This article was published as a part of the Data Science Blogathon.
Introduction
Organizations are turning to cloud-based technology for efficient data collecting, reporting, and analysis in today’s fast-changing business environment. Data and analytics have become critical for firms to remain competitive. Reports, dashboards, and analytics tools are used by business users to derive insights from data, monitor corporate performance, and support decision-making. This is where Data Warehousing comes in as a key component of business intelligence, allowing companies to improve their performance. These reports, dashboards, and analytics tools are powered by data warehouses, which store data effectively to reduce data input and output (I/O) and provide query answers swiftly to hundreds of thousands of users concurrently.
What exactly is a Data Warehouse?
A data warehouse is a centralized storage system that enables data storage, analysis, and interpretation to improve decision-making. Data warehouses receive data regularly from transactional systems, relational databases, and other sources.
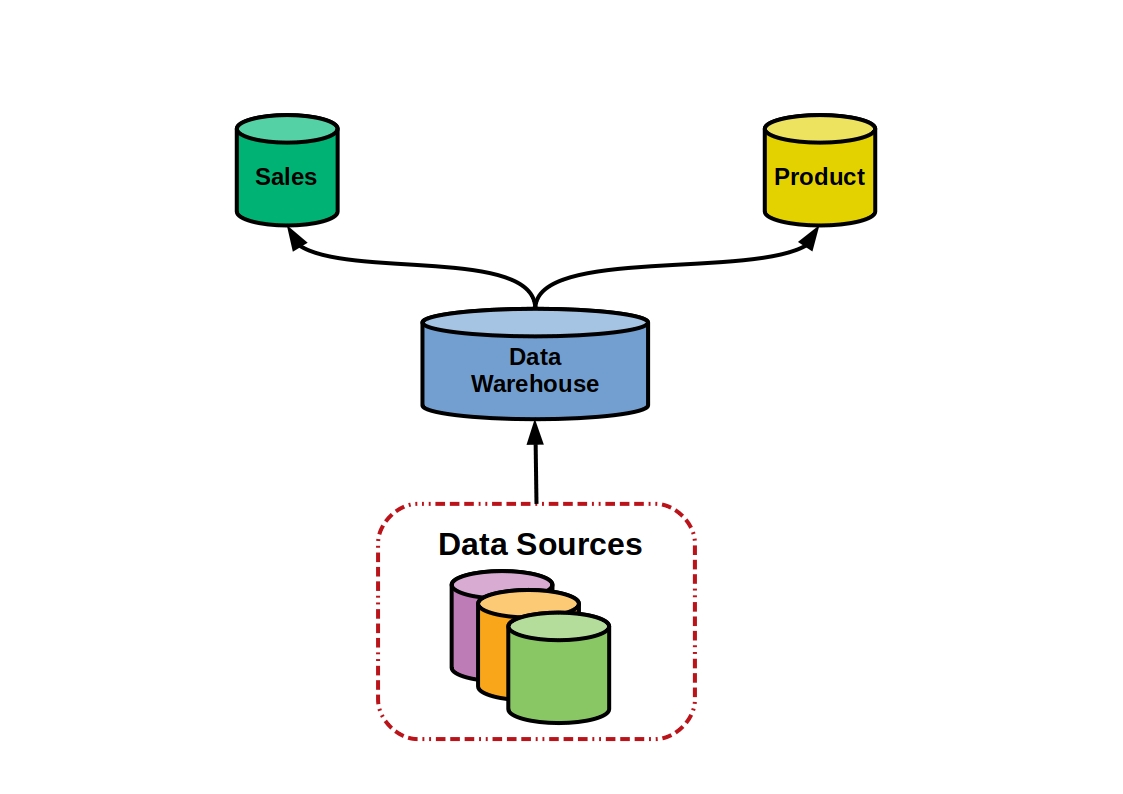
A data warehouse is a collection of organizational data and information derived from operational sources and external data sources. Periodically, data is extracted from various internal applications, such as sales, marketing, and finance, as well as customer-facing and external partner systems. The data is then made accessible and analyzable by decision-makers.
Interview Questions on Data Warehouse
1. What is the difference between Data Warehousing and Data Mining?
A Data warehouse stores data from several transactional databases via extraction, transformation, and loading. Data is periodically saved. It saves a vast quantity of data. Data warehouse applications include product management and development, marketing, finance, banking, etc. It is utilized for increasing operational efficiency and generating and analyzing MIS reports.
Whereas, Data Mining is the process of discovering patterns in huge datasets via the use of machine learning, statistics, and database management systems. Data is routinely evaluated here. It focuses mostly on analyzing data samples. Market Analysis and Management, Identifying Anomaly Transactions, Corporate Analysis, Risk Management, etc., are a few examples of application cases. It is used to improve corporate operations and make better judgments.
2. What are the significant features of a data warehouse?
Following are some of the significant features of a data warehouse:
- Subject-Oriented – A data warehouse is subject-oriented because it delivers information on a subject instead of the company’s activities. These may include products, customers, suppliers, sales, and income. Instead of focusing on actual operations, a data warehouse concentrates on modeling and analyzing data for decision-making.
- Integrated − It is created by merging data from numerous sources, such as flat files and relational databases, allowing for more accurate data analysis.
- Time Variant − The data gathered in a data warehouse are associated with a certain time frame. A data warehouse’s data gives information from a historical perspective.
- Non-volatile − Non-volatile storage does not delete existing data when new data is added. A data warehouse is kept distinct from the operational database, so frequent modifications to the operational database are not reflected in the data warehouse.
3. Define OLTP and OLAP.
- On-Line Transaction Processing (OLTP) is a program that alters data whenever received and has many concurrent users.
- Online Analytical Processing (OLAP) is a system that collects, maintains, and analyses multidimensional data for analysis and management purposes.
4. What is metadata?
The definition of metadata is information about data. Metadata gives data a more comprehensive identification and acts as the basis for its interactions with other data. It may also be a valuable tool for saving time, remaining organized, and maximizing the effectiveness of your working files.
5. What distinguishes structured data from unstructured data?
Structured data is organized, has a well-defined format, and can fit into a predefined table. It employs the DBMS storage technique. Scaling schemas is quite challenging. Among the protocols listed below are ODBS, SQL, ADO.NET, etc. Unlike structured data, unstructured data lacks a schema or framework. It is mostly unmanaged, highly scalable at runtime, and capable of storing data. Among the protocols adopted are XML, CSV, SMSM, SMTP, and JASON, among others.
6. In the context of data warehousing, what do you understand about a data cube?
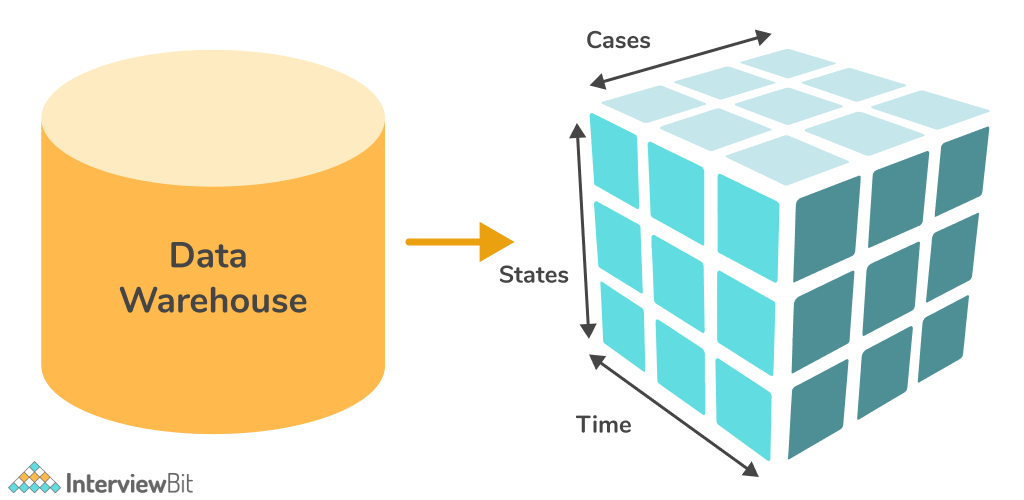
A data cube is a multidimensional data model that holds data that has been streamlined, summarised, or aggregated for fast and simple analysis utilizing OLAP technology. The data are kept in a data cube, which facilitates online analytical analysis. In data warehousing, an n-dimensional data cube can be built. A cube is typically thought of as a three-dimensional structure. A data cube holds information in the form of facts and dimensions.
7. What is the purpose of an ODS?
A data store for operational systems is called an operational data store. For reporting and analysis, this data is frequently used.
8. What do you understand by the term data purging?
Data purging is a procedure that involves ways that can permanently delete data from storage. Several approaches and strategies can be employed for data purging. The process of data forging frequently contrasts with data deletion. Thus, they are not the same. Data deletion is more temporary, whereas data cleansing permanently eliminates the data, freeing up additional storage and memory space that may be used for other reasons. The purging process allows us to archive data even if it is permanently removed from the main source, giving us the option to recover that data if we purge it. On the other hand, the deleting process permanently removes data but does not always require keeping a backup; it usually involves insignificant amounts of data.
9. Obtain a list of industry data warehouse systems currently in use.
The following are some of the key data warehouse systems now in use in the industry:
- Snowflakes
- Apache Hadoop
- Oracle Exadata
- Microfocus Vertica
- Teradata
- GCP Big Query
- SAP BW4HANA
- AWS Redshift
10. What is virtual data warehousing?
A virtual data warehouse gives a collected picture of completed data. A virtual data warehouse does not include historical data. It is frequently regarded as a logical data model of the provided metadata. Virtual data warehousing is the standard data system method for facilitating analytical decision-making. It is one of the most straightforward methods for translating data and presenting it in decision-makers format. As a result of virtualizing the data, it produces a semantic map that the top user can view.
Conclusion
This brings us to the conclusion of the blog post on the Most Frequently Asked Data Warehouse Interview Questions. We hope you found this information helpful and are now more prepared to attend the upcoming interviews. Below are a few of the article’s most important takeaways:
- A Data warehouse is used to store data from several transactional databases, Whereas; Data Mining is the process of discovering patterns in huge datasets.
- (OLTP) stands for On-Line Transaction Processing, and (OLAP) stands for Online Analytical Processing
- A data store for operational systems is called an operational data store
- A virtual data warehouse provides a consolidated view of all of the data that has been gathered.
I hope you liked my article on the most common questions asked in data warehouse interviews. If you are preparing for interviews, check more articles on our blog.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hello, my name is Prashant, and I'm currently pursuing my Bachelor of Technology (B.Tech) degree. I'm in my 3rd year of study, specializing in machine learning, and attending VIT University.
In addition to my academic pursuits, I enjoy traveling, blogging, and sports. I'm also a member of the sports club. I'm constantly looking for opportunities to learn and grow both inside and outside the classroom, and I'm excited about the possibilities that my B.Tech degree can offer me in terms of future career prospects.
Thank you for taking the time to get to know me, and I look forward to engaging with you further!





