This article was published as a part of the Data Science Blogathon.
Introduction
Regarding data analytics, getting insights from a data mart instead of a data warehouse or external data sources can save companies time and produce more targeted results. The idea of data marts is not new – they’ve been around for at least a decade – traditionally, these data marts have been built in-house to bridge data warehouses and analytics. But as organizations collect more and more data, it’s increasingly important to access smaller datasets and gain insights. It’s time to start looking at how the data mart can be better used and, importantly, what the next generation of data marts are. Power to bring
Unlike a data warehouse that stores enterprise-wide data, a data mart contains information related to a specific department or subject area. For example, a sales data mart might contain data related only to products, clients, and sales.
.png)
What is Data Mart?
A data mart is a small part of a data warehouse mainly related to a specific business domain, such as marketing (or) sales. The data stored in a DW system is huge, so data marts are designed with a subset of data that belongs to individual departments. A specific group of users can thus easily use this data for their analysis. Unlike a data warehouse, which has many combinations of users, each data mart will have a specific set of end users. Fewer end users lead to better response time.
Data marts are also accessible to business intelligence (BI) tools. Data marketplaces do not contain duplicate (or) unused data. They are updated at regular intervals. They are industry-oriented and flexible databases. Each team has the right to develop and maintain its data mart without modifying the data warehouse (or) other data marts. A data mart is more suitable for small businesses because it costs much less than a data warehouse system. The time required to build it is also less than the time required to build a data warehouse.
A visual representation of multiple data markets:
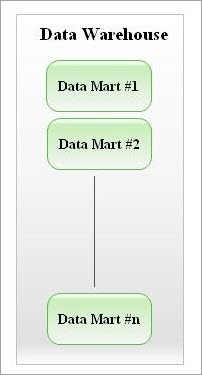
Source – https://en.wikipedia.org/wiki/Data_mart
When do we need a Data Mart?
As needed, plan and design a data mart for your department by involving stakeholders, as operating costs for a data mart can sometimes be high.
Consider the reasons below for building a data marketplace:
• If you want to partition data using a user access control strategy set.
• If a certain department wants to see query results much faster than scanning large DW data.
• If the department wants the data to be built on other hardware (or) software platforms.
• If the department wants the data to be designed suitably for its tools.
Cost-effective Data Mart
A cost-effective data marketplace can be built using the following steps:
• Identify functional divisions: Divide the organization’s data into data specific to each data mart (department) to meet its requirements without any additional organizational dependencies.
•Data marts support all these internal structures without disrupting DW data. One data market can be associated with one tool according to the user’s needs. Data marts can also provide daily updated data for such tools.
• Identify access control issues: If different data segments in a DW system need privacy and should be accessed by a group of authorized users, all such data can be moved to data marts.
Cost of Data Mart
The cost of a data mart can be estimated as follows:
• Hardware and software costs: Any newly added data mart may need additional hardware, software, computing power, network, and disk storage to handle the queries requested by end users. This makes data marting an expensive strategy. Therefore, the budget should be planned precisely.
• Network access: If the data mart location differs from the data warehouse location, all data should be transferred through the data mart loading process. Therefore, a network should be provided to transfer large volumes of data, which can be expensive.
• Time Window Constraints: The time required for the data mart loading process will depend on various factors such as complexity and volumes of data, network capacity, data transfer mechanisms, etc.
Types of Data Marts
Data marketplaces are divided into three types i.e., dependent, independent, and hybrid. This classification is based on how they were populated, i.e., which can be a data warehouse and other data sources. Extraction, transformation, and transport (ETT) is used to populate data marts with data from any source system.
Let’s look at each type in detail!!
1) Dependent Data Mart
A dependent data mart obtains data from the existing data warehouse. This is a top-down approach, as part of the restructured data into the data marketplace is extracted from a centralized data warehouse.
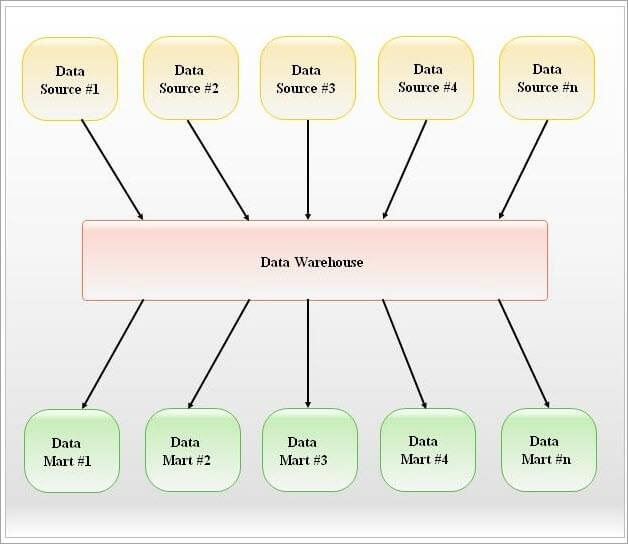
A data mart can use DW data either logically or physically, as shown below:
• Logical view: The data mart is not physically separated from the DW in this scenario. It logically refers to DW data through virtual views (or) tables.
• Physical subset: In this scenario, the data mart is physically separated from the DW.
Once one or more data marts are developed, you can allow users to access only the data marts (or) access both data marts and data warehouses.
ETT is a simplified process for dependent data marts, as usable data already exists in a centralized DW. The same set of summary data should only be moved to the appropriate data marts.
The Dependent Data Mart image is shown below:
2) Independent Data Mart
An independent data mart is best suited for small departments in an organization. Here, the data does not come from an existing data warehouse. The independent data market is not dependent on the enterprise DW or other data markets.
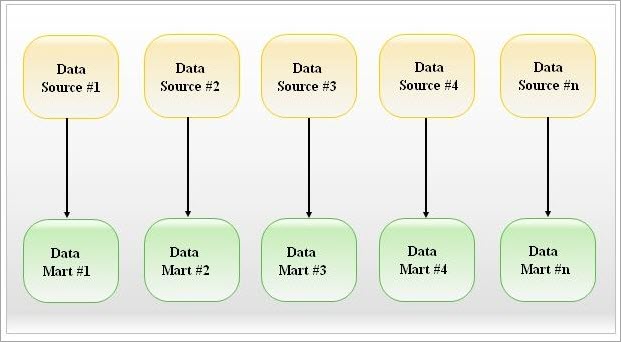
Source – https://www.javatpoint.com/data-warehouse-what-is-data-mart
Independent data marts are self-contained systems that extract, transform, and load data from external (or) internal data sources. These are easy to design and maintain as long as they support the simple business needs of the department.
With each stage of the ETT process, you have to work in the case of independent data marts similarly, as the data was processed into a centralized DW. However, the number of resources and data populated by data marts may be smaller.
Pictorial representation of Independent Data Mart:
3) Hybrid Data Mart
In a hybrid data market, data is integrated from both DW and other operating systems. These are flexible and have a big storage unit. It can also link to other data marts.
Visual representation of the Hybrid Data Mart:
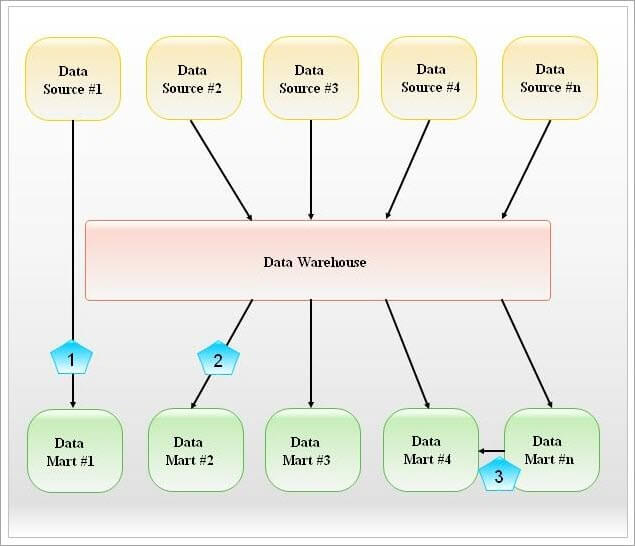
Image Source – https://www.javatpoint.com
Data Mart Implementation Steps
The Data Mart implementation, which is considered a bit complex, is explained in the following steps:
• Design: Since business users require a data mart, the design phase involves gathering requirements, creating appropriate data from appropriate data sources, and creating logical and physical data structures and ER diagrams.
• Construction: The team will design all the tables, views, indexes, etc., in the data mart system.
• Populating: Data will be extracted, transformed, and loaded into the data mart with metadata.
• Access: Data Marketplace data can be accessed by end users. They can query data for their analytics and reports.
• Administration: Includes various management tasks such as controlling user access, fine-tuning data mart performance, maintaining existing data marts, and creating mart recovery scenarios in case of system failure.
Structure of the Data Market
The structure of each data marketplace is created according to the requirements. Data mart structures are called star connections. This structure will vary from data market to data market.
Star joins are multidimensional structures comprising fact tables and dimensions to support large amounts of data. A star join will have a fact table in the middle surrounded by dimension tables.
The relevant fact table data is linked to the dimension table data with a foreign key reference. 20-30 dimensional tables can surround a fact table.
Similar to the DW system, the fact tables contain only numerical data in star connections, and the relevant textual data can be described in dimension tables. This structure resembles the star scheme in DW.
A pictorial representation of the structure of a star connection.
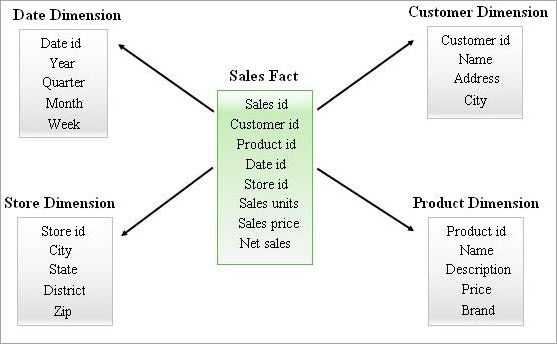
Source – https://en.wikipedia.org/wiki/Data_mart
But granular data from a centralized DW is the foundation for any data mart. Many calculations will be done on the normalized DW data to convert it into multidimensional data marts that are stored in the form of cubes.
It works similarly to how data from legacy source systems are transformed into normalized DW data.
When is a pilot data market useful?
A pilot project can be deployed in a small environment with a limited number of users to ensure the deployment is successful before a full deployment. However, this is not always essential. Once the purpose is served, the pilot deployments will be useless.
You must consider the scenarios below that they recommend for pilot deployment:
• If end users are new to the data warehouse system.
• If end users want to feel comfortable getting data/reports before going into production.
• If end users want hands-on use of the latest tools (or) technologies.
• If management wants to see benefits as a proof of concept before doing it as a major release.
• If the team wants to ensure that all ETL components (or) infrastructure components work well before release.
Disadvantages of Data Mart
Although data marketplaces have some advantages over DW, they also have some disadvantages, as explained below:
• Junk data marts that have been created are difficult to maintain.
• Data marketplaces are designed for the needs of small businesses. Increasing the size of data marts will reduce their performance.
• If you are creating many data marts, management should take proper care of their versioning, security, and performance.
• Data marts can contain historical (or) aggregate (or) granular data. However, due to data inconsistency, DW data and data mart data may not be updated simultaneously.
Conclusion
Many organizations are turning to data marts for cost savings. Therefore, this tutorial focused on the technical aspects of it in a data warehouse system. A data mart is more suitable for small businesses because it costs much less than a data warehouse system. The time required to build it is also less than the time required to build a data warehouse.
- Data marketplaces are divided into three types i.e., dependent, independent, and hybrid. This classification is based on how they were populated, i.e., which can be a data warehouse and other data sources.
- Star joins are multidimensional structures comprising fact tables and dimensions to support large amounts of data. A star join will have a fact table in the middle surrounded by dimension tables.
- Many calculations will be done on the normalized DW data to convert it into multidimensional data marts that are stored in the form of cubes.
- The Data Mart implementation, considered a bit complex, is explained in the following steps: Design, Construction, Populating, Access, and Administration.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Analyst who love to drive insights by visualizing the data and extracting the knowledge from it. Automating various tasks using python & builds Real time Dashboard's using tech like React and node.js. Capable of Creaking complex SQL queries to fetch the accurate data.





