This article was published as a part of the Data Science Blogathon.
Introduction
Image caption generator is the most fascinating application I found while working with NLP. It’s cool to train your system to label the images you feed to it. As interesting as it sounds, it is equally challenging to implement this application. It is a bit harder than object detection and image classification, which have been well researched. The task while building this application is not only to capture the objects contained in that image but also to have a semantic meaning of the captions generated. Initially, it was very hard to implement such types of applications, but with the improvement of computer vision and deep learning algorithms, availability of datasets it becomes easier to build image caption generators.
In this article, we will build one such application where our computer generates relevant captions for the images with the help of a large volume of datasets available. In this blog, we will particularly use one such dataset available on kaggle.com: the “Flickr8k dataset”.
Before you start reading this blog make sure you have some idea about how we process images and texts, LSTM (Long-Short term memory), and CNNs (Convolutional neural networks). You can check out my analytics profile if you want to read about these topics. Let’s start building our application without wasting our time.
Understanding the Data
The dataset we have contains about 8000 images each of which is annotated with 5 captions that provide a description of entities in the image. We have 6000 images for training, 1000 for validation, and 1000 for testing. The dataset differs in various aspects such as the number of images, number of captions, the format of the captions, and the image size.
The dataset will have the following files after you download it: –
- Flick8k/
- Flick8k_Dataset/: –
contains all the 8000 images we have
- Flick8k_Dataset/: –
· Flick8k_Text/
-
-
- Flickr8k.token.txt: – It
has the image id along with the 5 captions for that particular image. - Flickr8k.trainImages.txt:
– The image ids of the train images. - Flickr8k.testImages.txt:
– The image ids of the test images
- Flickr8k.token.txt: – It
-
Model Architecture
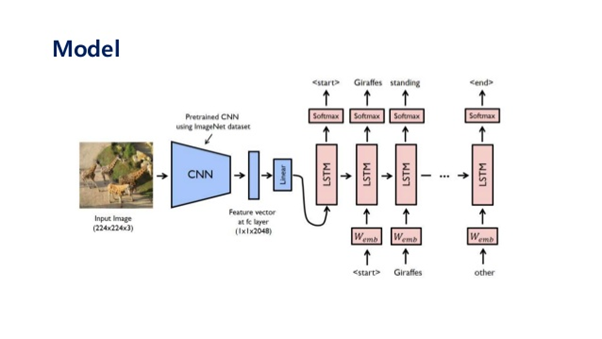
Source: https://stats.stackexchange.com/questions/387596/image-caption-generator
If you look at this carefully, you will see there are two models, one is the image-based model, and the other is a language-based model. We will use CNNs to extract the image features and then LSTM to translate the features and objects given by CNN into a natural sentence. We will use CNN as an encoder and LSTM as a decoder.
To encode our images, we will use transfer learning. We will use VGG-16 for the extraction of image features. You can use many more models like InceptionV3, ResNet, etc.
Building the Image Caption Generator
We will use Google collab and the TensorFlow library to build this application.
Importing Necessary Libraries
#Import Necessary Libraries from os import listdir from pickle import dump from keras.applications.vgg16 import VGG16 from keras.preprocessing.image import load_img from keras.preprocessing.image import img_to_array from keras.applications.vgg16 import preprocess_input from keras.models import Model from pickle import load from numpy import array import tensorflow from pickle import load from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences from tensorflow.keras.utils import to_categorical from keras.utils.vis_utils import plot_model from keras.models import Model from keras.layers import Input from keras.layers import Dense from keras.layers import Embedding from keras.layers import Dropout from keras.layers.merge import add from keras.callbacks import ModelCheckpoint import re import string
Extracting features from the Images
def extract_features(directory):
VGG_model = VGG16()
VGG_model = Model(inputs= VGG_model.inputs, outputs=VGG_model.layers[-2].output)
print(VGG_model.summary())
attribute = dict()
for i in listdir(directory):
file_name = directory + '/' + i
image = load_img(file_name, target_size=(224, 224))
image = img_to_array(image)
image = image.reshape((1, 224, 224, 3))
image = preprocess_input(image)
attributes = VGG_model.predict(image)
image_id = file.split('.')[0]
attribute[image_id] = attributes
return attribute
directory = '/content/gdrive/MyDrive/image_caption/Flicker8k_Dataset'
features = extract_features(directory)
print('Extracted Features: %d' % len(attribute))
dump(attribute, open('features.pkl', 'wb'))
In the above code, we are reconstructing the VGG-16 model. By popping off the last layer. This model is generally used to classify the images, but in this task, we don’t want to classify any image so we will be removing the last layer because we are more interested in the internal representation of the images.
After popping off the last layer, we use a for loop to go through every image in the dataset. We have also initialized an empty dictionary in which we will save our extracted features of the image. Since we can not send the image directly to our model, we will have to reshape it according to the preferred size of the model. So, we have used reshape function to reshape the image and then saved the features of the images in the dictionary.
Loading the text data
# load doc into memory def load_doc(file_name): file = open(file_name, 'r') caption = file.read() file.close() return caption
# extract captions for images
def load_descriptions(document):
map = dict()
# process lines
for line in document.split('n'):
tokens = line.split()
if len(line) < 2:
continue
image_id, image_description = tokens[0], tokens[1:]
# removing filename from image id
image_id = image_id.split('.')[0]
# converting the description tokens back to string
image_description = ' '.join(image_description)
# create the list if needed
if image_id not in map:
map[image_id] = list()
# store description
map[image_id].append(image_description)
return map
Here we are making a function to load the text data. This function will be used to load Flickr8k.token.txt which contains descriptions for all the images. This file contains unique image ids with their respective descriptions.
Next, we are creating a function that will extract the descriptions of all the images using a for a loop. Each of the image identifiers maps to one or more text-based descriptions. So, what this function will do is it will create a dictionary and will put all the captions in a list with the particular image id.
By using the for loop, we are reading each sentence from the document by splitting them based on a new line character called ‘n’. Then we make tokens of the descriptions by splitting them based on white spaces.

After this, we are checking if any image id has no caption, if the length of the description is less than 2, then I don’t want my loop to break, I’ll continue looping over all the sentences. You can use some other threshold if you want. I analyzed the data a bit and then decided to make the threshold 2.
Next, I am storing the image descriptions for corresponding images id’s. ‘token [0]’ has the image id, and after 0 elements in token, we have all the words in it, as you can see from the fig above, so for image descriptions we use ‘token[1:]’. I am then storing the unique image id which means removing the ‘jpg#’ part from the image id by splitting it on ‘.’ and storing the 0th element in a list. The image_id will look like this:

After this, I am joining back all the tokens to the text string using the ‘join’ function and save it in a dictionary
Cleaning the text data
def clean_descriptions(desc):
table = str.maketrans('', '', string.punctuation)
for key, desc_list in desc.items():
for i in range(len(desc_list)):
description = desc_list[i]
# tokenize
description = description.split()
# converting the text to lower case
description = [term.lower() for term in description]
# removing the punctuation from each token
description = [w.translate(table) for w in description]
# removing the hanging 's' and 'a'
description = [term for term in description if len(term)>1]
# removing the tokens with numbers in them
description = [termfor term in description if term.isalpha()]
# storing it as astring
desc_list[i] = ' '.join(description)
This function is self-explanatory and is very easy to understand. We are looping over all the descriptions, tokenizing them, looping on all the words by using list comprehension, and then cleaning them one by one. After executing this function, you will see the descriptions like:
def to_vocabulary(desc):
all_desc = set()
for key in desc.keys():
[all_desc.update(d.split()) for d in desc[key]]
return all_desc
Now we are creating a function called ‘to_vocabulary’ which will transform the descriptions into a set so that we can get an idea of the size of our dataset vocabulary. It takes descriptions as the argument, then for each key, we are picking up the corresponding description such that all the words in that description are first split on the basis of white spaces and then those words are added to a set called ‘all_desc’. You will get a dictionary with all the unique words in the dataset.

After this, we will save the descriptions using this function called ‘save_descriptions’.
def save_descriptions(desc, file_name):
lines = list()
for key, desc_list in desc.items():
for description in desc_list:
lines.append(key + ' ' + description)
data = 'n'.join(lines)
file = open(file_name, 'w')
file.write(data)
file.close()
Now let’s use all these functions in our ‘Flickr8k.token.txt’ file:
filename = '/content/gdrive/MyDrive/image_caption/Flickr8k.token.txt'
# load descriptions
doc = load_doc(filename)
# parse descriptions
descriptions = load_descriptions(doc)
print('Loaded: %d ' % len(descriptions))
# clean descriptions
clean_descriptions(descriptions)
# summarize vocabulary
vocabulary = to_vocabulary(descriptions)
print('Vocabulary Size: %d' % len(vocabulary))
# save to file
save_descriptions(descriptions, 'descriptions.txt')
Now
let’s start working on our train dataset. The functions we define here will be
similar to that we have already defined. Go through the code and you’ll easily
get to know what we are trying to do.
# load doc into memory def load_doc(file_name): file = open(file_name, 'r') text = file.read() file.close() return text
def load_set(file_name):
document = load_doc(file_name)
data_set = list()
# process line by line
for line in document.split('n'):
# skip empty lines
if len(line) < 1:
continue
# get the image identifier
identifier = line.split('.')[0]
data_set.append(identifier)
return set(data_set)
# load clean descriptions into memory
def load_clean_descriptions(file_name, data_set):
# load document
doc = load_doc(file_name)
desc = dict()
for line in doc.split('n'):
# split line by white space
tokens = line.split()
# split id from description
image_id, image_desc = tokens[0], tokens[1:]
if image_id in data_set:
# create list
if image_id not in descriptions:
desc[image_id] = list()
# wrap desc in tokens
description = 'startseq ' + ' '.join(image_desc) + ' endseq'
# store
desc[image_id].append(description)
return desc
The first function is the same as we have defined before to read the ‘Flickr8k.trainimages.txt’. After that, we define a function to load all the image ids in the training dataset and then return a complete list having only a single instance of each identifier, the set function is used to remove the duplicates.
The next function we see is the load clean description which is used to load the clean text descriptions for a given set of identifiers, thereby returning a dictionary of identifiers and the corresponding list of text descriptions. If you remember, we made a function named ‘save_description’ which saved all the clean text or descriptions in a file named “’descriptions.txt”, so we will use that cleaned file to load the clean descriptions. After separating the image_id and image_desc, we are initializing an if statement which skips all the images which are not present in the training dataset.
We then add ‘startseq’ at the start of all the descriptions and ‘endseq’ at the end of all the descriptions. We do this because we need the first word to start the process of image captioning and the last word to signal the end of the caption.
# load photo features
def load_photo_features(file_name, data_set):
# load all features
all_features = load(open(file_name, 'rb'))
# filter features
features = {k: all_features[k] for k in data_set}
return features
Now we make a function that loads the features of the train images. Hence it takes 2 arguments, the 1st is the file name in which we have saved image features of all the images, and the 2nd argument is the dataset which will be the training dataset here.
Encoding the Text Data
def to_lines(desc):
all_description = list()
for key in desc.keys():
[all_description.append(d) for d in desc[key]]
return all_description
def create_tokenizer(desc): lines = to_lines(desc) tokenizer = Tokenizer() tokenizer.fit_on_texts(lines) return tokenizer
def max_length(desc): lines = to_lines(desc) return max(len(d.split()) for d in lines)
Since our model can not understand strings, we need to convert all our descriptions into numbers so that our model can understand this data. The function ‘to_lines’ is used to convert the dictionary of clean descriptions into a list of descriptions, basically creating individual lines of descriptions and storing them in a list. In the next function, we use the ‘to_lines’ function to convert the dictionary to a list. We then define a tokenizer object using the Tokenizer() class and use the ‘fit_on_texts’ method to create individual tokens from the given descriptions.
‘max_length’ function is used to calculate the descriptions with the most words. It will loop over all the descriptions and then split them on the basis of white spaces and then calculate the description length using ‘len’ function and return the maximum length of the description in our dataset. You will see that this function will be used for padding later on.
filename = '/content/gdrive/MyDrive/image_caption/Flickr_8k.trainImages.txt'
train = load_set(filename)
print('Dataset: %d' % len(train))
# descriptions
train_descriptions = load_clean_descriptions('/content/gdrive/MyDrive/image_caption/descriptions.txt', train)
print('Descriptions: train=%d' % len(train_descriptions))
# photo features
train_features = load_photo_features('/content/gdrive/MyDrive/image_caption/features.pkl', train)
print('Photos: train=%d' % len(train_features))
# prepare tokenizer
tokenizer = create_tokenizer(train_descriptions)
vocab_size = len(tokenizer.word_index) + 1
print('Vocabulary Size: %d' % vocab_size)
# determine the maximum sequence length
max_length = max_length(train_descriptions)
print('Description Length: %d' % max_length)
We are now ready to encode the text. Please note that each description will be split into words and the model will actually generate the next word by providing one word and an image feature as input. Let’s understand this in an easier way:
Let’s say we have an image, and its caption is
‘The man is driving his car”. This sequence would be split into 7 input-output
pairs to train the model.
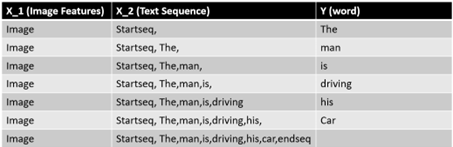
If you see the figure above, we are providing two inputs to our model. 1st is the image features and 2nd is the encoded text. The output is the next word in the sequence. Now the first word of the description will be provided to the model as an input along with the image to generate the next word. Just like the word ‘man’ is generated and subsequently ‘is’ and ‘driving’ is generated. The generated words will be combined and recursively provided as input to generate a caption for an image.
# create sequences of images, input sequences and output words for an image def create_sequences(tokenizer, max_length, desc_list, photo): x_1 = []
x_2 = []
y = []
for description in desc_list:
# encode the sequence
sequence = tokenizer.texts_to_sequences([description])[0]
# spliting one sequence into multiple x and y pairs
for i in range(1, len(sequence)):
# split into input and output pair
input_seq, output_seq = sequence[:i], sequence[i]
# pad input sequence
in_seq = pad_sequences([input_seq], maxlen=max_length)[0]
# encode output sequence
out_seq = to_categorical([output_seq], num_classes=vocab_size)[0]
# store
x_1.append(photo)
x_2.append(input_seq)
y.append(output_seq)
return array(x_1), array(x_2), array(y)
#Below code is used to progressively load the batch of data
# data generator, will be used in model.fit_generator()
def data_generator(desc, photos, tokenizer, max_length):
# loop for ever over images
while 1:
for key, desc_list in desc.items():
# retrieving the photo features
photo = photos[key][0]
input_img, input_seq, output_word = create_sequences(tokenizer, max_length, description_list, photo)
yield [[input_img, input_seq], output_word]
These two functions are a bit complex, but let’s try understanding them. We already know how we need our sequence to be. So before making a sequence, we first need to encode it. We will use this ‘create_sequences’ function in another function called ‘data_generator.’ If you look carefully, we are looping over all the descriptions one by one. The first loop is initiated in the data generator function, which gives a list of all the descriptions of a particular image. If you run:
for key, desc_list in descriptions.items(): print(desc_list)
The output will be:

A description is a dictionary that contains all the clean captions and the image ids. The second loop is initiated in the ‘create_sequences’ function, looping over all the descriptions.
for key, desc_list in descriptions.items(): #1st loop)
for desc in desc_list: #(2nd loop)
print(desc)
The output will be:

Look at the create_sequences function; we are initializing some empty lists and looping over all the captions. Then we use the ‘text_to_sequences’ method to encode the caption. The output of
for desc in desc_list:
# encode the sequence
seq = tokenizer.texts_to_sequences([desc])[0]
will be somewhat like this:
All your captions will be encoded in numbers. If you don’t know how ‘texts_to_sequences’ works, I would strongly recommend going through this link.
Now, after encoding, we are starting another for loop, which will help us in making the input and output sequence.
for key, desc_list in descriptions.items():
for desc in desc_list:
seq = tokenizer.texts_to_sequences([desc])[0]
print(seq)
for i in range(1, len(seq)):
in_seq, out_seq = seq[:i], seq[i]
print(in_seq,out_seq)
the output of this will be:
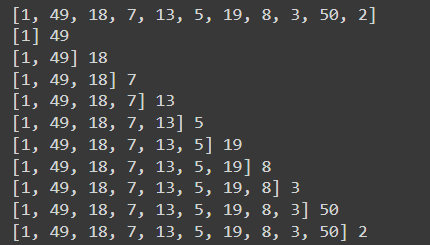
This is how we create our sequences; the output is recursively provided as an input to generate a caption for an image. Once we create the sequences, we will use the pad_sequences method to pad the input sequences. To read more about this method, click on this link.
Then we are using the to_categorical method to one hot encode the output. You can read more about this method on this link.
Model Building
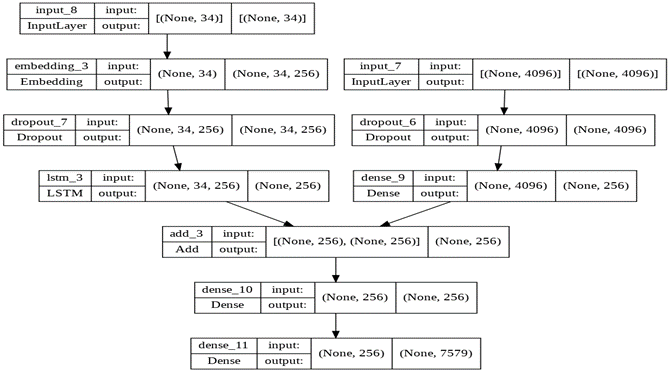
# define the captioning model from keras.layers import LSTM def define_model(vocab_size, max_length): # feature extractor model inputs_1 = Input(shape=(4096,)) fe_1 = Dropout(0.5)(inputs_1) fe_2 = Dense(256, activation='relu')(fe_1) # sequence model inputs_2 = Input(shape=(max_length,)) se_1 = Embedding(vocab_size, 256, mask_zero=True)(inputs2) se_2 = Dropout(0.5)(se_1) se_3 = LSTM(256)(se_2) # decoder model decoder_1 = add([fe_2, se_3]) decoder_2 = Dense(256, activation='relu')(decoder_1) outputs = Dense(vocab_size, activation='softmax')(decoder_2) # tie it together [image, sequence] [word] model = Model(inputs=[inputs1, inputs2], outputs=outputs) model.compile(loss='categorical_crossentropy', optimizer='adam') # summarize model print(model.summary()) return model
We will combine 2 encoder models (feature extractor model and sequence model) and then feed them to the decoder model. The feature extractor model is built to take input in the form of a vector containing 4096 elements. We are using the Input class of keras.layers to do this. Hence this model expects the input image feature to be a vector of 4096 elements. Then we are using a dropout layer for regularization, which is usually used to reduce the overfitting of the training dataset. Then we are using a dense layer to process 4096 elements of the input layer, producing a 256-element representation of an image.
The sequence model takes input sentences or descriptions to be fed to the embedding layer. The input sequences are of length 34 words, and the parameter mask_true is set as true to ignore the padded values. Then we are using a dropout layer to reduce overfitting. After this, we will use an LSTM layer having 256 memory units to process these text descriptions of the sentences.
Once the encoder model is ready, the decoder model merges the vectors from both the input models by doing an addition operation. Next, we are utilizing a fully connected layer with 256 units.
# train the model
model = define_model(vocab_size, max_length)
epochs = 20
steps = len(train_descriptions)
for i in range(epochs):
# create the data generator
generator = data_generator(train_descriptions, train_features, tokenizer, max_length)
# fit for one epoch
model.fit_generator(generator, epochs=1, steps_per_epoch=steps, verbose=1)
# save model
model.save('model_' + str(i) + '.h5')
In the next cell, we are training our model by saving it after each epoch, so by the end of all the 20 epochs, we will have 20 separate .h5 files in our directory. Since our system doesn’t have enough ram, we will use progressive learning to train our model. You can learn about progressive learning from this link. The model architecture looks something like this:
Predicting the Image Caption
To evaluate our model, we will use BLEU Score, which stands for Bilingual Evaluation Understudy score summarizes how close a particular generated text is to the expected text. It is prevalent in machine translation, but it can be used to evaluate other models such as image captioning, text summarization, speech recognition, etc.
Suppose we have a Spanish sentence: Hoy hace buen tiempo
Which we want to convert into English sentences. Now there can be multiple English translations that are equally appropriate translations of the Spanish sentence. Like
Statement 1 – The weather is nice today,
Statement 2 – The weather is excellent today.
Similarly, in the case of an image captioning problem, we can have several captions for a single image. As we saw in our problem, we have 5 captions for each image. So, the question is, how can we evaluate the associated models with equally good answers?
In classification type of problems where we have to predict if the image is of a dog or cat, here we just have only 1 answer, and we can measure the accuracy there. But what should we do when we have multiple answers? It would be challenging to measure accuracy in that case, so we incorporate BLEU Score in such cases. BLEU Score helps measure how good a particular machine-generated caption is by automatically computing the score. BLEU Score will be high if the predicted caption is close to the actual caption. If there is a complete mismatch, the score would be close to 0. Let’s see how to implement this on google collab.
# map an integer to a word
def word_for_id(integer, tokenizer):
for word, index in tokenizer.word_index.items():
if index == integer:
return word
return None
This function maps a given word using its corresponding word id. This function takes an integer value and tokenizer as an input argument. Inside this function, we are just checking if for a given the word and the corresponding index we have a match or not. If there is a match, return the actual word; otherwise, return NONE.
# generate a description for an image
def generate_desc(model, tokenizer, photo, max_length):
# seed the generation process
in_text = 'startseq'
for i in range(max_length):
# integer encode input sequence
sequence = tokenizer.texts_to_sequences([in_text])[0]
# pad input
sequence = pad_sequences([sequence], maxlen=max_length)
# predict next word
yhat = model.predict([photo,sequence], verbose=0)
# convert probability to integer
yhat = argmax(yhat)
# map integer to word
word = word_for_id(yhat, tokenizer)
if word is None:
break
# append as input for generating the next word
in_text += ' ' + word
# we will stop if we predict the endseq
if word == 'endseq':
break
return in_text
The following function is ‘generate_desc,’ which is required to generate the caption for a given image in a training or test dataset. The model takes 4 arguments: model, tokenizer, photo, and max_length. This function is self-explanatory. We are just trying to predict the captions for any given image.
Evaluating the Results
# evaluate the skill of the model
def evaluate_model(model, descriptions, photos, tokenizer, max_length):
actual, predicted = list(), list()
# step over the whole set
for key, desc_list in descriptions.items():
# generate description
yhat = generate_desc(model, tokenizer, photos[key], max_length)
# store actual and predicted
references = [d.split() for d in desc_list]
actual.append(references)
predicted.append(yhat.split())
# calculate BLEU score
print('BLEU-1: %f' % corpus_bleu(actual, predicted, weights=(1.0, 0, 0, 0)))
print('BLEU-2: %f' % corpus_bleu(actual, predicted, weights=(0.5, 0.5, 0, 0)))
print('BLEU-3: %f' % corpus_bleu(actual, predicted, weights=(0.3, 0.3, 0.3, 0)))
print('BLEU-4: %f' % corpus_bleu(actual, predicted, weights=(0.25, 0.25, 0.25, 0.25)))
We initialize two lists, one for actual description and the other for predicted description. We then use for loop to generate predicted descriptions using the generate_desc function. Similarly, the actual descriptions are saved in a variable named ‘references. Lastly, we are calculating the BLEU score based on these lists to summarize how close these predicted descriptions are to actual descriptions. Let’s implement all this on our test data:
# load test set
filename = 'Flickr_8k.testImages.txt'
test = load_set(filename)
print('Dataset: %d' % len(test))
# descriptions
test_descriptions = load_clean_descriptions('descriptions.txt', test)
print('Descriptions: test=%d' % len(test_descriptions))
# photo features
test_features = load_photo_features('features.pkl', test)
print('Photos: test=%d' % len(test_features))
# load the model which has minimum loss, in this case it was model_18
filename = 'model_18.h5'
model = load_model(filename)
# evaluate model
evaluate_model(model, test_descriptions, test_features, tokenizer, max_length)
Conclusion
Image caption generator is the most used application in the industry these days, and by now, you must have some idea how important this is. A project like this on your resume will help you get shortlisted. Here we learned how to build and evaluate our image caption generator. We used a CNN+LSTM model to train our model. Since we had just 8000 photos, the accuracy I achieved was not that good, but you should try it on your dataset with more photos. Few takeaways from this guide :
1- We used CNNs as an image extractor and LSTM for the sequential model.
2- We used progressive learning to train our model fast.
3- Training on a bigger dataset will give you better accuracy.
4- We used BLEU Score to evaluate our model.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I have recently graduated with a Bachelor's degree in Statistics and am passionate about pursuing a career in the field of data science, machine learning, and artificial intelligence. Throughout my academic journey, I thoroughly enjoyed exploring data to uncover valuable insights and trends.
I am eager to continue learning and expanding my knowledge in the field of data science. I am particularly interested in exploring deep learning and natural language processing, and I am constantly seeking out new challenges to improve my skills. My ultimate goal is to use my expertise to help businesses and organizations make data-driven decisions and drive growth and success.




