This article was published as a part of the Data Science Blogathon.
Introduction
Since the dawn of this millennium, technology has seen rapid advancement. This has led to the introduction of many news channels across different media viz. electronic including online and television, and print media. An increase in the number of platforms and channels has also paved the way for ever-increasing competition. Sensationalization has become a new way of attracting the attention of the audience, particularly for electronic media which at times is driven by fake news. Machine learning holds a promise in differentiating between real news and fake news. In this article, we shall be making use of a dataset to understand the technicalities of machine learning in detecting fake news.
Dataset
The dataset of fake and real news that has been used in this article can be downloaded here–
Importing the Dependencies
At the outset, we shall be importing the dependencies with the help of the following lines of code-
import numpy as np
import pandas as pd
import re
from nltk.corpus import stopwords
from nltk.stem.wordnet import WordNetLemmatizer
import string
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrixWe start by importing numpy, pandas, and re. ‘re’ is an in-built package that stands for the regular expression. A search pattern is formed with the help of a sequence of characters. Then, we shall be importing stopwords. Stopwords are words that are not very significant like a, an, etc. We import stopwords from nltk.corpus where ‘nltk’ is the natural language tool kit and ‘corpus’ is a repository of stopwords.
Lemmatization is done to convert the word to its base form. There is also a process called stemming which also converts the word to its base form but lemmatization is more contextual compared to stemming. For this, we shall import WordNetLemmatizer from nltk.stem.wordnet Lemmatization is done by using wordnets inherent function known as morphy. nltk.stem is the library for python Lemmitization. Next, we shall import string to use any constant and classes.
Now, we import TfidVectorizer from sklearn.feature_extraction.text. TfidVectorizer is Term Frequency Inverse Document Frequency that transforms text into a meaningful collection of numbers. The numbers are used to fit the machine algorithm for prediction. This makes use of the package sklearn.feature_extraction which extracts features in a format supported by machine learning. As this is a binary classification problem, we shall be using logistic regression to classify real and fake news. Next, we shall import nltk and download stopwords.
import nltk
nltk.download('stopwords')

Then, we shall print the stopwords in english with the help of print function.
print(stopwords.words('english'))

Next, we shall read the files by creating a dataframe with the help of the following lines of code
true_data = pd.read_csv('True.csv')
fake_data = pd.read_csv('Fake.csv')
Next, we shall be creating target columns for both true and fake data
true_data['Target'] = 0 fake_data['Target'] = 1
Then, we concatenate both the true and the fake data into a common dataframe ‘data’
data = pd.concat([true_data,fake_data]).sample(frac=1, random_state = 1).reset_index(drop=True) data

Data Pre-processing
Before developing the data model, we shall be pre-processing the data. With the help of the shape function, we will be able to identify a number of rows and columns.
data.shape
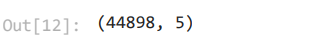
There are 44898 rows and 5 columns. Then, we shall be printing the first 5 rows of the dataframe by using the head() function.
data.head()
Then, missing values of the dataset are found by using isnull() function.
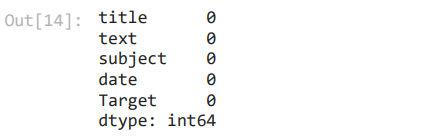
The above output indicates that there are no missing or null values in the dataset. Next, we shall merge columns into a common pandas dataframe ‘content’ with the help of the following lines of code
data['content'] = data['title'] + ' ' + data['text']
Next, we shall use the print function to generate the output of content.
print(data['content'])

Now, we shall be separating the data and target.
X = data.drop(columns='Target', axis=1) Y = data['Target']
Then, we shall print the data and target which are stored in variables X and Y respectively.
print(X) print(Y)
We shall be doing lemmatization to convert the word to its base form.
def clean(doc):
stop = stopwords.words('english')
punct = string.punctuation
wnl = WordNetLemmatizer()
stopwords_free = " ".join([i for i in doc.lower().split() if i not in stop])
punctuations_free = "".join(ch for ch in stopwords_free if ch not in punct)
normalized = " ".join(wnl.lemmatize(word) for word in punctuations_free.split())
return normalized
Then, we shall print the content dataframe.
We shall be doing lemmatization to convert the word to its base form.
def clean(doc):
stop = stopwords.words('english')
punct = string.punctuation
wnl = WordNetLemmatizer()
stopwords_free = " ".join([i for i in doc.lower().split() if i not in stop])
punctuations_free = "".join(ch for ch in stopwords_free if ch not in punct)
normalized = " ".join(wnl.lemmatize(word) for word in punctuations_free.split())
return normalized
Then, we shall print the content dataframe.
print(data['content'])

Next, we shall be using .values method to view the values of the dictionary as a list. We shall also be separating the data and the target stored in X and Y respectively. Also, we would print both data and target.
X = data['content'].values Y = data['Target'].values
print(X)

print(Y)

Now, we shall be converting the textual data to numerical data. This shall be done using TfidVectorizer which shall be imported from sklearn.feature_extraction.text. TfidVectorizer is Term Frequency Inverse Document Frequency that transforms text into a meaningful collection of numbers.
vectorizer = TfidfVectorizer() vectorizer.fit(X) X = vectorizer.transform(X)
We have fit X for transformation. Now, we shall be printing X to see the transformation.
print(X)
So, from the above output, we can draw the inference that ‘X’ has successfully transformed. This will be followed by splitting of the dataset into training and testing data.
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, stratify= Y, random_state=5)
In the above line of code, the test data would be 20% of the dataset.
Model Development
The first step of model development is to train the model. Here, we shall be using a logistic regression classification algorithm to differentiate between fake and real news. This will be done by fitting the data.
model = LogisticRegression() model.fit(X_train, Y_train)

The model has been developed, now we shall be evaluating the model.
Evaluation of Model
The model is evaluated with the help of an accuracy score and confusion matrix. First of all, we would obtain the accuracy score of the training dataset by using the following lines of code
X_train_prediction= model.predict(X_train) training_data_accuracy = accuracy_score(X_train_prediction, Y_train)
Then, we shall find the accuracy score of the training dataset
print('Accuracy score of the training data : ', training_data_accuracy)

From the output generated above, the accuracy of the training dataset is 99.19% indicating high accuracy of almost a perfect 100%.
Next, we shall find the accuracy of the testing dataset on a code very similar to the one we did for the training dataset
X_test_prediction = model.predict(X_test) test_data_accuracy = accuracy_score(X_test_prediction, Y_test)
Then, we shall find the accuracy score of the testing dataset
print('Accuracy score of the test data : ', test_data_accuracy)

From the output generated above, the accuracy of the testing dataset is 98.99%, almost 99% indicating high accuracy.
The last step would be to generate a confusion matrix which would identify the percentage of the dataset that has been classified as true positive, true negative, false positive, and false negative.The confusion matrix is depicted below
| Predicted: Yes | Predicted: No | Total | |
| Actual: Yes | a (T.P) | b (F.N) | a+b (Actual yes) |
| Actual: No | c (F.P) | d (T.N) | c+d (Actual No) |
| Total | a+c (Predicted yes) | b+d (Predicted No) | a+b+c+d |
| Here, T.P = True Positive, F.N = False Negative, F.P = False Positive, T.N = True Negative |
print(confusion_matrix(X_test_prediction,Y_test))

In this dataset, the model could classify 4243 as T.P and 4647 as F.P indicating a small percentage of misclassification.
Conclusion to Machine Learning
The key takeaways of this article are-
- We comprehended how to import dependencies particularly with respect to natural language processing.
- We developed an understanding of the application of lemmatization and vectorization for data pre-processing.
- Usefulness of logistic regression as a potent tool in binary classification as it could accurately distinguish between fake and real news to the tune of 99%.
- A very negligible misclassification percentage as only 49 got classified as false negative and 41 as false positive.
- There is another classification tool PassiveAggressiveClassifier which is an online classification tool very useful for data flowing from Twitter, etc. every second which we shall be discussing very soon.
Thank you for taking the time to go through this article on detecting fake and real news using machine learning. Stay safe!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a biotechnology graduate with experience in Administration, Research and Development, Information Technology & management, and Academics of more than 12 years. I have experience of working in organizations like Ranbaxy, Abbott India Limited, Drivz India, LIC, Chegg, Expertsmind, and Coronawhy.
Recognition:
1. Played major role in making a brand “Duphaston” worth “Rs 100 crores INR” in Abbott India Limited as Therapy Business Manager of Women’s health and gastro intestine team.
2. Won “best marketing skills” award in Abbott India Limited.
3. Came on the merit list of National IT aptitude test, 2010.
4. Represented my school in regional social science exhibition.
Courses and Trainings:
1. Took 54 hours training on vb.net in Niit, Guwahati.
2. Underwent training of 7 days on targeting and segmentation in Abbott India ltd, Lonavala.
3. Earned “Elite Certificate” from IIT-Madras on “Python for Data Science”.





