This article was published as a part of the Data Science Blogathon.
Introduction
Over the past few years, advancements in Deep Learning coupled with data availability have led to massive progress in dealing with Natural Language. Though it can seem quite diverse, NLP is restricted – when it comes to the ‘Natural Languages’ it can deal with in the present day.
Let’s play a game! I’ll throw a word at you, and you say the first thing that comes to your mind. Here we go!
So what did you think? Perhaps, a massive text corpus? Summarization? or a poetry-generating model? Whatever it was, I’m sure all of it was in English. When dealing with NLP, people tend to use the terms ‘Natural Language’ and ‘English’ synonymously. As heightened in its name, the spectrum of ‘Natural Language Processing isn’t confined to any one language. Given the current scenario of research and resources, it is clear that Indian Languages are understudied and underrepresented in NLP. This article endeavours to dig into the complexities in NLP for Indic Languages and explore the available tools for the same. So let’s dive right in!
.png)
Why can’t English NLP Techniques be applied to Hindi?
One can surely argue that since we usually work in NLP with embeddings, why can one not use the same techniques as one employs in English. This, however, is not feasible – natural languages tend to have structural differences. To have a better understanding, here are a few ways in which English and Hindi differ:
1. Subject-Verb-Object Vs Subject-Object-Verb Structuring
Sentences in English follow a Subject-Verb-Object (SVO) sentence structure, while in Hindi, sentences follow a Subject-Object-Verb (SOV) sentence structure. The same is exemplified below:

Sentence Structuring: English Vs Hindi
Logically, six structuring variants are possible in Natural Languages. These variants, along with no. of languages using them, are depicted below:

2. Preposition vs Postposition case-markers:
English uses ‘Prepositions’ as case markers, i.e. the position-denoting word comes before the place/position it indicates. On the other hand, Hindi uses ‘Post-positions’ as case markers, i.e. the position-denoting word after before the place/position it indicates. The same has been exemplified below:

Preposition Vs Postposition Case-Markers
3. Agility in Word Order
The sequence of words does not always matter in Hindi, i.e. changing the sequence of words would not change the meaning of the sentence. The same has been exemplified below:

These were just a few linguistic differences between Hindi and English that caused the two to be treated differently while performing NLP operations.
Challenges in NLP for Indic Languages
Apart from these structural differences we just saw, there are more challenges regarding NLP for Indic languages. The same are enlisted below:
1. Lack of Corpa and resources in Indian Languages
2. Lack of education and training institutes.
3. Ambiguity in Indian languages due to colloquial variations.
4. Geographical limitations of Indic Languages’ usage.
iNLTK: A library for Indic NLP
Now that we have understood the complexities and challenges in NLP for Indian Languages, it’s time to explore iNLTK (Natural Language Toolkit for Indic Languages). We are all aware of the popular NLP library NLTK; iNLTK transcends some useful capabilities of NLTK for Indian Languages.
Installation:
iNLTK can be easily installed using pip:
pip install inltk
As a dependency, you will need to install Pytorch version 1.3.1 as follows:
pip install torch==1.3.1+cpu -f https://download.pytorch.org/whl/torch_stable.html
Languages:
iNLTK allow its users the processing of a multitude of Natural Languages. These languages, along with their codes, are given below:
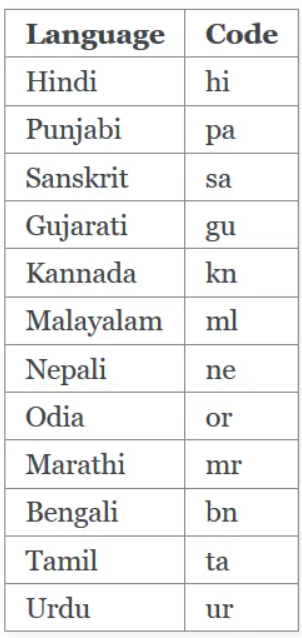
iNLTK Languages
Import and Setup:
Once we import the iNLTK library, we need to set the language up in the first place. Suppose we want to perform NLP operations on Hindi text, then this is how we’ll import and setup:
from inltk.inltk import setup
setup('hi') #Hindi
Please note that you need to do the setup while using the language for the first time; it downloads the requirements to the system. Once done, you need not set it up subsequently.
Tokenization using iNLTK
Tokenization refers to breaking the text into tokens, i.e. smaller units that can be used further for vectorization/generating embeddings. iNLTK provides an in-built function for tokenizing text data.
from inltk.inltk import tokenize text = 'काम को समय पर पूरा करना सबसे अच्छा है।' tokenize(text ,'hi')
Output:
[‘▁काम’, ‘▁को’, ‘▁समय’, ‘▁पर’, ‘▁पूरा’, ‘▁करना’, ‘▁सबसे’, ‘▁अच्छा’, ‘▁है’, ‘।’]
Generating Text Embeddings using iNLTK
Text embeddings are vectorized representations of textual data that can be fed to Machine/Deep Learning models for training. iNLTK proposes a function that generates embeddings of texts belonging to the available languages.
from inltk.inltk import get_embedding_vectors text = 'काम को समय पर पूरा करना सबसे अच्छा है।' vectors = get_embedding_vectors(text, 'hi') print(vectors)
Output:
[array([-0.084885, 0.014608, 0.224804, -0.403952, ..., -0.174789, -0.143138, 1.049093, 0.608228], dtype=float32), array([-0.254694, -0.020739, 0.008523, -0.348004, ..., 0.709753, -0.114417, 0.637649, -2.84761 ], dtype=float32), array([ 0.564121, -0.022803, 0.089818, -0.516518, ..., 0.129719, -0.034008, 0.432018, -0.204092], dtype=float32), array([-0.420775, -0.214894, -0.147413, -0.308402, ..., 0.594919, 0.344362, 0.505362, -0.434814], dtype=float32), array([ 0.302292, -0.134239, 0.533092, -0.524913, ..., -0.126133, 0.013963, 0.792167, 0.354887], dtype=float32), array([-0.12041 , 0.005264, -0.74978 , -0.550592, ..., -0.089831, -0.079805, 0.735688, -0.36183 ], dtype=float32), array([ 0.498025, -0.002567, -0.120121, -0.613983, ..., 0.551633, -0.10827 , 0.840663, -0.468278], dtype=float32), array([ 0.159892, -0.049027, -0.104136, -0.252363, ..., -0.186087, -0.41426 , 0.714297, 0.517596], dtype=float32), array([-0.183833, -0.005238, -0.187345, -0.113823, ..., 0.062584, -1.36463 , 0.665604, -1.425032], dtype=float32), array([ 0.792413, 0.01189 , -0.71231 , -0.313467, ..., 0.190676, 0.938687, 0.464781, 0.195361], dtype=float32)]
Predicting Subsequent-Words using iNLTK
Next, word prediction is a traditional problem in NLP. As the name suggests, given a sentence/part of the sentence, we try to find out the next possible word. iNLTK simplifies this problem by providing a function for the same.
from inltk.inltk import predict_next_words text = 'काम को समय पर पूरा करना' n=3 #n is the number of words to be predicted predict_next_words(text , n, 'hi') print(predict_next_words)
Output:
काम को समय पर पूरा करना पड़ता है !
(Note: This output can differ every time you run the code)
Generating Similar Sentences using iNLTK
iNLTK proposes a function that can generate similar sentences, given an input sentence as follows:
from inltk.inltk import get_similar_sentences text = 'काम को समय पर पूरा करना सबसे अच्छा है।' n=5 #number of similar senteces you want to generate get_similar_sentences(text, n, 'hi')
Output:
[‘काम को समय पर पूरा रखना सबसे अच्छा है।’, ‘काम को वक़्त पर पूरा करना सबसे अच्छा है।’, ‘काम को समय पर संतुलित करना सबसे अच्छा है।’, ‘काम को समय पर ख़त्म करना सबसे अच्छा है।’, ‘काम पर समय पर पूरा करना सबसे अच्छा है।’]
(Note: This output can differ every time you run the code)
Checking for Sentence Similarity using iNLTK
We can use iNLTK to check how similar are two sentences and get their similarity scores. Let’s try it out for some language other than Hindi this time.
from inltk.inltk import get_sentence_similarity text1 = 'সময়মতো কাজ শেষ করা ভালো' text2 = 'সময়মতো কাজ করাটা দারুণ' get_sentence_similarity(text1, text2, 'bn')
Please ensure you set up the language as ‘Bengali’ (bn) if using it for the first time in your environment.
Output:
0.3882378339767456
These are just a few applications that iNLTK delivers; for more information, you should check out iNLTK’s official documentation here.
Conclusion
While there’s a long way to go for natural language processing in Indic languages to come at par with that in English, this article explored the available tools for the same and gauged the existing constraints.
Here’s a quick recap of what we’ve learnt in this article:
- DUE TO STRUCTURAL DIFFERENCES, English NLP techniques cannot be applied to Indian languages.
- Lack of resources, corpora and training institutions are major challenges to Indic NLP.
- iNLTK is a diversified library that performs NLP on some of the most common Indian languages.
It’s time you try it on your own! Explore iNLTK and other Indic NLP libraries, and others expand the spectrum of Natural Language Processing tasks beyond just English!
Before you go…for doubts, queries, or potential opportunities in natural language processing, please feel free to connect with me on LinkedIn or Instagram.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm Suvrat Arora, a Computer Science graduate. Enthusiastic about AI, Data Science, ML and NLP - I believe that storytelling is a significant aspect of life which has led me to develop a practice of documenting, organizing, and disseminating knowledge across domains, making me an active contributor on multiple platforms.




