This article was published as a part of the Data Science Blogathon.
Introduction
Empirical evidence suggests that the large language models (LLMs) perform better on downstream tasks. And with the help of parameter-efficient methods, a single frozen pre-trained LLM can be leveraged to execute various tasks by learning task-specific soft prompts that modulate model behavior when concatenated to the input text. However, these learned prompts are tightly coupled to a given frozen model, so if the model is updated, the corresponding new prompts need to be retrieved. Considering this, would it not be better to devise an adaptive and task-agnostic solution? Given this, researchers from GoogleAI have proposed and investigated several approaches to “Prompt Recycling”, where a prompt trained on a source model is transformed to work with the new target model.
Source: Canva
The proposed methods do not leverage supervised pairs of prompts, task-specific data, or training updates with the target model, which would be as costly as re-tuning prompts with the target model from scratch.
Now, let’s dive in and take a closer look at the proposed methods.
Highlights
- GoogleAI researchers proposed and investigated several approaches to “Prompt Recycling,” where a prompt trained on a source model is transformed to work with the new target model.
- Learned transformation based on structural similarities between the models is applied to the prompt to build a new prompt suited to the target model. It infuses extra information beneficial for some tasks beyond the target model’s in-built knowledge.
- The recycling performance of the recycler declines when more and more tokens are used.
- Recyclers perform better when applied to different models and source prompt combinations. It was noted that the Base → Large recycling is unstable and that Large → Base recycling is more reliable and generates stronger prompts than Base → Base recycling, and the recyclability tends to decrease the more a prompt is trained.
What’s the Need for Recycling Prompts?
As we briefly discussed in the Introduction section, a single frozen pre-trained LLM can be leveraged to perform various tasks by learning task-specific soft prompts that modulate model behavior when concatenated to the input text. However, these learned prompts are tightly coupled to a given frozen model they were trained with. So, when a model is presented with new input to steer the model towards solving a new task, the activations of the model need to be modified.
Moreover, when the frozen model changes, the patterns of how it processes a given input also change, and the modifications induced by these approaches are no longer relevant. Thus, parameter-efficient methods also need retraining when the frozen models change.
Method Overview
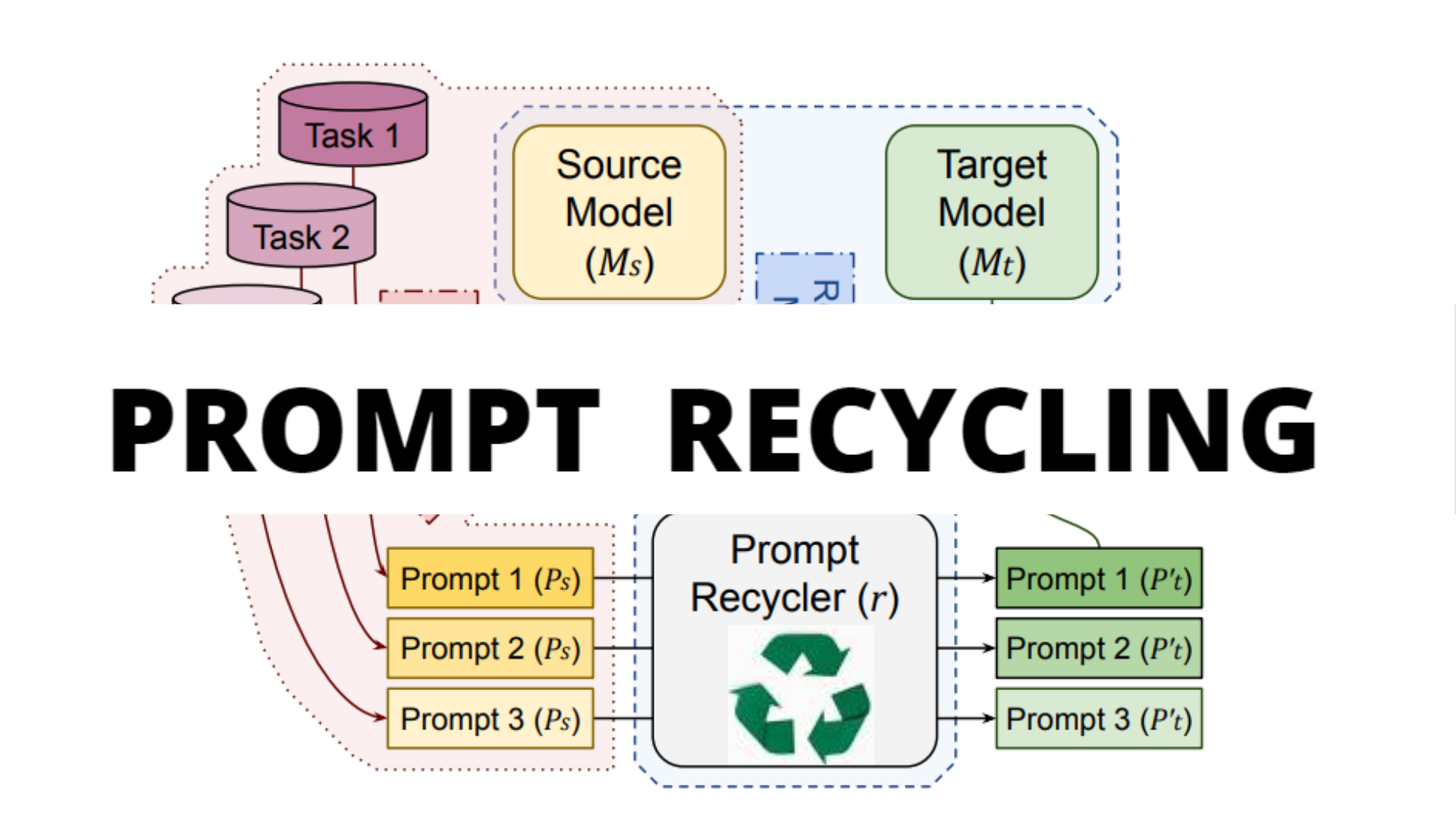
To mitigate the aforementioned issues, the soft prompts learned via Prompt Tuning for a source model Ms are adapted to work with a target model Mt without needing any training of the target model. This approach is termed “Prompt recycling” which is illustrated in Figure1.
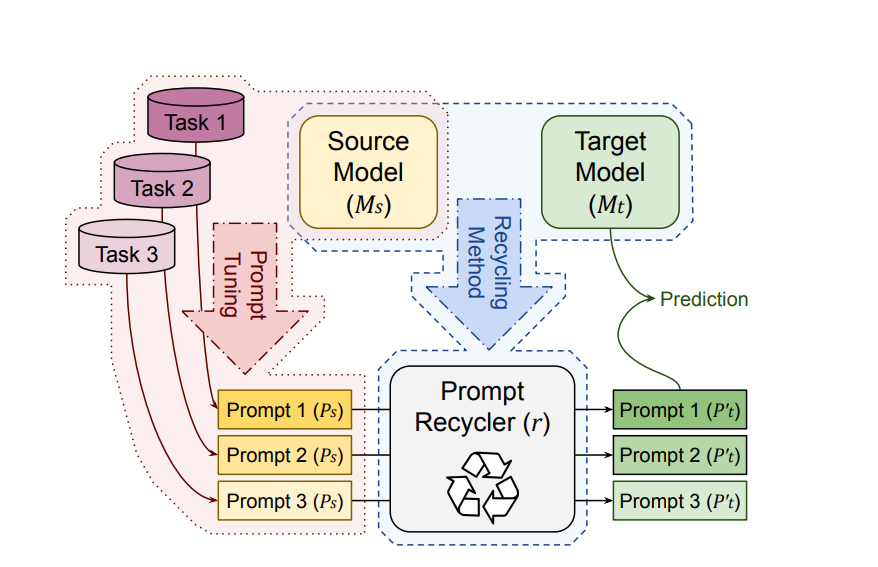
Figure 1: Framework for building a task agnostic Prompt Recycler (r) capable of transforming prompts (Ps) tuned for a source model (Ms) into prompts (P’t) that can be used with a target model (Mt).
For each experiment, three steps are followed:
- Train a source prompt (Ps) for some task (T) using the source model (Ms).
- “Recycle” the prompt with the help of some function (r) learned through the correspondence between the models so that the prompt is transformed into one that’s relevant for the target model. This transformation also takes care of any changes in prompt size that may be needed when moving between models of different sizes.
- Evaluate the recycled prompt (P’t) with the target model (Mt) on the held-out split of task (T).
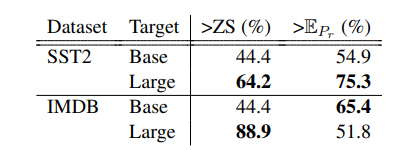
The proposed recycling methods aid in transferring prompts between the models. Under optimal settings, 88.9% of recycled prompts performed better than the target model’s zero-shot capabilities. However, the performance of the recycled prompts still lags behind the prompts trained from scratch with the target model (see Table1). Additionally, recycling from a larger source model to a smaller target model enhanced the reliability and performance of the recycled prompt.
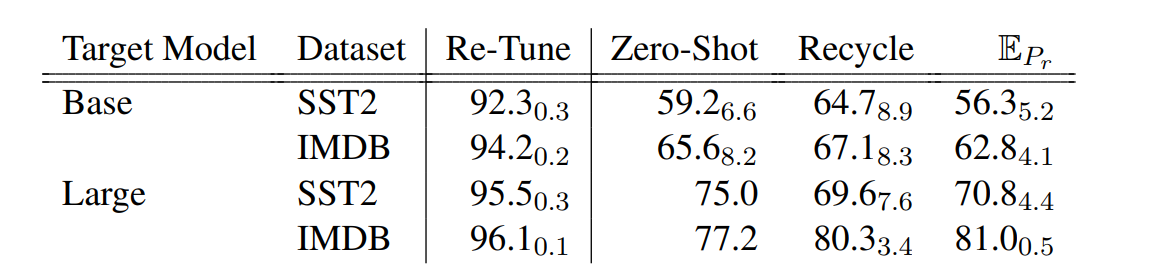 Table 1: Results indicate that the recycled prompts’ performance lags behind the best-case performance of re-tuning directly on the target model but exhibits gains over zero-shot performance and random prompts.
Table 1: Results indicate that the recycled prompts’ performance lags behind the best-case performance of re-tuning directly on the target model but exhibits gains over zero-shot performance and random prompts.Types of Prompt-Recycling Methods
Broadly, the following two methods were proposed for recycling the prompts:
A) Vocab-to-vocab transformations (v2v)
- v2v-lin
- v2v-nn
B) Linear Combination (lin-comb)
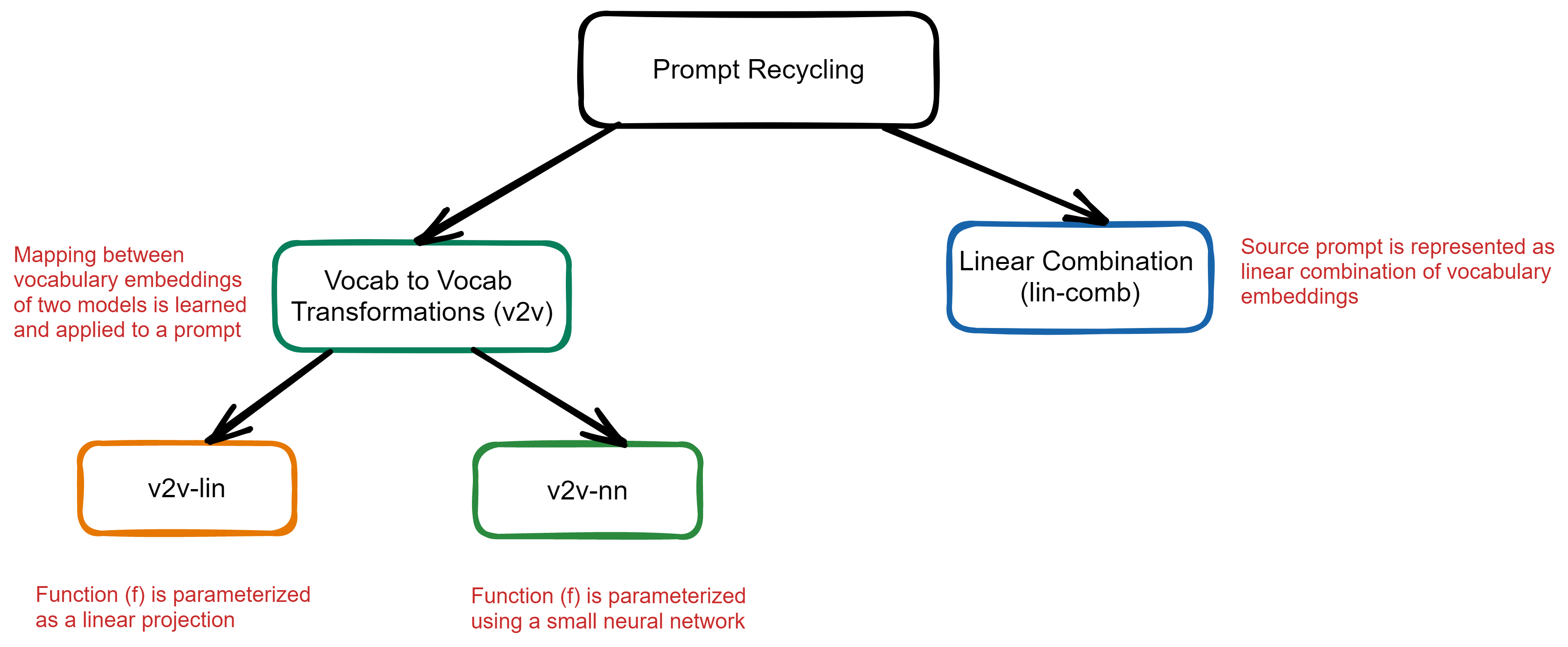
Figure 2: Graphical abstract of the proposed prompt-recycling methods
Notably, both methods are based on correspondences between the embedding representations of tokens across the two models.
It was hypothesized that a recycler trained to map embeddings from Ms to Mt can also be used to map prompts. In addition, the following assumptions were also made:
- Prompts are analogous to token embeddings since they are fed into the model similarly.
- The structural similarities exist in the relationships between tokens in the embedding spaces of different models.
- Across models, the relationship between token embeddings and prompt representations is similar.
Now, let’s take a closer look at the proposed methods.
A) Vocab to Vocab Transformations (v2v): A mapping across the vocabulary embeddings of two models are learned and applied to a prompt. A function needs to be found such that:
f(Vs) = Vt
Then the target prompt is estimated as follows:
P’t = f(Ps)
where Vs: Vocabulary of the source model (Ms)
Vt : Vocabulary of the target model (Mt)
1) v2v-lin: In this method, the function (f) is parameterized as a linear projection, and least squares are used to solve for a matrix Y such that
YVs = Vt
and then the P’t is calculated as follows: P’t = Y Ps.
2) v2v-nn: In this method, the function f is parameterized with a small neural network (NN), mapping the source embedding of size Es to the target embedding of size Et employing a hidden dimension of 4 ∗ Et and ReLU activation functions.
B) Linear Combination (lin-comb): In this method, the source prompt Ps is represented as a linear combination of vocabulary embeddings:
VsX = Ps
Once X is determined, the same linear combination is used on the target embedding vectors, for the corresponding tokens, for generating the estimated target prompt:
P’t = VtX
Results
1. Recycling Performance as a function of the number of words: Figure 3 shows that recycling performance varies greatly when a few token embeddings are used to learn the recycler (r). It also demonstrates that performance declines when more and more tokens are used, probably due to the relative rarity of these later tokens.
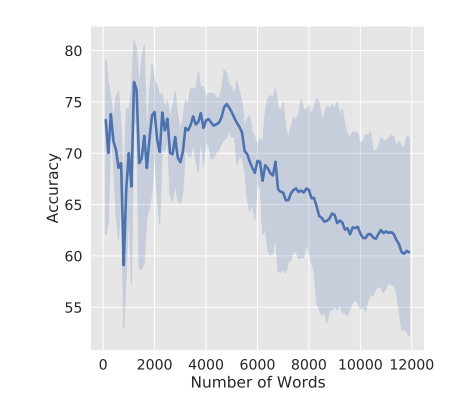
Figure 3: Graph illustrating the recycling performance of the recycler as a function of the number of words (Source: Arxiv)
2. Effect on Recyclability of prompt: As training progresses, prompt encounters repeated input and output pairs as multiple epochs loop over the dataset several times, and the prompt becomes increasingly specialized for completing this specific task in conjunction with this specific frozen model.
Figure 4 illustrates that recycling prompts later in training result in reduced recycling reliability. The source prompt begins to overfit the peculiarities of the specific source model with which it was trained. By 2,000 steps, trained prompts converge, they are within 2.25% of their maximal performance, and they begin to exhibit a growing loss on the validation set with stalling accuracy, indicating that the model is becoming more confident in its incorrect answers.
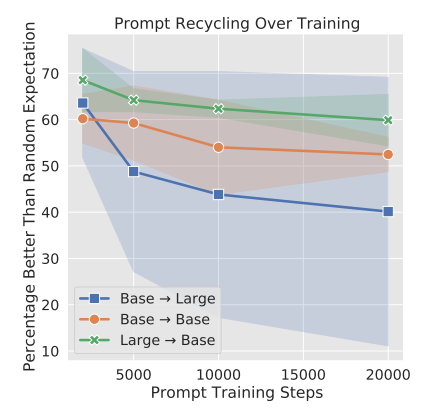
Figure 4: Graph illustrating that the recyclability decreases as the source prompt is trained longer. (Source: Arxiv)
3. Recycling Across Model Sizes: Table 2 highlights inconsistency in performance when recycling from Base→ Large, and the mean performance of recycling is less than that of random prompts. For SST2, a significant boost in performance is observed over Base → Base recycling, but not when compared to random prompts for IMDB. On average, Base → Large recycling is far more likely to outperform the Zero-Shot baseline than Base → Base recycler.
Also, it was noted that recycling from Large → Base is more reliable than Base → Base recycling, especially for SST2 (See Table 3). This indicates that the prompts trained with Large models either memorize their task-specific information in a way that is simpler to transfer to the Base model, or that Large prompts leverage the information stored in the Large model in a way that translates to knowledge extraction for Base models. This finding also suggests that better recycling methods may act similar to distillation methods and transfer knowledge from prompts trained on larger models to smaller ones.
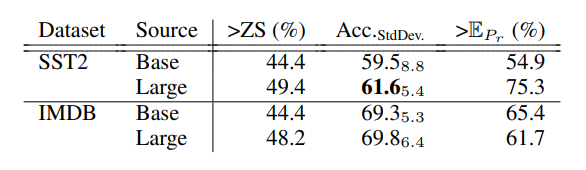
Table 3: Recycling from Large → Base is more reliable than Base → Base recycling, especially for the SST2. (Source: Arxiv)
4. Reliability of recyclers across various settings: Table 4 illustrates how different recyclers operate substantially differently in different settings. The v2v-nn recycler is the best Base → Base recycling method, while the other methods underperform. The other methods performed well in scenarios where the source and target models are of different sizes, especially for the SST2 dataset.
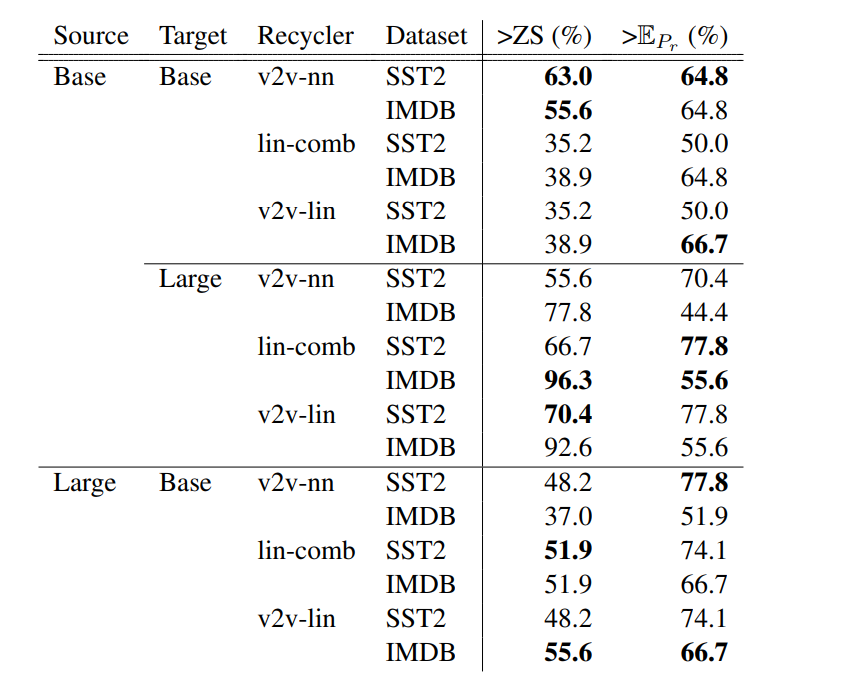
Table 4: Reliability of three recyclers across various settings. (Source: Arxiv)
Conclusion
To summarize, in this article, we learned:
1. Recycling prompts between different models is possible but difficult.
2. Learned transformation based on structural similarities between the models is applied to the prompt to build a new prompt that is suited to the target model and infuses extra information beneficial for some tasks beyond the target model’s in-built knowledge. This manifests as recycled prompts outperforming the target model’s zero-shot performance.
3. Recycling performance of the recycler declines when more and more tokens are used. Moreover, the recycled prompt performs better than randomly sampled prompts but not better than the re-tuned prompts trained in conjunction with the target model.
4. Recyclers perform better when applied to different models and source prompt combinations. It was noted that the Base → Large recycling is unstable and that Large → Base recycling is more reliable and generates stronger prompts than Base → Base recycling, and the recyclability tends to decrease the more a prompt is trained.
5. The v2v-nn recycler is the best method for Base → Base recycling, while the other methods (v2v-lin and lin-comb) underperform. The other methods performed well in scenarios where the source and target models are of different sizes, especially for the SST2 dataset.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]





