This article was published as a part of the Data Science Blogathon.
Introduction
In this article, we will build a simple recommendation system. For a given product, we will try to suggest or recommend similar-looking products. E-commerce websites often use such recommender systems. It works on a simple logic – if a consumer shows interest in a product by browsing its page, he/she will probably be inclined to show interest in similar products.
We use state-of-the-art pre-trained models for most image-classification tasks and apply transfer learning. Such Pre-trained models focus on correctly predicting the output class (or on reducing a loss function that’s geared towards maximizing predicted class probabilities). However, a recommender system suggests alternatives to a given product. To do that, we need to retrieve information from images. In this article, we will see a way to create image embeddings. We will use images of food and recommend similar-looking food images. The same can be downloaded here.
How does a computer represent an image?
Suppose you have an image of width 3 and height 3. The below illustration shows how the image is represented
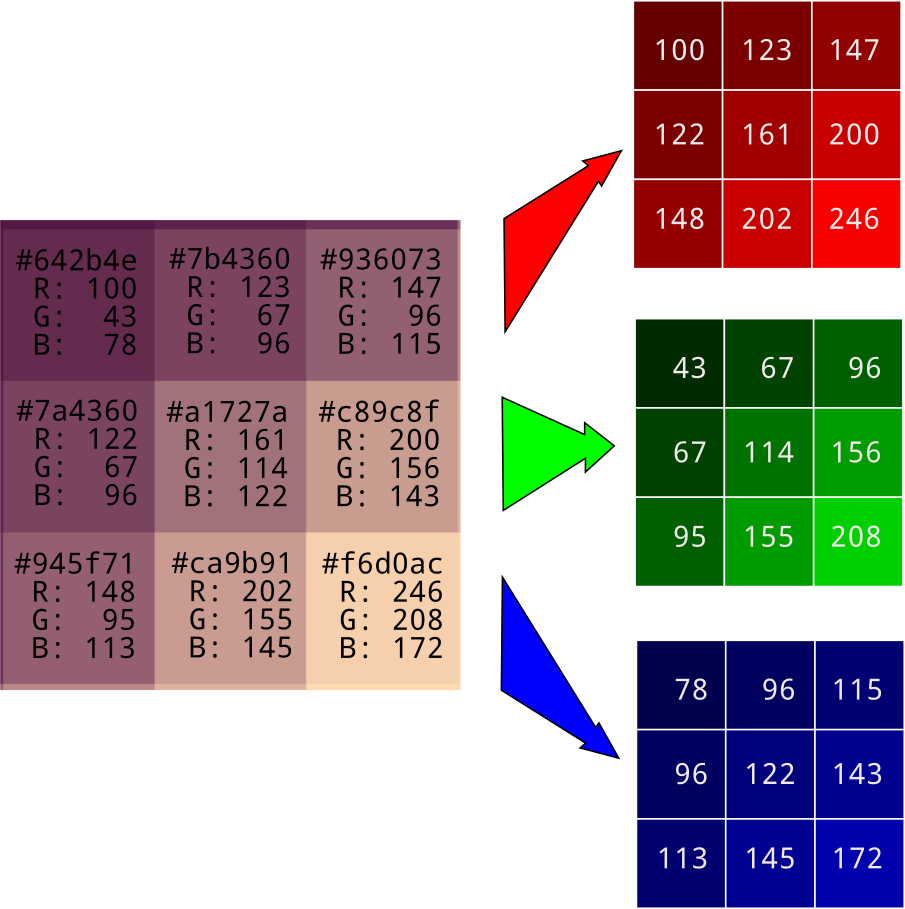
Each image can be broken down into the three primitive colors: Red, Green, and Blue. As shown above, we can represent every color using a 2-D matrix. Each cell of the matrix contains the pixel value. These pixels constitute the color saturation (or brightness). E.g., For Red, we have a matrix where each cell can have a value between (0,255). Each one is a different hue of red. So, for an image of size 3 x 3, we have a
- Red color having a matrix of size = 3 x 3 = 9 pixels
- Green color having a matrix of size = 3 x 3 = 9 pixels
- Blue color having a matrix of size = 3 x 3 = 9 pixels
- So the entire image will be represented by a matrix of width X height X Components = 3 x 3 x 3 = 27 pixels.
However, in real world, the image size are usually not so small with a shape of 3 X 3. For e.g. a 1080p image has a shape of 1920 x 1080. So the entire 1080p image will need 1920 x 1080 x 3 = 6,220,800 pixels. Let’s look at the code to fetch the components:
# import the necessary packages
import cv2
import imutils
import numpy as np
from matplotlib import pyplot as plt
#%matplotlib inline
#img_path = ‘food101/images/image_pizza_1.jpeg’
img_path = 'pizza.png'
im = cv2.imread(img_path)
plt.axis('off')
plt.imshow(im[:,:,::-1])
plt.title('Original Image')
plt.show()

row,col,plane = im.shape
red_component = np.zeros((row,col,plane),np.int64)
red_component[:,:,0] = im[:,:,0]
plt.axis('off')
plt.imshow(red_component)
plt.title('Red Component')
plt.show()
green_component = np.zeros((row,col,plane),np.int64)
green_component[:,:,1] = im[:,:,1]
plt.axis('off')
plt.imshow(green_component)
plt.title('Green Component')
plt.show()
blue_component = np.zeros((row,col,plane),np.int64)
blue_component[:,:,2] = im[:,:,2]
plt.axis('off')
plt.imshow(blue_component)
plt.title('Blue Component')
plt.show()



What is Image Embedding?
As we saw above, for a 1080p image, we need to store 1920 x 1080 x 3 = 6,220,800 pixels. These pixels are the visual representation of information like people, objects, etc. Since, we are trying to build an image recommendation system, using ~6M pixels to identify similarities will be computationally expensive. Is there an easier way to represent the image?

The short answer is Yes.
Instead of using image pixels, we can use Image Embedding. Image Embedding can be thought of vector representation of an image. It captures the image features and information into a vector format. Let’s look into a pre-trained model to understand how we can derive image embeddings.
Resnet50 architecture
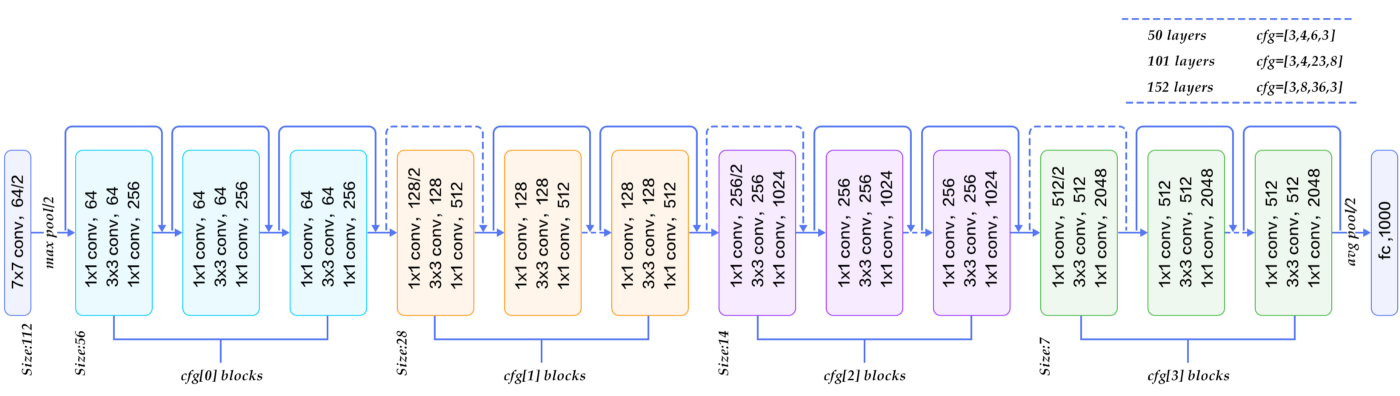
In simple terms, it takes up an image and applies several transformations using several hidden NN (Neural Network) layers. Using these transformations, it predicts which category the image belongs to. The model receives the pixel and neighbor data from an image through a convolution mechanism. More details here. Such Convolutions perform several transformations on the image data and creates a final vector. The output layer uses this final vector to classify the image into 1000 classes.
Extracting Embeddings
Instead of taking the last layer, we use the 2nd last layer of Resnet50 architecture. It contains a vector of size 2048, which is a representation of the image. This will be our image embedding. So, instead of using pixels, we can now use image embedding to represent the image features.
Let’s see how we can find out the image embedding of a single image.
from tensorflow.keras.applications.resnet50 import ResNet50,preprocess_input, decode_predictions
from tensorflow.keras.preprocessing import image
import numpy as np
import pandas as pd
import cv2
from tqdm.auto import tqdm
import os
from matplotlib import pyplot as plt
%matplotlib inline
def return_image_embedding(model,img_path):
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
curr_df = pd.DataFrame(preds[0]).T
return curr_df
model = ResNet50(include_top=False, weights='imagenet', pooling='avg')
img_path = 'food101/images/image_french_fries_692.jpeg'
return_image_embedding(model,img_path)

Great, its working. Now, let’s use a for loop and find the image embeddings for all images.
images_path = os.listdir('food101/images/')
embedding_df = pd.DataFrame()
for curr_img in tqdm(images_path):
curr_df = return_image_embedding(model,img_path)
curr_df['image'] = curr_img
embedding_df = pd.concat([embedding_df,curr_df],ignore_index=True)
How to find similar images?
Here, we will use cosine distance to determine the similarity. This article beautifully explains cosine similarity. It measures the distance between 2 vectors. As we can visually, if both the vectors are aligned, the angle between them will be 0. cos 0 = 1. So, mathematically, this distance metric will be used to find the most similar image.
Logic: For a given image, use the cosine similarity between the embeddings to identify the most similar images. This idea is derived using the KNN (K Nearest Neighbor) Model.
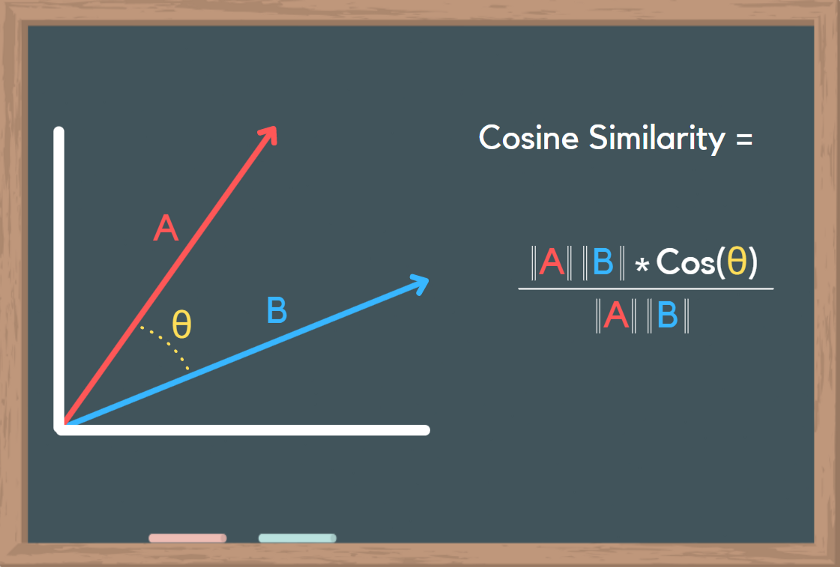
Let’s find out the cosine similarity between those embeddings.
from sklearn.metrics.pairwise import cosine_distances,pairwise_distances,cosine_similarity
cosine_similarity_df = pd.DataFrame(cosine_similarity(embedding_df.drop('image',axis=1)))
Let’s look at some samples to see how the model performed. Before that, let’s create a function to show the image.
def show_img(image_name,title=image_name):
img_path = 'food101/images/'+str(image_name)
im = cv2.imread(img_path)
im = cv2.resize(im, (960, 540))
plt.axis('off')
plt.imshow(im[:,:,::-1])
plt.title(title)
plt.show()
Now, let’s write a code to fetch the top n similar images basis the cosine distance
def fetch_most_similar_products(image_name,n_similar=7):
print("-----------------------------------------------------------------------")
print("Original Product:")
show_img(image_name,image_name)
curr_index = embedding_df[embedding_df['image']==image_name].index[0]
closest_image = pd.DataFrame(cosine_similarity_df.iloc[curr_index].nlargest(n_similar+1)[1:])
print("-----------------------------------------------------------------------")
print("Recommended Product")
for index,imgs in closest_image.iterrows():
similar_image_name = embedding_df.iloc[index]['image']
similarity = np.round(imgs.iloc[0],3)
show_img(similar_image_name,str(similar_image_name)+' nSimilarity : '+str(similarity))
image_name = 'image_french_fries_692.jpeg'
fetch_most_similar_products(image_name)










We searched for an image of french fries. In the recommendations, there are 2 images with names = image_grilled_cheese_sandwich_702.jpeg and image_hamburger_66.jpeg
However, visually, they contain french fries. The simple logic that we build is able to pick that trait.
Let’s test for another image of pizza:
image_name = 'image_pizza_1.jpeg' fetch_most_similar_products(image_name)










Visually, most of the images look like a pizza.
Conclusion and Key Takeaways
In this article, we saw how images are represented digitally. Each image has 3 primary color components – Red, Green, and Blue and a matrix is used to store image information into pixels. But the pixel count increases with an increase in image size. So, we use image embeddings. We learned how to use a state-of-the-art model for deriving image embeddings. Then we build a simple recommender system by retrieving similar images. We used cosine distances between the embeddings to find similar images. The simple recommender system is effective, and most retrieved products look very similar
Key Takeaways
-
The information and image features can be captured in a vector (or image embedding).
- We can use state-of-the-art models to derive image embeddings using transfer learning.
- This embedding is very useful and can be used for various tasks – like image similarity, image annotation, etc.
References: Link
Thanks for reading my article!!
Feel free to connect with me on LinkedIn if you want to discuss this with me.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Scientist with extensive experience in solving many real world business problems across different domains. Possess fine blend of business knowledge, maths/stats and technology/programming.
Experienced in handling client facing roles, stakeholder management, effective communication with presentation & negotiation skills.





