The gradient descent algorithm is an optimization algorithm mostly used in machine learning and deep learning. Gradient descent adjusts parameters to minimize particular functions to local minima. In linear regression, it finds weight and biases, and deep learning backward propagation uses the method.
The algorithm objective is to identify model parameters like weight and bias that reduce model error on training data.
This article was published as a part of the Data Science Blogathon
What is a Gradient?
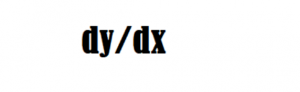
dy = change in y
dx = change in x
- A gradient measures how much the output of a function changes if you change the inputs a little bit.
- In machine learning, a gradient is a derivative of a function that has more than one input variable. Known as the slope of a function in mathematical terms, the gradient simply measures the change in all weights about the change in error.
Learning Rate:
The algorithm designer can set the learning rate. If we use a learning rate that is too small, it will cause us to update very slowly, requiring more iterations to get a better solution.
Types of Gradient Descent:
There are three popular types that mainly differ in the amount of data they use:

1. BATCH GRADIENT DESCENT:
Batch gradient descent, also known as vanilla gradient descent, calculates the error for each example within the training dataset. Still, the model is not changed until every training sample has been assessed. The entire procedure is referred to as a cycle and a training epoch.
Some benefits of batch are its computational efficiency, which produces a stable error gradient and a stable convergence. Some drawbacks are that the stable error gradient can sometimes result in a state of convergence that isn’t the best the model can achieve. It also requires the entire training dataset to be in memory and available to the algorithm.
class GDRegressor:
def __init__(self,learning_rate=0.01,epochs=100):
self.coef_ = None
self.intercept_ = None
self.lr = learning_rate
self.epochs = epochs
def fit(self,X_train,y_train):
# init your coefs
self.intercept_ = 0
self.coef_ = np.ones(X_train.shape[1])
for i in range(self.epochs):
# update all the coef and the intercept
y_hat = np.dot(X_train,self.coef_) + self.intercept_
#print("Shape of y_hat",y_hat.shape)
intercept_der = -2 * np.mean(y_train - y_hat)
self.intercept_ = self.intercept_ - (self.lr * intercept_der)
coef_der = -2 * np.dot((y_train - y_hat),X_train)/X_train.shape[0]
self.coef_ = self.coef_ - (self.lr * coef_der)
print(self.intercept_,self.coef_)
def predict(self,X_test):
return np.dot(X_test,self.coef_) + self.intercept_
Advantages
- Fewer model updates mean that this variant of the steepest descent method is more computationally efficient than the stochastic gradient descent method.
- Reducing the update frequency provides a more stable error gradient and a more stable convergence for some problems.
- Separating forecast error calculations and model updates provides a parallel processing-based algorithm implementation.
Disadvantages
- A more stable error gradient can cause the model to prematurely converge to a suboptimal set of parameters.
- End-of-training epoch updates require the additional complexity of accumulating prediction errors across all training examples.
- The batch gradient descent method typically requires the entire training dataset in memory and is implemented for use in the algorithm.
- Large datasets can result in very slow model updates or training speeds.
- Slow and require more computational power.
2. STOCHASTIC GRADIENT DESCENT:
By contrast, stochastic gradient descent (SGD) changes the parameters for each training sample one at a time for each training example in the dataset. Depending on the issue, this can make SGD faster than batch gradient descent. One benefit is that the regular updates give us a fairly accurate idea of the rate of improvement.
However, the batch approach is less computationally expensive than the frequent updates. The frequency of such updates can also produce noisy gradients, which could cause the error rate to fluctuate rather than gradually go down.
Advantages
- You can instantly see your model’s performance and improvement rates with frequent updates.
- This variant of the steepest descent method is probably the easiest to understand and implement, especially for beginners.
- Increasing the frequency of model updates will allow you to learn more about some issues faster.
- The noisy update process allows the model to avoid local minima (e.g., premature convergence).
- Faster and require less computational power.
- Suitable for the larger dataset.
Disadvantages
- Frequent model updates are more computationally intensive than other steepest descent configurations, and it takes considerable time to train the model with large datasets.
- Frequent updates can result in noisy gradient signals. This can result in model parameters and cause errors to fly around (more variance across the training epoch).
- A noisy learning process along the error gradient can also make it difficult for the algorithm to commit to the model’s minimum error.
Implementation of sgd classifier in sklearn:
from sklearn.linear_model import SGDClassifier X = [[0., 0.], [1., 1.]] y = [0, 1] clf = SGDClassifier(loss="hinge", penalty="l2", max_iter=5) clf.fit(X, y) SGDClassifier(max_iter=5)
3. MINI-BATCH GRADIENT DESCENT:
Since mini-batch gradient descent combines the ideas of batch gradient descent with SGD, it is the preferred technique. It divides the training dataset into manageable groups and updates each separately. This strikes a balance between batch gradient descent’s effectiveness and stochastic gradient descent’s durability.
Mini-batch sizes typically range from 50 to 256, although, like with other machine learning techniques, there is no set standard because it depends on the application. The most popular kind in deep learning, this method is used when training a neural network.
class MBGDRegressor:
def __init__(self,batch_size,learning_rate=0.01,epochs=100):
self.coef_ = None
self.intercept_ = None
self.lr = learning_rate
self.epochs = epochs
self.batch_size = batch_size
def fit(self,X_train,y_train):
# init your coefs
self.intercept_ = 0
self.coef_ = np.ones(X_train.shape[1])
for i in range(self.epochs):
for j in range(int(X_train.shape[0]/self.batch_size)):
idx = random.sample(range(X_train.shape[0]),self.batch_size)
y_hat = np.dot(X_train[idx],self.coef_) + self.intercept_
#print("Shape of y_hat",y_hat.shape)
intercept_der = -2 * np.mean(y_train[idx] - y_hat)
self.intercept_ = self.intercept_ - (self.lr * intercept_der)
coef_der = -2 * np.dot((y_train[idx] - y_hat),X_train[idx])
self.coef_ = self.coef_ - (self.lr * coef_der)
print(self.intercept_,self.coef_)
def predict(self,X_test):
return np.dot(X_test,self.coef_) + self.intercept_
Advantages
- The model is updated more frequently than the stack gradient descent method, allowing for more robust convergence and avoiding local minima.
- Batch updates provide a more computationally efficient process than stochastic gradient descent.
- Batch processing allows for both the efficiency of not having all the training data in memory and implementing the algorithm.
Disadvantages
- Mini-batch requires additional hyperparameters “mini-batch size” to be set for the learning algorithm.
- Error information should be accumulated over a mini-batch of training samples, such as batch gradient descent.
- it will generate complex functions.
Configure Mini-Batch Gradient Descent:
The mini-batch steepest descent method is a variant of the steepest descent method recommended for most applications, intense learning.
Mini-batch sizes, commonly called “batch sizes” for brevity, are often tailored to some aspect of the computing architecture in which the implementation is running. For example, a power of 2 that matches the memory requirements of the GPU or CPU hardware, such as 32, 64, 128, and 256.
The stack size is a slider for the learning process.
Smaller values allow the learning process to converge quickly at the expense of noise in the training process. Larger values result in a learning process that slowly converges to an accurate estimate of the error gradient.
Conclusion
In this article, we learned about different types of gradient descent. The key takeaways from the article are:
- The mini-batch steepest descent method is the recommended method because it combines the concept of batch steepest descent with SGD. Simply divide your training dataset into manageable groups and update each individually. This balances the effectiveness of batch gradient descent with the durability of stochastic gradient descent.
- When using batch gradient descent, adjustments are made after calculating the error for a certain batch. One advantage of the batch gradient descent method is its computational efficiency, which produces a stable error gradient and a stable convergence.
- Stochastic Gradient Descent (SGD) sequentially modifies the parameters of each training sample in each training sample of the dataset. This allows SGD to be faster than batch gradient descent. One benefit is that the regular updates give us a fairly accurate idea of the rate of improvement.
- In general, the higher the learning rate, the faster the model can learn at the expense of the non-optimal final set of weights. With a low learning rate, the model can learn a more optimal or globally optimal set of weights, but it can take considerable time to train.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data scientist @scloudin | Machine learning enthusiastic
I work with data extraction, data pipeline data modeling, data processing, data visualization and implementation of predicative model on top of historical data.
I like to play with data, so i work with ETL tool as well ETL is tool extraction, transformation and loading means we are taking data from one source and then transforming according to our requirements and then dumping it into data Wearhouse or database.




