This article was published as a part of the Data Science Blogathon.
Introduction
Most of us are familiar with SQL, and many of us have hands-on experience with it. Machine learning is an increasingly popular and developing trend among us. BigQueryML is a toolset that will allow us to build machine learning models by executing standard SQL queries. BigQuery ML, shortened to BQML, is a pure SQL solution that leverages BigQuery to query massive datasets and train a machine learning model with it. In this article, we’ll try out BQML, learn about its principles and how it works, and then follow an example implementation.
.png)
We will proceed step by step, starting with the introduction of BigQuery, to better grasp the entire process and what happens behind the scenes.
Prerequisite:
- Intermediate knowledge and experience with standard SQL
- Basic Understanding of Machine Learning concepts
What is BigQuery?
BigQuery is a highly scalable, serverless data warehouse that can process queries on petabytes of data in a few minutes. It is a cloud-based Paas, or platform as a service, data warehouse offered by Google. BigQuery features built-in functions such as geospatial analysis, real-time data collection, business intelligence, and integration with a range of Google Cloud Platform (GCP) services, in addition to Machine Learning, which we will emphasize today.
Any business works with data, and if the data is modest enough, it can probably be fit into spreadsheets. However, if the amount of data expands to gigabytes, terabytes, or even petabytes, a more efficient solution, such as a data warehouse, is required. Traditional database management systems are incapable of handling such massive amounts of data. This is where BigQuery comes in. It is built to manage huge amounts of data, such as log data from thousands of retail systems or IOT data from millions of car sensors worldwide. It can process at least 100 billion regular expressions at 1 μsec per. We can use BigQuery via clients like BigQuery Web UI, REST APIs, or bg command-line tool.
How does query processing work in BigQuery?
It is built on top of Dremel Technology, which Google has been developing internally since 2006. Dremel is the execution engine for BigQuery. Below is the representation of the BQ architecture.
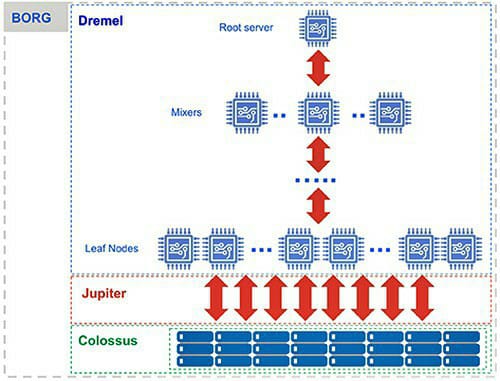
Source: https://cloud.google.com/blog/products/bigquery/bigquery-under-the-hood
First, the BigQuery client interacts with the Dremel engine via a client interface. Dremel converts the query into an execution tree. This tree is divided into two parts, its branches, and leaves. The branches are called mixers, which perform aggregation. The leaves are slots that perform necessary computation and read data using the Jupiter Network from the BQ filesystem. Google’s Jupiter network can deliver 1 petabit/sec of total bisection bandwidth. Now, mixers and slots are both run by Borg. Borg is a large-scale cluster management system that allocates server resources to Dremel jobs. Unlike traditional relational databases, BigQuery uses columnar storage, where data is co-located by column rather than storage. Internally, BQ stores data in a proprietary file format called a capacitor. It uses access patterns to encode data and reshuffle rows.
Databases such as MySQL and PostgreSQL use record-oriented storage to store data. It is effective for transactional modifications to a single or group of rows. In the case of aggregation, however, it must read the entire table into memory. Because BigQuery is focused on analytical use cases, its columnar storage allows it to read only a single column for aggregation.
All the files in BigQuery are stored in a distributed file system throughout Google called Colossus. Each Google data center has its Colossus cluster. Colossus ensures durability using erasure encoding, which breaks data into fragments and saves redundant pieces across a set of different disks.
Now that we have a general understanding of BigQuery and how it processes such massive quantities of data so quickly and effectively, we can move on to the machine learning portion.
Machine Learning on BigQuery
We are all aware that machine learning is an area of study in which we feed data to computers and allow them to learn and improve from that data without being explicitly programmed. In machine learning, any problem begins with identifying business problems, collecting an appropriate amount of data, preprocessing and splitting the data into train-test, training and evaluating the model, and finally deploying it to the cloud and making predictions.

Bigquery ML, on the other hand, greatly simplifies this process by automatically handling preprocessing and data splitting. It allows one to focus only on the right data formatting and choose which model to use. BQML allows us to,
- Train & Deploy ML models without moving data from BigQuery
- Iterate on models in SQL in BigQuery
- Make predictions without worrying about model deployment
Pricing & Supported Models of BQML
BigQuery currently supports over ten models, ranging from linear regression to K-Means clustering and time series to deep neural networks. A full list of supported models can be found on BQML documentation here.
Models in BQML can be classified into two categories: built-in models or models that are trained within BigQuery and external models like any imported models, DNN, or AutoML models. BQML pricing is on-demand and dependent on data location and type of operation, such as model creation, evaluation, or prediction, in addition to the model utilized.
Hands-on Implementation of BQML
We will create a regression model to predict the probability of a buyer adding a product to the cart using BigQuery by setting up a sandbox environment. To do that, go to the URL console.cloud.google.com/bigquery and click on create project button.

BigQuery provides over 100 datasets publicly available to analyze. These datasets can be found in the marketplace section of the google cloud navigation panel following this link. All the public datasets are available under the project bigquery-public-data, and we will pin this project within our UI by clicking on the + ADD DATA button as shown below-
For our prediction, we will use the ga4_obfuscated_sample_ecommerce dataset. It has tables divided by name events_YYYYMMDD i.e., data for each day represents a table. We can find the schema for every table and write a query like the below-
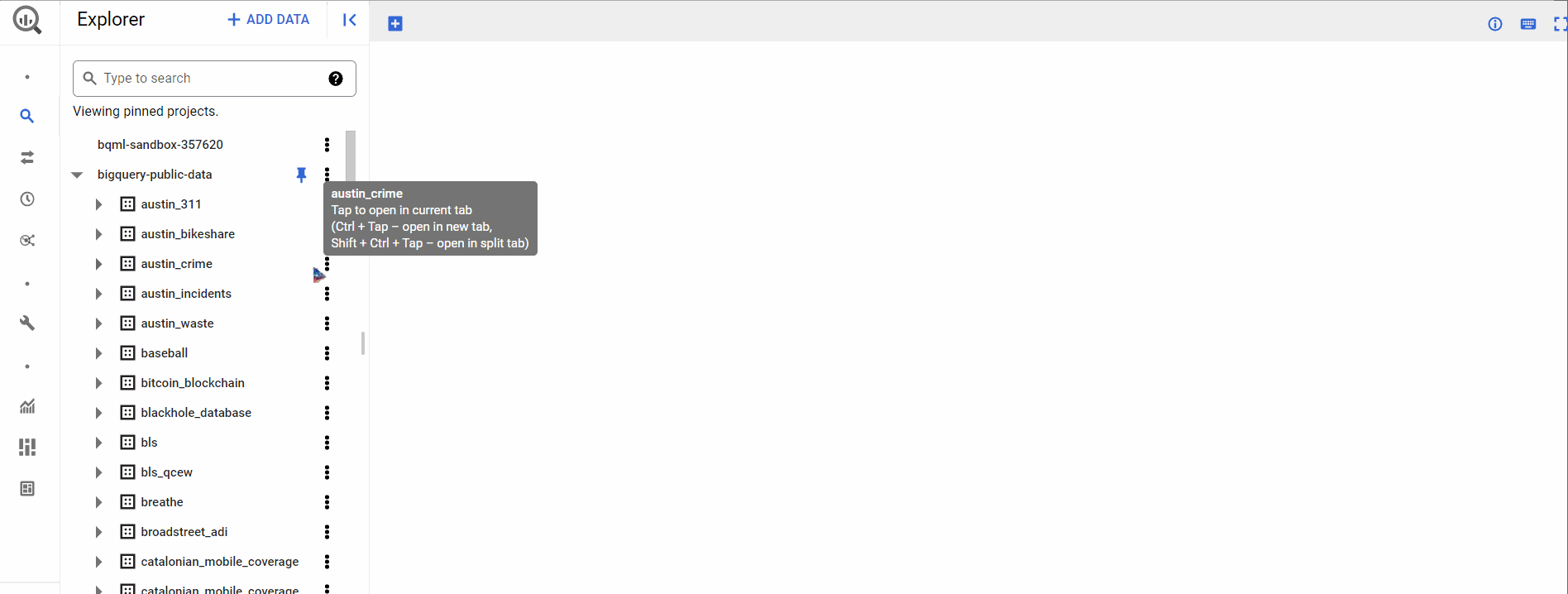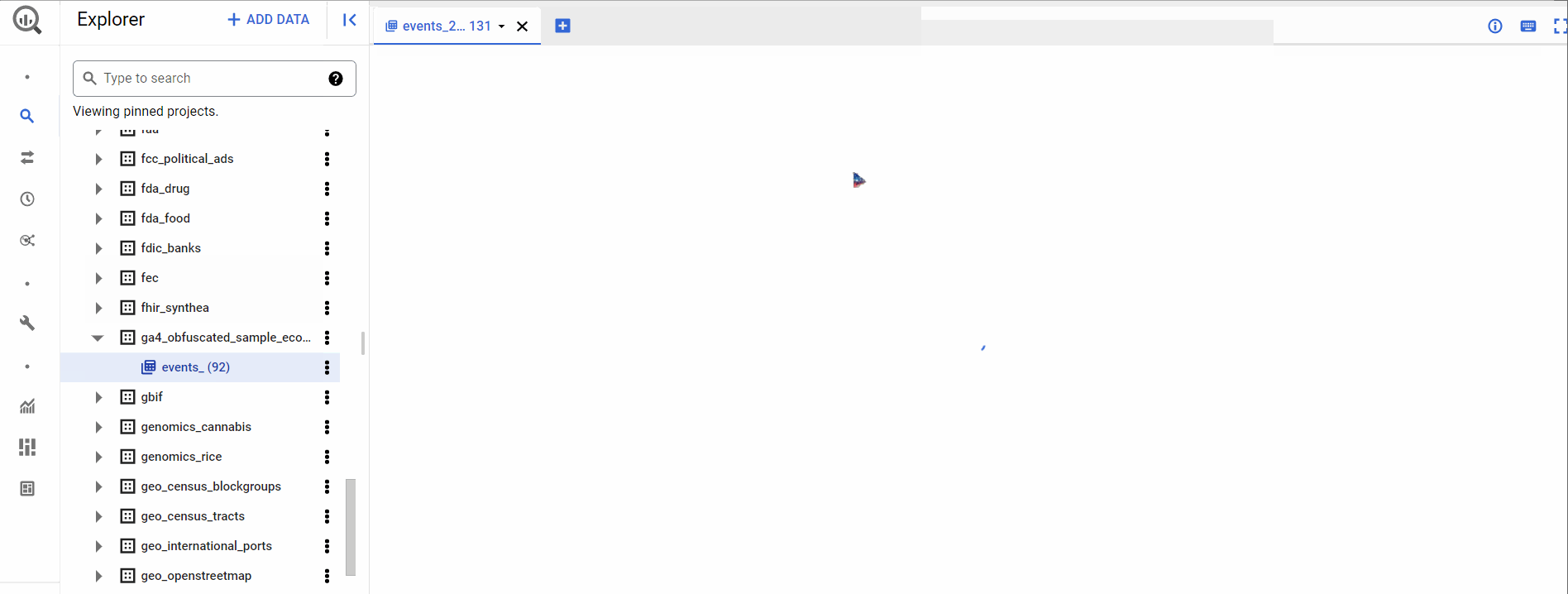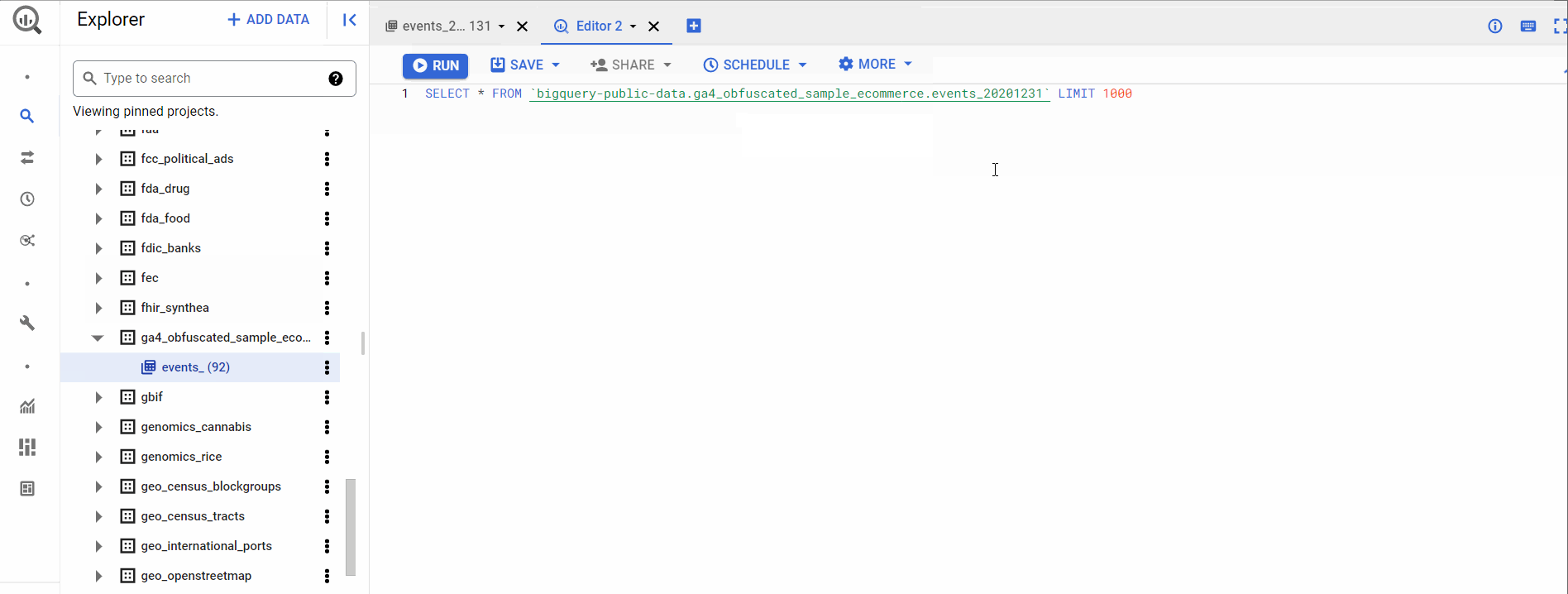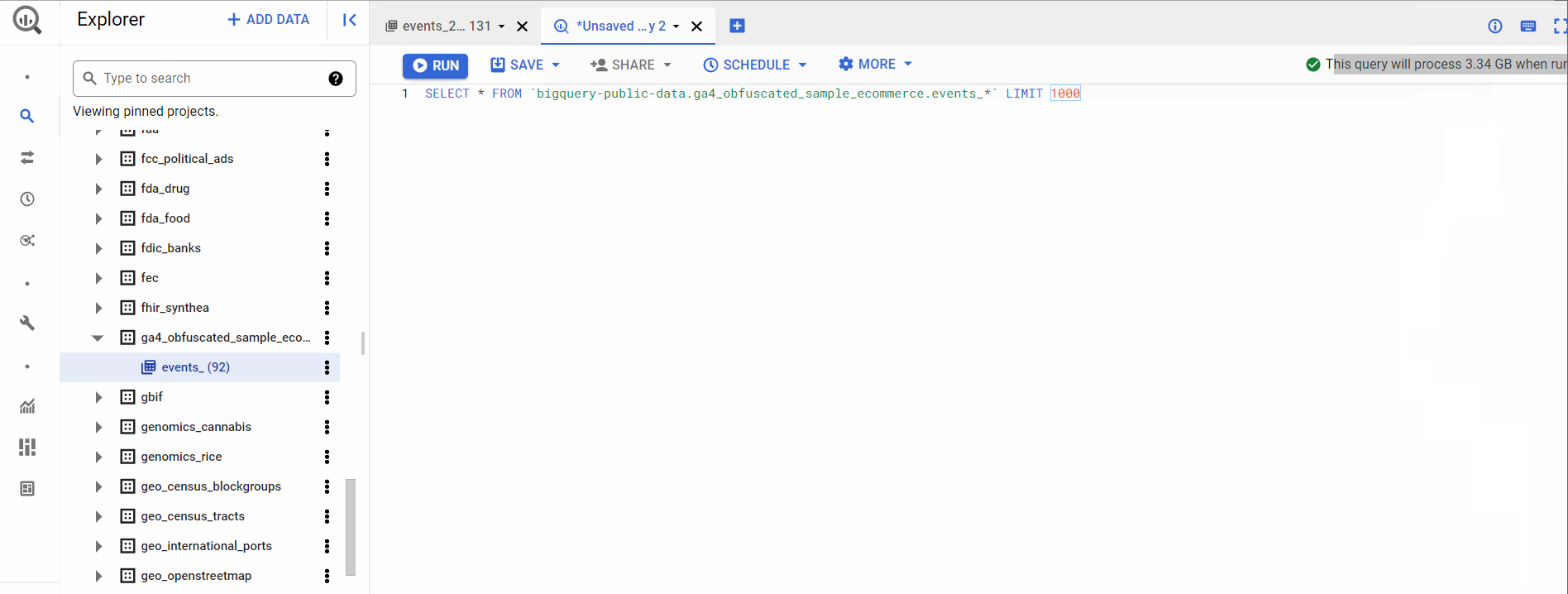
In the above clip, we’re changing the table name to events_* to select all the tables under the dataset. In the upper right corner, we can also check how much memory the query will process when run.
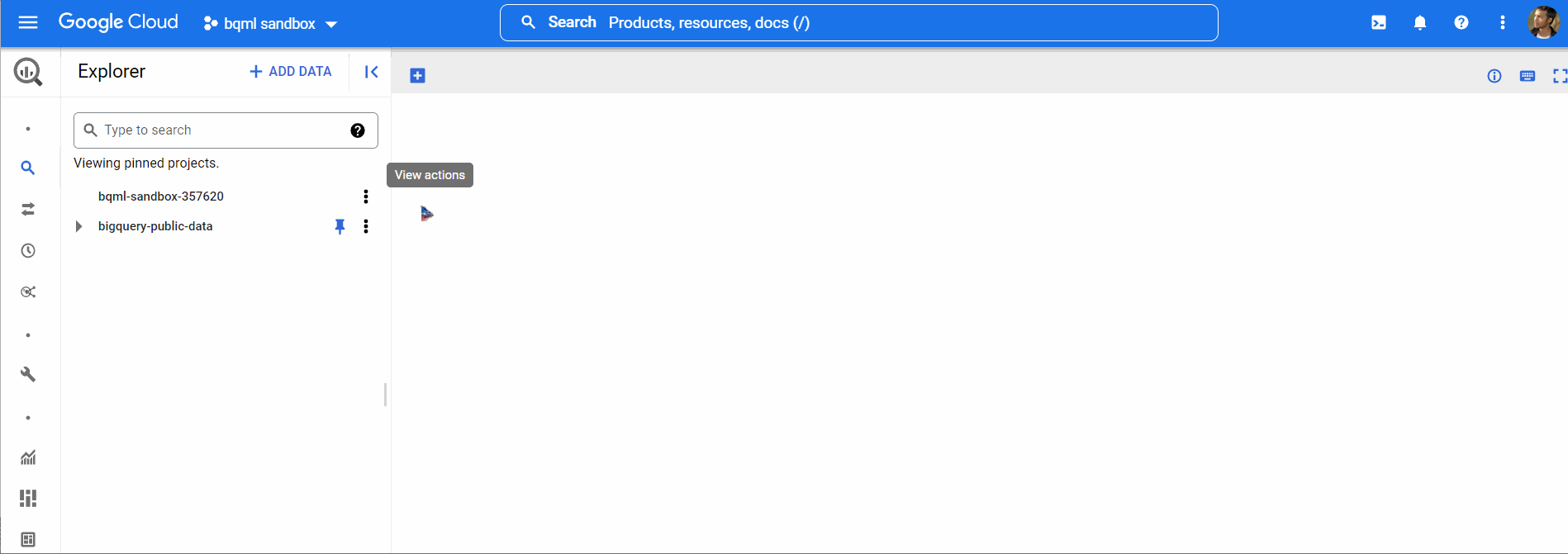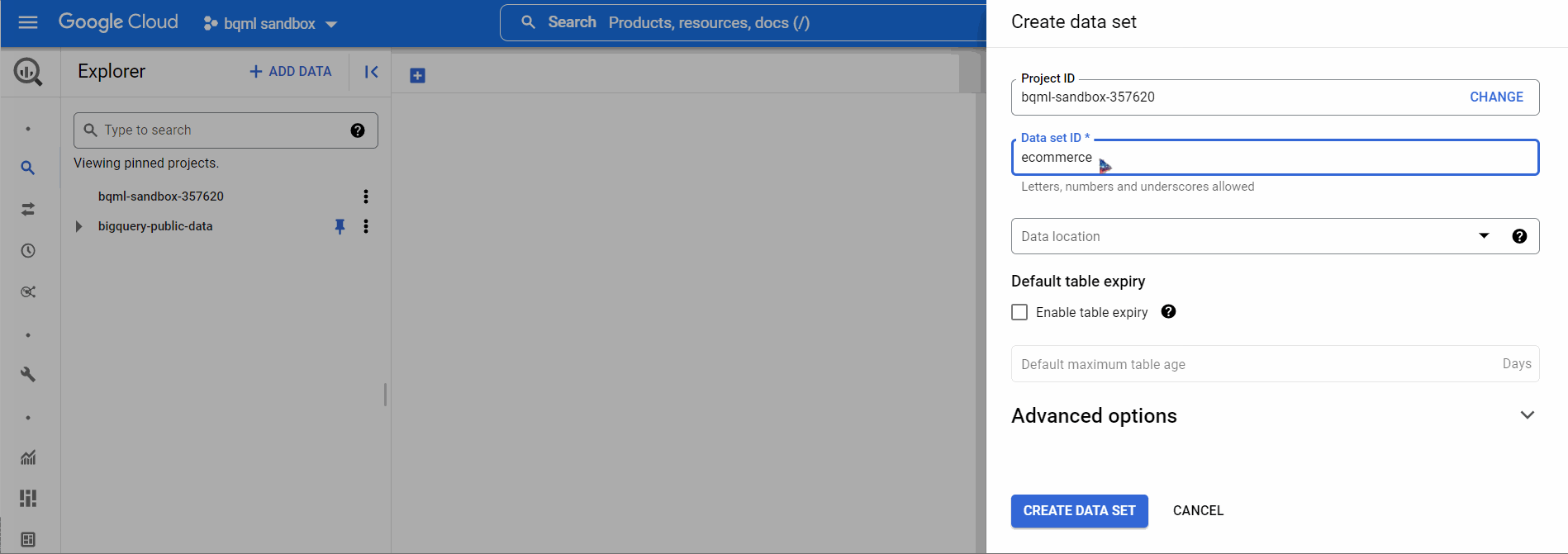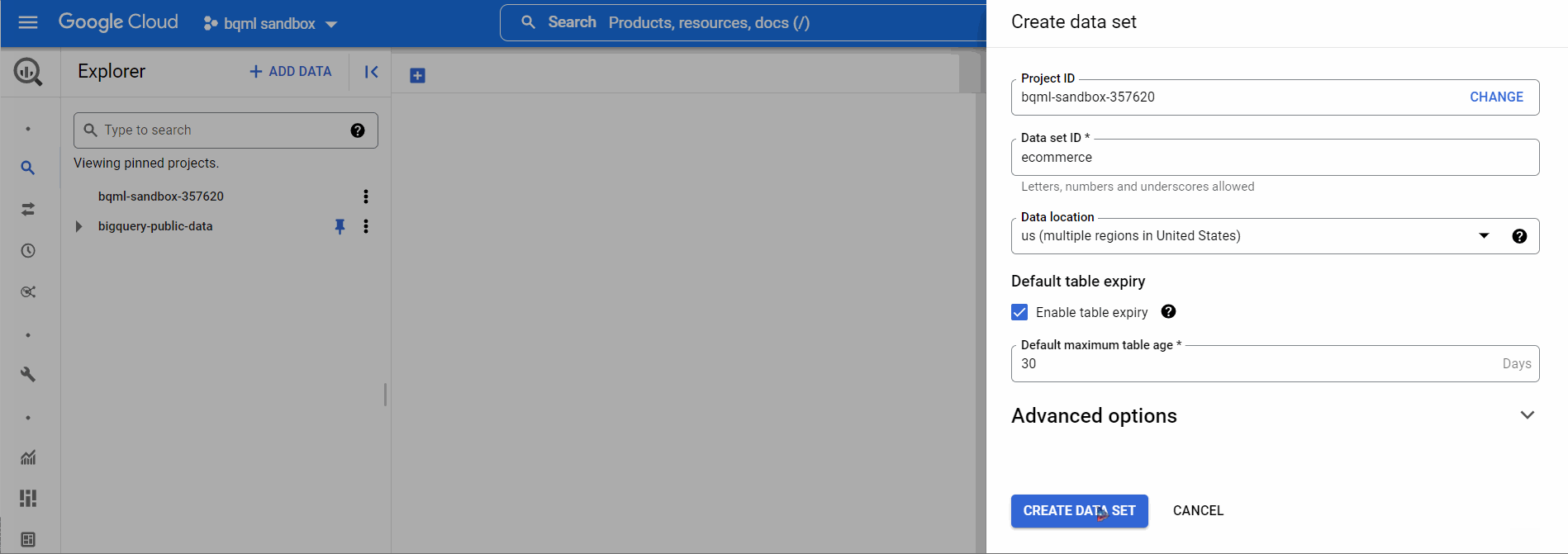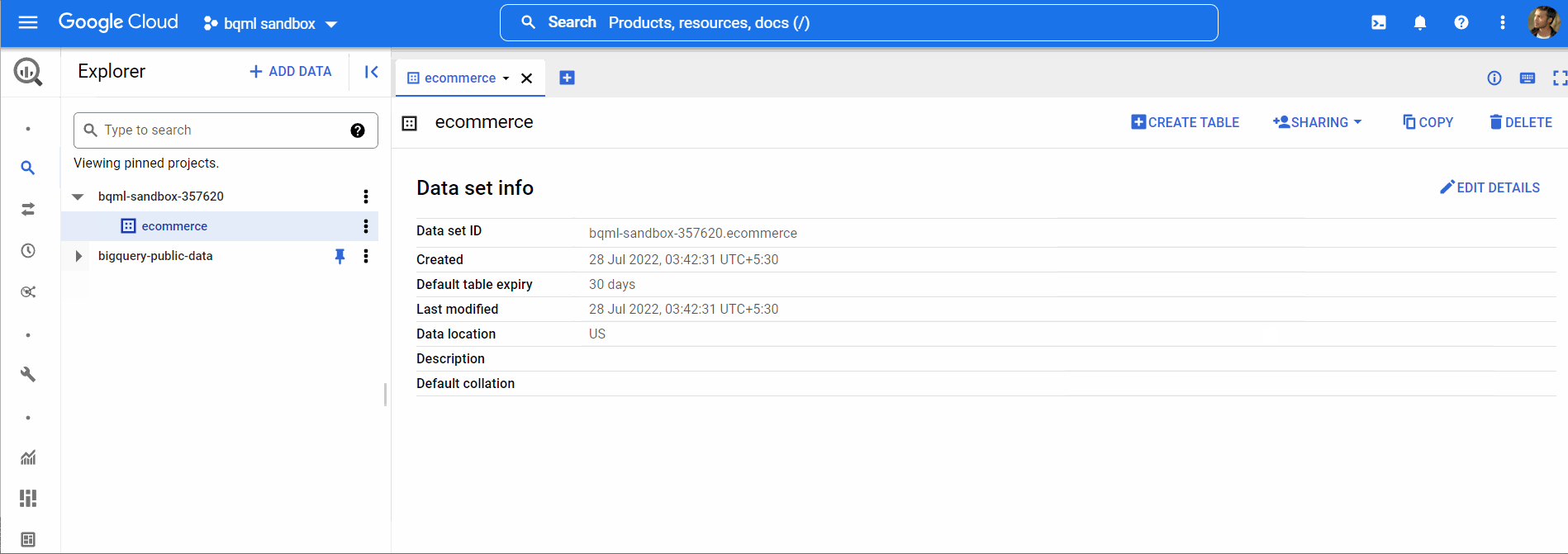
Before beginning the ML training, the models must be stored in a dataset. We will create a new dataset using BigQuery UI, name the dataset, and choose a location like the below-
Now, we will create our training set by the following query (link to query) below,
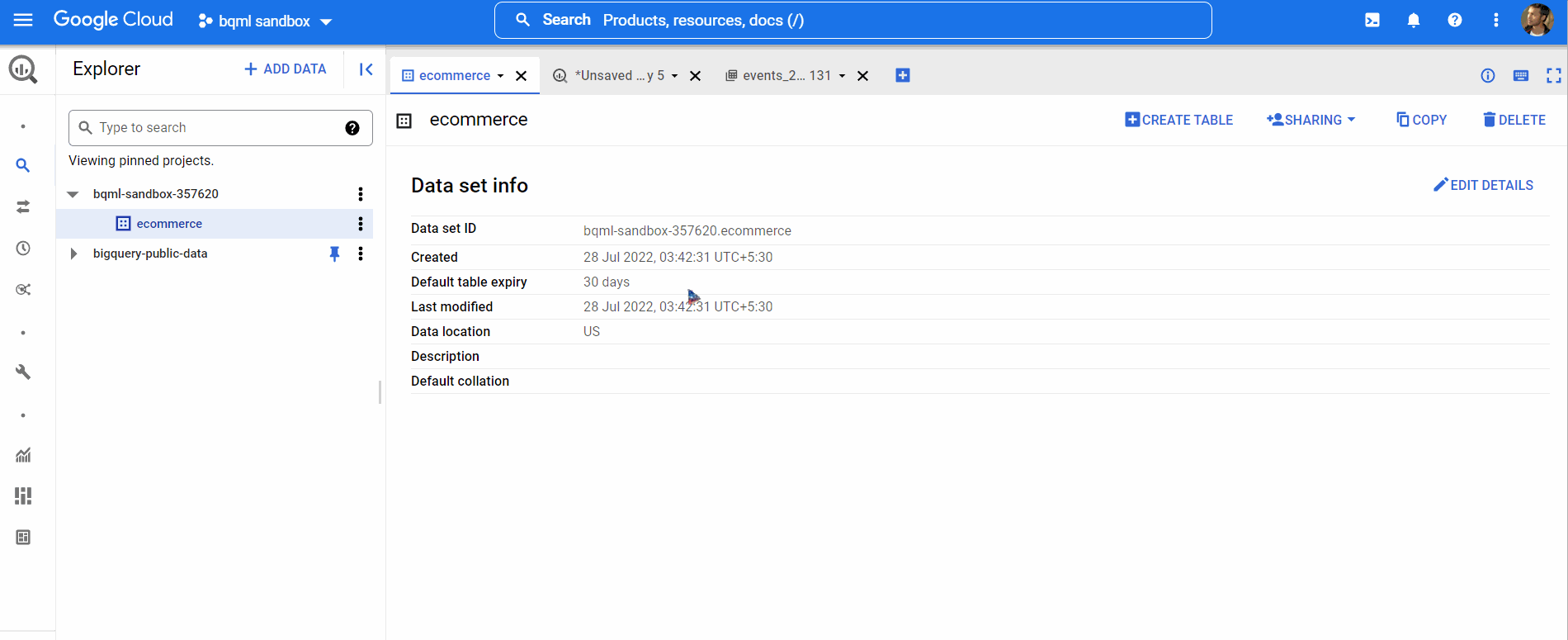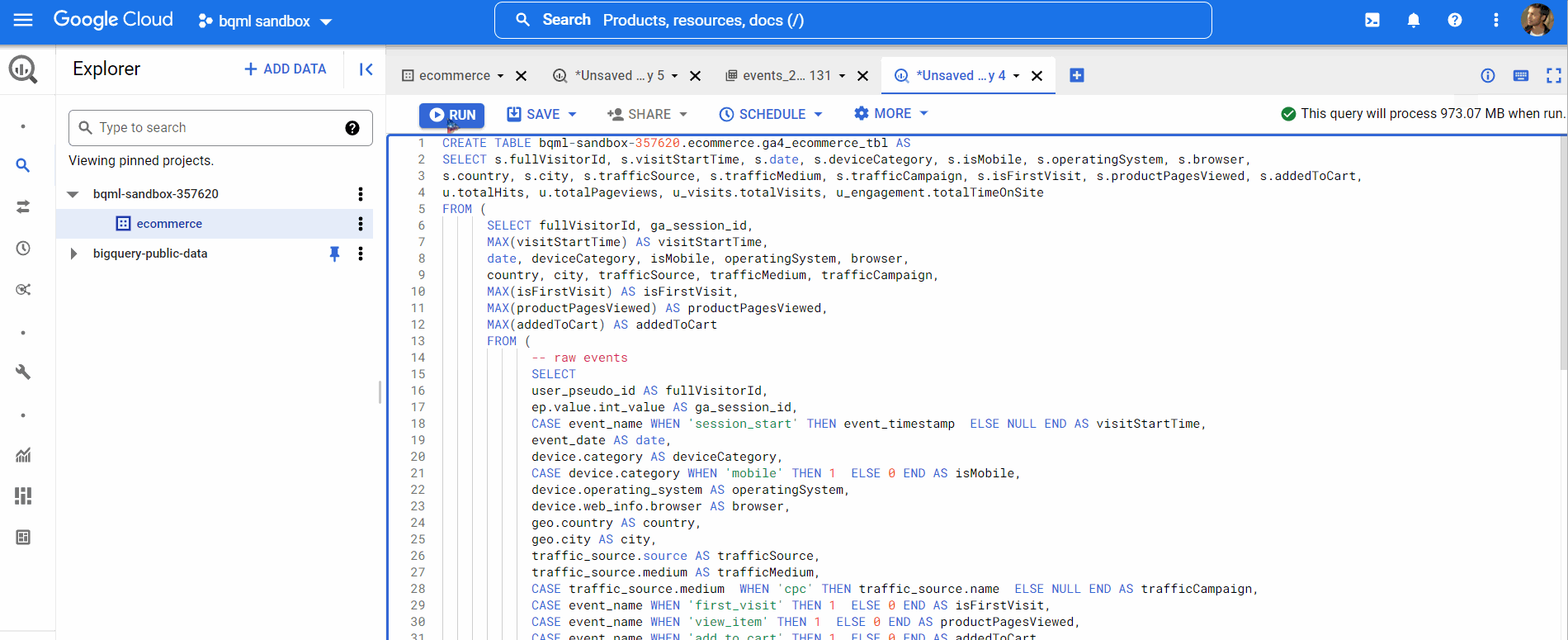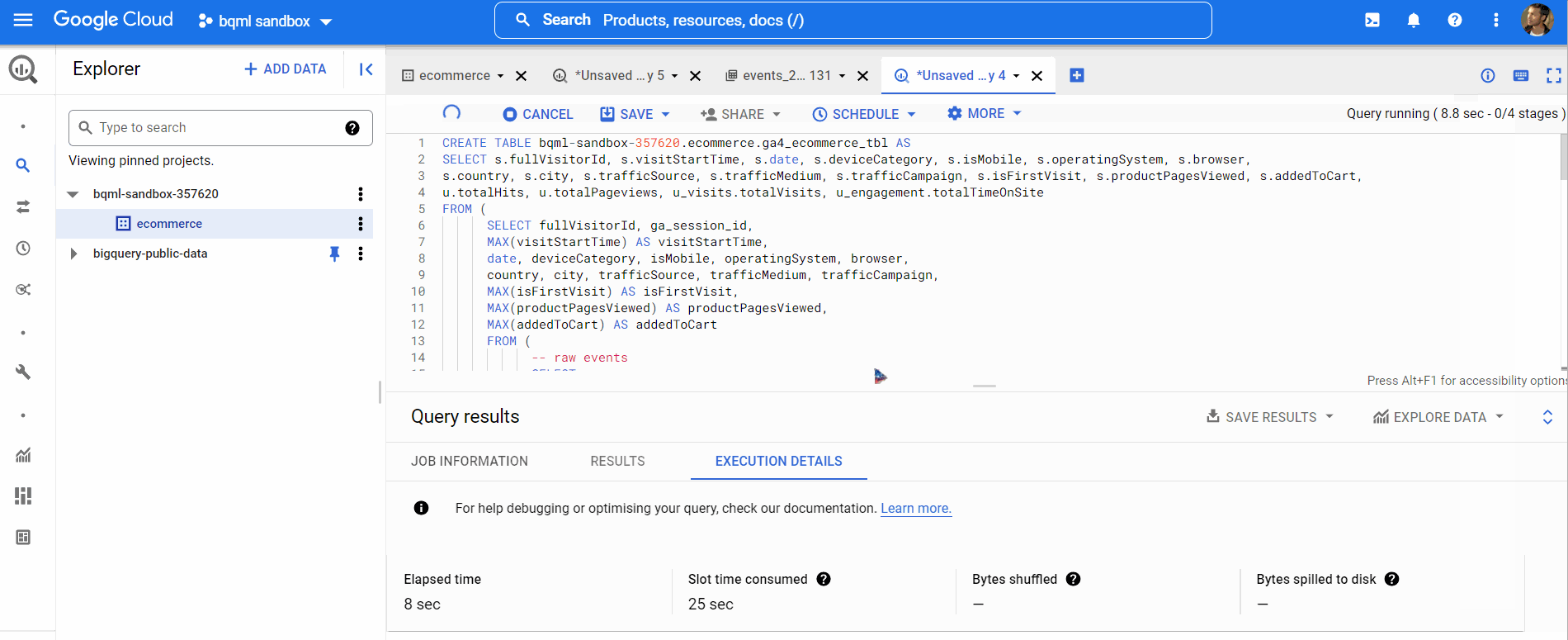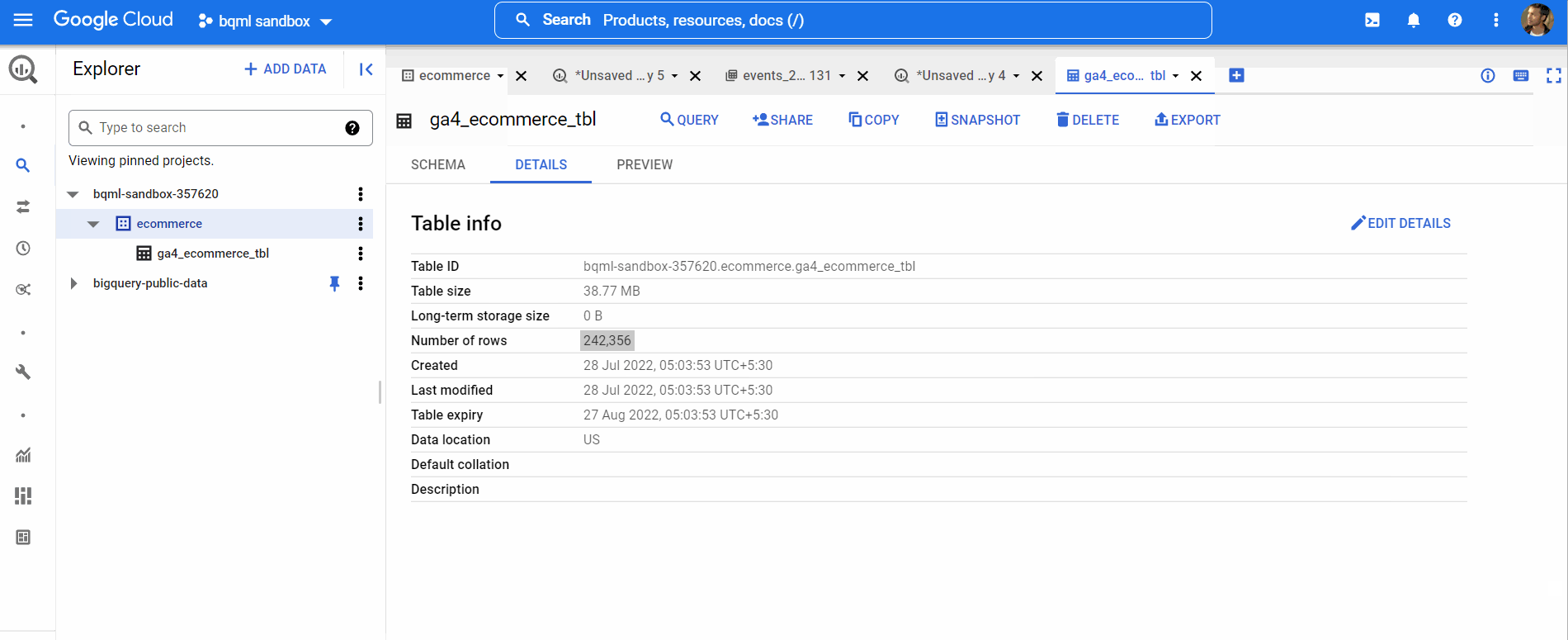
The following table will be used as our training dataset containing data from 2020. The schema of this table can be viewed in the same manner. We will skip all the data exploration and jump straight to the model creation part.
A little introduction to the BQML convention for creating a model-
- The CREATE MODEL statement is the same as CREATE TABLE is standard SQL. It’s always better to use CREATE OR REPLACE MODEL as per the standards.
- The ML.TRANSFORM is used for input preprocessing.
- BQML specifically looks for a column name label. If that column is not present in your query, then input_label_cols should be passed as an alternative target column.
Sample statement/convention for creating a model
Now, we will create our model using the query below
Query to Create or replace model,
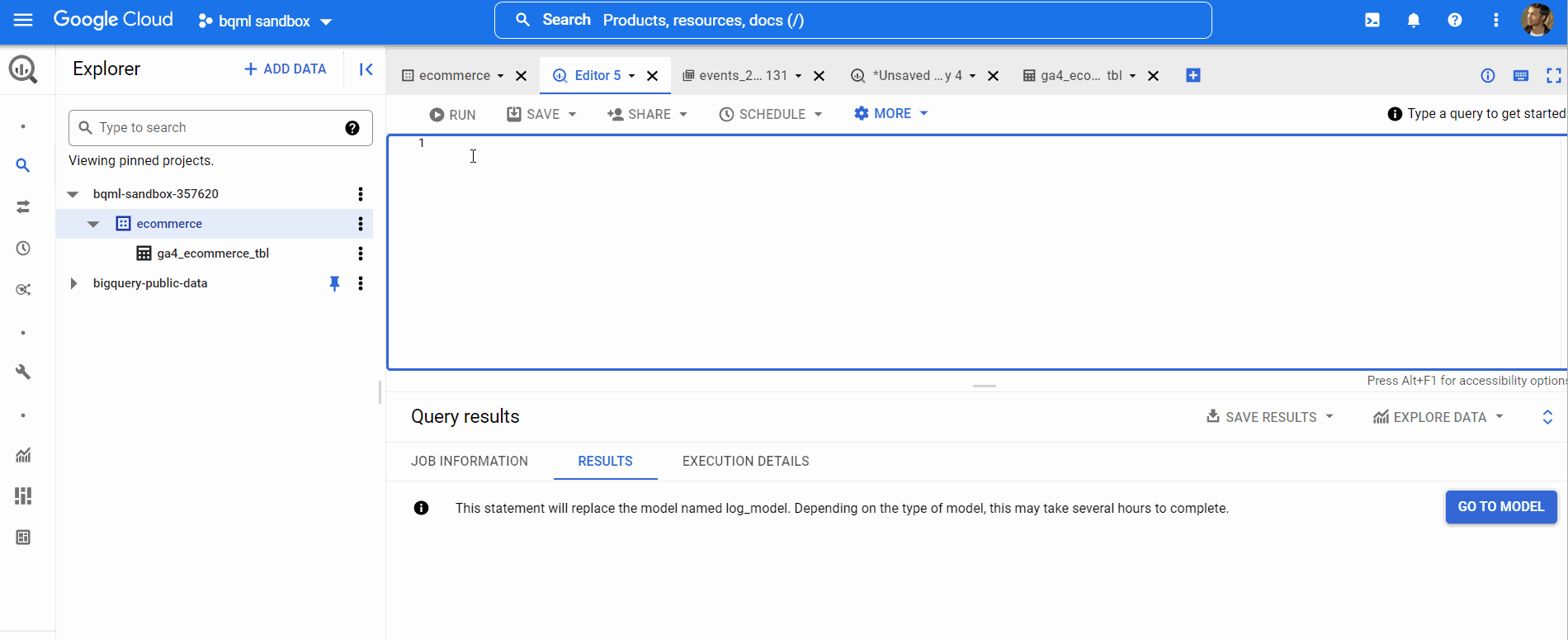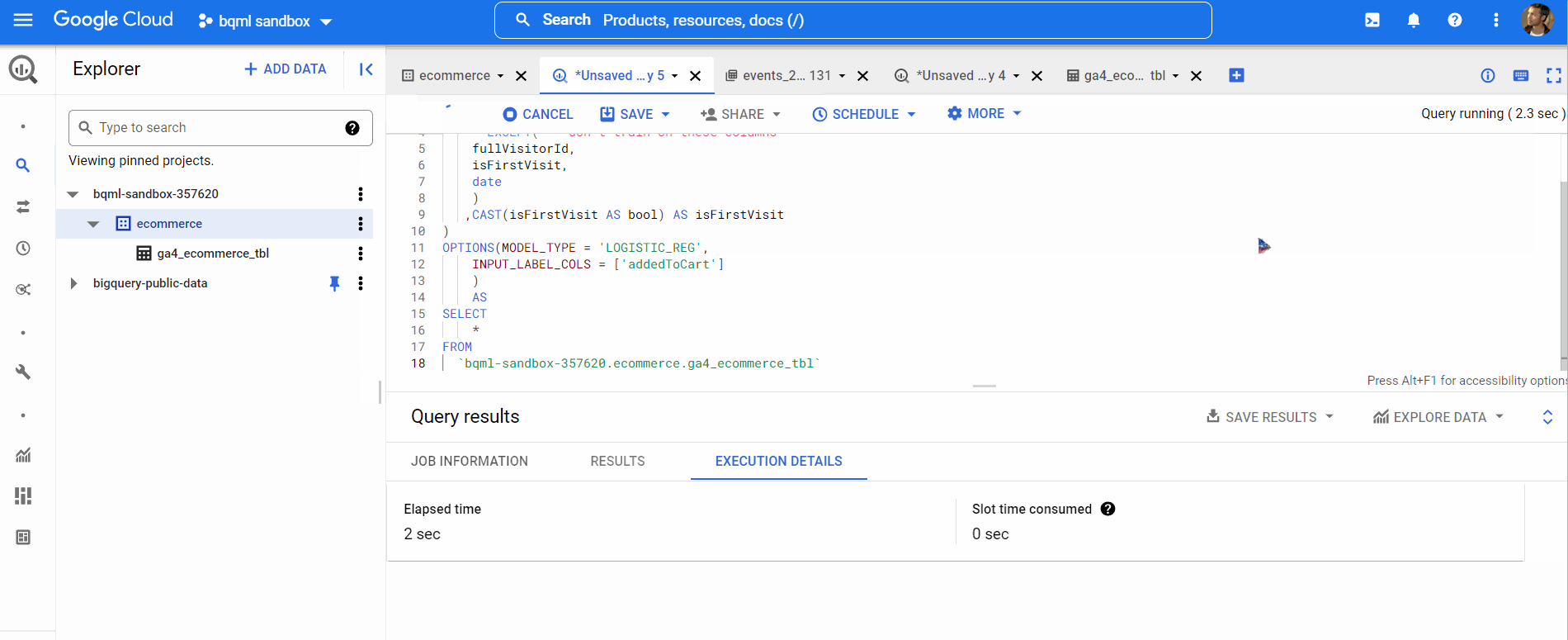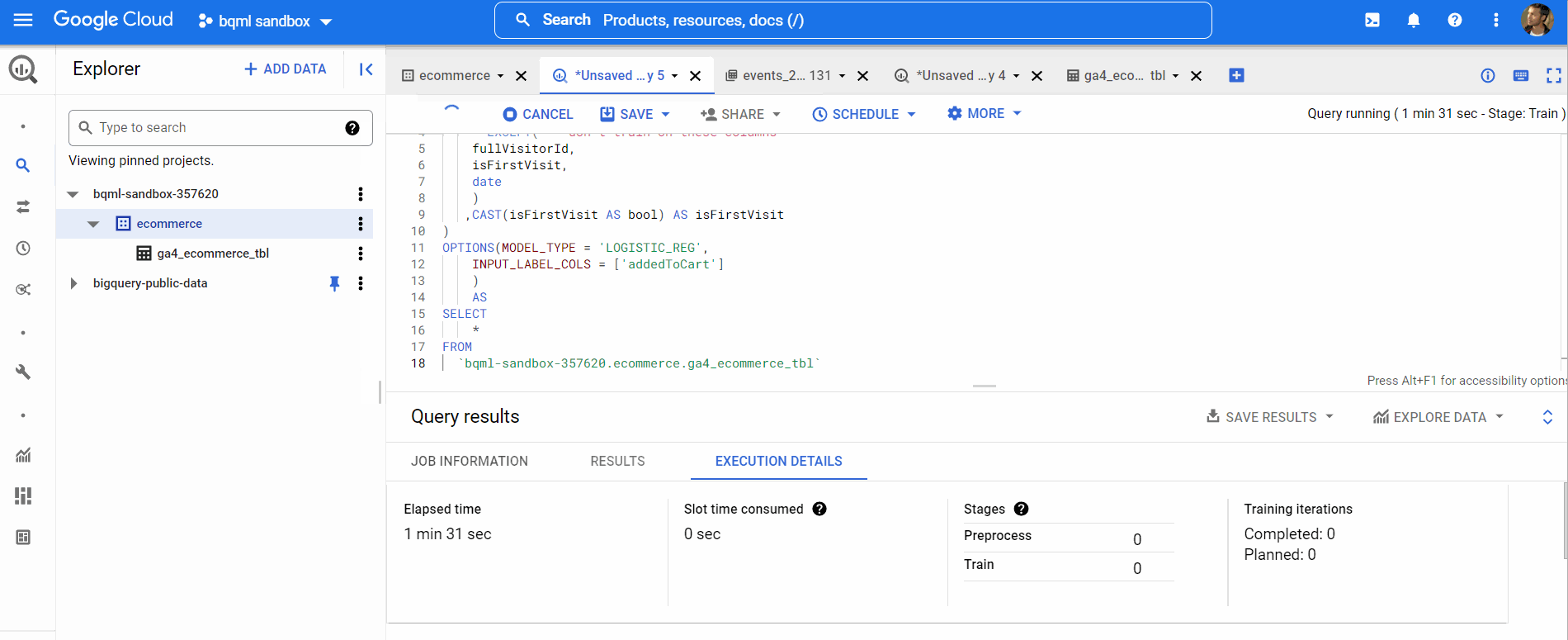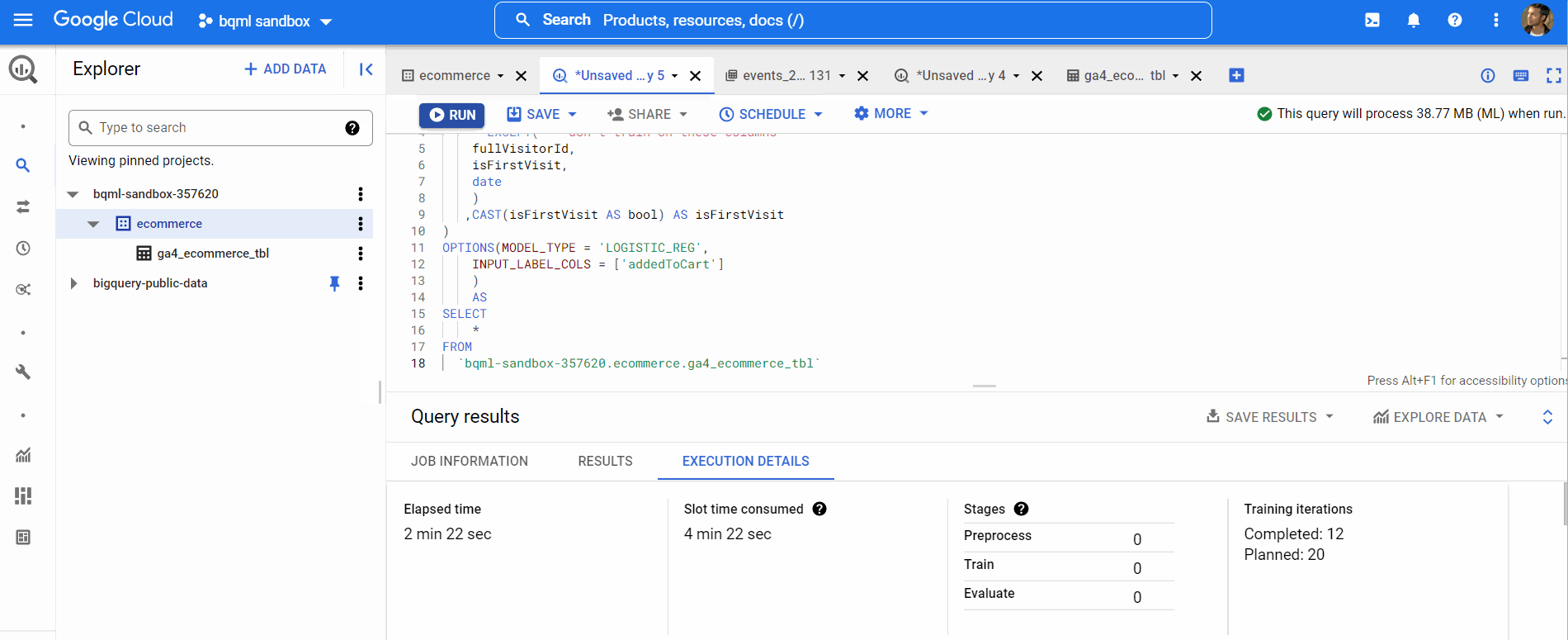 Now, our model has been trained. We can view the model performance by clicking on the GO TO MODEL button like below,
Now, our model has been trained. We can view the model performance by clicking on the GO TO MODEL button like below,
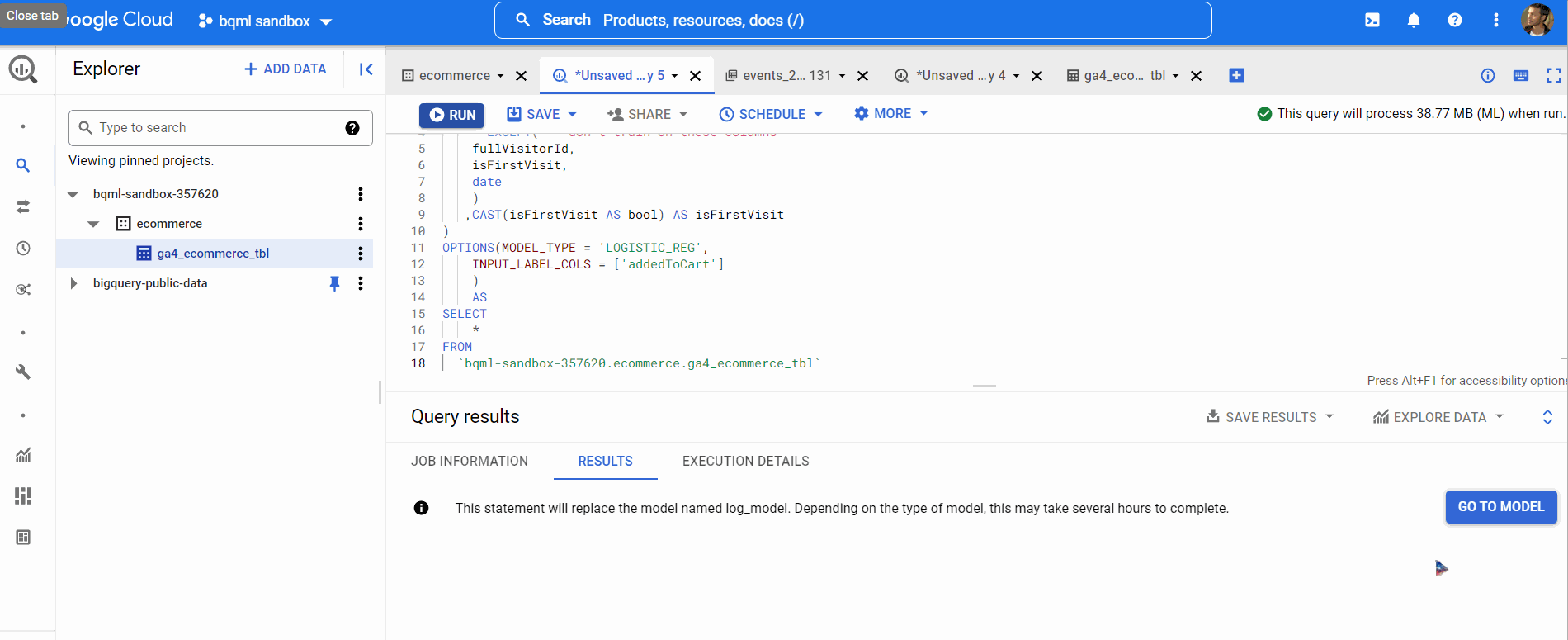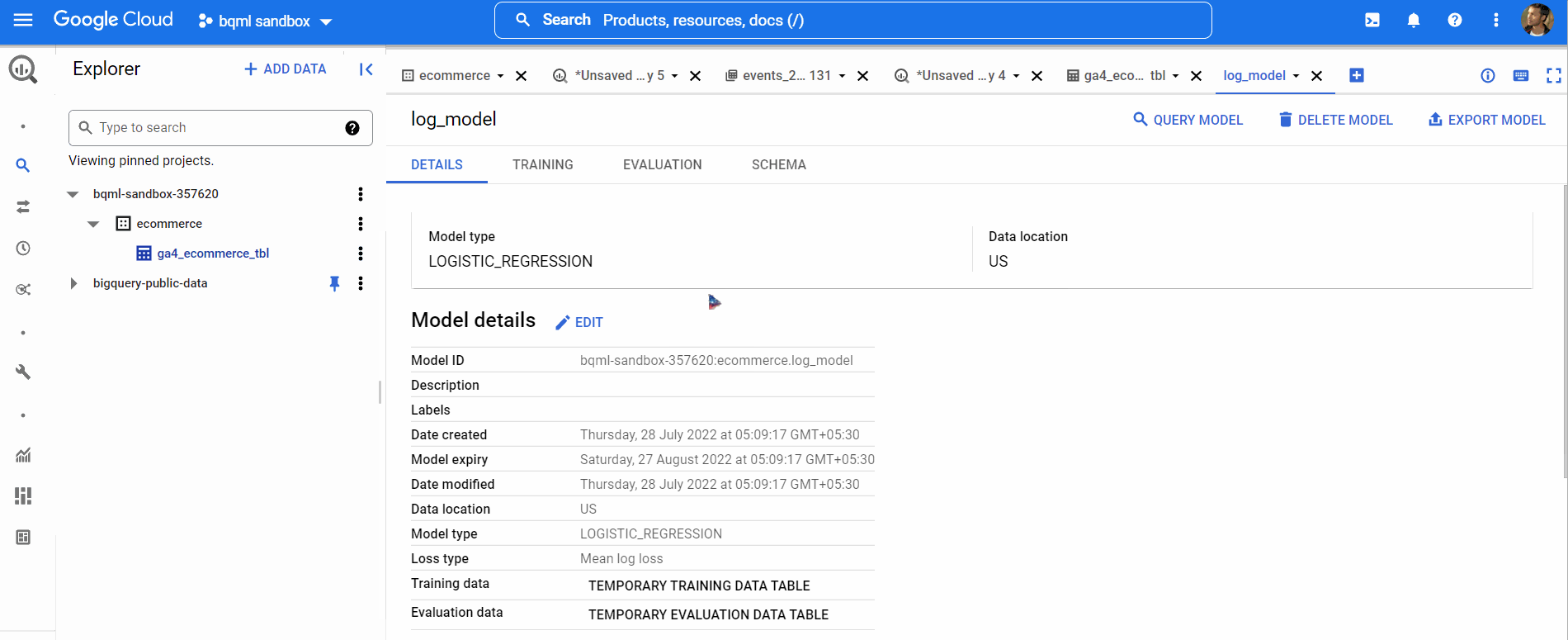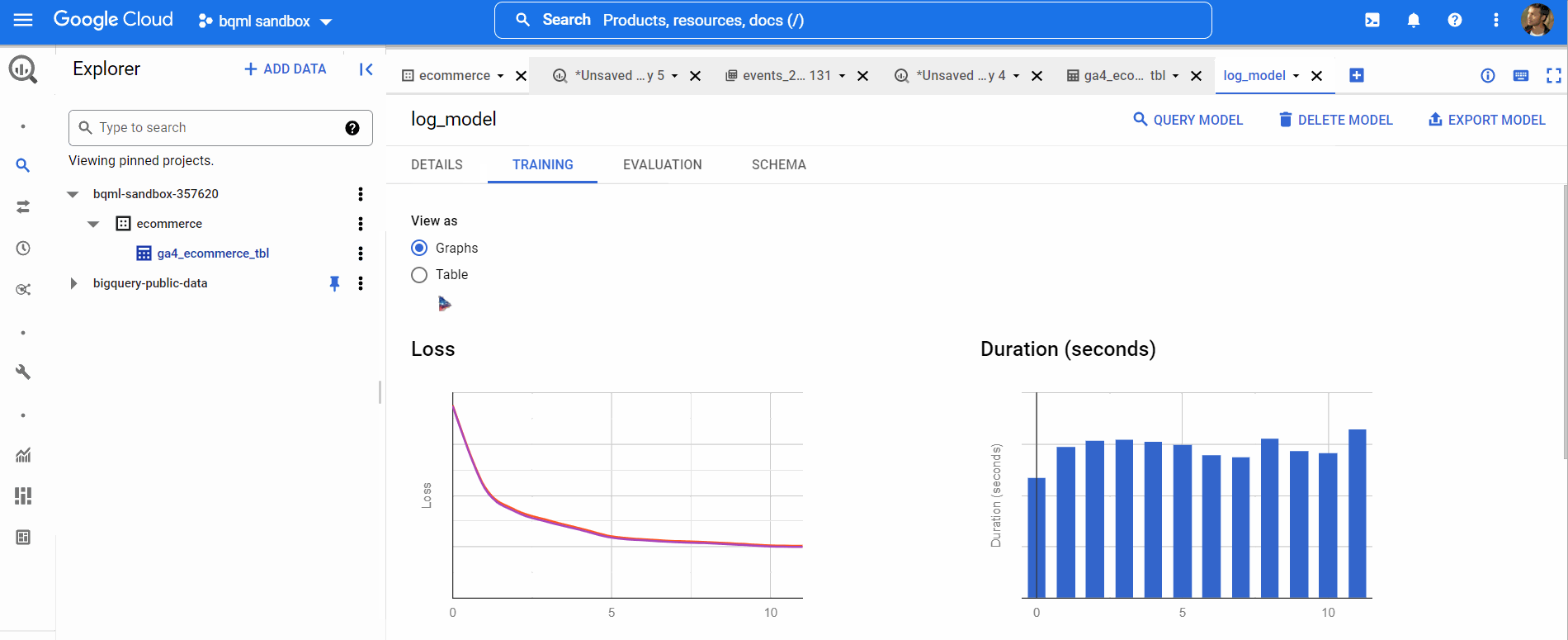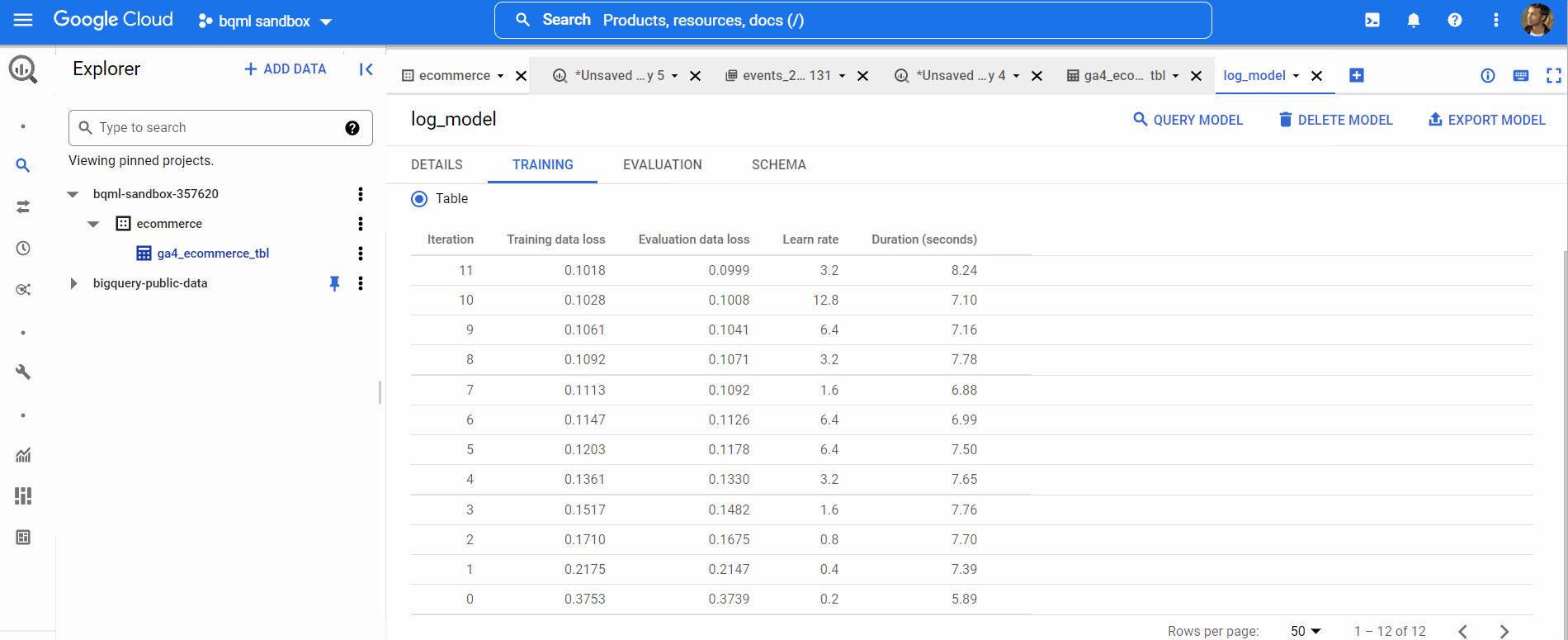
Now, it’s time for us to predict using our model. We’ve used data from 2020 to train our model. We will use data from Jan 2021 to predict. So, we’ll create a new table ga4_ecommerce_prediction_tbl using this query with the data from January’21.
Below is the query to make a prediction,
Added here
Query to make a prediction,
(log_model_predict.sql)
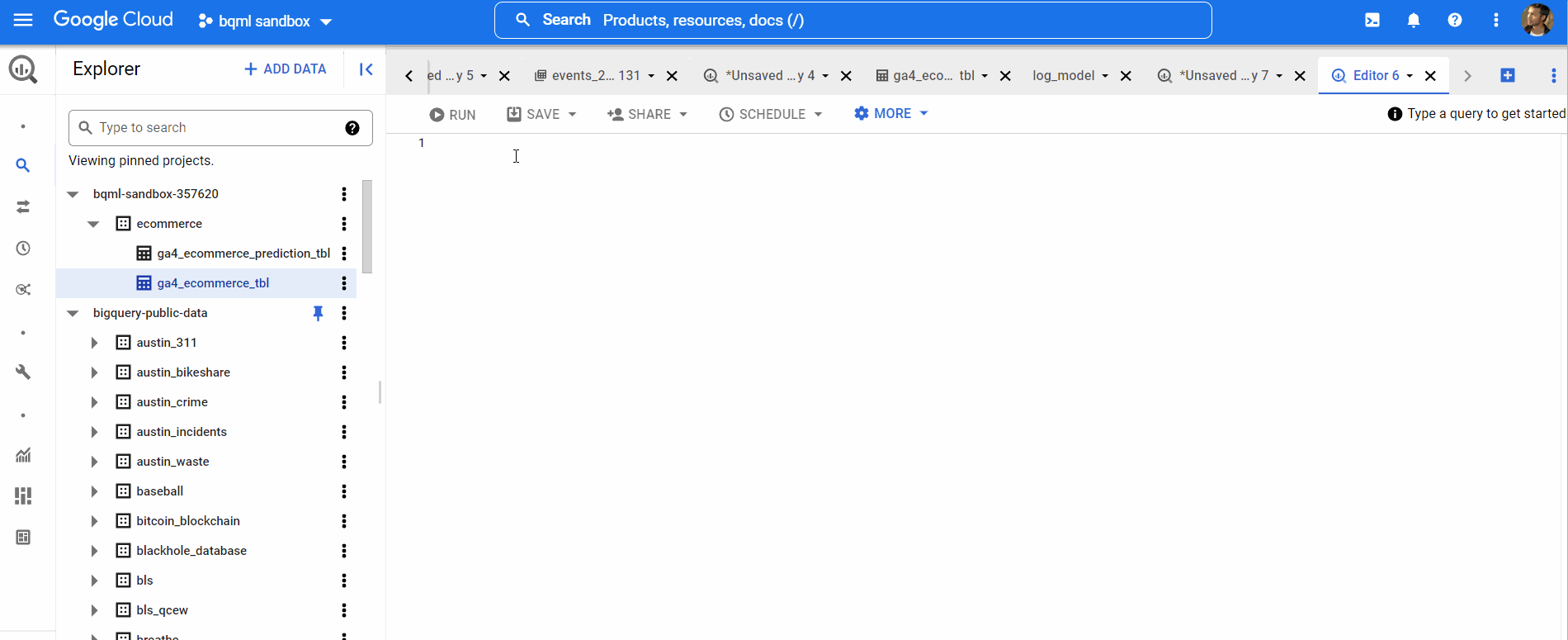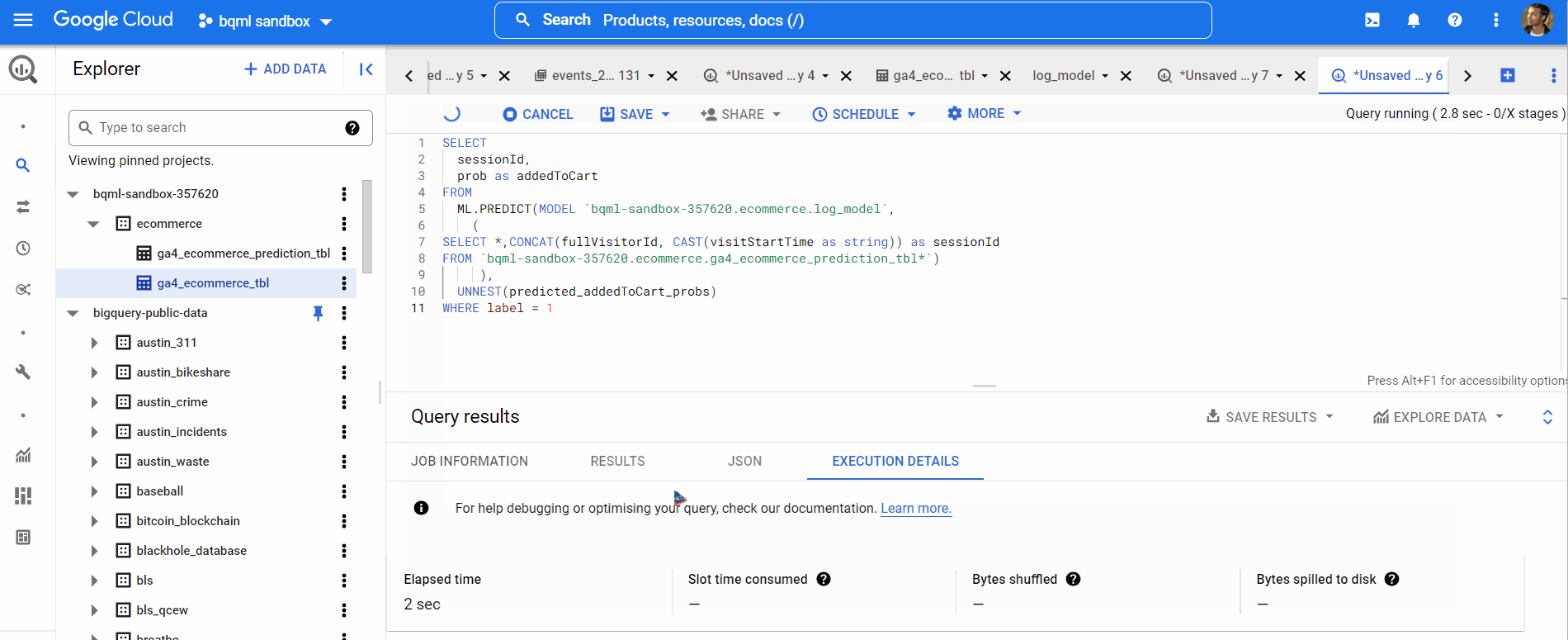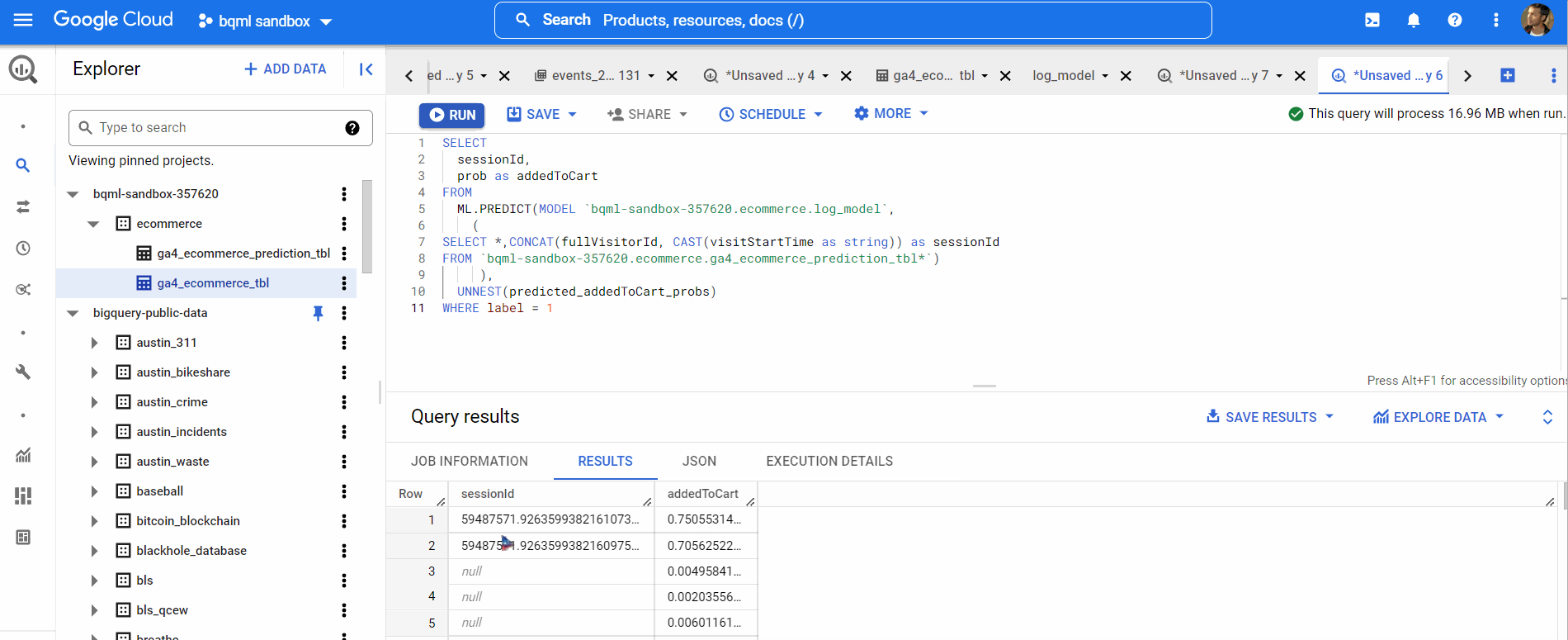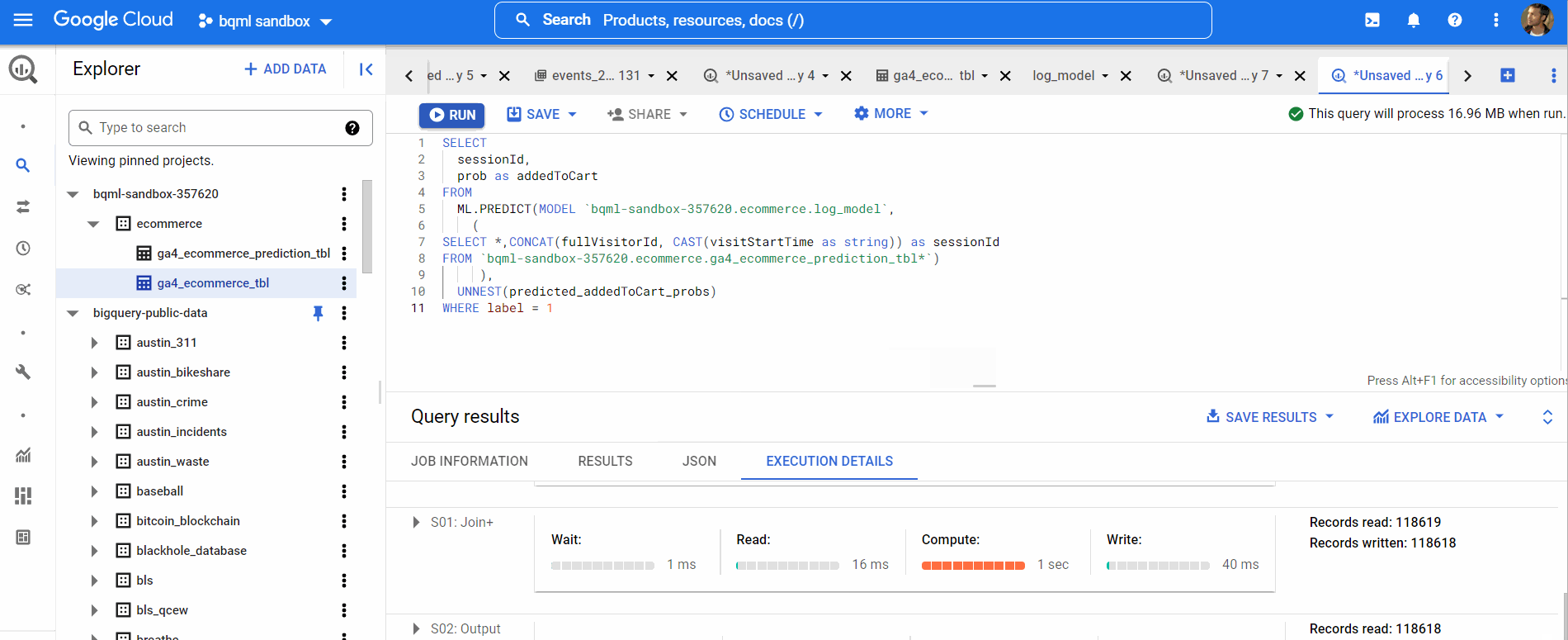
We can also evaluate our prediction using this query below,
.png)
So, we’ve just created a logistic regression model that can predict the probability of adding an item to a cart event with an accuracy of 93%. Though this is a base model, many advanced techniques are available to tune our model in BQML, but we can add that as a future scope.
When to use BQML?
We’ve just seen how powerful BigQuery’s toolkit is. But still, it has several limitations and shortcomings which restrict BQ for general use in ML. One should choose BQML for any of the below cases-
- When the dataset is too big to read into local memory or when there are other constraints on adding the dataset to local.
- When we need to serve the model directly afterward training. Because the model is in the same location as our data, we can make predictions directly from the database, eliminating the need for code writing, unit testing, and explicitly deploying into production.
- When we have a team of several languages, such as Python and R, SQL is undoubtedly the common field for all.
Conclusion
We’ve given a brief introduction to BigQuery ML. In this article, we’ve covered,
- What is BigQuery, and how does BQ manage to query terra bytes of data within seconds?
- Pricing and Currently Supported models in BQML.
- How ML in BigQuery differentiates from traditional ML and when to use BQML.
- Steps to build a logistic regression model in BQML from scratch can predict the probability of adding an item to the cart.
I hope this article was as straightforward and interactive as possible and that it inspired you to explore BigQuery for ML. If you have any suggestions or corrections, please let me know.
I’d love to connect with you via LinkedIn.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.






very informative blog, this will help me in future