Hadoop only support MapReduce functionality in the Hadoop collection; However, the advance of YARN has also made it possible to use other large data solution frameworks such as Spark, Flink, and Samza and many more in the Hadoop Cluster. YARN supports a wide variety of tasks such as broadcast processing, cluster processing, graph processing and duplicate processing.
What is YARN Architecture?
.png)
Apache YARN consists of two main components: Resource Manager and Node Manager. One Resource Manager per set while the Node Manager daemon works on all employee nodes.
A resource Manager is a daemon that is responsible for distributing resources to the collection. It has two main components which are the Editor and the Application Manager. The scheduler is responsible for organizing applications throughout the collection based on CPU memory and needs. There is only one Service Manager per set.
The Application Manager accepts tasks and creates specific Applicants and restarts them in the event of a failure.
Node Manager is a daemon that works on all staff nodes and manages resources at the machine level. Node Manager defines the resources available on the node and keeps track of usage. It also monitors the life of the nodes and if it is found to be unhealthy refer it to the resource manager. The Node Manager communicates with the resource manager to send regular reports about the usage of the report and liaises with the application manager to generate a JVM to perform the task.
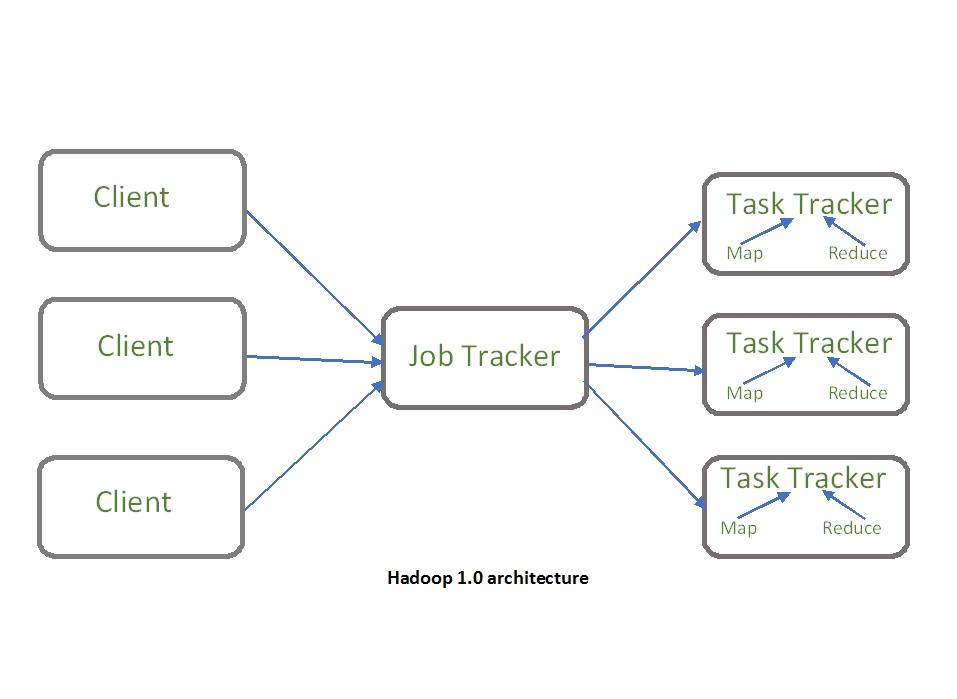
Application Master is responsible for managing the entire application life cycle from resource consultation, to tracking and monitoring of the work environment.
How Does YARN Support Frameworks?
YARN is not limited to Hadoop MapReduceHadoop MapReduce; can be used to run one of the most promising frameworks for data consulting services like Spark, Flink, Samza, and many more. The list below represents all the components that can currently operate on YARN.
YARN Scheduler
YARN supports three planning policies namely FIFO, Power, and Effective Planning that determine how revenue activities will be prioritized or prioritized.
FIFO Scheduler
In the FIFO Editorial Policy, requests are provided for “First Outgoing” but this policy may result in job starvation if the collection is shared between multiple users. Therefore, this policy is not valid for shared collections. By default, YARN is always set to FIFO policy.
Capacity Scheduler
In Capacity Scheduler, various organizations share their Hadoop collection to increase the use of the collection. Although organizations share their collection, Position Planners make sure that each organization receives its required volume.
Capacity Scheduler provides power guarantees, flexibility, resource-based planning, critical planning, multiple hires, and much more. We must configure the structure below in the conf / yarn-site.xml file to enable the Skill Editor in YARN.
Fair Scheduler
The Positive Planning Policy ensures that all active functions receive approximately equal shares in use (memory or CPU). Tasks are divided into rows and resources are distributed equally in those rows. It always ensures a small amount of queue sharing and when the queue is empty, excess resources are still distributed through operations running on other lines. We can also define a set of rules that apply to applications submitted for applications to enter the appropriate lines for further processing.
Reservation System
Users can store certain apps on YARN using the booking system so that important apps can always access resources on time. We can mark any leaf line as a booking line in Fair & Capacity Scheduler (fair-scheduler.xml / capacity-scheduler.xml). Let’s see how it works.
The user submits a booking creation request and receives a booking Id. In the next step, users submit a booking request and booking id and a Reservation Agent called GREE will create bookings in the System (The system is a data framework that monitors and tracks all bookings).
Next time a user makes a request with a booking id, the organizer will ensure that the app receives the reserved resources. However, if resources do not work they can be used to run other applications as well.
High Availability
Earlier in Hadoop 2.4, Cable Manager was a single point of failure in the YARN collection. However, after Hadoop 2.4 Resource Manager operates in active mode / StandBy to provide error tolerance and high availability.
The Standby Resource Manager regularly monitors all possible changes to the active Resource Manager and may replace them in the event of a failure. The Service Manager works closely with the veterinarian to record his status and decide which Service Manager should work in the event of a failure.
Failure The transition from active mode to standby mode may be automatic or automatic. Manual failover transmission can be done by the controller using the “yarn rmadmin” cli while in automatic failover transmission zookeeper daemon is used.
Yarn Federation
The Yarn Federation is a program to combine YARN’s smaller collections into a larger group. Applications running on the federated clusters can be configured in any sub-cluster location. There will be multiple resource managers for each collection. Such structures offer greater flexibility and scalability as a separate Service Manager will manage part of the collection thus increasing overall planning and monitoring performance.
YARN Versus Mesos
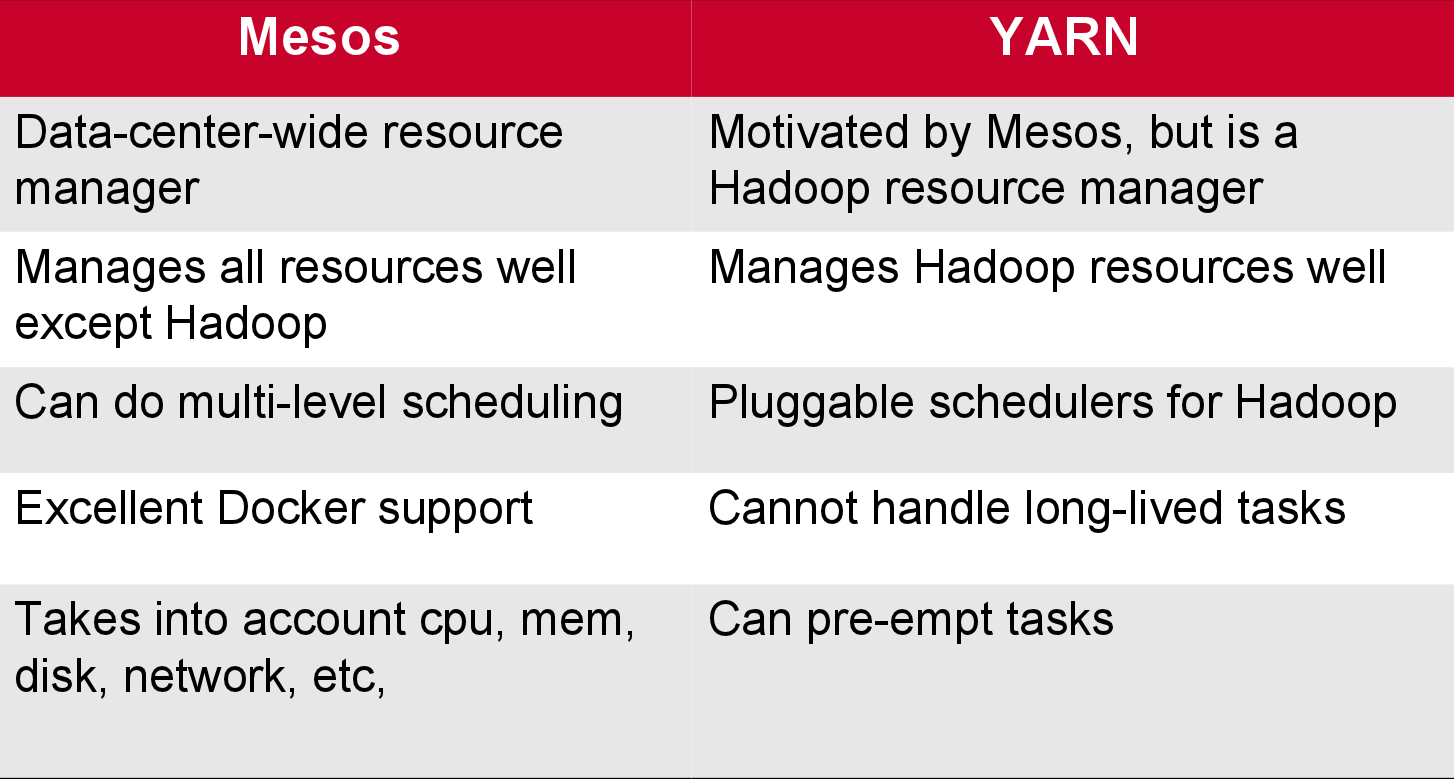
- Apache Mesos is another well-known resource manager in the market. There are a few important differences between the two.
- YARN is written in Java Mesos written in C ++
- By default, YARN is based on memory configuration only. By default, Apache Mesos has memory and editing CPU
- Apache YARN is a monolithic editor which means we follow a single step of planning and feeding for work Apache Mesos is a non-monolithic process that follows a two-step process of planning and feeding.
Conclusion
Undoubtedly, YARN is a robust, flexible, flexible engine management software that supports more than 15 large data structures. Allows the external application to run the Hadoop Distributed file system. It is in great demand and is widely used throughout the industry.
- The Architecture of YARN and the various components that we use to work with YARN i.e Resource manager, Application manager, Node Manager
- various frameworks supported by YARN – YARN scheduler, FIFO scheduler, Capacity Scheduler, and Fair Scheduler.
- The reservation system includes High Availability & High Federation. This was all you need to get started with YARN.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Analyst who love to drive insights by visualizing the data and extracting the knowledge from it. Automating various tasks using python & builds Real time Dashboard's using tech like React and node.js. Capable of Creaking complex SQL queries to fetch the accurate data.





