This article was published as a part of the Data Science Blogathon.
Introduction
We, as a learner, are in the stage of analyzing the data mostly in the CSV format. Still, we need to understand that at the enterprise level, most of the work is done in real-time, where we need skills to stream live data. For that, we have Spark Streaming from Apache Spark, and in this article, we will focus on the theoretical aspects of the same to get the idea of working with the same.
In my previous articles related to PySpark, I have gone through PySpark’s Data frame operations and MLIB library, where we went through many documentation examples of different algorithms and learned how to implement them in a real-world setting. Along with that, we also worked on various consultancy-based projects with PySpark.
Now it’s time to head towards advanced Spark topics, and we are starting from Spark Streaming. By far, we were working with the locally present dataset in our system, on-premises, or on the cloud, i.e., the dataset was not accessed in real-time. With this drawback, Spark streaming was born so that we can analyze and draw insights in real-time. For that reason only, we call it “streaming.”
This was a high-level introduction to Spark streaming. In the coming section of the articles, we will dig deeper into this concept, like how it works in the backend. What are its types? And more of it.
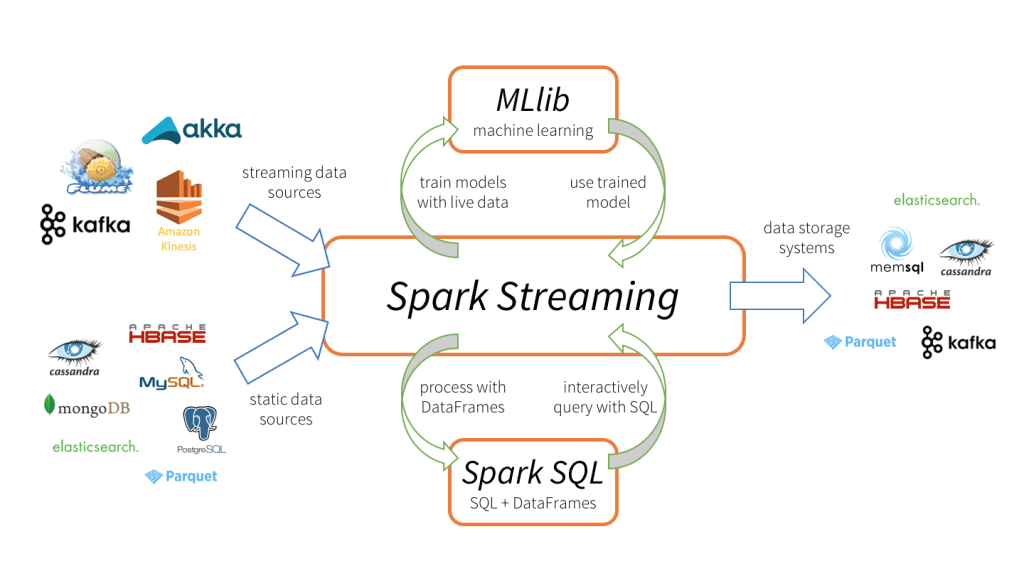
What is Spark Streaming
When we hear Spark Streaming as a term, the first thing that pops up is that it will only deal with real-time data (like Twitter developer API). Still, we can also work with batch processing, i.e., a dataset in the system, though other libraries and utilities are there; hence it is widely used for stream processing. Let’s discuss a few major characteristics of it.
- Scalable: Previously, what we have discussed has the hidden answer to this; when we say stream processing, that means it takes real-time data for the pipeline needs to be scalable, then only the purpose will be served.
- Fault-tolerant: The secret behind the fault-tolerant capacity of spark streaming is its worker nodes which are built on top of Spark only so similar to Spark it deals with high uptimes and sudden fault detection.
- Load balancing: Whenever working with live data, we must take care of the high traffic of data coming up for processing. We have load balancers in this option. We can equally distribute the traffic to each resource by this; we gain 2 objectives, one is the proper usage of resources, and another is dealing with high data traffic.
- Streaming and static: Spark Streaming combination can deal with a static dataset and a live dataset. For that, we need to work with interactive queries, providing native support to the end users.
Note: Spark Streaming is just another extension of the core Spark API
How does Spark Streaming Work?
Before digging deeper to spark Streaming specifically, let’s scratch the surface and understand how the most modern distributed system works:
- Receiving data: This is the data ingestion process where real/static data is being received (e.g., from IoT devices) and ingested to any system like Amazon kinesis or Apache Kafka
- Process data: In real-time processing, the data is processed in parallel on clusters. From this approach, stream data is being processed effectively and efficiently.
- Output: After the data is processed, we need to collect the data as the output, which is stored on downstream systems like Cassandra, Kafka, and Hbase.
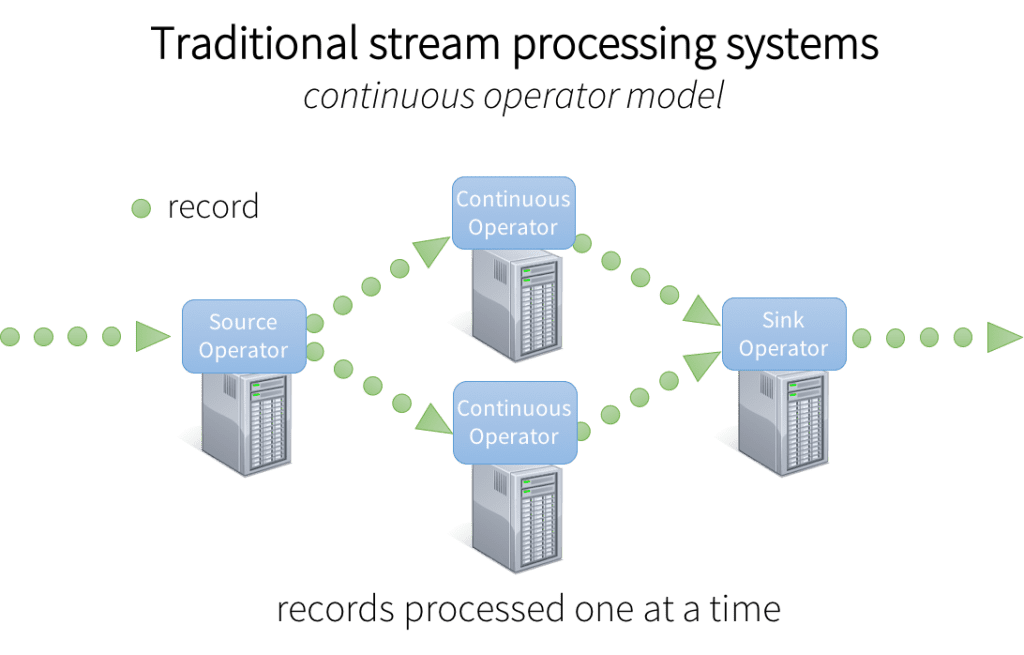
Now let’s discuss how Spark streaming works and what is the architecture model of the same; the architecture model is identical to the traditional model but with some advanced tools and techniques, which we will look into further:
- In Spark, Streaming data is first ingested from single or multiple sources such as through networking (TCP sockets), Kafka, Kinesis, IoT devices, and so on.
- Then the data is pushed to the processing part, where Spark Streaming has several complex algorithms powered by high-throughput functions such as window, map, join, reduce, and more.
- The last step of this process will be to push the data to large databases and dashboards to develop analytical solutions, more specifically, the live dashboards where we can see the data visualization of those advanced graphs changing in real-time. We can also use PySpark’s Machine learning techniques or graphical processing on the streamed data.

How does Spark Streaming Works Internally?
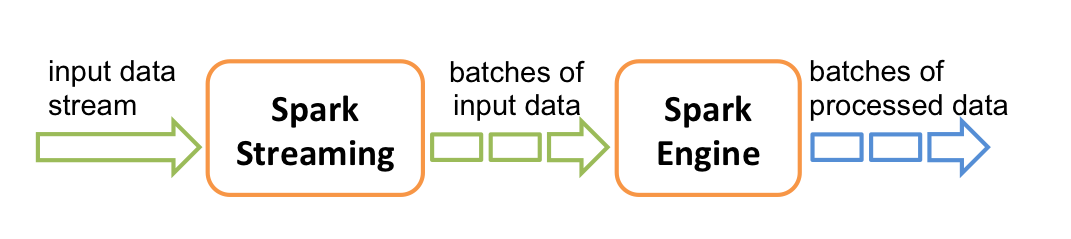
Let’s also discuss this segment, as it is essential to know what kind of processing technique Spark Streaming follows! The answer is simple and self-understandable as we all know that all traditional live streaming architecture works with batch processing, so is Apache spark. In this method, Spark streaming will simply take in the input streams and then break down into batches and process them parallelly.
Structured Streaming
A spark supports two types of streaming; one is the legacy project, i.e., the spark model, which we have already discussed; now it’s time to have an understanding of the other one, i.e., Structured Architecture
Structured Streaming: Unlike Spark Streaming, This one works on top of Spark SQL API/engine. The best part is that there is no confusion about whether we have to compute the batch data or live streamed data, as the implementation part is almost the same. The results keep updating as long as it receives the final data from input streams for such operations; one can use the Dataset/DataFrame API in either of the available languages (Python, Java, Scala, and so on).
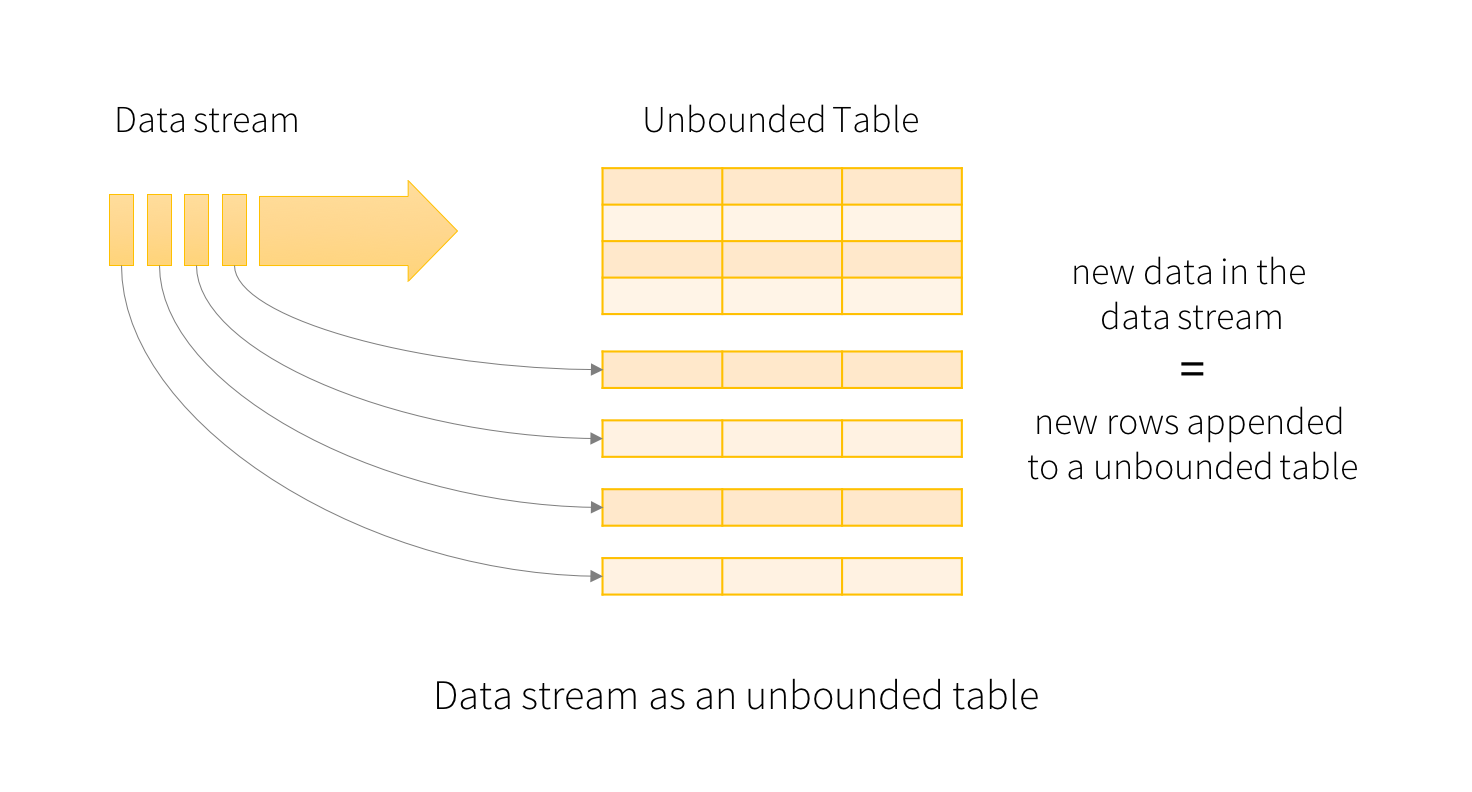
Architecture model of Structured Streaming
The main idea behind the structure streaming model is to treat it like an unbounded table (from unbounded, I mean, the table with no limit to store the records, or we can say it tends to increase its size every time the new data arrives). This format makes the live streaming the same as the batch processing concept, making it a bit easier in terms of implementation compared to other streaming models.
Conclusion
Here I’m concluding this article, where we will discussed everything about spark and structured streaming, like the working model of both the types as well as how they internally work and every insider thing which one needs to know before practically implementing it with other programming languages such as Python, Java, etc.
- The first thing about Spark Streaming we discussed was the “what” part, like what it means, the characteristics like how scalable the load balancing feature is, etc.
- Later in the article, we discussed how Spark Streaming works internally, where we learned how the data is received, processed, and given as the output.
- In the end, we learned about the other kind of streaming, i.e., Structured Streaming, and how it differs from the traditional one, i.e., Spark Streaming.
Here’s the repo link to this article. I hope you liked my article on Introduction to Spark Streaming. If you have any opinions or questions, comment below.
Connect with me on LinkedIn for further discussion on MLIB or otherwise.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





