This article was published as a part of the Data Science Blogathon.
Introduction

Airflow Apache platform for automating workflows’ creation, scheduling, and mirroring. Not only is it free and open source, but it also helps create and organize complex data channels. A data channel platform designed to meet the challenges of long-term tasks and large-scale scripts. Airflow was developed at the request of one of the leading open source data channel platforms. You can define, implement, and control your data integration process with Airflow, an open-source tool.
Operation Kernels (DAGs) allow you to describe program elements organized and executed according to a graphical schema. The platform offers many ready-made connectors for continuous and complete coverage of all business process conditions.
Workflows are designed and represented in Airflow Apache as a directed acyclic graph (DAG), with each node of the DAG representing a specific task. Built on the belief that every data pipeline is better defined than code, Airflow is a code-first platform allowing you to iterate quickly through your workflows. Other pipeline solutions fall short compared to the scalability of this code-first design philosophy.
Updated and maintained by the Apache Software Foundation.
Table of contents
Understanding the Architecture
Workloads: DAGs do several things. Some of them could be subclasses of the main conditional operator like this :
Operators: Use predefined jobs that are easy to connect to.
Sensor: A type of operator called a sensor monitors external events.
Task Flow: Python custom functions packaged as tasks and refined using tasks
Operators are the most important element of Apache Airflow, as they define what tasks are executed and how at runtime they function
Operators and sensors serve as models for creating tasks, but the terms task and operator are sometimes used interchangeably.
You can create and apply workflows on the Airflow platform. Work processes are represented in the form of directed acyclic graphs (DAGs). The following diagram shows the DAG model.

Tasks are contained in a DAG that defines dependencies and order of execution. Executors manage scheduled processes and execute tasks assigned by journals. The executive power compels workers to perform their jobs.
A database for storing state metadata, a web garcon for checking and modifying jobs and DAGs, and subdirectories containing DAG files are common elements of the Airflow architecture.
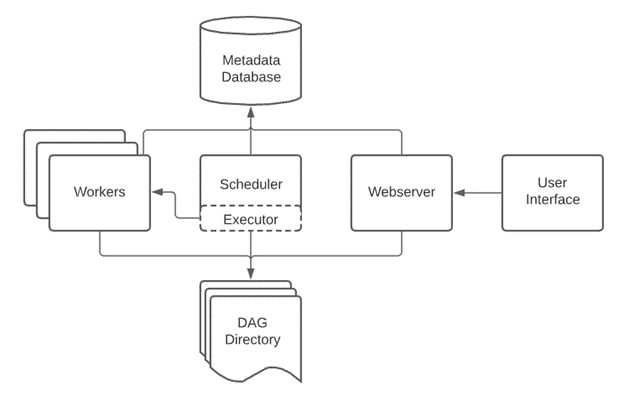
Control Flow
A DAG can be run multiple times, and multiple DAG implementations can fail randomly. A DAG can have multiple parameters that define its behavior, but all DAGs require a completion date argument
The >> and << characters can specify task dependencies within a DAG. Executes, but like branching and starting rules, only the last function can change how the task is executed.
first_task >> [second_task, third_task] third_task << fourth_task
A task must stay for all source operations to finish before executing. Still, only the rearmost functions, similar to branching and starting rules, allow you to change how tasks are executed.
SubDAGs can be used to embed “applicable” DAGs within other DAGs to manage complex DAGs. Use task groups to organize your tasks in the user interface visually
Delegates and their staff can be considered a single logical element throughout Airflow that controls the actual task tracking. As delegates mature, they typically introduce other building blocks, similar to task lines, that help delegates interact with staff.
Airflow Apache is reluctant to arrange and run, even if it has high-level support from either vendor or a direct command to run a shell or Python driver. Airflow is independent of the software you use.
Setting up Apache Airflow
You’ve probably heard of Airflow Apache ; what is it? (also called Extract in some cases) to automate complex tasks. Variant or ETL of the acronym Sucker). This is a valuable skill, but it can be difficult to learn to use, let alone set it up on the original PC. Explaining how to use Airflow could fill a 500 Runner book, so this post will be devoted to showing you how to install it on Windows 10.
Step 1 — Installing Ubuntu
What is Ubuntu? Ubuntu is a Linux operating system that simplifies your desktop experience. Most people are accustomed to using a nice graphical interface (GUI) to organize their folders and files. Still, Ubuntu, while intimidating, offers more desktop control and is more comfortable to use. I can do it. Before installing, check the developer system’s development by opening “Developers” and selecting the developer.
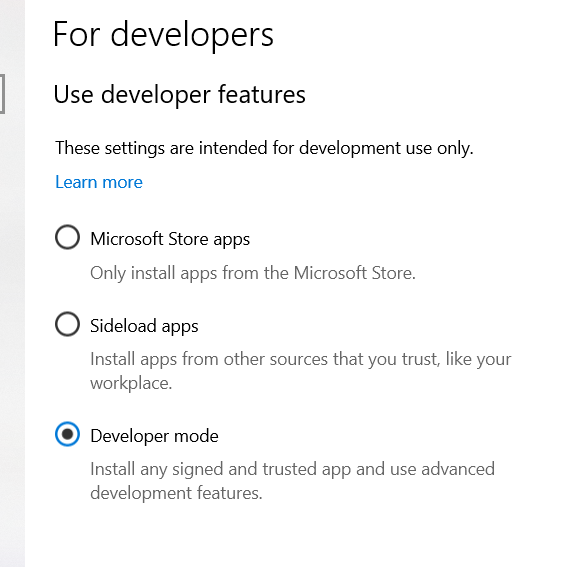
Search>Developer Settings>select Developer Mode
Then enable the “Subsystem for Linux” option in Windows Features.
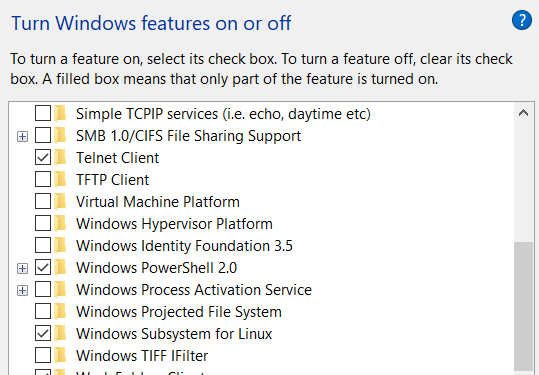
Finally, download the Visual C ++ builder
Now you can install Ubuntu. After installing ubuntu from the Microsoft Store, your device will automatically open and prompt you for your username and password.
FYI, once you start encoding your password, you may not see any characters on your terminal. Don’t worry. Your computer is not hacked. Trust your fingertips.

Still, type bash when nearing the terminal to boot into Ubuntu and update after completing the last step. Bash is a command language that allows you to interact with your computer.
Step 2 — Installing Pip
Pip is a management system designed for installing software packages written in Python. That’s all you need to download Apache Airflow. Complete this step by running the following code command: pip
sudo apt-get install software-properties-common
sudo apt-add-repository universe
sudo apt-get update
sudo apt-get install python-setuptools
sudo apt install python3-pip
sudo -H pip3python install --upgrade pipStep 3 — Install Airflow Dependencies
Before installing Apache Airflow, make sure the required dependencies are installed by running the following command is needed. Airflow Apache uses SQLite as an overview database. However, read the Airflow documentation if you want to use a scalable commercial product like PostgreSQL. But if you want to avoid complexity and learn the basics, skip to step 4. Run the following code and you should be good to go.
sudo apt-get install libmysqlclient-dev
sudo apt-get install libssl-dev
sudo apt-get install libkrb5-devStep 4 — Installing Apache Airflow
Finally, we are here !! Run the code below and you’re good to go.
export AIRFLOW_HOME=~/airflow
pip3 install apache-airflow
pip3 install typing_extensions# initialize the database
airflow initdb# start the web server, the default port is 8080
airflow webserver -p 8080# start the scheduler. I recommend opening up a separate terminal #window for this step
airflow scheduler# visit localhost:8080 in the browser and enable the example dag on the home page
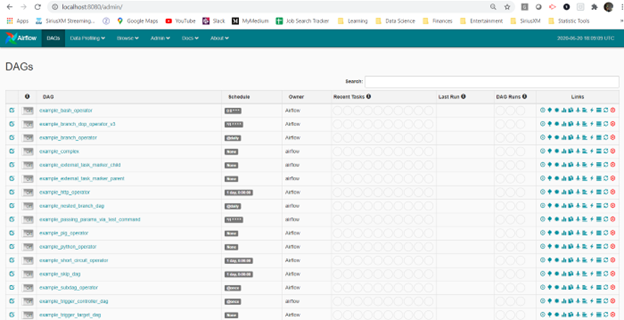
And you’re done! Now you can play with this super-important tool. Fewer installation headaches so you can save energy for more productive work.
Core Concepts Overview
- Directed Graph: A directed graph is any graph whose vertices and edges have a specific order or direction.
- Directed Acyclic Graph: A directed graph without cycles is called a directed acyclic graph. A cycle is a collection of vertices connected, forming an unconstrained chain.
A data channel defined in Python code is called a directed acyclic graph (DAG). Each label in Airflow is organized to describe the relationships between tasks and represent groups of tasks that need to be completed. The usefulness of DAGs becomes apparent when you classify their functionality.
- Directed: All jobs with dependencies must have at least one upstream or downstream task defined.
-
Acyclic: Data that a task cannot generate references itself. This prevents the formation of infinite circles.
- Graphs: Each task is organized in a specific structure, and operations are performed at given points where connections with other tasks are established.
For demonstration purposes, the image below compares a valid DAG on the left and a disabled DAG on the right with some direct connections.
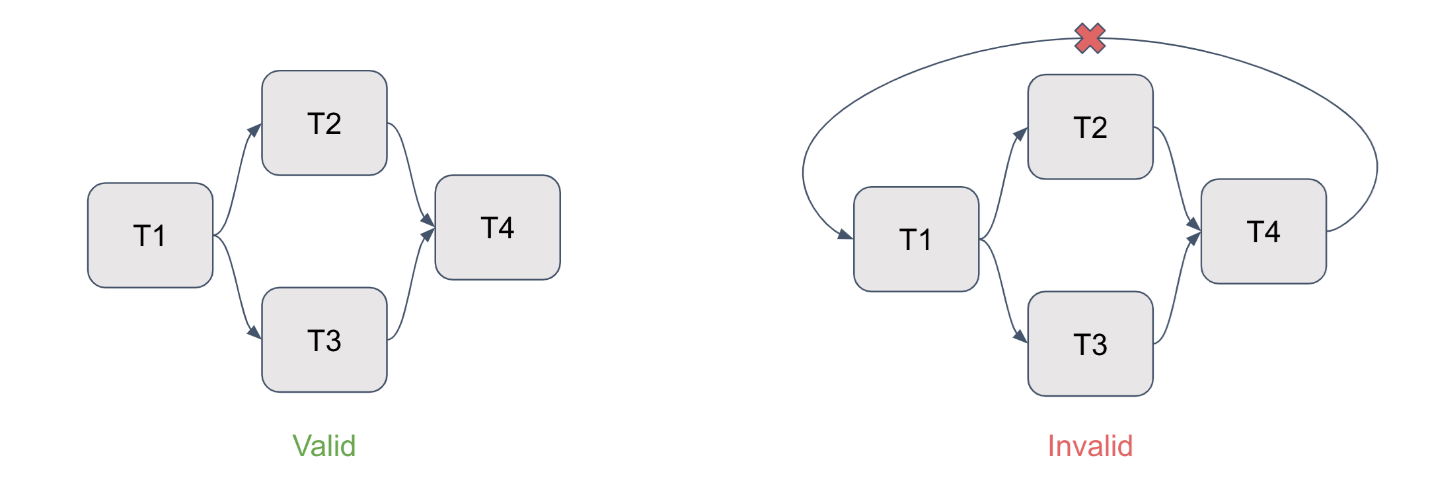
- Tasks: Each task represents a node in a given DAG. These are visual representations of the work done at each stage of the workflow, showing the effective work done by the operator.
- Operators: The main airflow unit defines the specific work of the operators. They can be likened to envelopes that indicate how a particular task or its DAG nodes are reused. Instructions specify what must be done at each step in the process, but the DAG ensures that the instructions are planned and implemented in a specific order.
Operators fall into three broad categories:
- Action operators perform functions similar to Python and Bash operator
- A Transfer operator, similar to S3ToRedshiftOperator, transfers data from a source to a target.
- Like ExternalTaskSensor, the sensor operator sticks to the task it needs to perform.
Each driver has its description but can communicate with each other through XComs.
Here is his collective structure of DAGs, drivers, and tasks based on :
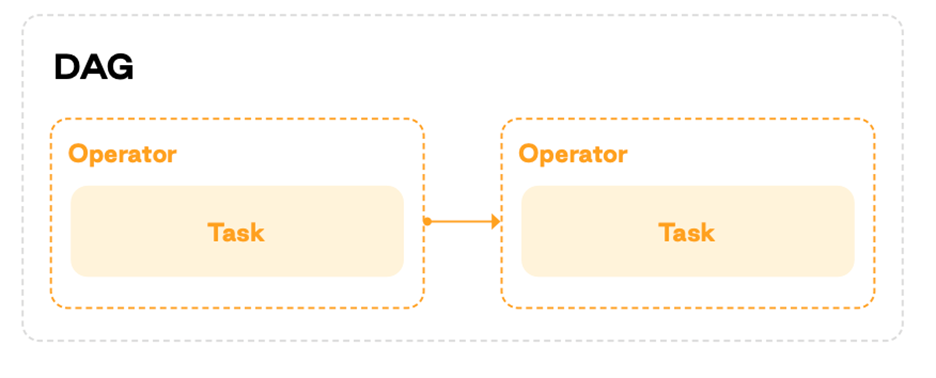
- Hooks: An approach to connect airflow to external systems is to use hooks. You can connect to external APIs and databases, such as Hive, S3, and MySQL. They serve as the base for drivers. Secure information, like authentication data, is stored outside the interceptor and not in the transformed metadata database that resides in the Airflow enclosure and is accessible through the Airflow connector.
- Providers: A provider is a collection of all drivers and hooks required by a particular service (Amazon, Google, Salesforce, etc.). As part of Airflow2.0, these packages are delivered together but are readily available in multiple packages and ready to install on your Airflow system.
- Plugins: Airflow plugins combine hooks and drivers to perform specific functions, like moving data from Salesforce to Redshift.
- Connections: Airflow stores data needed to connect to external systems, like API tokens and authentication credentials. Fact data is translated and stored as metadata in a stabilized Postgres or MySQL Airflow database and managed directly from the user interface.
- Scheduler: A scheduler that manages the initiation of pre-scheduled workflows and the delegation of tasks to delegators for follow-up.
- Executor: Task Manager is called Executor. While very unusual designs delegate tasks to workers, forced ventilation configurations do everything within the design architecture.
- Web Server: A web server that provides an accessible user interface for inspecting, invoking, and modifying the behavior of DAGs and tasks.
- DAG files: A collection of DAG files that the scheduler and executor (and all workers that the executor has) can see.
Airflow Best Practices
Here are a few best practices to help you use Airflow more effectively.
- Define the Clear Purpose of your DAG: Before you start constructing a DAG, you should precisely consider what you want from it. Questions like DAG input, its purpose, when and how frequently it should be run, and with what third-party tools should it interact? Your data channel shouldn’t be too complex. DAGs should serve a purpose similar to optimizing machine literacy models or exporting data to a data storehouse. To minimize complexity and simplify conservation, keep DAGs as simple as possible.
- Keep Your Workflow Files Up to Date: Assembling with Python law, you need to find a way to support the Airflow workflow. The easiest way is to sync them with a Git repository. In the DAGs brochure of the Airflow brochure, you can produce subfolders associated with the Git repository from which Airflow will download lines. You can use BashOperator and make requests to make the factual sync. A Git repository can also be used to attend new lines used in workflows, similar to machine literacy training scripts. One option is to start a workflow by making a request.
- Use Variables for More Flexibility: There are several approaches to increase the inflexibility of DAG objects using Airflow. Each process prosecution receives a runtime terrain variable that’s incontinently collected into an SQL statement. This includes the cycle ID, Kurd, and time of the former and coming run. For illustration, you can set the data period to a predefined performance interval. A metadata database that can be modified via an Internet interface, API, and CLI is another option Airflow offers for storing variables. For illustration, it can be used to keep train paths flexible.
- Define Service Level Agreements (SLAs): Using Airflow, you can specify a deadline for a task or an entire workflow. In case of a deadline violation, the responsible person is notified, and the event is recorded in the database. This allows you to identify anomalies that can beget detainments, similar to the liability that you’ll reuse large quantities of data.
- Machine Learning Workflow Automation with Run: AI: Perpetration By using Airflow to automate machine literacy workflows, AI can help automate resource operation and collaboration. Prosecution With AI, you can automatically do various computer ferocious tests.
- Set Priorities: Time issue points do when multiple work processes contend for the prosecution simultaneously. You can control the prioritization of workflows using the precedence weight parameter. A single parameter can be set per task or handed as the dereliction value for the entire DAG. Airflow 2.0 allows you to use multiple scheduling events to reduce workflow launch detainments.
Importance of Airflow Apache
These are the main arguments for the importance of Apache Airflow.
- A key benefit of Apache Airflow is the ability to coordinate analytics and data workflows under one roof. This gives you full visibility to track your progress.
- Execution log entries are collected in one place.
- Using Airflow is important because it includes a way to structure process code and thus automates workflow development.
- If your DAG is low, you can send a report message via Slack when an error occurs.
- Clearly express DAG dependencies.
- The ability to play metadata allows individual files to be downloaded.
Use Case
Almost Any Package Data Channel Can Use Airflow due to its versatility; exclusions are very useful when planning tasks with complex external system dependencies. For illustration purposes, the following image shows Airflow’s complex process.
By creating channels in code and using one of the available Airflow plugins, you can work with multiple dependencies using a single platform for collaboration and monitoring.
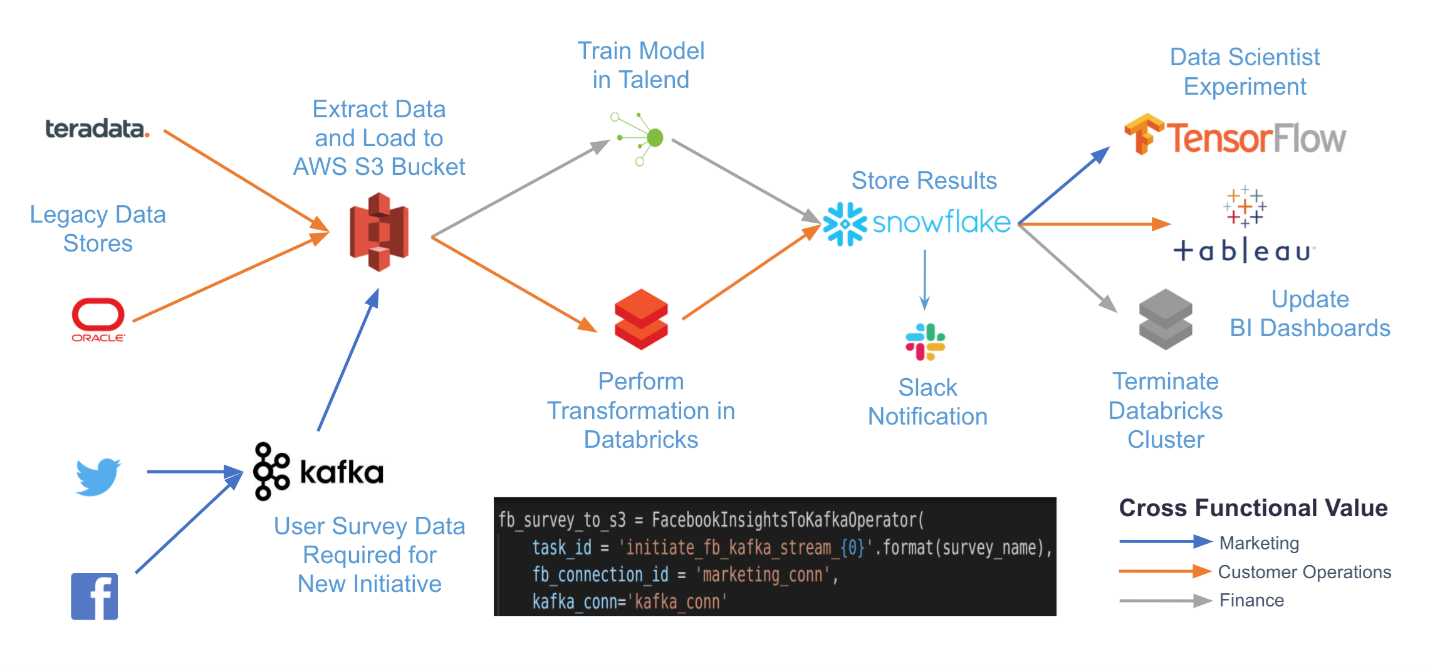
Advantages of Apache Airflow
- Data extraction and upload coordinate: using other systems to perform data payload and extraction activities.
- Integrations: Several connectors are already in place, including Amazon S3, Azure, Apache Spark, and others.
- Rendering with standard Python: You can create a comprehensive workflow using Python without prior experience with other technologies or fittings.
- Graphical User Interface: See the status of ongoing and completed tasks while covering and managing the process.
- Ease of use: Basic knowledge of Python is enough to get started.
- Open Source Community: Airflow is free, widely used, and has a sizeable user base.
- Efficiency: Improved System Integration and Collaboration
- Governance: Ability to Polarize Data Flow Description and Operation
- Fewer Errors: Less Security Breach and Consequent Rework
- Reduced Costs: Time
Limitations of Airflow Apache
- Data quality cannot be truly monitored: A idler with blinders, Airflow. However, it’ll affect the channel, If the commodity goes wrong with the data. This doesn’t affect course correction. Nearly every stoner has encountered some type of workflow where a task has been completed and needed to validate data only to find that a column is missing, invalid, or the data isn’t coming. The system isn’t transferred. This is especially true as the data structure evolves as you go from knockouts of acyclic data graphs( DAGs) to thousands. However, because you’re now using these DAGs to prize data from external data sources and APIs, icing data quality in flight is more delicate, If so. You can not” cancel” the raw data set or have your operation process.
- Onboarding for Airflow is not simple: Learning the tailwind takes time. numerous mound Overflow vestments and papers describe the struggles of inventors asking,” Why do I not plan to start?” Tailwind Scheduler starts cataloging at the end of the specified period, not in the morning. More on that latterly. There’s also no way to learn Celery Executor and RabbitMQ or Redis to control Airflow.
- Intervals in the Airflow Scheduler are not intuitive: As its attestation countries, “ workflows are designed to be stationary or sluggishly dynamic, ” and Airflow is used to record repetitious blocks rather than rerun them. This doesn’t make it ideal for some ETL and data wisdom use cases, as it doesn’t have an important eventuality for slice data or those who need it all the time.
- Airflow Scheduler has no versioning: The capability to maintain channels’ performances is a standard DevOps and software development practice that Airflow lacks. It’s not an easy way to save everything you’ve created and redo it as demanded. For illustration, if you cancel a task from your DAG and exercise it, you’ll lose the metadata associated with the case. This makes the tailwind tricky and harder to remedy unless you write to catch it yourself. It isn’t possible to confirm possible corrections by reassessing against former data.
- Windows users cannot locally utilize it: There is no important difference to say. It isn’t possible unless you use customized Docker compose lines that aren’t included in the regular depository.
- Debugging takes a lot of time: The operator organizer and driver activator are not sufficiently decoupled from the tailwind. Many drivers do both. This was helpful in advance when rendering the platform but was a destabilizing factor that made debugging difficult. You should check your input parameters, i.e., driver, If the commodity goes wrong.
Conclusion
In this article, this Airflow Apache tutorial provided a systematic guide to setting up the platform on Ubuntu. Installing necessary dependencies and highlighting the importance, advantages, and limitations of Apache Airflow equips users with the knowledge to manage workflows efficiently, enhancing their understanding of this powerful workflow automation tool.
Here’s a quick overview of what this article offers readers:
- Open source, rigidity, scalability, and support for reliable operations are all hallmarks of Apache Airflow.
- The three main tasks in Apache Airflow are planning, capping, and creating workflows. These tasks were performed using a directed acyclic graph (DAG).
- To refresh your knowledge, you learned about Apache Airflow features key elements, operational cases, stylish practices and configuration requirements, and Apache Airflow benefits and limitations in this course.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
||📊Lead Technical Analyst at HP||Connecting data to dollar||📋Certified - Data Scientist||SAP ERP||Microsoft Data Analyst,LSS Yellow Belt||🥇3*MVP,1*APAC Champion@HP||🏆Blogathon Winner’22@Xebia,2*AVCC||AVCC Member’22||





