
Image Credit: Datatechvibe
Introduction
The web contains a wealth of publicly available videos which can be utilized to train the RL agent for sequential domains like robotics, video games, computer use, etc. However, most of these videos only demonstrate a record of what happened but not exactly how it was achieved, i.e. the data related to the exact sequence of key presses and mouse movements to carry out an action is missing, this lack of action labels poses a challenge. Owing to this challenge and to harness the wealth of unlabeled video data available on the internet, OpenAI just released a semi-supervised imitation learning method: Video PreTraining (VPT). In this, the agents learn to act by watching (pre-training) the wealth of unlabeled video (missing action labels) data available on the internet.
Firstly, a small dataset is gathered from the contractors, including the screen recording of their actions while playing the game and the keypresses and mouse movements. Then this small dataset from contractors and a massive unlabeled video dataset of human Minecraft play are used to train a neural network (Inverse Dynamics Model) to play Minecraft. The trained inverse dynamics model (IDM) is then employed to predict the action (labels) of a much larger dataset of online videos, the actions that must have been taken at each step between two video frames. Then it learns to act via behavioural cloning.
In this post, we will take a look at Video Pre-training (VPT) method overview, results obtained, and potential avenues of future research proposed by the OpenAI researchers.
Method Overview
Figure 1 illustrates the proposed Video Pre-training method, which can be broken down into three steps:
- Training the Inverse Dynamics Models
- Collecting Clean Data
- Training the VPT Foundation Model via Behavioral Cloning
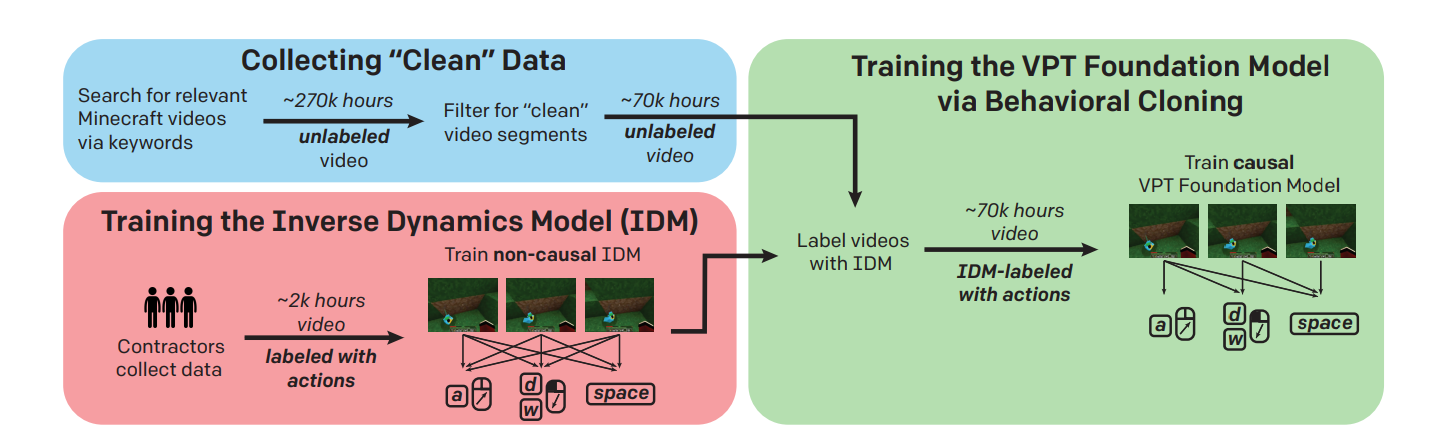
Figure 1: Video Pretraining (VPT) Method Overview (Source: Arxiv)
1) Training the Inverse Dynamics Models (IDM)
-
The IDM architecture essentially comprises a temporal convolution layer, a ResNet 62 image processing stack, and residual unmasked attention layers.
-
For training the IDM, a small amount of labelled contractor data is gathered to minimise the negative log-likelihood of action at timestep t. The experiments demonstrated that the IDM objective is much easier to learn, and a fairly accurate IDM can be trained with very little labelled data (as few as 100 hours).
-
Unlike an imitation learning strategy, the IDM can be non-causal, which means that its prediction can be a function of both past and future events. Furthermore, this trained IDM is utilized to label online videos.
2) Collecting “Clean” data (Data Filtering)
-
A large amount of dataset of Minecraft videos is gathered by searching the web for related keywords.
-
The online videos often contain artifacts due to i) watermarks, channel logos, a video feed of the player’s face, etc. ii) video feeds collected from platforms other than a computer with different gameplay, or iii) video feeds from game modes other than “survival mode” for Minecraft. The data is called “clean” when it does not contain visual artifacts and is from survival mode.
-
With enough data, a large enough model, and enough training compute, a Behavioral Cloning (BC) model trained on both unclean and clean videos would likely still perform well in a clean Minecraft environment. However, for the sake of simplicity and training compute efficiency, a model was trained and used to filter out unclean segments using a small dataset comprising 8800 images sampled from online videos labelled as clean or unclean by contractors.
3) Training the VPT foundation model via Behavioral Cloning
-
A foundation model was trained with behavioural cloning (BC) such that the negative log-likelihood of actions predicted by the IDM on clean data is minimized.
-
Furthermore, this model exhibits nontrivial zero-shot behaviour and can be fine-tuned with both imitation learning and RL to perform even more complex skills.
For a particular trajectory of length T, the following expression is minimized:
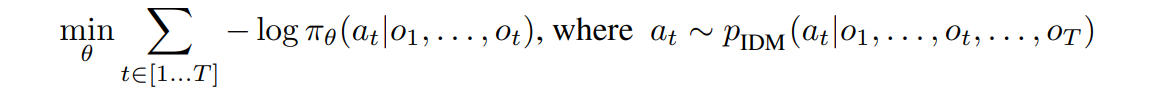
Results
Performance of the Inverse Dynamics Model

Figure 2: (Left) IDM keypress accuracy and mouse movement as a function of dataset size. (Right) IDM vs behavioural cloning data efficiency. (Source: Arxiv)
-
IDM was trained only on 1962 hours of data and achieved 90.6% keypress accuracy and a 97% accuracy for mouse movements evaluated on a held-out validation set of contractor-labelled data.
-
Figure 2 (right) validates the hypothesis that the IDMs can be trained with relatively less labelled data than the Behavioral Cloning (BC) models since inverting environment mechanics is significantly simpler than modelling the entire distribution of human behaviour.
-
Furthermore, it was found that it is more effective to use contractor data within the VPT pipeline by training an IDM than it is to train a foundation model from contractor data directly.
VPT Foundation Model Training and Zero-Shot Performance

Figure 3: (Left) Training and validation loss on the web_clean internet dataset with IDM pseudo-labels and loss on the main IDM contractor dataset (Right) Amount a given item was gathered per episode (Source: Arxiv)
-
The models were evaluated by measuring validation loss and were rolled out in the Minecraft environment.
-
Minecraft environment was chosen because (1) it is one of the world’s most actively played video games. Thus, freely available video data is abundant, and (2) it is open-ended with a wide range of things to do, similar to real-world applications.
-
The behavioural cloning (BC) model (the “VPT foundation model”), which was trained on 70,000 hours of IDM-labeled online video, performs tasks in Minecraft that are practically impossible to achieve with RL from scratch.
-
It learns to chop down trees to collect logs, craft those logs into planks, and then craft those planks into a crafting table. In addition, the model can swim, jump pillars, hunt for food, and eat it.
Fine-Tuning with Behavioral Cloning
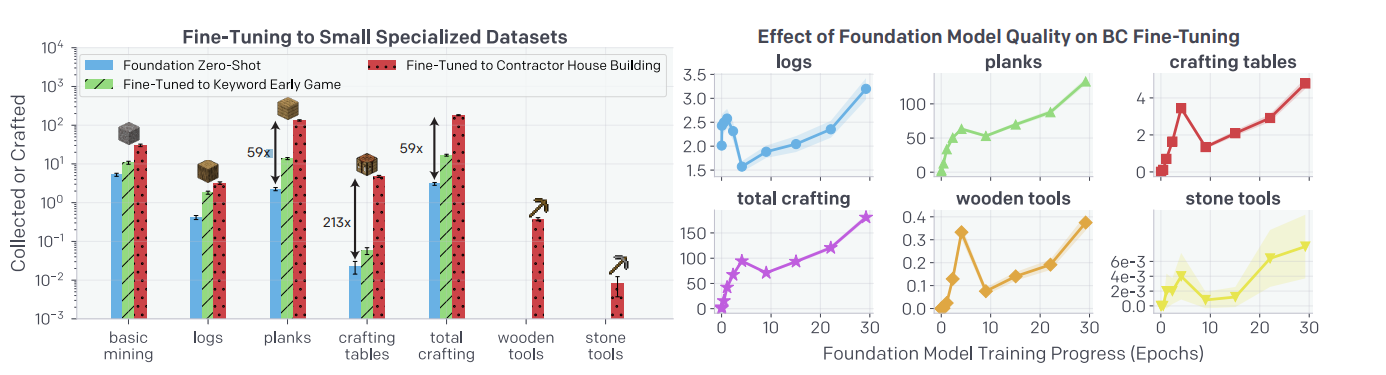
Figure 4: (Left) Collection and crafting rates for three policies: the zero-shot VPT foundation model and the VPT foundation model BC fine-tuned to the earlygame_keyword or contractor_house datasets. (Right) Collection and crafting rates for VPT foundation model snapshots
during training, after they are, BC is fine-tuned to the contractor_house dataset.
-
Foundation models are designed to have a broad behaviour profile and are generally capable of performing various tasks. And they are fine-tuned on specific datasets given based on the task.
-
When fine-tuned on the more narrow, targeted dataset, a massive gain in reliably performing the early game skills already present in the foundation model is observed. The fine-tuned model also learns to craft both wooden and stone tools.

Figure 5: Sequence of items required to craft a stone pickaxe, labelled with the median time it takes proficient humans to reach each step. (Source: OpenAI)
Crafting of a crafting table “zero-shot” (Source: 80.lv)
Fine-Tuning with Reinforcement Learning
 Figure 6: Illustration of sequence of items for acquiring a diamond pickaxe. (Source: OpenAI)
Figure 6: Illustration of sequence of items for acquiring a diamond pickaxe. (Source: OpenAI)
-
To demonstrate the efficacy of RL fine-tuning, a challenging task of obtaining a diamond pickaxe within 10 minutes starting from a fresh Minecraft survival world was assigned. Doing so requires complex skills like mining, inventory management, crafting with and without a crafting table, tool use, operating a furnace, and mining at the lowest depths, where many hazards like enemies and lava exist (Fig. 6). Adding to the challenge, progress can be easily lost by dropping items, destroying items, or dying.
-
Agents are rewarded for each item gathered in the sequence. Lower rewards are awarded for items that have to be collected in bulk and higher rewards for the items near the termination of the sequence.
-
A major problem when fine-tuning with RL is catastrophic forgetting because previously learned skills can be lost before their value is realized. To combat the catastrophic forgetting of latent skills such that they can continuously boost exploration throughout RL fine-tuning, an auxiliary Kullback-Leibler (KL) divergence loss is added between the RL model and the frozen pre-trained policy. Notably, the treatment without a KL loss obtains only items early in the sequence (logs, planks, sticks, and crafting tables) and fails to progress further into the sequence.
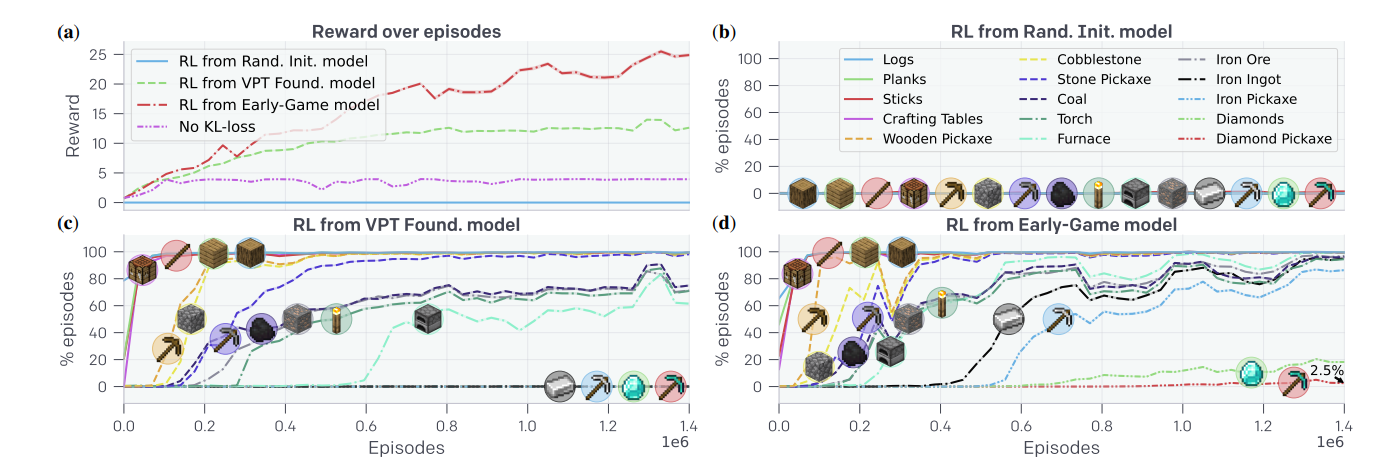
Figure 7: RL Fine-tuning results. (a) Reward over episodes (b) RL from a randomly initialized model (c) RL fine-tuning from the VPT Foundation model (d) RL fine-tuning from the early-game model (Source: Arxiv)
-
Figure 7 a): The training from a randomly initialized policy fails to achieve almost any reward.
-
Figure 7 b): RL from a randomly initialized model occasionally collects sticks by breaking leaves and never learns to reliably collect logs.
-
Figure 7 c): The RL fine-tuning from the VPT foundation model teaches everything in the curriculum, including mining iron ore and crafting furnaces. However, the agent fails to smelt an iron ingot.
-
Figure 7 d): The RL fine-tuning from the early-game model learns to gather all items in the sequence towards a diamond pickaxe and crafts a diamond pickaxe in 2.5% of episodes. The results get better by BC fine-tuning the VPT Foundation Model to the earlygame_keyword dataset and subsequently fine-tuning with RL. Furthermore, it was found that the three-phase training (pretraining, BC fine-tuning, and then RL fine-tuning) succeeds in learning extremely complex tasks.
Data Scaling Properties of the Foundation Model
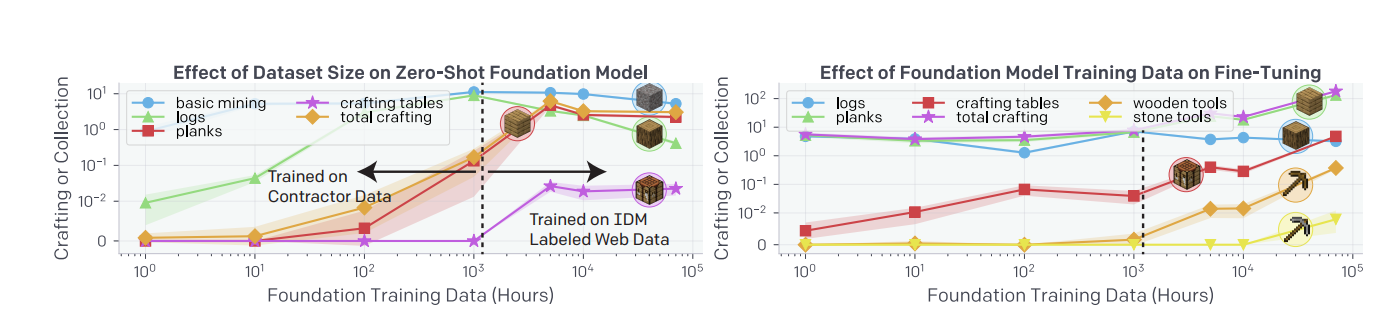
Figure 8: (Left) Effect of Dataset size on the zero-shot foundational model (Right) Effect of foundation model training on fine-tuning (Source: Arxiv)
-
It was hypothesized that it is far more effective to use labelled contractor data to train an IDM than it is to directly train a BC foundation model from that same small contractor dataset. To validate this hypothesis, foundation models were trained on increasing amounts of data from 1 to 70,000 hours.
-
Figure 8 (left) illustrates the comparison between foundation models trained on increasing orders of magnitude of data from 1 hour up to the full ∼70k hours web_clean dataset. Foundation models trained = 5k hours are trained on subsets of web_clean, which
does not include any IDM contractor data. -
Following the experiments, it was found that the zero-shot model only begins to start crafting tables at over 5000
hours of training data. Also, when each foundation model is fine-tuned to contractor_house, it was noticed that the crafting rates for crafting tables and wooden tools increase by orders of magnitude when using the
entire ∼70k hour web_clean dataset.
Effect of IDM Quality on Behavioral Cloning
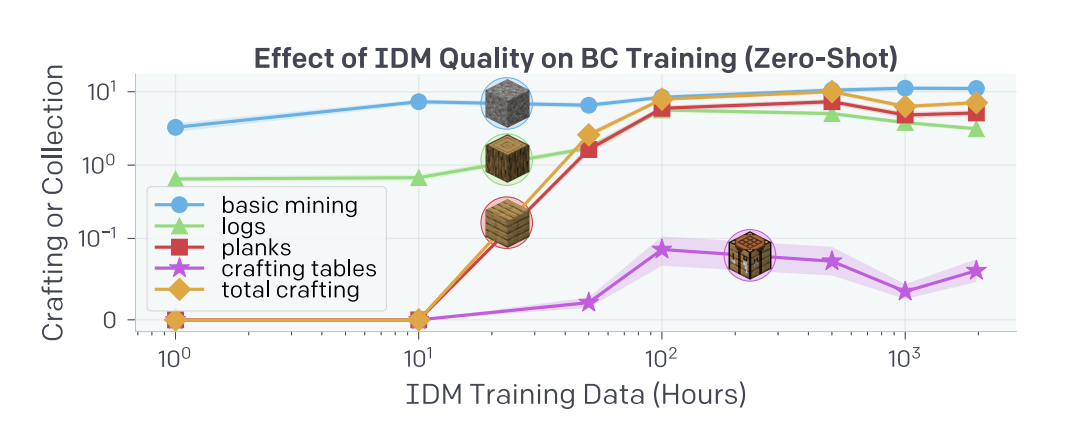
Figure 9: Zero-shot performance of BC models trained from scratch on the earlygame_keyword dataset labelled with IDMs that were trained on increasing amounts of contractor data. (Source: Arxiv)
-
It was investigated how downstream BC performance is affected by IDM quality. IDMs were trained on increasingly larger datasets and used each to independently label the earlygame_keyword dataset.
-
IDMs trained on at least 10 hours of data are required for any crafting, and the crafting rate increases quickly up until 100 hours of data, after which it saturates. Similarly, crafting tables are only crafted after 50 or more hours of IDM data and gain a plateau after 100 hours. These results suggest that the number of hours of data could be reduced to as low as 100 hours for skilful crafting.
Future Work
-
The loss was not consistently correlated with downstream evaluation metrics, making progress slow and difficult to achieve. The next step would be to investigate the correlation between various training metrics and downstream evaluations.
-
Furthermore, all the models in this work were conditioned exclusively on past observations; we cannot ask the model to execute certain tasks. The experiments on conditioning the models on closed captions (text transcripts of speech in videos) revealed that the models become weakly steerable, this needs to be investigated further.
-
To implement sequential conditional action spaces to completely model the joint distribution and have the model predict future text and the next action.
Ethical Considerations
While the researchers do not anticipate any direct negative societal impacts from the models trained, however, they claim that with the improvisation and expansion of VPT to other domains, it will be immensely crucial to assess and mitigate harms inflicted by other forms of pre-training on the internet datasets, such as emulating inappropriate behaviour.
Conclusion
In this post, we explored a semi-supervised imitation learning method called Video Pretraining (VPT) proposed by OpenAI researchers. This method enables the RL agents to learn to act by watching the wealth of unlabeled data freely available on the internet. It was noted that VPT can perform remarkably well even when the downstream task is not learning to act in that domain. Although researchers only experimented in Minecraft, researchers believe that the findings apply to other domains, such as computer usage. In hopes of assisting future research prospects, OpenAI has open-sourced contractor data, Minecraft environment, model code, and model weights in the hopes that it will aid future research prospects.
To sum it up, the key takeaways from this post are:
-
OpenAI researchers just released a semi-supervised imitation learning method called Video PreTraining (VPT) that enables the RL agents to learn to act by watching freely available unlabeled video data.
-
Dataset gathered from the contractors (which includes screen recording of actions, keypresses, and mouse movements) along with a massive unlabeled video dataset of human Minecraft play is used to train a neural network (Inverse Dynamics Model) to play Minecraft.
-
The trained inverse dynamics model (IDM) is then employed to predict the action (labels) of a much larger dataset of online videos, the actions that must have been taken at each step between two video frames. Then it learns to act via behavioural cloning.
-
The models demonstrated remarkable zero-shot performance and, when fine-tuned with RL, achieved an unprecedented result of crafting a diamond pickaxe in Minecraft, a task that usually takes skilled humans over 20 minutes (24,000 actions).
Read the paper: https://arxiv.org/abs/2206.11795
View code and Model weights: https://github.com/openai/Video-Pre-Training
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]





