This article was published as a part of the Data Science Blogathon.
Introduction
Computer Vision Is one of the leading fields of Artificial Intelligence that enables computers and systems to extract useful information from digital photos, movies, and other visual inputs. It uses Machine Learning-based Model Algorithms and Deep Learning-based Neural Networks for its implementation. Computer Vision Implementations include Facial Recognition, Hand gesture recognition, Human emotion detection Analysis, Color detection, and object detection and classification, among other noteworthy applications. In this article, we will discuss YOLO(You Only Look Once), one of the supreme Object Detection and Classification Algorithm. Before diving, It’s important to know these terms and the difference between Detection and Classification.
What is Object Detection and Classification:
Object Detection and Classification techniques are widely used methods while working in the field of computer vision. Using Images/Videos/Camera feeds as inputs enables the system to recognize and classify objects in a frame in real-time.
Object Detection simply means detecting an object in a frame. To detect is to verify or acknowledge the object’s presence in the frame. The object Detection method should be able to return the object’s position in a frame.
Object Classification, on the other hand, is classifying the Objects. To classify is to predict the class of the object. i.e., It returns whether the detected object is a car, an animal, or a human like us. Convolutional Neural Network Is the most popular Neural Network for Object Classification models.
What is YOLO?
You Only Look Once(YOLO) is an algorithm that detects and recognizes various objects in a picture (in real-time). In 2015, Object Detection, Object Detection, Object Detection, and Object Detection proudly presented a new approach to the world of object detection Algorithms. The paper link is provided Object Detection. The model takes an image or a series of images (video frames) as Input and returns important features like x- coordinates, y-coordinates, Class name, and Confident score(Probability). YOLO promises excellent learning capabilities, faster speed(up to 45 FPS), and high accuracy compared to other Algorithms. It is small in size as well. YOLO V6-s is the latest addition to the YOLO family, which achieved 43.1 mAP on the COCO val2017 dataset with 520 FPS on T4 using TensorRT FP16 for bs32 inference.
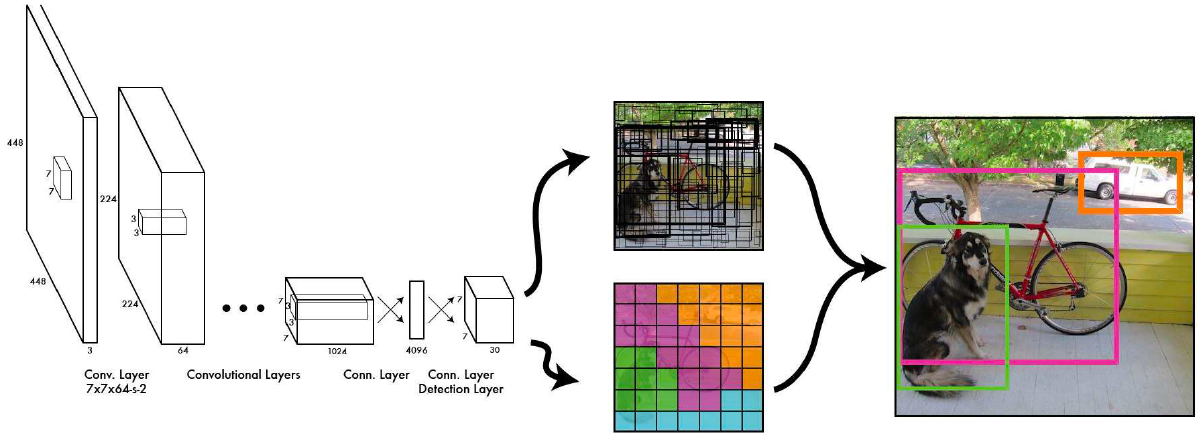
(source: original paper of YOLO V1)
Why YOLO? (YOLO vs. Other Algorithms)
YOLO Is a single-stage algorithm consisting of 24 CNN layers followed by two fully connected layers. This means that prediction in the entire frame is made in a single algorithm run. The CNN is used to predict various class probabilities and bounding boxes simultaneously. It answers the WHATs and WHEREs of the objects faster than other object detection algorithms like RCNN, Fast RCNN, masks RCNN, etc., which are two-stage Algorithms (detection and classification). This single Iteration of an end-to-end Object Detection makes predictions of bounding boxes and class probabilities simultaneously. Thus, increasing the accuracy of the result.
If we look at the multi-stage R-CNN model, It utilizes the Selective search to extract numerous sections in a frame called regions(~2000 regions). These are the Yellow Boxes that we can see in the below image. Next, for every region proposal, we use the CNN network, which is trained for picture classification to create feature vectors. Finally, We classify each region by passing the feature vectors and using a linear SVM model for each category.
Each region proposal is fed independently to the CNN for feature extraction. This makes it impossible to run R-CNN in real-time.
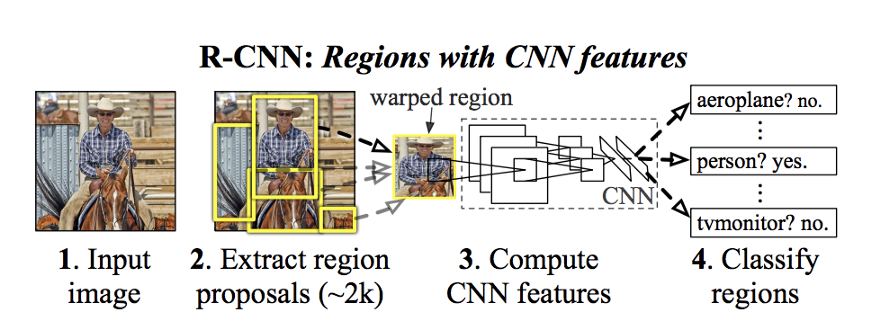
(source: https://arxiv.org/pdf/1311.2524.pdf)
The Faster R-CNN model uses Region Proposal Network(RPN) for generating region proposals. Then the fast R-CNN model works on it to detect the objects in the regions. This is much faster than R-CNN, but YOLO beats them all with its single iteration algorithm. Below is the comparison between R-CNN and YOLO algorithms.

(source: IEEE 2020 Conference)
What makes YOLO this fast?
YOLO in its single iteration over the frame, follows 3 steps to identify and classify the objects.

(source: YOLO’s first paper )
1. Residual boxes: The image/frame is divided into grids of fixed dimensions, say n*n. Every cell tries to detect objects within them. We can see in the above image how the residual boxes are generated.
2. Bounding box regression: It is an outline that highlights an object in an image. Its attributes are Height, width, class(of the object), and box center(bx, by). The bounding boxes are highlighted by yellow color in the second step of the image above.
3. Intersection over union: It describes how boxes overlap. The IOU equals 1 if the predicted bounding box is the same as the real box. This mechanism eliminates bounding boxes that are not equal to the real box. IOU is calculated as the ratio of ‘area of overlap’ to ‘area of the union’. Finally, by Non-Maximal Suppression, YOLO suppresses all bounding boxes with lower probability scores to achieve final bounding boxes.
YOLO Architecture

It consists of three parts :
-
Backbone: Yolov5 incorporated cross stage partial network (CSPNet) into Darknet, creating CSPDarknet as its backbone, which is used to extract key features from an image. CSPDarknet employs DarkNet for object detection. The base layer’s feature map is divided into two parts using a CSPNet technique, and these two parts are then combined using a cross-stage hierarchy.
-
Neck: Yolov5 applies a path aggregation network (PANet) as its neck, which is used to create a feature pyramid network. FPN produces proportionally scaled feature maps at several levels in a completely convolutional manner from a single-scale image of any size. The underlying convolutional designs have no bearing on this procedure. This helps the model to identify the same object in various sizes and scales.
-
Head: The head of Yolov5, namely the Yolo layer, is responsible for the final detection step i.e. It performs dense prediction. It uses anchor boxes to construct the final output vector with class, confident scores, and bounding boxes.
YOLO implementation

We implemented YOLO v5 on 2 datasets: COCO(81 classes) and Object365(365 classes), on a video, and below is the output snap of one frame. We can see the bounding boxes labelled with the class name and probability score as output. Here’s the official guide for the implementation of Object Detection.

Conclusion
YOLO family has been the supreme leader in Object Detection and Classification Algorithms since its inception. Although YOLO offers high computational speed and takes less time than other Object detector models, It lags to Faster R-CNN in terms of Accuracy.
- This article showed the difference between object detection and object classification.
- We learned about YOLO and how it is better than other algorithms.
- We then saw about the working of YOLO and its architecture.
YOLO can be a perfect application for implementing self-driving cars, parking assist technology, and providing strong home security solutions.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
🎓 I'm a Final-year Undergrad pursuing my BTech in Computer Science from MIT Academy Of Engineering, Pune. As a curious learner, I am also working on my honors in Data Science to expand my expertise in this domain.




