This article was published as a part of the Data Science Blogathon.
Introduction
These days companies seem to seek ways to integrate data from multiple sources to earn a competitive advantage over other businesses. The needs and requirements of a company determine what happens to data, and those actions can range from extraction or loading tasks to more complex processing. In addition to keeping up with the daily operations of a business, an insight into how different products are selling and what type of customers it attracts is necessary. To gain this perspective, data is transferred from transactional databases to a system that can handle large volumes of data and its processing and analysis. These tasks can be done manually but are time-consuming and intensive. A data pipeline is demanded quick automated data flow.
The data pipelines are useful to businesses, like an eCommerce enterprise that uses data for quick insights and uses them effectively, where pipelines are used for tasks like reporting, business intelligence, customer segmentation, sentiment analysis, and recommendation systems. Where organizations struggle to perform big data processes for continuous observation and supervision concerning numerous phases, creating robust data pipelines to carry out data processes automatically resolves the problem and drives business efficacy.
So, let’s get started with the data pipeline.
What is Data Pipeline?
A data pipeline is a series of steps to ingest the raw data from different sources and transfer the data to a destination for analysis and storage. Following each step delivers an output, which is the input to the next step. Until the pipeline is complete, the process keeps running. Sometimes, independent steps may be run in parallel.
The key elements of the data pipeline are a source, processing steps, and a destination or sink. Data pipelines may have the same source and sink, which makes the pipeline purely about modifying the dataset. Data pipelines allow data flow to a data warehouse from an application or to an analytics database from a data lake for use by business intelligence (BI) and analytics tools. By manually interfacing with source databases and writing code, developers can create pipelines themselves. A prevalent example of a data pipeline is the number of people visiting a forum daily.
To understand how much labor is obligatory in putting together an old-school data pipeline and how much of a service data pipeline is, let’s review the stages and important parts of data pipelines along with technologies available for replicating data.
Data Pipeline Architecture
The architecture of a data pipeline is the design and structure of code and systems that modify, clear, and copy as demanded and route source data to destination systems, like data lakes and data warehouses.
Three factors contribute to the speed with which data is transferred through the data pipeline:
- Rate or throughput is how much information can be processed by a pipeline in a given period.
- Data pipeline reliability allows the individual systems within the data pipeline to be fault tolerant. To help ensure data quality, a secure data pipeline with built-in auditing, logging, and validation mechanisms is considered.
- Latency is the time a single data unit takes to travel through the pipeline. It is more related to response time than to throughput or volume. Both in terms of money and processing resources, low latency can be expensive to maintain, and an organization should maintain a balance to increase the value it gets from analytics.
The aim of data engineers should be to optimize these aspects of the pipeline to cover the company’s needs. A business must consider its objectives, cost, and the type and availability of resources when designing its pipeline.
Data pipeline architecture requires several contemplations such as outlay of data, amount and type of processing need to happen, whether data is being generated in the cloud or on-premises, where data need to go, etc. So, keeping in mind the above aspects, data pipelines may be architected differently. A classic instance is a batch-based data pipeline with a point-of-sale system that generates many data points that are required to send to the data warehouse and an analytics database. It looks like this:
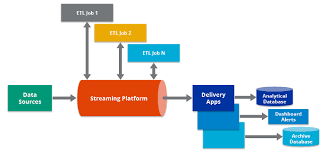
Another example is the streaming data pipeline, in which data from the point of sales system would be operated as soon as it is produced. The engine of this pipeline sends the output from the data pipeline to data repositories. The data stream is managed by the stream processing framework, where it can be processed and delivered. It looks like this:
The third example of a data pipeline is a combination of batch and streaming pipelines and is called Lambda Architecture. It allows developers to track real-time streaming use cases and historical batch analysis. It is most popular and widely used in big data environments.
Designing Data Pipeline
A data pipeline can be a simple process of data extraction and loading, or it may be built to handle the information in a modernized way. A data pipeline architecture is layered where each output acts as an input to the next until data reaches its destination.
Data Sources
The data sources are the wells, lakes, and streams where enterprises first collect data. SaaS provides thousands of data sources, and hundreds of others are hosted by every company on their systems. They play an essential part in the architecture as a first layer; there is nothing to ingest without good quality information.
Ingestion
The ingestion elements of the data pipeline are the processes that read data from data sources using an application programming interface (API) through the extraction method. To know about the information that is to be collected, the procedure known as data profiling is used, i.e. analyzing the data for its quality and structure and testing how well it would fulfil the purpose of an enterprise. The data is ingested as batches or through streaming after it is profiled.
Transformation
The data might require a change in its structure or format after it is extracted from data sources by filtering, aggregation and mapping coded values with description. The combinations are an important part of the transformation. It involves database joins, making it possible to exploit encoded relationships in relational data models. The transformation timings depend on what data replication method an enterprise prefers to use in its data pipeline: ETL (extract, transform, load) or ELT (extract, load, transform). While ETL is an older approach that transforms data until it is loaded to its destination, ELT is used in modern cloud-based data centres that load data without transformation.
Destination
The water towers and holding tanks are the final stop of the data. A data warehouse is the end of the line for data replicated through the pipeline. In a centralized location, these specialized databases include all the cleaned and mastered data from a company, enabling reporting, business intelligence, and not to mention analytics decisions better for analysts and executives. The data scientists and analysts can access a large amount of data through data lakes which store less-structured data. Ultimately, an organization may provide data into an analytics tool that accepts data feed directly.
Monitoring
The data pipelines are complex networks comprising the software, hardware, and networking, all of which are prominent to failures. The tracking, logging, and alerting code are required to help data engineers control output and fix the issues that can occur during the process to maintain the pipeline’s capability to extract and load data and keep the pipeline operational.
Tools, Technologies, and Techniques
When it comes to data pipelines, a company can either use a Saas pipeline or write its own code for the same. Organizations can hire developers to write, test, and maintain the code that is necessary for the data pipeline. These processes use several toolkits and frameworks:
- To generate faster, better data from their existing applications, businesses use open-sourced distributed platforms like Apache Kafka and RabbitMQ. These platforms are used to record events from business applications that allow communication between different systems and make them available as high-throughput streams.
- Workflow management tools can lessen the complications of creating a data pipeline. The tools like Airflow and Luigi constitute the processes that make up the pipeline and provide developers with a way to sort and contemplate data workflows and resolve dependencies automatically.
- Scheduling processes on time is yet another crucial step in the data pipeline. Many open tools allow users to create detailed schedules administering ingestion, data transformation, and loading to the target.
Developers mostly use the programming languages like Java, Python, Ruby, or Scala to define and write processes for data pipelines. However, the complications are always there with the do-it-yourself approach to creating the data pipeline from scratch. Where data engineers have better jobs to do than monitoring complex systems, developers could also be working on projects that provide direct business profits. This is where SaaS data pipelines play a significant role. The organizations don’t need to write their ETL code and build data pipelines from the base. One example is Stitch which provides easy to-manage and quick-to-set up data pipeline.
Types of Data Pipelines
Before implementing a data pipeline, figuring out if it would be cloud-based or an on-premises solution is a basic step. The on-premises pipeline allows a company to control its data completely, but it has its demerits, i.e., resource-intensive, time-consuming, and expensive labor. If a company decides to use a cloud-based pipeline, a third-party cloud contributor provides storage, computing power, and services through the Internet. The type of data pipelines are:
Batch Processing
Companies use batch processing pipelines to schedule regular transfers of extensive amounts of data. Batch jobs can be scheduled to run at set intervals, for example, every 24 hours or when the data hits a certain volume.
Real-Time
Real-time data pipelines are used to capture and process data as it’s created at the source. IoT devices, real-time applications, and mobile devices are common data sources.
Cloud-native
Cloud-native pipelines are created to operate with cloud sources, cloud destinations, or both. These hosted in clouds, scalable solutions allow companies to offload infrastructure costs and management burdens.
Open source
The open-source pipelines are fully customizable to a company’s needs and wants, but creating and managing them requires specialized expertise. The enterprises seeking an alternative to manage and create the solutions for their data pipelines can seek open-source pipelines.
An Example of Data Pipeline
Let’s look at an example of calculating the number of visitors to a website in a day.
The number of visits along with raw logs is registered by the dashboard daily. The pipeline runs continuously and captures and processes the visitor count as new entries that are added to the server log. Few things to know about how the pipeline is kept organized:
- Every part of the pipeline is kept away from others. These parts accept the given input and return a defined output.
- All of the raw data can be accessed to run different analyses at any time as it is stored in a database.
- Before moving data through the pipeline, data is checked for any redundancy. It is important to remove duplicate data, so all the duplicate data is deleted in the analysis method.
- The output of each part of the pipeline serves as an input to the consecutive next. So to scale up pipeline components individually or use the outputs for different analysis types, each component is kept as small as possible.
Let’s implement the above case using python.
We need a way to get data from the current step to the next every time. The database which keeps the count of IPs by day will be able to take out events as they are added if the next step is specified in the database. More performance can be gained by using a queue to transfer data to the next stage, which is not important at the moment. We will create another file, countvisitors.py and add some code that pulls out information from the database and counts by day.
Firstly, we query the database’s data where we connect a database relation and for any rows added after a certain timestamp.
Now we need a way to extract the IP and time from each requested row. The code below initializes two empty lists, pulls out the time and IP as an answer to the question, and appends them to the list.
def get_time_and_ip(lines): ips = [] times = [] for line in lines: ips.append(line[0]) times.append(parse_time(line[1])) return ips, times
The above code should note that the time is parsed from a string into the date, time object. The code for parsing is:
def parse_time(time_str): time_obj = datetime.strptime(time_str, '[%d/%b/%Y:%H:%M:%S%z]') return time_obj
lines = get_lines(start_time)
ips, times = get_time_and_ip(lines)
if len(times) > 0:
start_time = times[-1]
for ip, time_obj in zip(ips, times):
day = time_obj.strftime("%d-%m-%Y")
if day not in unique_ips:
unique_ips[day] = set()
The above code means that there is a key for unique IPs each day, and the values are sets containing all the unique IPs that visit that day. To run it every 5 seconds, code snippets are taken from above:
unique_ips = {}
counts = {}
start_time = datetime(year=2017, month=3, day=9)
while True:
lines = get_lines(start_time)
ips, times = get_time_and_ip(lines)
if len(times) > 0:
start_time = times[-1]
for ip, time_obj in zip(ips, times):
day = time_obj.strftime("%d-%m-%Y")
if day not in unique_ips:
unique_ips[day] = set()
unique_ips[day].add(ip)
for k, v in unique_ips.items():
counts[k] = len(v)
count_list = counts.items()
count_list = sorted(count_list, key=lambda x: x[0])
for item in count_list:
print("{}: {}".format(*item))
time.sleep(5)
We saw how to produce logs via a script and two pipeline steps to analyze the logs. To run the entire pipeline, the analytics pipeline repo is needed to be cloned from GitHub. To install README.md file can be followed. After this, run log generator.py and store logs.py, and launch count visitors.py.
When the above steps are completed, the visitor count will be printed out for the current day every five seconds. If the script is left to run for multiple days, the visitor count for multiple days would be visible.
Conclusion
Raw datasets always contain data points that may or may not be useful for a particular business. A data pipeline integrates and manages critical business data to simplify analytics and reporting using different technologies and protocols.
Concluding the article, we find out:
- Data pipelines are the pillar of digital systems. They convert, pass and save data and provide important highlights.
- Data pipelines must be advanced to keep up with the ever-growing data and modernization processes. Hence different architectures are used according to the requirements.
- While the advanced methods can be complicated for creating a data pipeline from scratch, some open source data pipelines are available, along with the required technology and toolkits to get on with it.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





