This article was published as a part of the Data Science Blogathon.
Introduction
Earlier, I had introduced basic concepts of Apache Kafka in my blog on Analytics Vidhya(link is available under references). This article introduced concepts involved in Apache Kafka and further built the understanding by using the python API of Kafka to write some simple Producer and Consumer applications. The present article is intended to build upon the learnings in the referenced blog to understand the concept of partitions and consumer groups in Kafka using some Kafka-python. If you are new to Kafka, I would advise you to look at the referenced article first and come back here to build the concepts further. We can consider this article as a sequel to the referenced article as they go hand in hand.
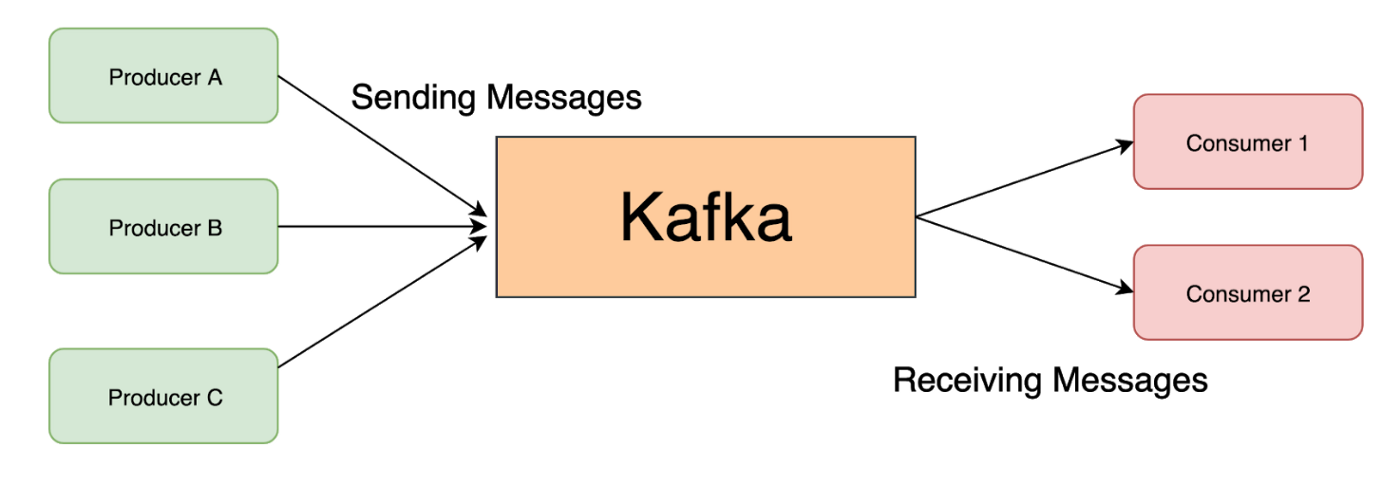
Apache Kafka is an event streaming platform, or we can say that Kafka can handle the transportation of messages across multiple systems/microservices. Apache Kafka is distributed as it relies on multiple servers and is also scalable, where we can start small and add servers per requirement.
Revisiting the Basics
An application called Producer sends a stream of messages(events) to Apache Kafka, and these messages get consumed by an application called Consumer. There could be more than one Producer sending messages to Kafka Cluster; similarly, there could be more than one consumer taking messages from the Kafka Cluster. Producer serializes the objects to byte array and sends them to Kafka, and Consumer deserializes the byte array on the receiving end.
If a Consumer application is interrupted, the Producer will continue working and send messages to Kafka, where the messages are stored. Once the Consumer returns online, it need not start consuming from the beginning and can restart from where it left off as this information (offset) is available in the cluster. The Producer and Consumer are operationally decoupled and work at their own pace. The sequence of messages arriving at the Kafka Cluster is called a Topic. We can have as many topics as it is needed to describe various types of events. In an e-commerce application, user registration can be a topic; another topic can contain user purchase order life cycles, etc.
The messages arriving into a topic are ordered, and their position is identified by a sequence number called offset. The messages are immutable, and if there is a change in a message, this can be achieved only by sending another message. Let’s say we order pizza online, which goes as an event into Kafka. Later we have a change of mind and want to cancel the order. Now the cancellation is generated as a new event and consumed by the relevant consumer applications to update the status. It is also important to note that more than one Consumer can consume messages on a topic for different needs. Suppose we have a pizza order generated as an event. In that case, one consumer application could be for the delivery agent, and another application consuming the same event from that topic could be a payment application.
Partitions and Consumer Groups in Apache Kafka
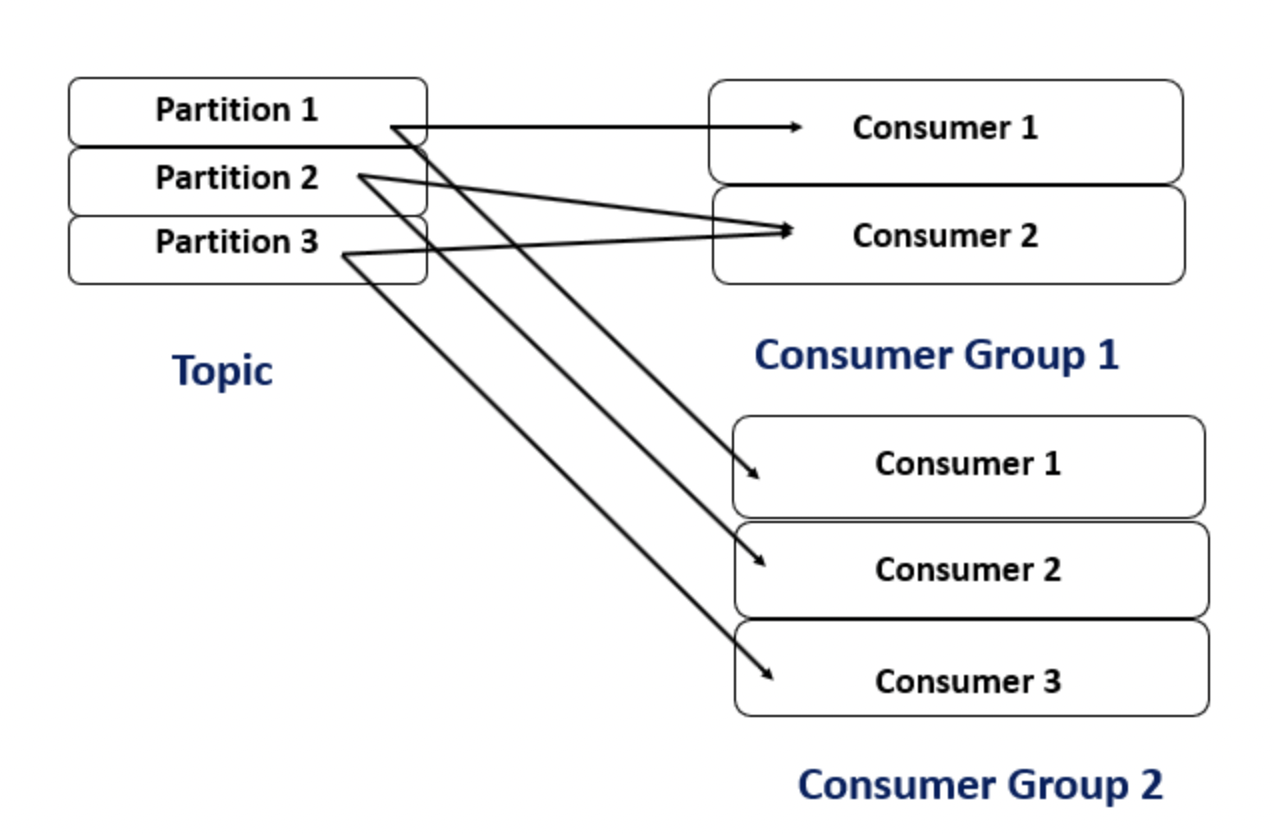
The topics on Apache Kafka Cluster are stored on servers called brokers. The topics are split into multiple pieces and stored across multiple machines. These chunks are called partitions. A Consumer Group is a group of consumers sharing the same group_i . When consumers consume a topic within the same group(having the same group_id), every message will be delivered to only one consumer.
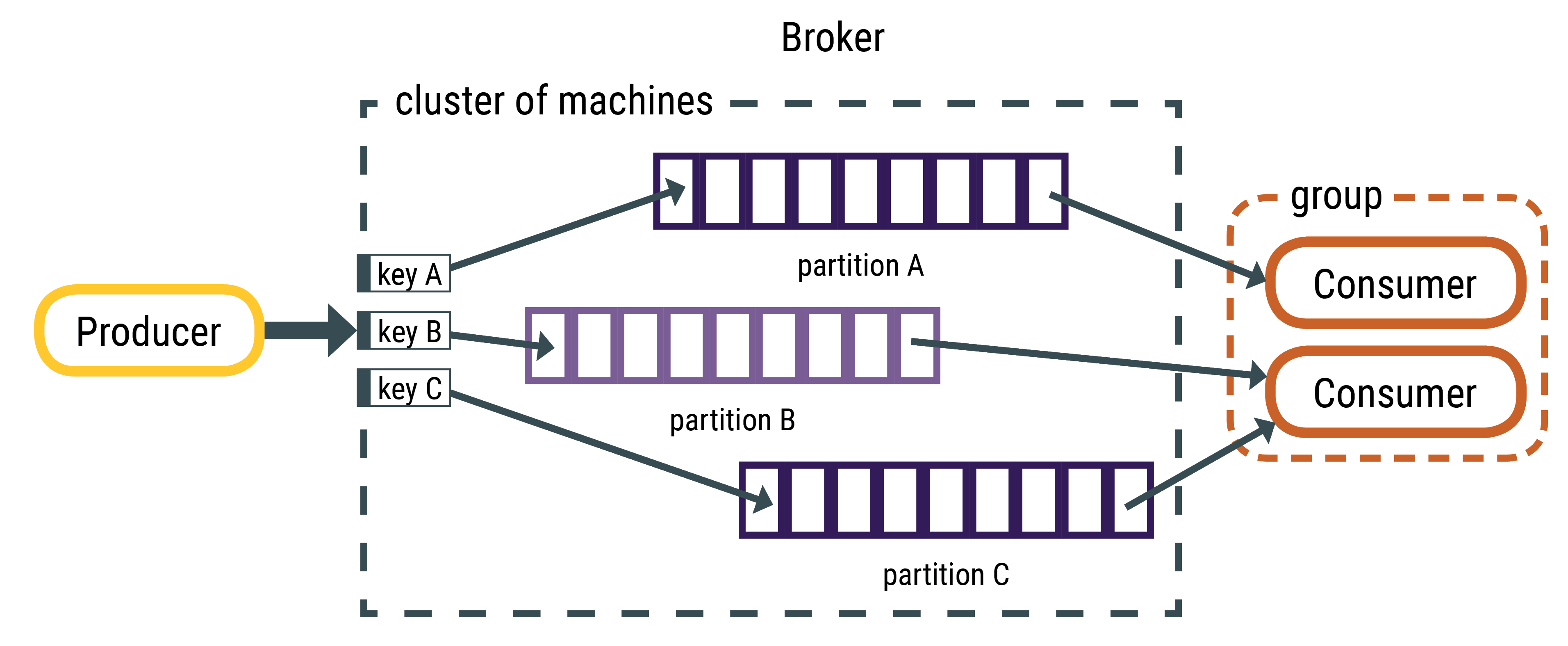
Source: https://docs.datastax.com/en/kafka/doc/kafka/kafkaHowMessages.html
Kafka assigns the partitions of a topic to the consumers in a group so that each partition is assigned to one consumer in the group. This ensures that records are processed in parallel and nobody steps on other consumers’ toes.
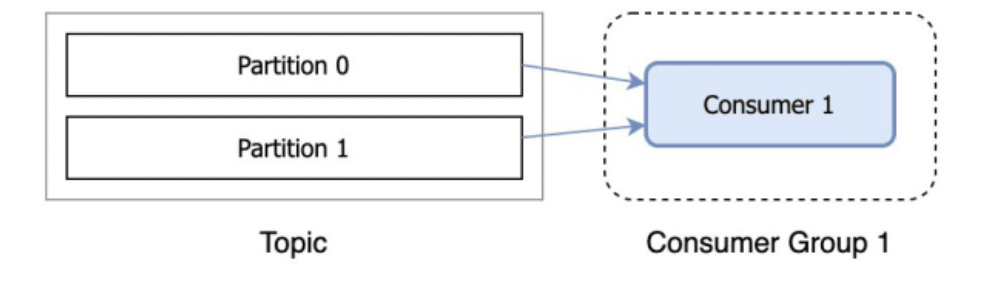
Source: https://dev.to/de_maric/what-is-a-consumer-group-in-kafka-49il
If we have two partitions and only one consumer, the consumer reads from both. On the other hand, if there are two partitions and two consumers, each consumer is assigned one partition. If more consumers are in a group than the number of partitions, extra consumers will sit idle. When a consumer fails, the partitions assigned to it will be reassigned to another consumer in the same group.
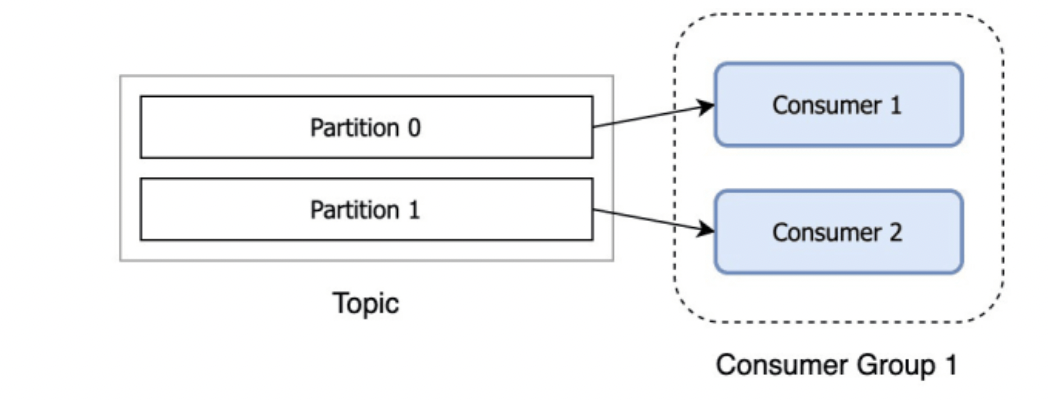
Source: https://dev.to/de_maric/what-is-a-consumer-group-in-kafka-49il
Hands-on Exercise on Apache Kafka
Now that we have visited the basic concepts regarding consumer groups, it is time to cement that understanding with some code. We will use the python API of Apache Kafka to write our Producer and Consumer applications. As practised in my referenced article, I will use Docker-Compose to run Kafka on the local machine. So please ensure that you have Docker and Docker-Compose installed on your machine. A recommended way is to install Docker-Desktop on your machine. Relevant links are placed in the references section. Now, we head over to Terminal, create our Kafka Cluster, and start exploring the subject. First, create a project directory,
mkdir av_kafka cd av_kafka
Create a virtual environment for the project with one of the many available tools (I have used conda ),
conda create --name av_blog conda activate av_blog
This will activate your virtual environment, and use pip install to load Kafka-Python
pip3 install kafka-python
We can confirm the installation of the package using the following command,
pip list | grep apache-kafka
Confirm the installation of docker and docker-compose,
docker --version docker-compose --version

create a docker-compose.YAML file in the project directory with the following contents,
version: '3'services:zookeeper:image: wurstmeister/zookeepercontainer_name: zookeeperports:- "2181:2181"kafka:image: wurstmeister/kafkacontainer_name: kafkaports:- "9092:9092"environment:KAFKA_ADVERTISED_HOST_NAME: localhostKAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
We are using the images wurstmeister/zookeeper and wurstmeister/kafka to run the Kafka services . You must ensure that ports 2181 and 9092 are available in the local machine, or you may have to look at an alternate Port. Zookeeper keeps track of the Kafka Cluster nodes and keeps track of Kafka topics, partitions, etc. We can run the following command to get the docker containers containing our services up and running,
docker-compose up -d
The -d tag will run the command in the background, and the terminal is available for further exploration. Once the command finishes running, check the status of services,
docker-compose ps

We can see Kafka and zookeeper services are running. We can execute command Line Kafka commands by getting into the Kafka container.
docker exec -it kafka /bin/sh cd opt/kafka/bin
The first command will open a new terminal prompt. All the required Kafka bash files are in the opt/kafka/bin folder. Now we can execute Kafka commands
Let’s create a topic called test_topic,
kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 1 --topic test-topic
We can list and describe the topics with the following commands,
kafka-topics.sh --list --zookeeper zookeeper:2181 kafka-topics.sh --describe --zookeeper zookeeper:2181 test-topic
We have created a topic with one partition and one replication factor called test-topic. Use ctrl+c or ctrl+D to quit the docker container. We can write our Producer and Consumer applications to and consume from the topic. The approach we follow is to create different scenarios involving producers, consumers, and consumer groups to understand the concepts involved.
(A) Case 1 ->One Producer and One Consumer
# producer_case1.py
from kafka import KafkaProducer
import json
import time
producer = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('ascii'),
key_serializer=lambda v: json.dumps(v).encode('ascii')
)
topic_name='test-topic'
#send an event(message)
print(f"Sending event to {topic_name}")
producer.send(
topic_name,
key={"id":1},
value={"name":"John", "Item":"Iphone"}
)
time.sleep(3)
producer.flush()
#next messages
print(f"Sending event to {topic_name}")
producer.send(
topic_name,
key={"id":2},
value={"name":"Mary", "Item":"Laptop"}
)
time.sleep(3)
producer.flush()
print(f"Sending event to {topic_name}")
producer.send(
topic_name,
key={"id":3},
value={"name":"Jim", "Item":"Fitness Band"}
)
time.sleep(3)
producer.flush()
print(f"Sending event to {topic_name}")
producer.send(
topic_name,
key={"id":4},
value={"name":"Lisa", "Item":"watch"}
)
time.sleep(3)
producer.flush()
We start by importing a Kafka producer from Kafka and initializing a new Kafka producer. The argument bootstrap_servers = [‘localhost:9092’] sets the Host and Port. We use the send() method to send a couple of messages to the Kafka cluster. The message contains a key and value with the name of a person and the item being ordered by the individual.
from kafka import KafkaConsumer
consumer = KafkaConsumer(bootstrap_servers=['localhost:9092'],
auto_offset_reset='latest',
group_id='my_test_gp')
topic_name='test-topic'
print("Available Kafka topics are ..",consumer.topics())
consumer.subscribe(topics=[topic_name])
consumer.subscription()
for message in consumer:
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))
We import kafka consumer from kafka and initialize a kafkaConsumer . We pass the argument bootstrap_servers as we did for the Producer. The group_id will identify the consumer group for the consumer. The auto_offet_reset parameter indicates where the consumer starts consuming the message in case of a breakdown or interruption. We have used for loop to print the messages received by the consumer and print out the Topic, Partition, Offset, key, and value of each message on the Terminal. We can run the producer and consumer applications from the terminal. It would be advantageous if we could split the terminal window into two separate tiles and watch the execution of the script. I have used an application called iTerm for this on Mac, and I would advise you to check out a similar feature for your system. On one tile, we will run producer; in another, we will run consumer. Run the consumer application first to appreciate the execution of scripts in a better manner.
python consumer_case1.py python producer_case1.py

The output tells us the producer is sending events to Kafka Cluster, and the Consumer application (only one in this case) is consuming in real-time.
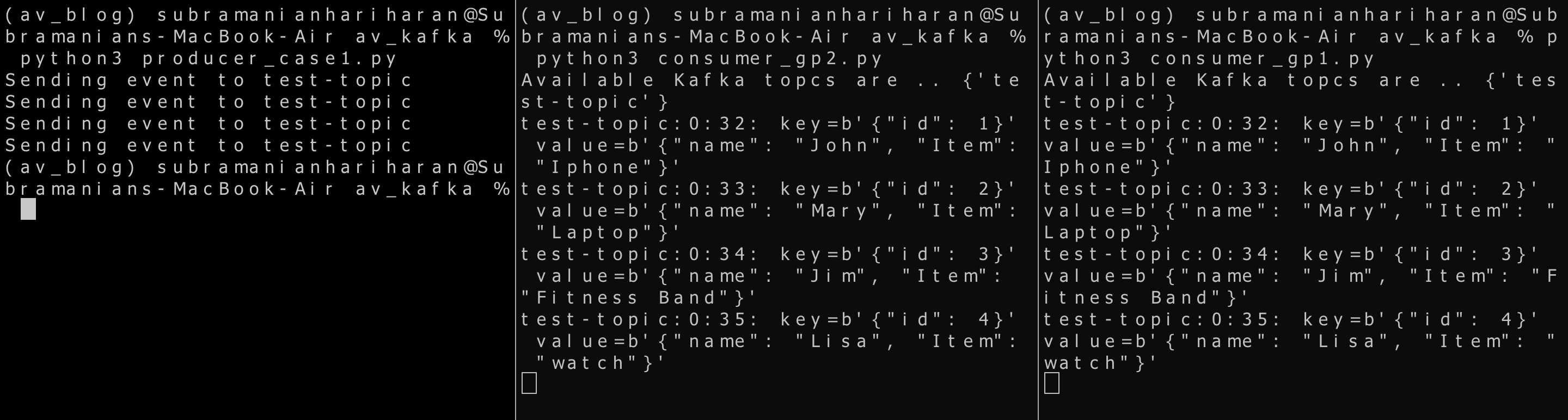
Case 2 -> One producer and two consumers (part of separate consumer groups)
In this scenario, we will explore a case where two consumers are consuming from the same topic. Our producer application code remains the same. create two consumer codes similar to consumer_case1.py. We call the applications consumer_gp1.py and consumer_gp2.py. The only change in the code is the group_id parameter in the Kafka consumer instance for consumer_gp.py is my_test_gp1 and my_test_gp2 for consumer_gp2.py. Consumer applications belong to two consumer groups. In a real-life application, one consumer application may belong to the shipping of item group, and the other may belong to the notification generation group. In this case, we expect both consumers to consume the topic independently. Let’s run the scripts,
python consumer_gp1.py python consumer_gp2.py python producer_case1.py
Case 3 -> One producer, two consumers (part of the same consumer group ), and a topic with one partition.
In this scenario, we will explore the topic with one partition (called 0) and two consumers in the same consumer group consuming from the topic. Our producer application remains the same. Create two consumer applications similar to the above script,
consumer_cg1_1.py. consumer 1 from group_id =’test_group’
consumer_cg1_2.py. consumer 2 from group_id = ‘test_group”
Executing the scripts,
python consumer_cg1_1.py python consumer__cg1_2.py python producer.py
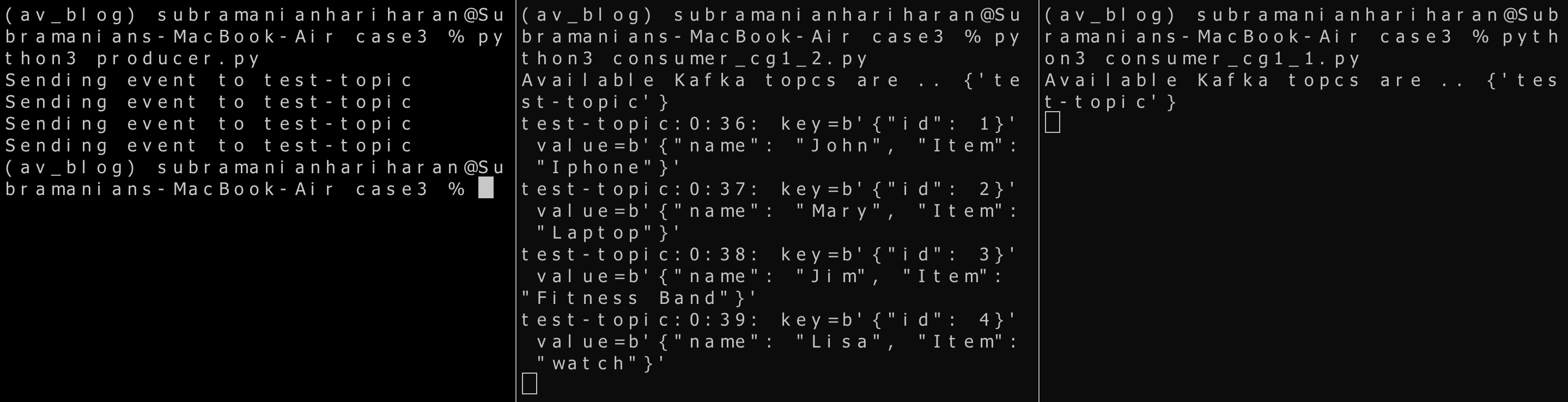
It is seen that only one consumer from the group is consuming the message. There is only one partition hence even though there are two consumers in the consumer group, only one consumer is consuming the messages on the topic, and the other consumer is idle.
Case 4 -> One Producer, a topic with two partitions and two consumers in one consumer group consuming from the topic
In the last scenario, we will try and understand the behavior of the consumers in one consumer group in the Kafka Cluster when there is more than one partition. Let’s create a fresh topic called test-topic-partitioned with two partitions on the terminal inside the docker container as we did initially,
kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 2 --topic test-topic-partitioned
If we list our topics, two topics should show up on the screen,
kafka-topics.sh --list --zookeeper zookeeper:2181
We can check the details of a new topic created using describe flag,
kafka-topics.sh --describe --zookeeper zookeeper:2181 test-topic-partitioned
The display on the screen indicates two partitions(partition 0 and partition 1) in our newly created topic. Let’s first create a producer script called producer_part.py.
We are sending four events to the topic. Please note that topic_name is changed to the newly created topic. For the first two records, in the producer.send() method; we include a parameter partition to send the record to a particular partition. In the last two records, note that we use the same key to send the message. As Kafka will send a particular key to a specific partition, I have excluded the partition parameter in the send() method.
from kafka import KafkaProducer import json import time
producer = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('ascii'),
key_serializer=lambda v: json.dumps(v).encode('ascii')
)
topic_name='test-topic-partitioned'
print("Sending messages to partitions....")
#send an event(message)
producer.send(topic_name,
key={"id":0},
value={"name":"Frank", "Item":"Shoe"},
partition=0
)
producer.send(topic_name,
key={"id":1},
value={"name":"John", "Item":"Shirt"},
partition=1
)
time.sleep(2)
producer.flush()
producer.send(topic_name,
key={"id":0},
value={"name":"Mark", "Item":"Pens"},
)
producer.send(topic_name,
key={"id":1},
value={"name":"Jim", "Item":"Printer"},
)
time.sleep(2)
producer.flush()
Create two consumer applications within the same consumer group called test- group. The scripts are consumer_cg1_p0.py and consumer_cg1_p1.py for application consuming from partition 0 and partition 1, respectively.
from kafka import KafkaConsumer
from kafka import TopicPartition
topic_name='test-topic-partitioned'
group_id = "test-group"
consumer_partition_0 = KafkaConsumer(bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest',
max_poll_records = 10)
print("Available Kafka topcs are ..",consumer_partition_0.topics())
consumer_partition_0.assign([TopicPartition(topic_name, 0)])
consumer_partition_0.subscription()
for message in consumer_partition_0:
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))
#consumer_cg1_p1.py
from kafka import KafkaConsumer
from kafka import TopicPartition
topic_name='test-topic-partitioned'
group_id = "test-group"
consumer_partition_1 = KafkaConsumer(bootstrap_servers=['localhost:9092'],
group_id=group_id,
auto_offset_reset='earliest',
max_poll_records = 10)
print("Available Kafka topcs are ..",consumer_partition_1.topics())
consumer_partition_1.assign([TopicPartition(topic_name, 1)])
consumer_partition_1.subscription()
for message in consumer_partition_1:
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))
Note that topic_name and group_id are the same for both consumers. However, we have assigned partition 0 and 1 to each consumer using the assign() method. We can run the scripts and evaluate the outputs.
python consumer_cg1_p0.py python consumer_cg1_p1.py python producer_part.py

Consumer_cg1_p0.py consumes two records sent to partition 0, and two records produced to partition1 are consumed by consumer_cg1_p1.py.
Conclusion to Apache Kafka
This article explored the concepts related to partition and consumer groups in Apache Kafka using Kafka-python. The key takeaways from this article are as follow:
- Partitions are the way Apache Kafka produces scalability and redundancy
- Multiple consumers can consume a single topic in parallel
- When a consumer group consumes a topic, Kafka ensures that one consumer consumes only one partition from the group
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A Marine Engineering professional with more than 29 years experience with a passion to leverage data for business solutions. I am a post graduate In Mechanical Engineering with experiences ranging from Operations, Production, Project Management, Quality Management and Data Analytics. I have also completed Advanced Certification in Data Science from Thayer School of Engineering , University of Dartmouth. I strongly believe learning is continuous process for growth in life and sharing knowledge builds a sense of community





