Introduction
Google Cloud Platform (GCP) consists of many database services. GCP offers three reference architectures for global data distribution – a hybrid, multi-cloud, and regional distribution. It would help to consider these architectures when choosing a Google database service.
In this post, we’ll explain data distribution in GCP and provide an overview of Google’s popular cloud database services, including critical considerations when evaluating and choosing a service. We’ll also show how NetApp Cloud Volumes ONTAP can help centralize and simplify the management of Google’s cloud database resources.
This is part of our series of comprehensive guides to cloud storage technologies.
.png)
This article was published as a part of the Data Science Blogathon.
Table of contents
Deploying Databases on Google Cloud
Google Cloud Platform (GCP) supports three primary deployment models: single cloud, hybrid, and multi-cloud.
Single Cloud Deployment
The simplest deployment model is to deploy databases only on Google Cloud via:
- Creation of new cloud databases on Google
- “Lifting and moving” existing workloads from on-premises to the cloud and decommissioning on-premise database resources
Hybrid Deployment: Google Cloud and on-premises Resources
A hybrid deployment is practical when you have applications in the cloud that need access to on-premises databases or vice versa. For example, if you do on-premise marketing analytics and need to access customer databases hosted in the cloud.
There are three primary considerations for deploying a database in a hybrid model—with some data in Google Cloud and some on-premises:
- Main database – you need to decide if your central database will be stored locally or in the cloud. If you choose the cloud, GCP resources can act as a data center for on-premises resources. Your internal resources can sync data to the cloud for remote use or backup if you choose local. This allows you to maintain mirrored databases to provide failover during a crash.
- Managed services – these services are only available for cloud resources. If you need to use a hybrid app with your data, you may not be able to access managed services for that app. For example, if you’re building a hybrid cloud database, you can’t take full advantage because your on-premises resources are unmanaged. These services include scalability, redundancy, and automatic backups. However, you may use third-party managed services.
- Portability – The type of data storage you choose affects the portability of your data. To ensure reliable data transfer and consistent configuration and management, you must consider cross-platform storage such as MySQL. Using homogeneous databases on-premise and in the cloud provides that you don’t have to reformat or change the data schema, allowing you to transfer it as needed quickly.
The following diagram shows an example of a hybrid architecture with Google Cloud and on-premise systems.
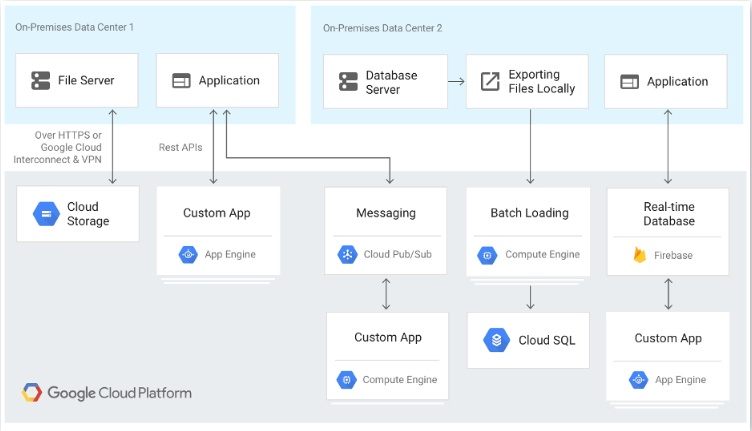
Multicloud Deployment: Including Google Cloud and Other Providers
Multicloud deployments allow you to combine databases deployed in Google Cloud with database services from other cloud providers. This can help you build more security features, distribute your database more efficiently, or take advantage of a broader range of proprietary cloud features.
When considering a multi-cloud deployment, you should be aware of the following:
- Integration – it is essential to ensure that client systems can seamlessly access databases regardless of the cloud in which they are deployed. You can use open-source client libraries to ensure seamless database availability across clouds such as clouds (see the JDBC guide).
- Database Migration – With multiple cloud providers, you may need to migrate data between clouds. It would help if you used database replication tools or export/import processes to migrate databases to GCP. There are several Google Cloud migration tools that you can use to migrate data to Google Cloud, such as Google Storage Transfer.
The following diagram shows a multi-cloud deployment involving GCP and another public cloud provider.
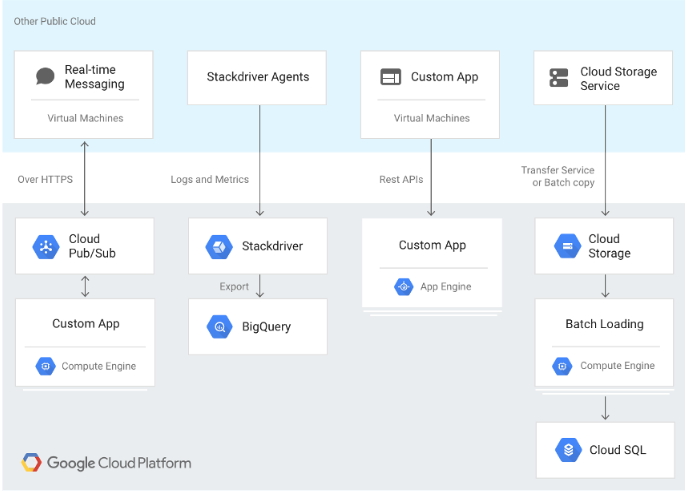
Google Cloud Database Services
GCP offers several Google Cloud database services to choose from. Below is an introduction to each.
Cloud SQL
Cloud SQL is a fully managed Google Cloud relational database service compatible with SQL Server, MySQL, and PostgreSQL. It includes automatic backup, data replication, and disaster recovery features to ensure high availability and resilience. You can integrate this service with Kubernetes, App Engine and BigQuery.
Every day Cloud SQL use cases include:
Cloud SQL
Cloud SQL is a relational database service compatible with SQL Server, MySQL, and PostgreSQL. It includes automatic backup, data replication, and disaster recovery features to ensure high availability and resilience. You can integrate this service with Kubernetes, App Engine and BigQuery
Every day Cloud SQL use cases include:
- Lift and move local SQL databases to the cloud
- Extensive SQL data analysis
- Content Management System (CMS) data storage and scalability support.
- Database management using Infrastructure as Code (IaC)
- Development and deployment of container applications and microservices
Cloud Spanner
Cloud Spanner is another fully managed relational database service from Google Cloud. It differs from Cloud SQL in that it focuses on allowing you to combine the benefits of a relational structure with non-relational scalability.
Examples of using Cloud Spanner include:
- Supply chain management and manufacturing
- Financial trading, analysis, and prediction
- Logistics and transport
BigQuery
BigQuery is a fully managed serverless data warehouse. You can use it to perform data analysis through SQL and query data streams. This service includes a built-in data transfer service to help you migrate data from on-premises sources, including Teradata.
BigQuery includes features for machine learning, business intelligence, and geospatial analytics. These features are provided through BI Engine, BigQuery ML, and GIS.
Usage examples for BigQuery include:
- Process analytics and optimization
- Big data processing and analysis
- Behavioral analytics and predictions based on machine learning
- Modernization of the data warehouse
Cloud Bigtable
Cloud Bigtable is a fully managed NoSQL database service from Google Cloud. It is designed for large operational and analytical tasks. Cloud Bigtable features high zero-downtime configuration, availability, and sub-10ms latency. You can integrate it with various tools, including BigQuery, TensorFlow, and Apache Services.
Examples of using Cloud Bigtable include:
- Financial analysis and forecasting
- Internet of Things (IoT) data reception and processing
Cloud Firestore
Cloud Firestore is a fully managed serverless Google Cloud NoSQL database designed for serverless application development. You can use it to store, synchronize and query data for web, mobile, and IoT applications. It includes features for offline support, live sync, and built-in security. You can integrate Firestore with Firebase, GCP’s mobile development platform, to make building and managing apps easier.
Examples of uses for Cloud Firestore include:
- Mobile and web applications with online and offline options
- Multi-user, collaborative applications
- Real-time analysis
- Social media applications
- Gaming forums and leaderboards
Firebase Database in Real Time
Realtime Database is a Google Cloud NoSQL database that is part of the Firebase platform. It allows you to store and sync data in real-time and includes caching features for offline use. The real-time database also will enable you to implement declarative authentication, matching users by identity or pattern. It includes mobile and web software development kits (SDKs) for easier and faster application development.
Usage examples for Firebase Realtime Database include:
- Developing applications that work across devices
- Optimization and personalization of ads
- Third-party payment processing
- Machine learning integration
Cloud Memory Storage
Cloud Memory store is a fully managed Google Cloud in-memory data store. It is designed to be scalable, highly available, and secure. Cloud Memory store enables application caches with sub-millisecond latency to access data.
Examples of using Cloud Memory store include:
- Lift and shift application migration
- Application of machine learning
- Real-time analysis
- Low latency data caching and loading
Pick a Google Cloud Database
Even after exploring the database options in Google Cloud, deciding which choices suit you can be challenging. This allows you to optimise your implementations according to the capabilities of the database rather than trying to tailor the database service to fit all needs.
Cloud SQL
Cloud SQL is a good choice when you need relational database functionality but don’t need more than 10TB of storage or more than 4000 concurrent connections. You must also be skilled in on-premise management.
Cloud Spanner
Cloud Spanner is a good choice when you plan to use a large amount of data (more than 10TB) and need transactional consistency. It is also good to use sharding for higher throughput and availability.
If you know or think you may need to be able to scale your Google Cloud database horizontally, Cloud Scanner is a better choice than Cloud SQL. If you are starting with Cloud SQL and need to migrate to Cloud Spanner eventually, be ready to rewrite the application in addition to migrating the database.
Cloud Firestore/Datastore
This is a good option when you plan to focus on application development and need live sync and offline support. Cloud Datastore is recommended if you need to store unstructured data in JSON documents. This is compared to when you need to store structured data, in which Cloud Spanner is recommended.
Another factor to consider is whether you need Atomicity, Consistency, Isolation, and Durability (ACID). You must choose Cloud Spanner because Cloud Datastore only offers atomic and persistent transactions.
Cloud Bigtable
Cloud Bigtable suits scenarios where there’s a substantial volume of data associated with a single key, excelling in providing low-latency and high throughput. Opt for Cloud Bigtable when you require focused analysis in a specific area, as opposed to Cloud Spanner, which is ideal for handling multi-region traffic. Consider Cloud Bigtable for applications like DevOps monitoring in the context of a time series, while Cloud Spanner shines as the preferred option for an infrastructure monitoring platform designed for software-as-a-service (SaaS) offerings.
Cloud memory storage
Cloud Memorystore is a good choice if you use key-value datasets and transaction latency is your primary concern.
If you don’t need disk persistence and only use a caching service, Cloud Memorystore should be your choice. However, if you are concerned about issues such as cache and database consistency or stream processing, you should choose Cloud Bigtable. Likewise, whenever your data volume is too large to fit in memory, Cloud Memorystore is not the best choice for you.
Google Cloud Database Management with ONTAP Cloud Volumes
NetApp Cloud Volumes ONTAP, the leading enterprise-grade storage management solution, provides secure and proven storage management services on AWS, Azure, and Google Cloud. Cloud Volumes ONTAP supports capacities up to 368 TB and supports various use cases such as file services, databases, DevOps, or any other enterprise workload with a robust feature set including high availability, data protection, storage efficiency, Kubernetes integration, and more.
Cloud Volumes ONTAP is especially helpful in dealing with database workloads in the cloud, bridging the gap between your cloud database capabilities and the public cloud resources they run on.
Conclusion
Google Cloud offers a variety of storage options for you to choose from. These services form the base of many other cloud services, and understanding your options can help you manage your cloud more efficiently.
- Google Cloud Platform (GCP) supports three primary deployment models: single cloud, hybrid, and multi-cloud. Portability, Managed Services, and central database
- GCP offers several Google Cloud database services to choose from. Below is an introduction to each:- Cloud SQL, Cloud Spanner, BigQuery, and Cloud Bigtable
- Multicloud deployments allow you to combine databases deployed in Google Cloud with database services from other cloud providers. When considering a multi-cloud deployment, you should know the following: Integrity & Database Migration.
Frequently Asked Questions
Q1. How to choose a cloud database?
A. Choose a cloud database by assessing your specific needs. Consider factors like data volume, performance requirements, scalability, budget, and support for your preferred programming language.
Q2. What considerations apply when choosing a cloud-based database?
A. Consider factors such as data volume, scalability, performance, data model (relational or NoSQL), security, compliance, cost, and integration capabilities with your existing systems.
Q3. How do I select a database for my business?
A. Choose a database for your business by evaluating factors such as data structure, application requirements, expected growth, budget, and the expertise of your development team.
Q. What are the 3 types of cloud databases?
A. The three primary types of cloud databases include Relational Database Management Systems (RDBMS), NoSQL databases, and NewSQL databases, each catering to specific data and scalability needs.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a Machine Learning Enthusiast. Done some Industry level projects on Data Science and Machine Learning. Have Certifications in Python and ML from trusted sources like data camp and Skills vertex. My Goal in life is to perceive a career in Data Industry.





