This article was published as a part of the Data Science Blogathon.
Introduction to Minerva

Google presented Minerva; a neural network created in-house that can break calculation questions and take on other delicate areas like quantitative reasoning.
The model for natural language processing is called Minerva. Recently, experimenters have developed a very sophisticated natural language processing model. You can use it to restructure textbooks or write essays. Still, Google argues that these neural networks do not show a significant aptitude for “quantitative logic tasks” similar to computational problems.
Introductory language models are extensively used in various natural language tasks similar to question answering, logic, and summarization. Still, these models struggle with tasks that bear numerical logic, similar to working calculation and engineering problems.
Minerva is a new language model that uses sequential logic to answer good and scientific problems. It provides results incorporating numerical calculations and emblematic manipulation. Google exploration introduces it to answer similar problems using numerical calculation and emblematic manipulations. It is grounded on a new Google research exploration
Recent Language Models Contributions
Language models have done veritably well on numerous natural language tasks. Neural networks trained on a large quantum of different data in an unsupervised way can do well on various tasks in PaLM, BERT, GPT- 3, and Gopher.
Language models are still far from being as good as individualities in quantitative thinking. It takes a variety of capacities to break calculation and wisdom problems, including the capability to read and comprehend questions written in both natural language and fine memorandum, to recall material formulas and constants, and to develop step-by-step results that involve numerical computations and symbol manipulation.
Fascinating Phase – Range of Challenges
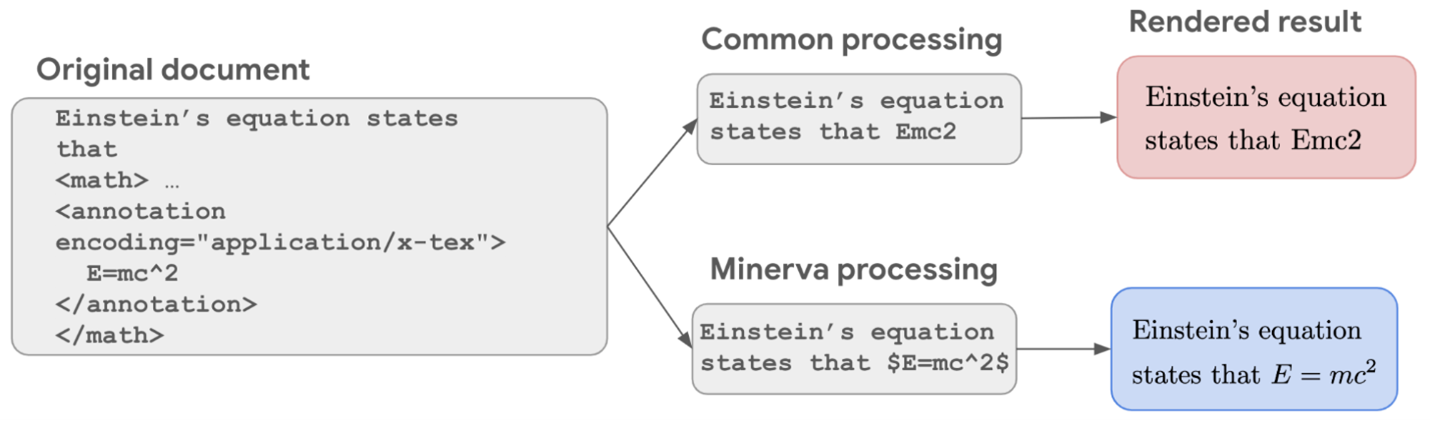
The experimenters trained Minerva on a 118 GB dataset of scientific papers from the arXiv preprint service and web runners with fine expressions in LaTeX, MathJax, or other formats. The model maintains the symbols and formatting information in the training data as pivotal to the semantic meaning of good equations. Minerva also uses contemporary egging and grading procedures to answer good problems effectively.
Minerva uses ultramodern egging and grading procedures to answer good problems. It generates several answers by stochastically evaluating all implicit issues while answering a question. It selects the most frequent result as the last answer by employing maturity voting and chain of study or notepad.

https://tinyurl.com/234puxb8
|
A dataset for quantitative logic Careful data processing preserves fine information, allowing the model to learn mathematics at an advanced position. |
Their findings show that performance on a range of grueling quantitative logic tasks improves by gathering training data material for quantitative logic challenges, training models at scale, and exercising best-in-class conclusion approaches. They also show that the training data should apply to the task.
Minerva on STEM Benchmarks
The experimenters examined Minerva on STEM marks ranging in difficulty from grade academy position challenges to graduate-position coursework, assessing its numeric logic chops. These marks included those for technology, engineering, and calculation.
- Problems from high academy calculation competitions
- The MMLU- STEM is a subset of the Massive Multitasking Appreciation Measure that focuses on STEM subjects at the high academy and council situations, including engineering, chemistry, calculation, and Physics.
- GSM8k That Includes introductory computation Operations Used in Grade School Math Problems
- OCWCourses is a set of the council- and graduate- position challenges from MIT OpenCourseWare. It covers a range of STEM subjects like solid-state chemistry, astrophysics, reasoning equations, and special reciprocity.
Minerva’s strategy for logic quantitatively is not grounded on formal mathematics. It parses queries and produces replies using a combination of natural language and LaTeX fine expressions.
Their findings show that Minerva constantly produces innovative issues, occasionally significantly, occasionally by a significant periphery.
When Minerva goes South
Minerva makes many arithmetic errors, most of which she interprets fluently. About half of the miscalculations are miscalculations, and the other half are logical crimes where the path to the outcome does not follow a logical chain of investigation. The model needs improvement.
A model can also correct the definitive answer, but for the wrong reason. We call similar cases” false positives” because they are inaptly counted in the overall evaluation of the model’s performance. In our analysis, we set up that the false positive rate is low (Minerva 62B produces lower than 8 false positive results in the calculation)
Below are a couple of illustration miscalculations the model makes
Computation mistake: The model inaptly cancels the square root on both sides of the equation.

Logical mistakes: The model computes the number of free throws at the fourth practice but also uses this number as the eventual answer for the first practice.

Future Scope
Machine literacy models are useful tools in many scientific disciplines, but they are often not designed to solve specific problems. We hope that the ability of these general models to tackle quantitative logic problems will help push the frontiers of science and education. Minerva is a small step in that direction.
Limitations
Google’s way of allowing quantitative logic is not formal calculation. Minerva understands questions and gives answers using a blend of natural language and LaTeX fine expressions. There is no unequivocal calculation structure underneath the structure. It is not clear if it is possible to do it in a formal way.
This issue is not present in formal approaches to theorem evidence (e.g., see Coq, Isabelle, HOL, spare, Metamath, and Mizar). Still, one advantage of an informal approach is that we can use it to address various issues that could be grueling to define.
Conclusion
Machine competency models are great tools in many scientific fields, but they are always used only to solve problems. The researchers hope their model can develop quantitative logic to help experimenters and scientists learn new openings.
- With Google’s support, this is state-of-the-art technology.
- This could change the rules of the quantitative modeling game in the long run.
This article paves the way by helping readers understand the nuances of this incredible sandwich of technology and experimentation from Google brainchild Minerva.
Do spend time checking some of these intriguing interactive sample explorer!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
||📊Lead Technical Analyst at HP||Connecting data to dollar||📋Certified - Data Scientist||SAP ERP||Microsoft Data Analyst,LSS Yellow Belt||🥇3*MVP,1*APAC Champion@HP||🏆Blogathon Winner’22@Xebia,2*AVCC||AVCC Member’22||



