Overview
Analytics Vidhya has long been at the forefront of imparting data science knowledge to its community. With the intent to make learning data science more engaging to the community, we began with our new initiative- “DataHour”.
DataHour is a series of webinars by top industry experts where they teach and democratize data science knowledge. On 15th March 2022, we were joined by Laurent Picard for a DataHour session on “DataHour: Building smarter solutions with no expertise in machine learning”.
Laurent Picard is a developer passionate about software, hardware, science, and everything shaping the future. In a past life, he worked on educational solutions, pioneered the eBook industry, and co-founded Bookeen. Launching 24/7 digital platforms made him appreciate how much cloud technologies are developer superpowers. Laurent works at Google Paris and enjoys exploring, learning, and sharing the world of possibilities.
Are you excited to dive deeper into the world of Smarter Solutions? We got you covered. Let’s get started with the major highlights of this session: Building smarter solutions with no expertise in machine learning
Introduction
If we look at or think of the development of Data Science and Machine Learning, we all will encounter 40 years of its journey. 40 years is the time it took for experts to reach the current level of machine learning: surpassing traditional algorithms, neural network models, etc. And now to the more advanced version: understand text, image, audio, and video data. 40 years and today’s 4 hours are equally equivalent nowadays. Surprised! but it’s true that today it takes only 4 to 40 hours for any developer to use such a model, or even create a new one, and solve specific business problems. This all is possible all because of 40 years of dedicated manual, semi-manual smarter solutions and then to now advancement of Machine Learning.
Learnings through of session:
- Learn how to benefit from existing machine learning models
- How to create a custom model with AutoML techniques?
- A live demo
Any sufficiently advanced technology is indistinguishable from magic Arthur C. Clarke
Let’s begin with the magical🪄journey. Everywhere we heard of machine learning and machine learning benefits. So, firstly we’ll understand what is machine learning and why it is so popular, etc.
What is Machine Learning?
In layman’s terms, machine learning for a few years understood as – it is something that helps you with your data. Like it takes the input data that you want to understand and extracts information out of it. Machine learning is a part of AI and machine learning is embedded in itself deep learning. Deep learning deals with neural networks and has brought most of the innovations in the past years. Further going ahead, let’s have a look at how deep learning works?

How does Deep Learning work?
There were a few waves of AI in the 50s, the 80s, and the 90s. Moreover, especially in the 80s, people thought – let’s try to mimic the way we think our brain works with synapses with networks of neurons and so on. For that, we need many examples and if you think about it that’s how we learn as children – we learn from our parents, siblings, friends, teachers and so on. We learn a lot from examples. From this experience, you learned how to manage and solve problems. And it’s just a solution that didn’t work before. If you try to solve these problems with algorithms before, it kind of worked but machine learning now manages to solve some kinds of problems.

Three Ways One can Benefit from Machine Learning
You can develop expertise in ML especially like AI, Deep Learning, etc. When you’re already an expert or developed expertise maybe not in all topics but know how to work on vision or how to work on data and so on. Mostly if you deal with deep learning you will deal here with neural networks. But the landscape is larger than that now, if you are a developer you can use API and these APIs are actually wrappers around big machine learning models. And they do provide you a way to actually use machine learning without any knowledge.

In between comes AuytoML – you can build your own customized models without any expertise. There are lego bricks also. Building blocks actually take one of these lego bricks and use them inside your own solution.
Machine Learning APIs
We can say these APIs are ready-to-use models for maximum problem solutions. So let’s start with the machine learning API. In the market, you’ll find many API providers. Hence you can use APIs from any cloud provider. In fact, sometimes in a browser – you have existing APIs.
Ready-to-use Models
As you all know that the data you have as input can be text, images, videos, or even speech and from that, you need to extract information. And sometimes the extracted information is actually your input in another way. These different machine learning models/APIs are built on this extracted information. These ask input to process the result on the basis of already stored input performed types/in-built functions.
Vision API’s
The vision API helps in analyzing images. For example:
In the 90s, there was only – edge detection possible. To detect edges in a picture for instance a Sobel filter is used. And from that, it could be concluded that there are flowers at the edges but it didn’t work. Because if we try this on new/other pictures, it didn’t work.
Here, Machine learning emerged as a very nice solution.
Label detection
The first feature a vision model can do is to give you labels. The picture was labelled with labels. So here this picture is about nature, flowers, gardens, spring, plants, and botany, everything is correct here.

So, it’s a web API that you can use here and get a good response like this is a nature’s image which gets 95 per cent. Most of the time with machine learning models you get confidence scores-how best is the model. With a low score, it’s better not to show it to the user, or to be very careful with the result.
Landmark detection
A vision model can detect landmarks and specifically it matches pictures between them. And when pictures are very close then you can detect something. It’s the same picture as before. The presenter flipped it- zoomed, cropped, and applied the color filter. Now, it exists in a different form. Here the visual model tells that this picture most likely is about the Hobbiton movie set. So, this is where the lord of the rings movie was shot and it even gives him the GPS location and that is perfect. The confidence score is a bit low 61 per cent but the response is perfect.

There’s not any single pixel in common with the original one.
Object Detection
A vision model can detect objects with bounding boxes. This is the cast of lord of the rings in a restaurant.

Here are the bounding boxes for the persons, even, the small person and smaller parts are detectable like pants, t-shirts, even the ceiling lamp. It’s like class mapping. A person is a class and whenever someone or pixels looking like a person are detected-they are mapped to the person class.
Face Detection
Vision models can detect faces. So, here it’s a 3d rendition of Golem. It’s not a real picture. Golum was a human being and it does look like a human.

With this we get a close bonding box here and different dots for the nose, the mouth and everything. A vision model can also try to detect emotions on faces.
Text Detection
Optical Character Recognition – algorithms companies developed to detect glyphs with some different methods. It worked but there were mistakes always. Machine learning brings more advancement in the same field. For example, a screenshot.

With the vision model – the different blocks of text, sentences, lines, different words and even the different symbols can be traced. Machine learning makes mistakes like humans do mistakes so it’s always interesting to see the limits of a machine learning model.

We applied a perspective effect on the screenshot and it still works. The text is perfect. It makes a very small mistake- the double quotes, here at the end, it transcribed it as a single quote.
Handwriting Detection
The next level is handwriting detection. So it almost never worked on a specific like analyzing checks with expensive solutions and that would only work in some countries. Because we have different handwritings and so on. It’s not as perfect as printed text but it does detect handwriting and does very few mistakes.

So here, this is a sheet of paper written by Tolkien himself and here also we get the same result i.e. different blocks of text, different lines, different words, different symbols and the result is amazingly good. The only annoying mistake it makes here is kings. Rest is almost perfect.
Web Entity Detection and Image Matching
Vision models can detect objects and so they also try to match objects with existing ones. This is called web entity detection. A web entity is someone/something famous and most usually the person or the entity as a Wikipedia page. If you have a Wikipedia page, you’re famous. Here we took a unique picture of Tolkien.

We modified this picture- zoomed in, cropped the picture, and applied a color filter. So it’s a different picture. And the vision model tells that most probably this picture is about GR Tolkien. Here it tells that the label you could attach to this picture is JRR of Tolkien and can get the URL link of pictures from a Spanish newspaper. This is a web entity for Tolkien. So the description is JR Tolkien but better than that we get a unique identifier here. There’s a big knowledge graph. So it would be a token itself.
You know we’ve been crawling the web for over 20 years and to understand what we have on web pages we need to understand the different entities and this is the entity for GR Tolkien. If we were talking about Christopher Tolkien, Tolkien’s son then we would get maybe just Tolkien or Christopher Tolkien. But you cannot really trust texts. There are different ways to write about entities sometimes. And so here we have a unique way to detect Tolkien whatever the language, whatever if he had pseudonyms, or whatever he doesn’t but if he had then we would use the entity id to uniquely identify objects or entities. Moreover, you can also detect other images like a person walking in a forest or a person against a tree.
OSS Client Libraries
There are client libraries. There you can find your favorite languages. In client libraries, you can actually in a few lines call the machine learning model called the API and get the result and use that right away. You create a client always on the same principle as you provide the content(image). You call the features that you want face detection and for one picture it’s the result is live and then you can detect all and know where all the faces in the pictures are and also what are the sentiments that have been detected. we’ll do a demo with this code a bit later okay
Video Intelligence API
This is almost the same but with one more dimension i.e. time. If you take pictures with time then it’s a video. For example, videos have been transcribed by the Video Intelligence API. This video model is able to understand the video. What it can do? It can describe a video with labels but it can also detect the different video shots. So video shot is a segment that is uniquely a part of the video. And there are many small segments of around two seconds. You can do object tracking, location extraction of all the different objects, etc. It’s also able to detect persons. It’s even better than with the vision API. It does also work on face detection but what’s great with the video model is that you can track the different entities.
**Video**–put a video.
Remember you have one more dimension – time. So here you can know how many people you have and where they are moving inside the segment, inside the video you can also recognize logos. Then let’s stop the video and have a look at what’s been detected. It can transcribe the text as OCR does. So it works still on printed and handwriting and here you have all the text that’s been detected in the video and you can track it. It can help you know whether there are parts that you should not show to children i.e., called explicit content detection. With the lego brick with the building block, you can extract the speech and get it transcribed into text.
Example of Object Detection inside videos

It’s an example of object detection inside videos. Here we’ll show the bounding boxes and create a gif from them. These are the few lines you need to analyze for the video and understand it. From the result, you can do all lots of stuff like cut the video into different segments, etc.
Natural Language API
These are used to analyze text. In reality, the text is what researchers worked on. Initially on computers we all deal with texts, we called programs with texts, we write text, we exchange messages in text and so on. It’s a big field called NLP- Natural Language Processing. There are NL models to understand the text. So the first feature an NL model can do is it can give you the syntax of a full article/paragraphs/chapters/sentences.
Text Detection

Here, we’ll get that this sentence is in English and the full syntax of the text. Today’s NLP does work with many different languages. Earlier doing this was a difficult task with NL engines. But with advanced NL models, we can be very precise and can go up to the level of punctuation.

It does simplify the way one can use results.
Entity Detection

It’s more useful because it can detect entities. They are mapped to different classes. Example: here in red we have p Tolkien – a person/writer. Companies are using that to detect the way we speak about their companies, etc.
Content Classification

With this, we can also classify content. This kind of feature is used by companies who have archives of newspapers or scanned their old newspapers. They have made an OCR pass. So they have the text and now they can also automatically classify all the different articles in different categories.
Sentiment Analysis
We can detect sentiments in the text also. Here we took two different reviews a positive one and a negative one from the hobbit book.

Here is what we get on the right-hand side. We get a score between minus one and plus one. This score represents how positive or negative we are speaking here inside the sentence but it can be at the paragraph level or at the entity level and it doesn’t work. Here the negative sentences come from Pauline’s review. She hated the book so unfortunately, there are many neutral sentences because most of the time we are pretty neutral. And here the positive sentences come from the New York times review. They love the book and it does show.
This feature is used by companies who are browsing uh social networks to understand how uh users are speaking about their products and services, etc.
Example: how to analyze sentiments in text.

Translation API
It translates 100+ languages with a simple request.

Neural Translation Model in 2016
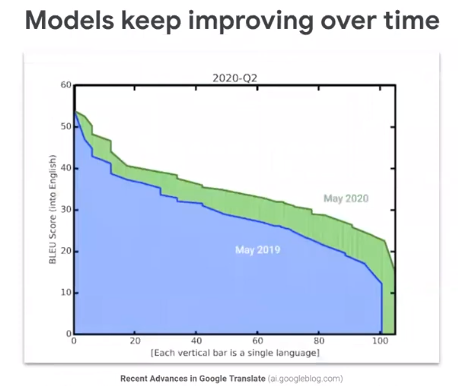
In 2016, Google Translate from one day to the other suddenly became very good. The presenter was mainly translating Chinese and Japanese texts into French or English and six years ago it worked okay. He could get the sense of the text but certainly, it was very good. It’s because, in 2016, the google translate team switched from a statistical model to a pure machine learning model.

This is when we got good results here. So it’s a bit hard to understand it but in green, it’s the improvement that machine learning models advance. It is a machine translation here in orange you see at the time you see the gap between a human translation and the machine pronunciation. So the gap is pretty small. What’s so good also about machine learning is that you can improve over time. You can actually keep training provide more examples and then your model improves.
Create client and translation

Speech-to-Text API
Machine learning models convert speech to text in 120 languages with a simple request. It works in real-time and it’s now the core of assistance like you have Alexa, Siri, Google Assistant, etc. You can speak to them and then your speech is actually transcribed into text and the text is analyzed with a Natural Language Model. This is how it works.

There are many features:
Speech Archives/Speech Timestamps
Some companies have hundreds of hours of speech they would like to use but they cannot. Because it’s very time-consuming to listen to speech and transcribe it.

They can actually do that automatically and they can also have the position in the audio file of each word you can ask for time stamps.
The code example in python
You create a client and then recognize it with some configuration. Here we’re asking to get the punctuation. It’s a very hard problem to try to understand when is the beginning and the end of a sentence and even more than that and you can also get the word timestamps.

Text-to-Speech API
This helps in extracting speech when you have text. Around 22 years ago, the text-to-speech engine embedded in e-books could press play a book and you could hear the book aloud. Nobody used that because it was a robot talking to you it was very annoying. Now, you can have human-like voices. One of them at google is called WaveNet. It’s a technology that’s been developed by Deepmind.

This is the most advanced machine learning model because it can focus on the narrow problem of an audio signal. But it’s been sold by Deepmind.
Go and perform a live demo as performed by the presenter in the session. Here’s the code to generate that you actually just have to select the voice you want to use and that’s it and then you can specify the text and you have an audio file.

Build A Custom Model Without any Expertise – AUTOML
With existing machine learning models, you can make your applications smarter but in some cases, it will not work because maybe you have a more specific problem and the generic answers will not work. Here is an example: if we take two pictures and input them into the vision model. We’ll get almost the same answers because basically in a generic way those are skies, those are clouds in the sky or sky clouds.


It’s almost the same answer. But if we want to build a weather forecasting application then we need to detect the difference between the Cyrus and the alto-cumulus.
AutoML can be a solution here. How does it work?

Here you need to work a little bit more than before. You need to provide data i.e, you need to build your own custom data set from pictures. Once you have your data set everything else is automated. It’s an iterative process. Then you’ll launch the first quick training to get a sense of whether you’re doing well with your data set. Mostly we did a couple of training because there can be mistakes in your data set. Resultantly, do a second training and it starts to work well. When you do the training you have two options either you want the best accuracy and then you want a cloud model. Therefore, the first option is to launch cloud training. You will have a model in the cloud and you will be able to call it with your own API. Everything is private – the data set, the API- this is yours.
You can also build an edge model. An edge model is a lighter model that you’ll be able to export to somewhere else. So for instance in a container, you can export the model and use it on your mobile if you want to do mobile applications for iOS or Android. And you can also use the model on the web page.
Go and perform the AutoML clouds Demo done by the presenter in the session.
Auto-generate a custom model from your data

You can build AutoML models from text images, and videos, structured data like tables, databases, even excel files CSV, etc. You can build many different custom machine learning models. In fact, you can even do your own custom translation model if you are not happy with the translation API. You can do your own custom shot detection or custom classification of videos and so on.
AutoML in Vertex AI
Auto ML features are also grouped at google cloud under the vertex AI. So this is the whole AI platform maybe here is a more simple view to understanding what you can do with a custom video, object tracking, etc.

Here you can detect your own video actions, specific ones used by all the sports tv channels, you can do image segmentation, etc.
Go and try the demo on how to detect emotions, the presenter explained in the session. The code for the same can be located on the presenter’s Github repo.
AutoML under the hood

Learning to learn: Neural Architecture Search

The first technique – this one is specific to google at least. There is a research paper it’s called neural architecture search. Internally we call that meta-learning. So before doing the training with your data. The process “automl” is actually exploring different architectures to make sure that the best active architecture is selected. So how does it work? First, it tries to select models that will train faster than others and with better accuracy. So it’s computing intense and this is why also we have built dedicated hardware called TPUs- tensor processing units. GPUs or TPUs are typically used for training and for predictions.
Transfer Learning

The other technique is transfer learning. This is how it works here on the left you have the existing machine learning model. For example the vision division model- you have an image of the different types of clouds and you launch a training, it’s building actually new layers that are called hidden layers. And so it builds a new private model for you and you’ll customize/specialize your model at the last layers just to solve your own need.
Hyperparameter/auto-tuning
Finally, the last part known to experts is how to fine-tune the hyper parameters. This is not something that can be learned from the examples. You can learn this from the training itself. So, in the past for the last 10 years, experts used to fine-tune these parameters.

AI Platforms and Industry Verticals
You can develop expertise if you have time and you can do more machine learning. So at Google, there are different platforms like Vertex AI, Document AI, Dialog flow (if you want to build chatbots), etc. Like Siri, Alexa,…Call centres are using AI now.
Tensorflow (Favorite ML repo on Github) & Pytorch
You can use existing products or you can build your own products and if you wanna do machine learning as of today you cannot be wrong if you choose Tensorflow and or Pytorch. These are the two machine learning frameworks that consolidated over the last years.
How can we build smarter solutions?

What’s the time you need with machine learning APIs? Just hours. Example face detection is done by the presenter.
moustache I did the first prototype I did it in one afternoon uh you really need two hours to
You have data, then you make a request to the machine learning model. You have the answer and you try to build a prototype. It’s really a matter of hours.
For AutoML, it’s rather a matter of days. Example presenter made people yawning/people sleeping machine learning model in 2 days.
Conclusion
I hope you would have enjoyed the session. Stay tuned for another interesting DataHours. Try out all online demos’ on your own for better and more precise learning. Hope this session will also help in choosing your expertise.
Learnings you have:
- You have learnt how to benefit from existing machine learning models.
- How to create a custom model with AutoML techniques?
- A Live demo
You can contact the presenter on Twitter and LinkedIn.
Source of images: Presenter’s presentation.






