This article was published as a part of the Data Science Blogathon.
Introduction
In this article, we attempt to capture the complexity of ETL and workflow orchestration tools, which aid in better data management and control by providing multiple alternatives for performing various operations in discrete blocks while maintaining visibility and clear goals for each action.
We’ll continue by gaining knowledge of how ETL operates, outlining the roles each of its steps plays, using examples to illustrate some of its use cases, and outlining their functionality. We’ll look at ETL tools in more detail below, along with how their features can be used to handle data better and adapt tasks for such data.
What is ETL?
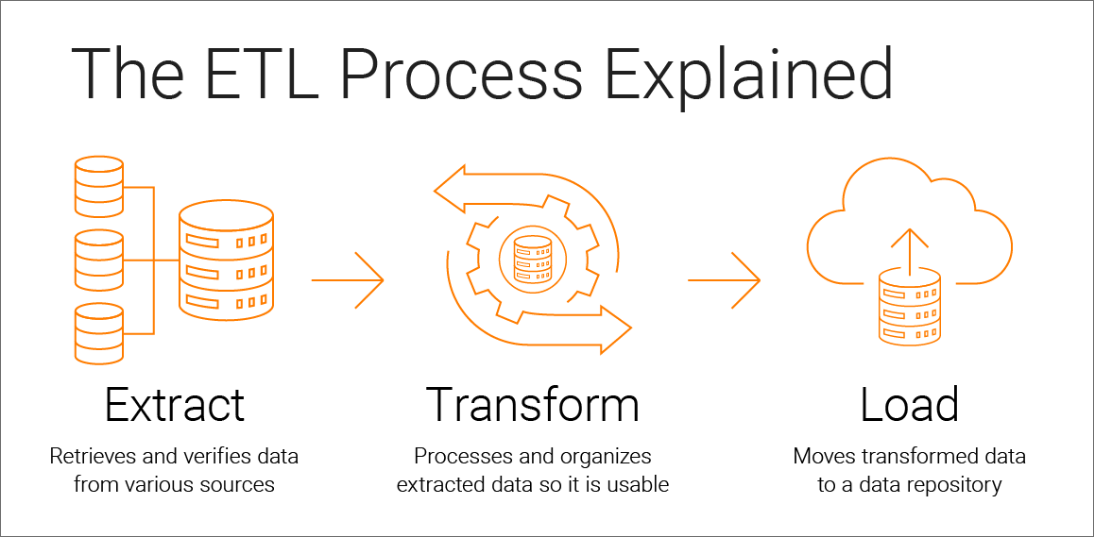
The term “ETL” (Extract Transform Load) is used when data-related operations, including data retrieval, pre-/post-processing and its storage in a reusable format, and many other common functions applied to data to manipulate it, are integrated to form a close end-to-end process, where raw data turns into useful processed data.
Extraction
This is the first phase where raw data in many formats like image, audio, and historical data are retrieved from large multiple storages (Google Cloud Storage, AWS s3 buckets, flat files, and several other RDBMS databases) and preprocessed to create useful data.
Transform
The data from the extraction process is then run through multiple operations like fixing data types, removing unwanted attributes, joining, and splitting. Towards the end of all these operations, we have produced usable data sent off to be stored in large warehouses(Snowflake, BigQuery, Redshift) or similar storage.
Load
The newly modified data must be saved in a format that may be used again. Anytime new information is added, the existing data can be updated. It may be carried out at regular intervals or anytime new client data is received, or data is generated.
https://www.informatica.com/content/dam/informatica-com/en/images/misc/etl-process-explained-diagram.png
ETL Pipelines
A phrase for tasks completed in a predetermined sequence is a pipeline. Data transformation is accomplished using predetermined processes in the ETL pipelines. Pipelines cover all operations applied to data to change it before it is transferred to the next tasks in the pipeline.
Here are a few useful examples for ETL operations if you’re wondering where they get to be used regularly:
1. Construct incoming raw data for model training
After retrieving the raw data from the Data Lake that was produced by the customers, cleaning and prepping the data and transforming photos by using transformations like resizing and cropping, and ultimately exporting it in the required format that can later be utilized for model retraining.
2. User Analytics and pattern recognition
Extract historical data from massive data storage systems like Google Cloud Storage or storage buckets. Employing BigQuery and SQL-based querying tools.
Following processing, this data is supplied into analytical and visualization programmes like Power BI or Tableau. It can be combined with Python to perform descriptive analytics, the output of which can be applied to business decisions.
3. Model validation
A model must often be monitored once it is put into production. Frequent runs maintain the model’s accuracy under control, monitor any loss of accuracy, and aid in determining its reason. It could be a pipeline operation, or continuous data drift brought on by the flow of new data in sequence.
4. Pipeline health monitoring
Monitoring and running the pipeline continuously helps us learn how the data changes over time and how to modify the pipeline to adapt to changing data. Users may change tasks and controls by integrating notifications to identify where their pipeline is failing.
5. Hyperparameter searching
ETL and workflow management technologies, like Airflow and Prefect, can be used for use cases outside their primary scope, such as hyperparameter tuning and searching, and dividing data into training, validation, and test sets. It is possible to make tasks difficult enough to prevent data from leaking between sets of data. Using Airflow, hyperparameter tuning and searching may be automated. DAGs can be created to search for and test hyperparameters and then report the findings to the user.
Workflow Orchestration Tools
Workflow orchestration tools are data monitoring and regulating tools that adhere to business rules and orchestration governing rules to help regulate data flow and establish pipelines that transform data through activities assembled into workflows.
Airflow

https://airflow.apache.org/images/feature-image.png
Airflow is an open-source workflow orchestration and management built by the Airbnb tool used in building workflows, which helps make solutions for ETLs.
Airflow can be used with python to prepare tasks and workflows, making it easy for users as most of the ETL processes are preferred to be defined in the python language because of some of its robust libraries like pandas and dask, which play a major role in ETL process using python.
It adheres to a principle known as DAGs (Directed Acyclic Graphs).
Where tasks are mapped in a graph that follows an order or direction indicating which task should be executed next.
These tasks can be made independent or dependent on other tasks, where the outcome of one task enables the execution of the tasks that depend on it, and vice versa if the dependent tasks are unsuccessful.
The biggest advantage of tools like airflow is they allow users to control their workflows.
Tasks are individual functions that perform a specific set of work defined by the user.
Below is a code snippet of what a task in a workflow looks like.
Workflows: Workflows are a group of tasks with a defined execution order. These appear in the form of DAGs when visualized in the airflow interface.
Below is a figure showing how workflow tasks in a graph view look.

Airflow includes features like logging and monitoring tasks; it allows users to schedule their workflows when desired. They provide operators as a template for defining a task.
Some operators are :
BashOperator – used to execute a bash command
PythonOperator – used to call a python function
DummyOperator/EmptyOperator – acts as a dummy or empty task which does not do any operation.
Sample code snippet showing how to define dummy operator tasks and setup workflow.
Workflow scheduler
A scheduler offered by Airflow enables customers to keep track of all of their DAGs and alerts them when their dependencies are met. It offers the choice of scheduling a run for a later time.
The presets provided by airflow, such as @monthly, @daily, @once, and @hourly, can be used to establish schedules, or you can use cron patterns to set your time interval.
Simply include the start date option in the default args to configure a workflow with a scheduler, and your workflow will then be a scheduled workflow.
Airflow UI: The airflow UI allows us to monitor our running activities and perform workflows by clicking run on the flows on the DAG’s page. Any DAGs that are registered appear on the DAG’s page under the name of the workflow name supplied in the DAG’s initialization phase in the script.
Prefect
https://www.prefect.io/images/prefect_v2.jpg
Prefect is a recent workflow orchestration and data flow control tool that competes with Apache Airflow. It includes a cloud solution for monitoring workflows and managing deployments and an enhanced and easier user interface.
To improve task and workflow performance, Prefect can be paired with Dask, which works in distributed environments. Dask-powered ETL pipelines can be made more scalable and resource-distributed.
Tasks are distinct functions the user defines to conduct any operation or transformation on the incoming data. To better comprehend logs in the event of an error, keep your tasks basic and avoid cramming too many functions or operations into a single task. In the case of several processes, construct distinct tasks to make monitoring and viewing logs for simple activities easier.
Below is a code snippet showing how to set up a basic task:
Task runner
- Prefect provides task runners where tasks can be run sequentially or concurrently.
- SequentialTaskRunner allows running your tasks sequentially, one after the other.
- ConcurrentTaskRunner allows running tasks concurrently, where tasks can be switched depending on the IO.
- DaskTaskRunner can use dask. Distributed to execute tasks that need parallel execution.
Flows
- Flows are a combination of tasks grouped under one entity called a flow to control their execution.
- Below is a code snippet that shows how to define a task, add it under a flow, and register the flow by giving it a name. This name is used to uniquely identify the flow in the prefect UI.
- Prefect collaborates closely with Dask to improve the performance of each task by providing the opportunity to run them concurrently.
- Dask manages the execution of Prefect workflows in a distributed environment, unlike Apache Airflow, which relies on its scheduling system.
- Prefect includes several distinguishing features that are not seen in other workflow engines.
- Prefect supports parameterized workflows, dynamic mapping of workflow tasks during runtime, and flexibility in execution logic.
- This is something that prefect has been integrated with, which other workflow orchestration engines do not specify.
Conclusion
ETL is a critical component of any company that deals with large amounts of data. It aids in data organization and data cleanliness.
Regular intervals of ETL pipelines may be utilized to create data to train models and identify trends or anomalies, which helps in decision making. It diversifies data distribution and gives us greater control over the data and the altering methods we apply to it.
Workflow orchestration tools like airflow and perfect, which leverage the advantages of concepts like DAGs and scheduling, make it easier for us to control the data and task flow. Help us in logging to understand what happens in each task and lets us monitor their outcomes.
With tools like these coming with communication integrations like email, slack, or other methods of notifying, it effortlessly saves time. It allows for careful and impactful adjustments to be made to the already constructed pipeline.
Below are some of the key takeaways:
1. Simple overlook of ETL and its phases.
2. Discover some use cases where ETL comes into the picture and how it helps.
4. ETL and workflow orchestration tools help maintain data and its sanitation.
3. How Apache Airflow can be used to set up workflows and leverage its advantages of job scheduling to set workflows to run at a future date.
4. Prefect with its comfortable UI and easy-to-build workflows enable us to deploy pipelines easily and quickly and let us monitor them on the cloud.
5. Features in Prefect which are unique and how they help work in a distributed environment with dask.
I hope you liked my article on ELT and workflow orchestration tools. Share your opinion in the comments below!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
An avid learner and sharer of knowledge. Student and a software engineer(computer vision) , exploring AI and its applications , collaborating and building dynamic solutions with vast day to day use cases. Enjoys going to tech events and meetups meeting like minded people sharing experiences .





