This article was published as a part of the Data Science Blogathon.
Introduction
Let’s say you want to create some clusters as fast as possible with less money. What services will you choose? This is when Google Dataproc became the ideal tool that disables clusters when not in use and saves you money and time.
Google Cloud Dataproc is another popular managed service that has the potential to process large datasets, especially those used in Big Data initiatives. It is one of the most preferred Google Cloud public offerings. With Dataproc, you can intend to process, transform and understand huge amounts of data.
 (1).png)
Organizations or businesses can use it to process data from millions of IoT devices and predict business opportunities in sales and production. In addition, organizations can also use it to analyze log files for identity gaps as part of security considerations. Google Cloud Dataproc allows users to create multiple managed clusters that support scaling from 3 to over hundreds of nodes. Creating on-demand clusters and using them during job processing is also possible for users with the Dataproc service. Users can consider shutting down the clusters after completing any particular processing task.
When using Google Cloud Dataproc, you may want to size your clusters depending on your budget constraints, workload, performance requirements, and available resources. Dynamic scaling is permissible even when a task or process is being executed. It is an evolution of managed services that set a new benchmark in data set processing. Therefore, you should understand the in-depth concepts before theming them in your organizational practice. And this article wants to help you with that!
Functional Overview of Google Cloud Dataproc
Google Cloud Dataproc is built on several open-source platforms, including Apache Hadoop, Apache Pig, Apache Spark, and Apache hive. All of these platforms collectively have a different role at Dataproc.
Apache Hadoop supports aspects of distributed processing of large data sets across different clusters. Apache Spark, on the other hand, is a platform that serves as an engine for large-scale and faster data processing. Apache Pig is implemented for analyzing large data sets and Apache Hive provides a storage facility for data and helps with storage management for SQL databases.
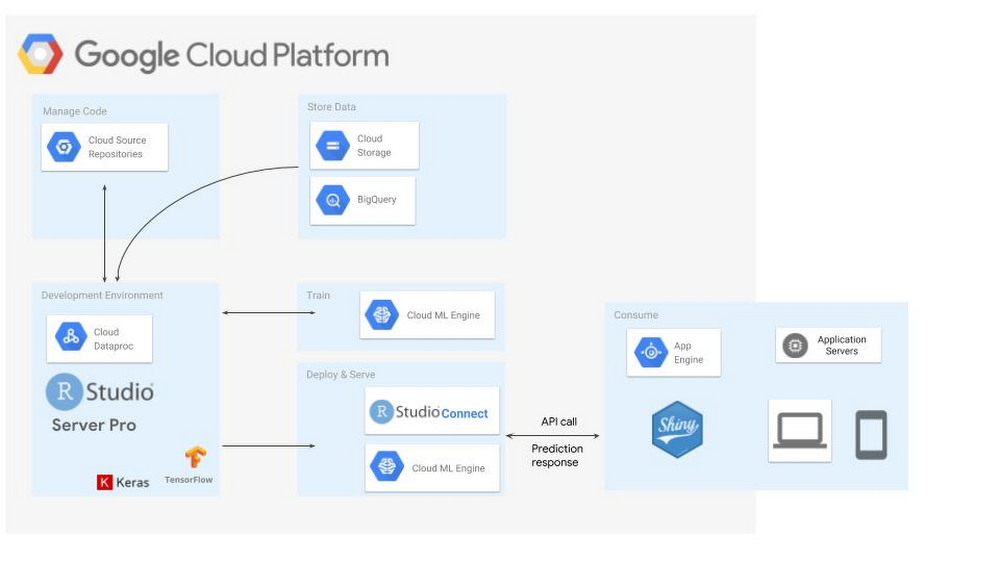
Source: -https://cloud.google.com
Dataproc supports native versions of all these open-source platforms. This means that users are in control of upgrading and using the latest versions of each platform. Not only that, but users also have access to use open-source tools and libraries within the ecosystem.
Google Cloud Dataproc is integrated with other associated services within Google Cloud. Some cloud services that share connected services integration with Dataproc are BigQuery, Bigtable, Google Cloud Storage, Stackdriver Monitoring, and Stackdriver Logging. Organizations and businesses can start creating clusters, managing them, and running tasks using the Google Cloud Platform console. You can also use SDK (Software Development Kit) or REST API to create, manage and run applications.
Cloud Dataproc Prices
The Google Cloud Dataproc pricing and billing depend on the size of the Dataproc clusters and how long they run. The cluster size depends on the total number of virtual CPUs, including worker and master nodes. And the execution time for a cluster is the time between the creation and deletion of the cluster. There is a specific pricing formula for evaluating the invoice amount using Dataproc. The formula is as follows:
$0.016 * number of vCPUs * clock time
The pricing formula calculates the amount at an hourly rate, but Dataproc can also be billed by the second, and increments are always billed per 1 second of tap time. The minimum billing time is, therefore 1 minute. Dataproc usage by users is specified in fractions of hours.
The Dataproc price is in addition to each VM’s price per Compute Engine instance. In addition, additional cloud resources are used for the complete implementation of Google Cloud Dataproc, the fees of which will also include the overall implementation. You can refer to the official Google Cloud Dataproc pricing documentation to learn more about pricing.
Different Kinds of Workflow Templates in Dataproc
Dataproc includes various workflow templates that allow users to perform various tasks workably. The different kinds of workflow templates in Dataproc are:
Source: -https://cloud.google.com
1. Managed cluster
The managed cluster workflow template allows you to create a short-lived cluster to run on-demand or set tasks. And you can easily delete the cluster after the workflow is finished.
2. Cluster Selector
This workflow template specifies any existing clusters on which the workflow jobs can run after specifying user labels. The workflow then intends to run through the clusters that match all other specified labels. Multiple clusters match the labels in this workflow instance, then Dataproc will choose the one with the most available YARN memory to run the workflow tasks. And at the end of completing the workflow task, the cluster is not removed. To learn more about how to use cluster selectors with different workflows, check out this official documentation!
3. Inline
This type of workflow template intends to instantiate workflows using the gcloud command. For the same, you can use YAML files or call Dataproc’s Instantiate Inline API. Embedded work to create or edit workflow template resources! If you need more ideas on using Dataproc inline workflows, then here is the official documentation to enlighten you on the necessary knowledge.
4. Parameterized
This workflow template allows you to perform different values multiple times. And in the process, you can avoid repeatedly modifying the template for multiple runs by setting the parameters in this template. And with this parameter, you can intend to pass different values to the template for each run.
Using workflow templates is of the utmost importance. Workflow templates are used to find automation for specific repetitive tasks. These templates will narrow down frequent task executions or configurations within the workflow and automate the process. In addition, Workflow templates offer support for long-lived and short-lived clusters. The managed cluster template is for a short-lived cluster, while the Cluster Selector template is for a long-lived cluster.
Google Cloud Dataproc: Usage Examples and Best Practices
What b then use cases to explain the effectiveness of Google Cloud? Use cases define the implementation of a cloud service for organizational and business beneToder to explain the basic aspects of Google Cloud Data. You must go through the use cases specific to the service. Use cases include:
1. Workflow planning
As mentioned in the previous section, workflow templates offer a flexible and easy mechanism for managing or executing workflow tasks. They are like reusable configurations for executing workflows! And they usually have graphs of all the jobs to be done. Information about tasks and their duration is set here.
In addition to Dataproc, you can also use Cloud Scheduler for scheduling workflows. It allows you to schedule almost any jobs like Big Data, Batch, or Cloud Infrastructure. Easy to use, with schedules during, hours,y or daily. More information about Cloud Scheduler can be found in this documentation!
2. Using Apache Hive via Cloud Dataproc
When you use Apache Hive over Cloud Dataproc, you can bring maximum flexibility and flexibility to your cluster configuration. Take a customization approach for specific Hive jobs and then scale each one according to your workflow requirements. Hive is an open-source data warehouse that is built on top of Hadoop. It offers a SQL-like query language called HiveQL. Therefore, it is used for the analysis of structured and large datasets.
Must Read: What is Cloud SQ?!
Dataproc is a fairly capable service from Google Cloud that allows running Apache Hadoop and Spark jobs. Dataproc has the potential for its instances to remain stateless; it is still recommended to use Hive data in cloud storage and Hive Meta store in MySQL over Cloud SQL to integrate Apache Hive into Cloud Dataproc.
3. Using custom images in the correct instance
Custom images come into play when you use image versions to pool Big Data components and operating systems. They are used to provision Dataproc clusters! Image versions can be used to merge the OS, Google Cloud connectors, and Big Data components into a unified package. This complete package is then deployed to your cluster as a whole without splitting it.
Therefore, if you have certain dependencies, such as Python libraries, that you intend to bring to the cluster, you should use custom images.
4. Gain control over initialization actions
One of the Google Cloud Dataproc best practices is to gain control over the initialization actions. These actions are intended to allow customization of Cloud Dataproc with specific implementations. When you create a Dataproc cluster, you might consider specifying actions for executables and scripts. These scripts will then be run on all specific nodes in the cluster once their setup is complete. Therefore, looking for initialization actions from an area where you can regulate them to suit your specific needs is better.
Conclusion
Dataproc is a super fast service that takes around 5-30 minutes just to create Hadoop or Spark clusters. You can try to create it either on-premises or through IaaS providers. Additionally, Dataproc clusters are comparatively faster than others regarding starting, calling, and shutting down clusters. Each operation requires 90 seconds or less than the processing result.
- Google Cloud Dataproc is built on several open-source platforms, including Apache Hadoop, Apache Pig, Apache Spark, and Apache hive. All of these platforms collectively have a different role at Dataproc.
- Dataproc supports native versions of all these open-source platforms. This means that users are in control of upgrading and using the latest versions of each platform. Not only that, but users also have access to use open-source tools and libraries within the ecosystem.
- Google Cloud Dataproc allows users to create multiple managed clusters that support scaling from 3 to over hundreds of nodes. Creating on-demand clusters and using them during job processing is also possible for users with the Dataproc service.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Analyst who love to drive insights by visualizing the data and extracting the knowledge from it. Automating various tasks using python & builds Real time Dashboard's using tech like React and node.js. Capable of Creaking complex SQL queries to fetch the accurate data.





