Data is the new oil; however, unlike any other precious commodity, it is not scanty. On the contrary, due to the advent of digital technologies, and social media, the abundance of data is a matter of concern for data scientists. Any machine learning algorithm needs preprocessed data set for better performance. Data preprocessing involves cleaning, transformation, and reduction of the data set. It is the first step of any data mining project; however, we often consider it implicit and neglect its importance. This article describes ten frequently encountered issues under data preprocessing so that every reader can have a simple checklist of issues and corresponding solutions before embarking on their next project.
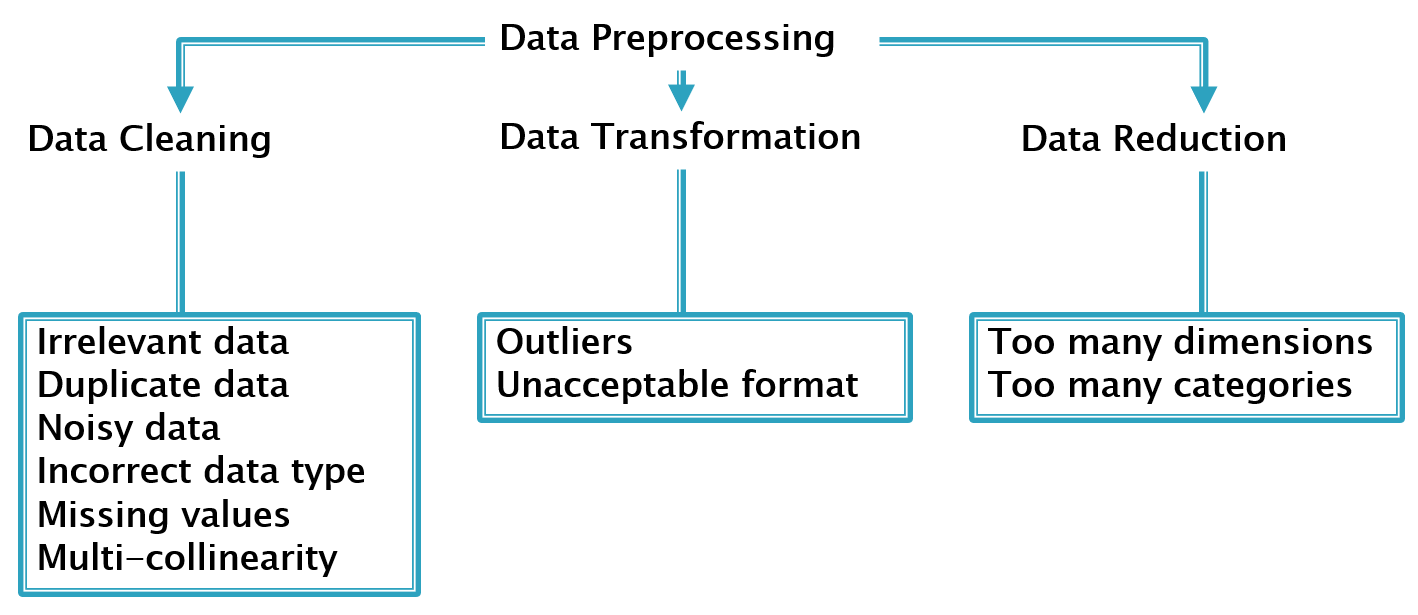
Although big data leading to beautiful insights is a buzzword, data collected from the source is seldom in the desired format. Refining the raw data is a tedious task that data scientists have to perform. Data preprocessing to extract quality data may seem painful; however, it is a necessary evil. This article discusses a sound approach to data cleaning, transformation, and reduction steps to obtain accurate results. To apply these steps, we assume the raw data is collated from its source in a file and consolidated in a structured manner, with each row representing a record and column representing an attribute. Data preprocessing can be viewed as a sequence of three tasks, as shown in the following figure.
Figure 1. Tasks under data preprocessing
The basics of Data Preprocessing- Understanding the Data Requirements
The first task in data preprocessing should start with understanding the data requirements of a data mining project. Data is classified under many types, the two main classifications being categorical and numerical. The numerical data type can be further divided into integer and continuous. Similarly, categorical data is sub-divided under unordered, ordered, and binary, to name a few. Different algorithms require different data types, so the treatment applied for each type is not the same. Thus, our first task would involve understanding why we need the data. Keeping the end objective in mind, we will have one or more sets of target algorithms in mind that we want to apply to the relevant data.
Different machine learning algorithms have different requirements regarding the type and structure of data that is accepted as input. Under predictive analytics, the algorithms are classified as either supervised or unsupervised machine learning techniques. The algorithm for mining data based on the problem we wish to solve will help us determine what the relevant columns are and whether these columns are in the correct format. For example, algorithms implementing linear regression under supervised learning accept numerical data; hence, any categorical variable included in the model must be converted into numerical dummy variables. In another case, it is a standard practice to bring the numerical data under different columns to a scale between 0 to 1 before applying an algorithm implementing clustering under unsupervised learning.
Exploring the Data, Identifying the Issue at Hand in Data Preprocessing
Once the objective and possible set of algorithms to apply is apparent in our mind, we should proceed towards exploring the data set. At this stage, we focus on the metadata and perform descriptive statistics of the data-set to identify the type of each column, its statistical distribution, missing values, and so on. The data consolidated from its source can have the following issues.
1. Irrelevant data
The most basic yet unavoidable issue that requires data cleaning is the presence of attributes in the data set that are irrelevant to the problem we are trying to solve. For example, in a problem where we want to predict the price of a house, the owner’s contact number does not seem to be a relevant attribute.
2. Duplicate data
Integrating data from different sources may result in redundant columns and rows in the data set.
3. Noisy data
Errors in measurement, entry, and data transmission may lead to invalid, inconsistent, and out-of-range values. For example, a column representing gender may have an unknown coding ‘S’, and a column to store a date in ‘dd-mm-yy’ format may have an entry ‘11-30-2021’. Another example of noise for categorical data is caused due to the use of the upper and lower case to store data in a specific column. Similarly, for numerical data, using a different measurement scale, such as kilogram and pound for a specific column, may lead to noisy data.
4. Incorrect data type
A data-set would generally store different types of data such as integer, float, and string. However, the type in which a data column is stored may be wrong. For example, a numerical attribute like the price of a house may be stored as a string.
5. Missing values
It is seldom a case where values are not missing in a data set. It may occur due to unavailability of the particular instance of data and error in recording, leading to noisy data and consequent labeling as a missing value.
6. Multi-collinearity
In a data set, values under different columns can be correlated. Such correlation may be purely accidental, indicative of an underlying relationship, or due to duplication of data in some form or the other.
7. Outliers
Outliers are extreme data points compared to the rest of the data. They can be detected numerically by calculating the data distribution’s inter-quartile range and standard deviation. They can also be visualized using box plots, histograms, and scatter plots.
8. Unacceptable format
The data may be in a format that is not acceptable to the machine learning algorithm to be applied later in the data mining stage.
9. Too many dimensions
The columns in a data set are also known as dimensions, attributes, or features. As human beings, we can visualize data only in up to three dimensions. For machines, although dimensions of more than three are not a major concern, the interpretability of data reduces with higher dimensions. A data set may be characterized by too many dimensions making it harder to cluster data and obtain meaningful patterns.
10. Too many categories
In a categorical variable, there can be many categories. For example, the column storing the name of ‘Locality’, to which a person belongs, can lead to too many categories. This issue can be observed through descriptive statistics like a bar chart showing the frequency of data category-wise. Too many categories can lead to too many dummy variables while transforming categorical to numerical ones.
These issues can be addressed under the three steps of data preprocessing, as shown in the following figure.
Figure 2. Frequently encountered issues addressed under the three steps of data preprocessing
Addressing the Issue with a Solution in Data Preprocessing
The possible approaches to address the issues mentioned in the above section are discussed here.
1. Irrelevant data
Irrelevant attributes in the data-set need to be discarded before proceeding to further data preprocessing, and a mere inspection is often sufficient to filter what is relevant. However, there might be instances where we need to take the help of a subject matter expert to determine whether a specific attribute is relevant or not.
2. Duplicate data
Due to data replication, duplicate rows and columns would hamper the analysis process. It should be detected and removed at the onset of the data cleaning process. In case of a data value conflict for redundant data, the original data source can be checked to resolve the problem and perform data integration.
3. Noisy data
Treatment of noisy data will depend on the type of noise introduced. Although a mere inspection would reveal whether the value is invalid or out of range, its treatment in a large data-set will require an automated filtering mechanism. For example, a person’s age cannot be 200 or non-numeric. Such values can be summarily rejected. Another instance of noisy data in the case of categorical variables may be due to inconsistent entries in free text fields caused by spelling mistakes and multiple spellings. For example, in a column storing ‘Country’, the same country India can be stored as IND, Bharat, and so on. In such an instance, it is necessary to standardize the categories and correct the error in format or value. If an error cannot be corrected, the entry can be marked as missing instead of discarding the entire record.
4. Incorrect data type
Data stored using incorrect type can hinder its analysis and must be converted to its correct type before applying data mining algorithms. For example, the years of experience of a person stored as a string cannot be used to predict the salary using linear regression, which accepts numerical data as input.
5. Missing values
Machine learning algorithms cannot handle missing values as input, and there are three approaches to treating missing values in a data-set. The most straightforward approach is dropping the rows or columns with missing values; however, dropping too many observations may not be feasible. The second approach involves imputation, replacing the missing values with relevant statistical measures. For example, in the case of numerical data, the missing values can be filled in by mean and median, and in the case of categorical data, the mode can be used. However, deciding the appropriate value to replace a missing value is controversial since there is no way to ascertain whether the filled-in value is truly representative. On the other hand, missing values in a particular row or column can have a pattern and convey important information. The third approach to treating missing values aims to capture this information by replacing the missing data with a default value or adding an indicator variable to flag where values are missing.
6. Multi-collinearity
While the presence of correlation in a data-set can be valuable information, there are certain situations, such as applying a linear regression model in which we want to avoid multi-collinearity. Highly correlated features can be discarded, keeping the most relevant features in the model to avoid correlated predictor variables.
7. Outliers
The presence of outliers may have a disproportionate influence on data mining models. They can be retained or removed in the data cleaning stage depending on the context of the problem, based on subject matter expertise. In case of retention of outliers, tree-based and boosting machine learning algorithms can be used to achieve the end objective since they are not sensitive to outliers. Another approach to treating outliers is known as ‘winsorizing’. It involves the replacement of outliers above and below a threshold by the nearest threshold values.
8. Unacceptable format
As discussed earlier under task 1, the algorithm to be applied in the data mining stage may expect the data to be in a specific format. Depending upon the case, it requires data transformation and may involve creating dummy variables, scaling, normalization, and dimension reduction. Scaling involves transforming the data to a specific scale, for example, 0 to 1. It may be important to bring all the numerical attributes to the same scale while applying a specific data mining algorithm since the presence of attributes with a larger magnitude may dominate the result. Scaling can be performed using different methods like min-max and standard scaler. Normalization is another way of data transformation in which the data-set is converted into a normal distribution. Tukey’s ladder of powers can be used to remove skewness in numerical data. Algorithms such as those implementing support vector machines perform better on normalized data.
9. Too many dimensions
The first step to dealing with too many dimensions in a data-set would involve the removal of irrelevant dimensions through inspection. Next, analysis based on collinearity and advanced methods like principal component analysis is employed to reduce the dimensions.
10. Too many categories
A single categorical variable with ‘n’ categories will be transformed into ‘n-1’ dummy variables. For example, a variable storing twenty categories will lead to nineteen dummy variables making the dimension of a data-set with multiple such categorical variables unmanageable after transformation. The categories close to each other can be combined to solve this issue.
Another problem that may occur with too many categories is the presence of value corresponding to a few categories dominating the data resulting in a skewed distribution. The data corresponding to categories with insignificant frequency can be combined under a single category like ‘Others’.
Once the data set is preprocessed and ready for the next stage, it should be saved in the desired format. It is always prudent to keep a backup of data for future reference at each stage of a data mining project
Conclusion
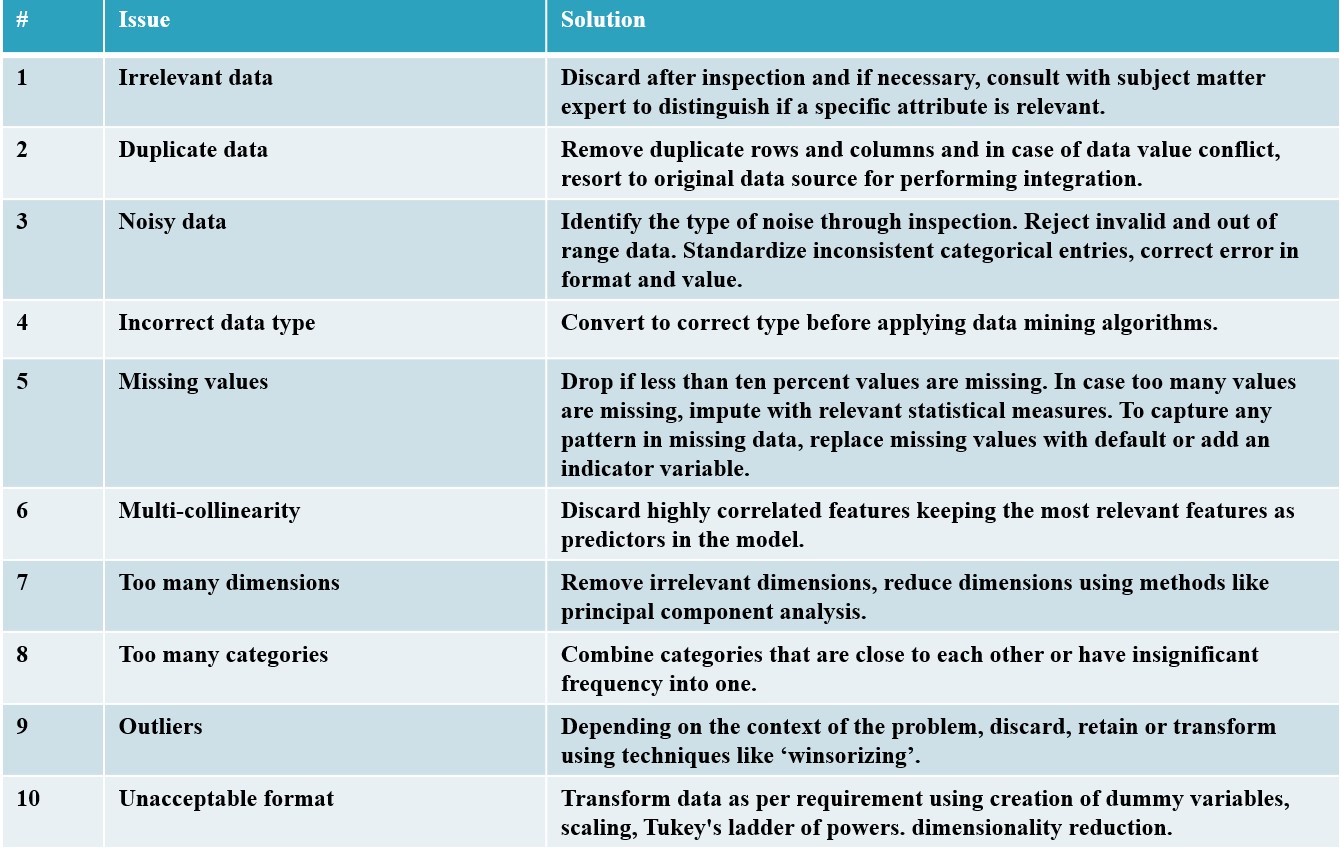
Today data science is not just a science but also an art of investigating tons of data with subject matter expertise. It is not enough to be good at statistics to excel in data science since applying advanced machine learning algorithms to incorrect data will lead to incorrect results. This article attempts to remind the reader that data is not useful unless cleaned, transformed, and reduced to the extent that it can be processed meaningfully by the advanced machine learning algorithms available. The following figure presents a summary of the issues and corresponding solutions discussed in this article.
Figure 3. Checklist of issues and corresponding solutions addressed under data preprocessing
Although this article is not exhaustive, the aim behind writing it will be fulfilled if it rescues the reader from the overload of information on this topic. We hope it saves their time by presenting a crisp overview of the data preprocessing needs, issues of a data mining project, and the solutions at hand.
Are you overwhelmed by data preprocessing? Our course “How to Preprocess Data” will guide you through the essential steps of cleaning, transforming, and reducing data for meaningful analysis, ensuring you can apply advanced machine learning algorithms effectively. Enroll now to master the art and science of data preprocessing and elevate your data science projects
Key takeaways
Remember that most of your time in a data mining project is spent in data preprocessing. Once your data is cleaned and in a format acceptable to the machine learning algorithms, the next steps are relatively less tedious.
Every project and its requirements are unique; however, the issues and solutions discussed in this article are general guidelines and can be referenced as a checklist.
Read the literature on data preprocessing but do not get lost. Focus on understanding the issues and addressing them depending upon the context.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
We use cookies essential for this site to function well. Please click to help us improve its usefulness with additional cookies. Learn about our use of cookies in our Privacy Policy & Cookies Policy.
Show details
Powered By
Cookies
This site uses cookies to ensure that you get the best experience possible. To learn more about how we use cookies, please refer to our Privacy Policy & Cookies Policy.
brahmaid
It is needed for personalizing the website.
csrftoken
This cookie is used to prevent Cross-site request forgery (often abbreviated as CSRF) attacks of the website
Identityid
Preserves the login/logout state of users across the whole site.
sessionid
Preserves users' states across page requests.
g_state
Google One-Tap login adds this g_state cookie to set the user status on how they interact with the One-Tap modal.
MUID
Used by Microsoft Clarity, to store and track visits across websites.
_clck
Used by Microsoft Clarity, Persists the Clarity User ID and preferences, unique to that site, on the browser. This ensures that behavior in subsequent visits to the same site will be attributed to the same user ID.
_clsk
Used by Microsoft Clarity, Connects multiple page views by a user into a single Clarity session recording.
SRM_I
Collects user data is specifically adapted to the user or device. The user can also be followed outside of the loaded website, creating a picture of the visitor's behavior.
SM
Use to measure the use of the website for internal analytics
CLID
The cookie is set by embedded Microsoft Clarity scripts. The purpose of this cookie is for heatmap and session recording.
SRM_B
Collected user data is specifically adapted to the user or device. The user can also be followed outside of the loaded website, creating a picture of the visitor's behavior.
_gid
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the website is doing. The data collected includes the number of visitors, the source where they have come from, and the pages visited in an anonymous form.
_ga_#
Used by Google Analytics, to store and count pageviews.
_gat_#
Used by Google Analytics to collect data on the number of times a user has visited the website as well as dates for the first and most recent visit.
collect
Used to send data to Google Analytics about the visitor's device and behavior. Tracks the visitor across devices and marketing channels.
AEC
cookies ensure that requests within a browsing session are made by the user, and not by other sites.
G_ENABLED_IDPS
use the cookie when customers want to make a referral from their gmail contacts; it helps auth the gmail account.
test_cookie
This cookie is set by DoubleClick (which is owned by Google) to determine if the website visitor's browser supports cookies.
_we_us
this is used to send push notification using webengage.
WebKlipperAuth
used by webenage to track auth of webenagage.
ln_or
Linkedin sets this cookie to registers statistical data on users' behavior on the website for internal analytics.
JSESSIONID
Use to maintain an anonymous user session by the server.
li_rm
Used as part of the LinkedIn Remember Me feature and is set when a user clicks Remember Me on the device to make it easier for him or her to sign in to that device.
AnalyticsSyncHistory
Used to store information about the time a sync with the lms_analytics cookie took place for users in the Designated Countries.
lms_analytics
Used to store information about the time a sync with the AnalyticsSyncHistory cookie took place for users in the Designated Countries.
liap
Cookie used for Sign-in with Linkedin and/or to allow for the Linkedin follow feature.
visit
allow for the Linkedin follow feature.
li_at
often used to identify you, including your name, interests, and previous activity.
s_plt
Tracks the time that the previous page took to load
lang
Used to remember a user's language setting to ensure LinkedIn.com displays in the language selected by the user in their settings
s_tp
Tracks percent of page viewed
AMCV_14215E3D5995C57C0A495C55%40AdobeOrg
Indicates the start of a session for Adobe Experience Cloud
s_pltp
Provides page name value (URL) for use by Adobe Analytics
s_tslv
Used to retain and fetch time since last visit in Adobe Analytics
li_theme
Remembers a user's display preference/theme setting
li_theme_set
Remembers which users have updated their display / theme preferences
We do not use cookies of this type.
_gcl_au
Used by Google Adsense, to store and track conversions.
SID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
SAPISID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
__Secure-#
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
APISID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
SSID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
HSID
Save certain preferences, for example the number of search results per page or activation of the SafeSearch Filter. Adjusts the ads that appear in Google Search.
DV
These cookies are used for the purpose of targeted advertising.
NID
These cookies are used for the purpose of targeted advertising.
1P_JAR
These cookies are used to gather website statistics, and track conversion rates.
OTZ
Aggregate analysis of website visitors
_fbp
This cookie is set by Facebook to deliver advertisements when they are on Facebook or a digital platform powered by Facebook advertising after visiting this website.
fr
Contains a unique browser and user ID, used for targeted advertising.
bscookie
Used by LinkedIn to track the use of embedded services.
lidc
Used by LinkedIn for tracking the use of embedded services.
bcookie
Used by LinkedIn to track the use of embedded services.
aam_uuid
Use these cookies to assign a unique ID when users visit a website.
UserMatchHistory
These cookies are set by LinkedIn for advertising purposes, including: tracking visitors so that more relevant ads can be presented, allowing users to use the 'Apply with LinkedIn' or the 'Sign-in with LinkedIn' functions, collecting information about how visitors use the site, etc.
li_sugr
Used to make a probabilistic match of a user's identity outside the Designated Countries
MR
Used to collect information for analytics purposes.
ANONCHK
Used to store session ID for a users session to ensure that clicks from adverts on the Bing search engine are verified for reporting purposes and for personalisation
We do not use cookies of this type.
Cookie declaration last updated on 24/03/2023 by Analytics Vidhya.
Cookies are small text files that can be used by websites to make a user's experience more efficient. The law states that we can store cookies on your device if they are strictly necessary for the operation of this site. For all other types of cookies, we need your permission. This site uses different types of cookies. Some cookies are placed by third-party services that appear on our pages. Learn more about who we are, how you can contact us, and how we process personal data in our Privacy Policy.