This article was published as a part of the Data Science Blogathon.
Introduction
One of the sources of Big Data is the traditional application management system or the interaction of applications with relational databases using RDBMS. Such RDBMS-generated Big Data is kept in the relational database structure of Relational Database Servers.
Big Data storage and analysis of the Hadoop ecosystem, like MapReduce, Hive, HBase, Cassandra, Pig, etc., required a tool to communicate with relational database servers for importing and exporting Big Data stored in them. Sqoop is an element of the Hadoop ecosystem that facilitates interaction between relational database servers and Hadoop’s HDFS.
“SQL to Hadoop and Hadoop to SQL” is the definition of Sqoop.
Sqoop is a technology developed to move data between relational database servers and Hadoop. It is used to import data from relational databases like MySQL and Oracle into Hadoop HDFS and to export data from the Hadoop file system to relational databases. The Apache Software Foundation provides it.
How does Apache Sqoop Work?
In this post, I’ll illustrate how this is accomplished with the help of a simple Sqoop architecture. For your convenience, below is a simplified Sqoop architectural diagram.
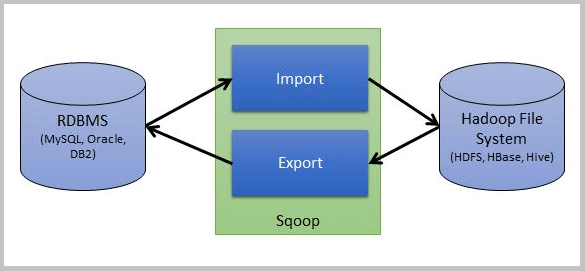
As shown in the diagram, one source is an RDBMS like MySQL and the other is a destination like HBase or HDFS, etc., and Sqoop handles the import and export operations.
Apache Sqoop Interview Questions
1. What are the significant benefits of utilizing Apache Sqoop?
Here is a list of the primary benefits of utilizing Apache Sqoop:
- Support parallel data transmission and fault tolerance- Sqoop uses the Hadoop YARN (Yet Another Resource Negotiator) architecture for concurrent data import and export procedures. YARN additionally provides a capability for fault tolerance.
- Import only essential data- Apache Sqoop just imports the necessary data. It imports a subset of rows produced by a SQL query from a database table.
- Support all major RDBMS- Sqoop supports all major RDBMS to connect to HDFS, including MySQL, Postgres, Oracle RDB, SQLite, etc. When relating to an RDBMS, the database wants JDBC (Java Database Connectivity) and a connector that supports JDBC. Because it supports entire loading tables, data may be imported straight into Hive/HBase/HDFS. Using the incremental load function, the remaining sections of the table may be loaded whenever they are modified.
- Directly loads data into Hive/HBase/HDFS- Apache Sqoop imports data from an RDBMS database into Hive, HBase, or HDFS for analysis. HBase is a NoSQL database. However, Sqoop can import data into it.
- A single command for data loading- Sqoop provides a single command for loading all tables from an RDBMS database into Hadoop.
- Encourage Compression- Sqoop includes deflate (gzip) algorithm and -compress parameter to compress data. Using the -compression-codec parameter, we can shorten the tables and put them into Hive.
- Support Kerberos Integration Security- Sqoop supports Kerberos Security authentication too. Kerberos is an authentication system for computer networks that employ “tickets” to allow nodes to communicate securely between non-secure points to confirm their identities to one another.
2. What is the function of the Eval tool?
Sqoop Eval will assist you in using the sample SQL queries. This may be performed against the database since the results can be previewed on the console. Interestingly, using the Eval tool, you would be able to determine whether the demanded data can be imported accurately.
3. What is the default file format that Apache Sqoop uses to import data?
Using two file formats, Sqoop facilitates data import. The like:
i) Delimited Text File Format
This is the default file format used for importing data using Sqoop. In addition, this file type can be explicitly selected for the Sqoop import command with the –as-textfile argument. Similarly, supplying this parameter will generate a string-based representation of all the records in the output files, with delimited rows and columns.
ii) Sequence File Format
The Sequence file format may be described as a binary file format. Their records are kept in record-specific custom data types that are shown as Java classes. In addition, Sqoop builds these data types and presents them as Java classes automatically.
4. In Sqoop, how do you import data from a specific column or row?
Sqoop enables users to Export and Import data depending on the WHERE clause.
Syntax:
-columns -where -query
5. List the fundamental Apache Sqoop commands and their respective applications.
The fundamental Apache Sqoop controls and their functions are as follows:
- Export: This function allows the HDFS directory to be exported as a database table.
- List Tables: This function would assist the user in listing all tables in a certain database.
- Codegen: This method will allow you to develop code for interacting with various sorts of database records.
- Create: This function allows the user to import the table definition into the database hive.
- Eval: This function will always assist you in evaluating the SQL statement and displaying the results.
- Version: This function will assist you in displaying information connected to the database’s text.
- Import all tables: This function assists the user in importing all tables from a database to HDFS.
- List all the databases: This method would allow a user to generate a list of all databases on a specific server.
6. What is the function of the JDBC driver in sqoop configuration? Is the JDBC driver sufficient to link sqoop to a database?
Sqoop requires a connector to link the various relational databases. Sqoop requires a JDBC driver of the database to interface with it. Nearly all database manufacturers offer a JDBC connector unique to their database.No, Sqoop requires both JDBC and a connector to connect to a database.
7. Is there a way to include Sqoop into a Java program?
To utilize Sqoop in a Java program, the Sqoop jar must be included in the classpath. If we want to use Sqoop in a Java application, we’ll have to define every single parameter programmatically. The Sqoop.runTool() method must be called after this step.
8. How can the number of mappers utilized by the sqoop function be controlled?
–num-mappers is used to regulate the number of mappers run by a sqoop command. Moreover, we should begin by selecting a limited number of map jobs and then progressively grow up, as selecting a large number of mappers at the outset may hinder database performance.
9. Comparison between Apache Sqoop with Flume.
Ans. Therefore, let’s explore all the distinctions based on their respective characteristics.
a. Data Flow
Sqoop is compatible with any relational database management system (RDBMS) that has a basic JDBC connection. In addition, Sqoop can import data from NoSQL databases such as MongoDB and Cassandra. Additionally, it supports data transmission to Apache Hive and HDFS.
Similarly, Apache Flume works with streaming data sources that are continually created in Hadoop systems. Like log files.
b. Type of Loading
Apache Sqoop – Sqoop load is not primarily driven by events.
Apache Flume – In this case, data loading is entirely event-driven.
c. When to use
Apache Sqoop — However, if the data is stored in Teradata, Oracle, MySQL, PostgreSQL, or any other JDBC-compatible database, it is a good fit.
Apache Flume – It is the greatest option for moving the majority of streaming data from sources such as JMS or spooling directories.
d. Link to HDFS
Apache Flume – Typically, Apache Flume data go to HDFS via channels.
Apache Flume – Data typically travel to HDFS using channels in Apache Flume.
e. Architecture
Apache Sqoop – Its architecture is built on connectors. However, this implies that the connectors are well-versed in interacting with numerous data sources. Similarly, data must be retrieved.
Apache Flume, on the other hand, has an agent-based architecture. Essentially, it implies that code developed in Flume is referred to as an agent, and it is responsible for obtaining data.
10. Describe the advantages of using Sqoop in the present day.
Apache Sqoop is identified as a useful resource for people who have difficulties driving data from a data warehouse. Additionally, it is used to import data from RDBMS to HDFS. Users can import several tables with the use of Sqoop. Interestingly, Apache Sqoop makes it simple to export the data-selected columns. In addition, Sqoop is compatible with the vast majority of JDBC databases. Here is a set of interview questions that can help you pass the Sqoop screening.
Conclusion
This article provides information about Sqoop along with Big data. Basically, Sqoop is a Hadoop ecosystem element that supports communication between relational database servers and HDFS. We hope that these questions may assist you in preparing for upcoming interviews. Still, if you have any questions about Sqoop Interview Questions, feel free to ask. In addition, we have seen the following:
-
How beneficial is it to use Apache Sqoop?
-
How does Sqoop Operate?
-
Essential Commands and their respective functions
-
How do Sqoop, RDBMS, and Hadoop systems link each other, and so on?
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hello, my name is Prashant, and I'm currently pursuing my Bachelor of Technology (B.Tech) degree. I'm in my 3rd year of study, specializing in machine learning, and attending VIT University.
In addition to my academic pursuits, I enjoy traveling, blogging, and sports. I'm also a member of the sports club. I'm constantly looking for opportunities to learn and grow both inside and outside the classroom, and I'm excited about the possibilities that my B.Tech degree can offer me in terms of future career prospects.
Thank you for taking the time to get to know me, and I look forward to engaging with you further!





