This article was published as a part of the Data Science Blogathon.
Introduction
Don’t push people to where you want to be; meet them where they are.
– Meghan Keaney Anderson, VP Marketing, Hubspot
In the past few years, we have witnessed a drastic transformation in the marketing strategies employed by organizations across the globe. Companies are constantly striving and coming up with innovative ideas to capture the attention of their customers. In today’s day and age of heightened activity across the digital space, it only makes sense that organizations have focussed their budgets and attention more on digital marketing as compared to some of the traditional forms. With several platforms at an organization’s disposal like YouTube, Instagram, Twitter, Facebook, etc., it becomes important to identify the right one that resonates the most with the organization’s target audience.

However, identification of the right platform is never the last step. A robust digital marketing strategy for the respective platform is important that ensures a wider reach, greater engagement, and more conversions. One such strategy that has taken prominence in recent times in a collaboration with influencers on a particular platform. It is a strategy employed by most startups worldwide today where they identify and tie up with influencers who create content related to the same field and have thousands and millions of followers. These influencers are new-age versions of brand ambassadors, and the organization can leverage the trust and authenticity built by them among their huge follower base and market their products.
In this article, we will try and make use of the capabilities of Python and web scraping techniques to identify potential influencers for collaboration on one such online platform – YouTube.
Scenario
For a hypothetical scenario, let us assume that there is an Indian startup operating in the space of Crypto Trading. The organization is looking for means to reach out to a wider audience and is looking for collaboration opportunities with individuals creating Youtube content related to Cryptocurrencies. They want to collaborate with someone who
1. Creates content specifically related to cryptocurrencies
2. Caters primarily to an Indian audience
3. Has more than 10,000 subscribers
4. Has more than 100,000 views across all videos
5. Is active, i.e., uploads videos regularly
Approach
Our approach to identifying a potential influencer with the above specifications would be as follows:
1. Search for all the listings on Youtube with different combinations of keywords related to cryptocurrency trading
2. Make a list of all the channels that get listed in our search results
3. For every channel identified, extract all the relevant information and prepare the data
4. Filter the list based on our required criteria mentioned above
WARNING! Please refer to the robots.txt of the respective website before scrapping any data. In case the website does not allow scrapping of what you want to extract, please mark an email to the web administrator before proceeding.
Stage 1 – Search
We will start with importing the necessary libraries
To automatically search for the relevant listing and extract the details, we will use Selenium
import selenium from selenium import webdriver as wb from time import sleep from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.keys import Keys
For basic data wrangling, format conversion, and cleaning, we will use pandas and time
import pandas as pd import time
We firstly create a variable called ‘keyword,’ to which we will assign all the search keywords we will be using on YouTube in the form of a list.
keywords = ['crypto trading','cryptocurrency','cryptocurrency trading']
Next, we would want to open YouTube using chromedriver and search for the above keywords in the search bar.
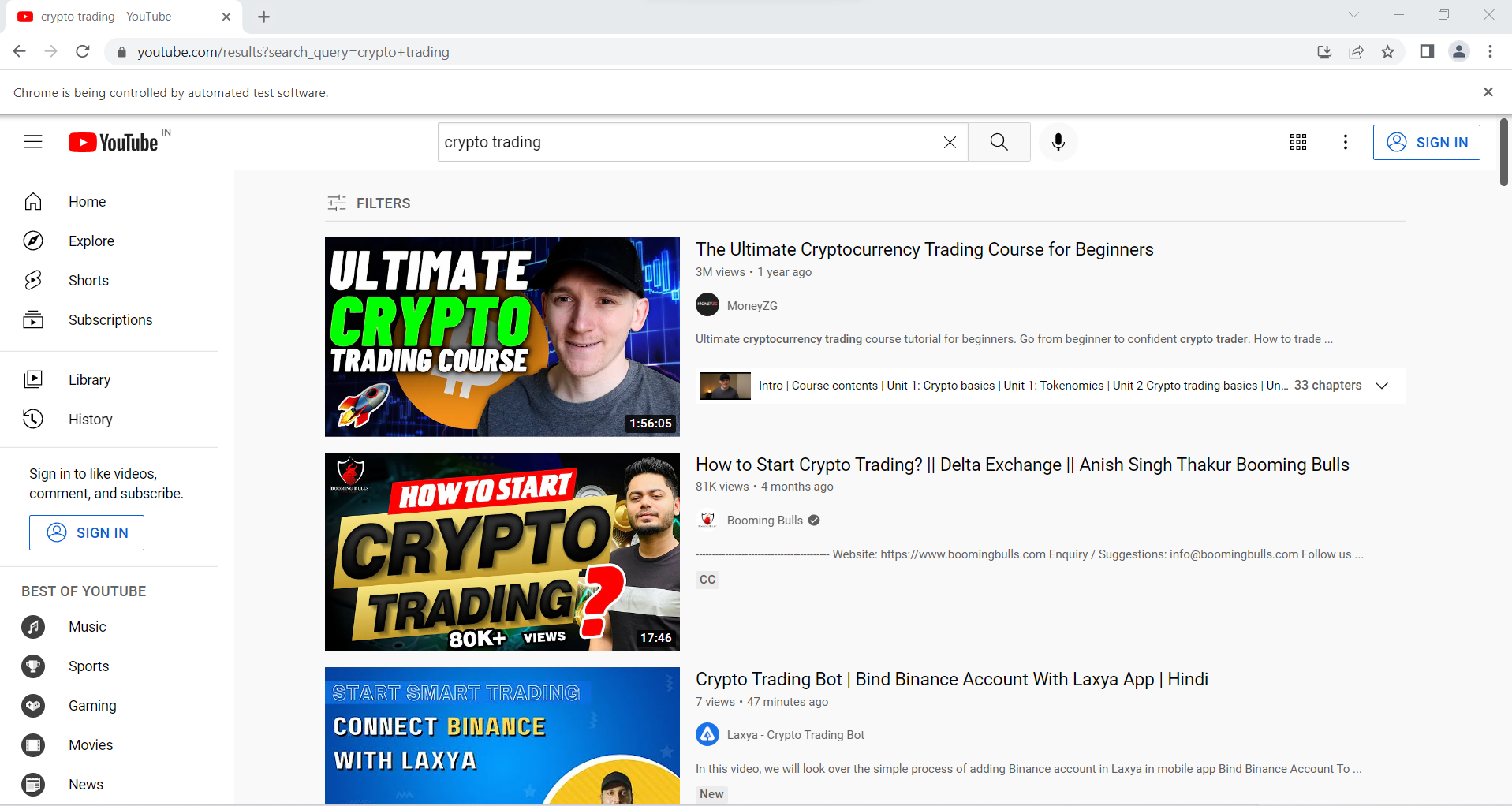
The following piece of code will present to us all the listings related to our keywords on the platform. However, the initial listing shows just 3-4 results on the page, and to access more results, we will have to scroll down. It is completely up to us how many results we would want; accordingly, we can put a number for the number of scroll downs we should do for each search result. We will incorporate this into our script, and for our purpose, scroll down 500 times for each search result.
for i in [i.replace(' ','+') for i in keywords]:
driver.get("https://www.youtube.com/results?search_query={}".format(i))
time.sleep(5)
driver.set_window_size(1024, 600)
driver.maximize_window()
elem = driver.find_element_by_tag_name("body")
no_of_pagedowns = 500
while no_of_pagedowns:
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.2)
no_of_pagedowns-=1
For all the loaded video results, we will try and extract the details of the profile from which they have been uploaded. For this, we will extract the channel link and create a dataframe, df, where we map the channel link with the respective keyword that generated that channel’s listing. Since a search term can possibly list multiple videos from the same Youtube channel, we will delete all such duplicate entries and keep only unique channel names that appear with each keyword search. We finally have a list of 64 unique YouTube channels at our disposal.
profile =[video.get_attribute(‘href’) for video in driver.find_elements_by_xpath(‘//*[@id=”text”]/a')]
profile = pd.Series(profile)
df = pd.DataFrame({'Channel':profile,'Keyword':str(i)})
df = df.drop_duplicates()
df.head()

Stage 2 – Data Extraction
For every channel that we obtained above, we would next go to the respective channel’s page link. Each channel’s page has 6 sections – Home, Videos, Playlists, Community, Channels, and About.
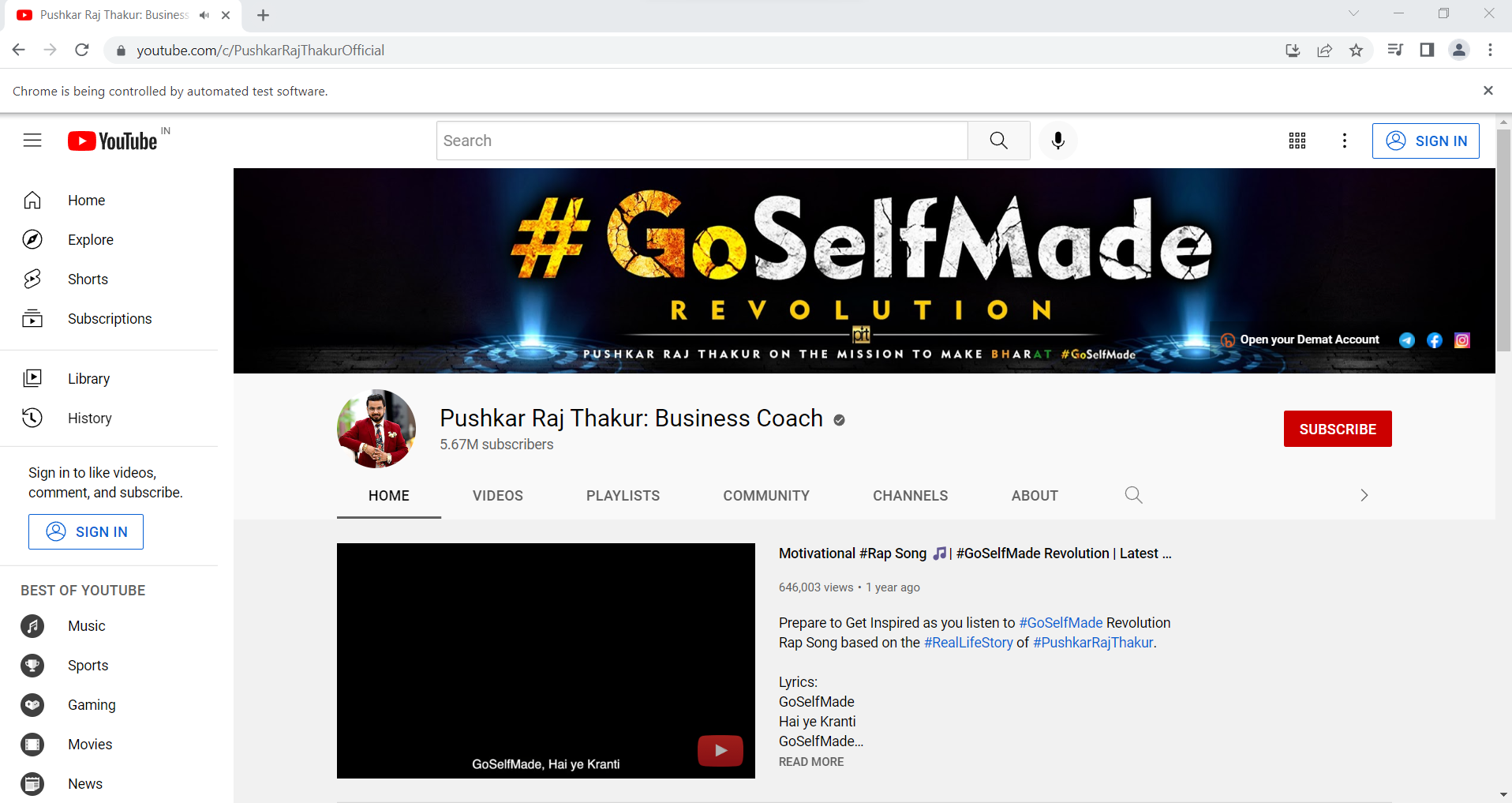
Among these 6 sections, we are concerned with only the Videos and About sections as they would give us the information we require.
Videos – This section will help us understand the upload frequency of the channel. This page lists all the videos the channel posted with the respective view count and timeframe w.r.t how long back the video was posted. For our purpose, we will only look at the duration of the last 3 videos uploaded
About – This section will help us with the channel description, date of joining, channel views, subscriber count, and base location of the channel’s owner
We will use the following code to extract all this information
df2 = pd.DataFrame()
for i in range(0,len(df)):
driver.get(df.iloc[i]['Channel'])
time.sleep(3)
driver.find_element_by_xpath('//*[@id="tabsContent"]/tp-yt-paper-tab[2]/div').click()
time.sleep(3)
frequency = [x.text for x in driver.find_elements_by_xpath('//*[@id="metadata-line"]/span[2]')][0:3]
frequency = pd.Series(frequency)
frequency = ', '.join(map(str, frequency))
try:
driver.find_element_by_xpath('//*[@id="tabsContent"]/tp-yt-paper-tab[7]/div').click()
except:
try:
driver.find_element_by_xpath('//*[@id="tabsContent"]/tp-yt-paper-tab[6]/div').click()
except:
driver.find_element_by_xpath('//*[@id="tabsContent"]/tp-yt-paper-tab[5]/div').click()
name = driver.find_element_by_xpath('//*[@id="channel-name"]').text
name = pd.Series(name)
time.sleep(3)
desc = driver.find_element_by_xpath('//*[@id="description-container"]').text
desc = desc.split('n')[1:]
desc = ' '.join(map(str, desc))
desc = pd.Series(desc)
DOJ = driver.find_element_by_xpath('//*[@id="right-column"]/yt-formatted-string[2]/span[2]').text
DOJ = pd.Series(DOJ)
views = driver.find_element_by_xpath('//*[@id="right-column"]/yt-formatted-string[3]').text
views = pd.Series(views)
subs = driver.find_element_by_xpath('//*[@id="subscriber-count"]').text
subs = pd.Series(subs)
location = driver.find_element_by_xpath('//*[@id="details-container"]/table/tbody/tr[2]/td[2]/yt-formatted-string').text
location = pd.Series(location)
link = pd.Series(df.iloc[i]['Channel'])
tbl = pd.DataFrame({'Channel':name,'Description':desc,'DOJ':DOJ,'Last_3_Vids_Freq':frequency,'Views':views,'Subscribers':subs,'Location':location,'Channel Link':link})
df2 = df2.append(tbl)
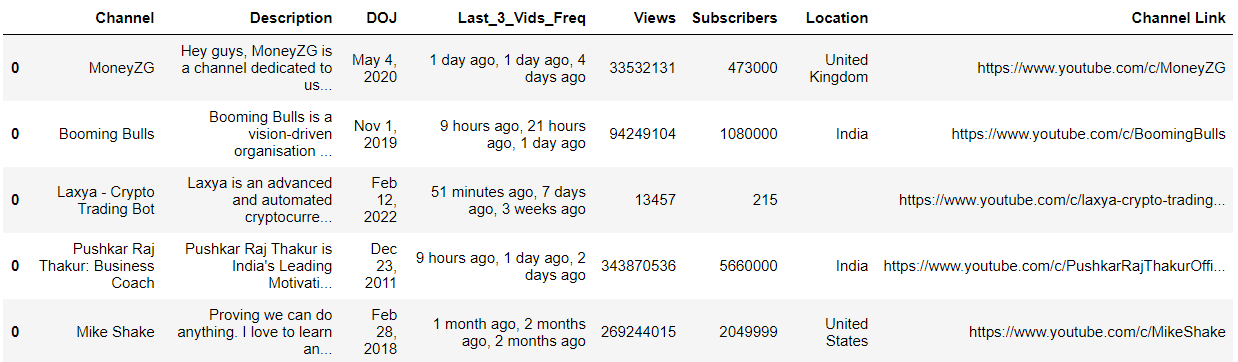
df2['Views'] = pd.to_numeric(df2['Views'].str.replace('views','').str.replace(',',''))
df2['Subscribers'] = df2['Subscribers'].str.replace('subscribers','').replace({'K': '*1e3', 'M': '*1e6'}, regex=True).map(pd.eval).astype(int)
df2.head()
Stage 3 – Data Filtering
Until now, we have obtained a list of 64 YouTube channels that showed up among the results when we searched using our identified keywords. As we can see from the sample output, not all will be of use to us. We will go back to our list of criteria, based on which we would like to collaborate with a content creator and filter our data accordingly. The criteria were as follows
1. Creates content specifically related to cryptocurrencies
2. Caters primarily to an Indian audience
3. Has more than 10,000 subscribers
4. Has more than 100,000 views across all videos
5. Is active, i.e., uploads videos regularly
We will firstly filter out channels that specifically create content related to cryptocurrencies
df2 = df2[df2['Description'].str.contains('crypto',case=False)]
Next, we need channels that primarily cater to an Indian audience. For this, we will make an assumption that a channel from a particular location creates content wanting to primarily cater to the audience from the same location. Thus, we will filter out channels with location as ‘India.’
df2 = df2[df2['Location'].str.contains('India',case=False)]
We will use our defined thresholds to further filter out the channels that meet our criteria regarding views count and subscribers.
df2 = df2[(df2['Views']>=100000)&(df2['Subscribers']>=10000)]
Lastly, we will remove the channels that had less than 3 uploads in the past one month with the following line of code
df2 = df2[~((df2['Last_3_Vids_Freq'].str.contains('months')) | (df2['Last_3_Vids_Freq'].str.contains('years')))]
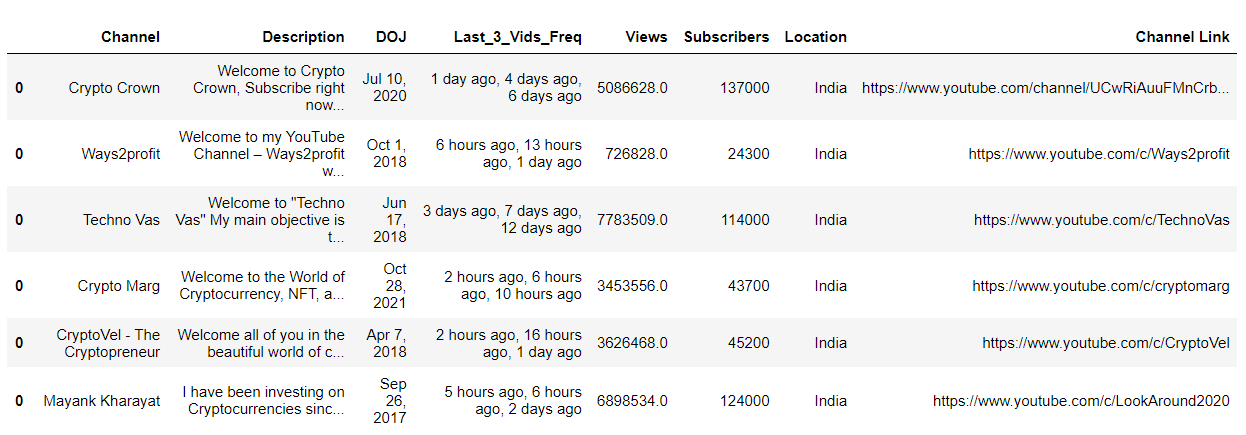
We have a curated list of 6 channels that meet all of our criteria – Crypto Crown, Ways2profit, Techno Vas, Crypto Marg, CryptoVel – The Cryptopreneur, and Mayank Kharayat. We can reach out to these six channels for potential collaboration and promote our products through them.
Conclusion
In this article, we used web scrapping with Python to identify relevant influencers on YouTube who can be ‘potential brand ambassadors for an organization dealing with cryptocurrencies. The process is very handy for small firms and startups as they look to increase their reach quickly. Collaborating with relevant influencers on digital platforms like YouTube, Instagram, Facebook etc., can facilitate the process as it enables the organization to leverage the massive follower base of the influencer and widen its reach in a short span of time and at a minimal cost.
Key Takeaways
- Collaboration with digital influencers is one of the most effective means to increase audience reach in today’s day and age
- Web scraping can be a handy technique to extract a list of relevant influencers for brands, especially startups
- One should carefully understand the audience and the reach of the identified list and, based on one’s preferred criteria, collaborate with the most suitable digital influencers
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a data scientist with a passion for innovative problem-solving. With years of experience in the industry, I work with one of the world's leading cloud-based software companies, where I apply my expertise in data analysis, modelling, and visualization to drive meaningful insights and help businesses make data-driven decisions. Through my work, I have gained a deep understanding of the latest technologies and tools in the field of data science and machine learning, and I am always eager to learn more and stay up-to-date with the latest trends and developments. In my free time, I enjoy exploring new coding techniques, experimenting with new data sets, and sharing my knowledge and experience with other data scientists and enthusiasts.





