This article was published as a part of the Data Science Blogathon.
Introduction
Topic models, an essential part of Natural Language Processing (NLP) workflows, can be used in multiple and diverse fields. There are two main problems with topic models: finding topics that can be used to predict an outcome and making it easier to understand the topics that have already been found. As we will see in this article, Latent Dirichlet Allocation and other unsupervised topic models have significant problems (LDA). Even though we will focus on the issues with LDA, the things we talk about here apply to other types of unsupervised topic models and impart an understanding of supervised topic models.
To illustrate, we will work with many Amazon review datasets. But the approach below can be used in many other places where topic models are beneficial, getting meaningful entities out of 10-K filings or other financial texts, getting entities out of legal documents, etc. Over time, I’ve seen a lot of use cases in natural language processing (NLP) where unsupervised models struggle to be accurate or interpretable.
Problems with Unsupervised Topic Models
The motivation for this approach we will cover in this article comes from the paper published by David Blei in 2017 [1].
We’ll look at a set of Amazon reviews for Sensodyne toothpaste made by GlaxoSmithKline to show how. Imagine that GlaxoSmithKline wants to predict “customer ratings over time for different consumer products, like Sensodyne,” using “topics over time extracted from customer review texts.” Before we go into more detail and look at an example, let’s talk about the problems with unsupervised topic models like LDA. Figure 1 shows two different reviews of Sensodyne written by two different people. Notice that a topic model would give both of these reviews the same three topics: [Price-Related, Taste and Flavor, and Delivery Quality].

Figure 1: An intuitive example of why unsupervised topic models don’t work
To sum up, there are three problems with unsupervised topic models such as LDA:
– Overlapping and Correlated Topics: Dirichlet Style Topic distributions used in LDA don’t capture this
– Bag of words: words are exchangeable, and sentence is not modeled.
– Unsupervised: sometimes weak supervision is desirable
Approach and Example: Supervised Topic Models
In this example, we will use 200 thousand reviews of 24 different types of Sensodyne published by customers on Amazon between 1st Jan 2017 to 31st December 2019. The below snapshot shows how the data looks like for 5 random customers

Figure 2: Glimpse of the data set up for the problem
Below shows the distribution of ratings for the Sensodyne product types for our 200K+ reviews:
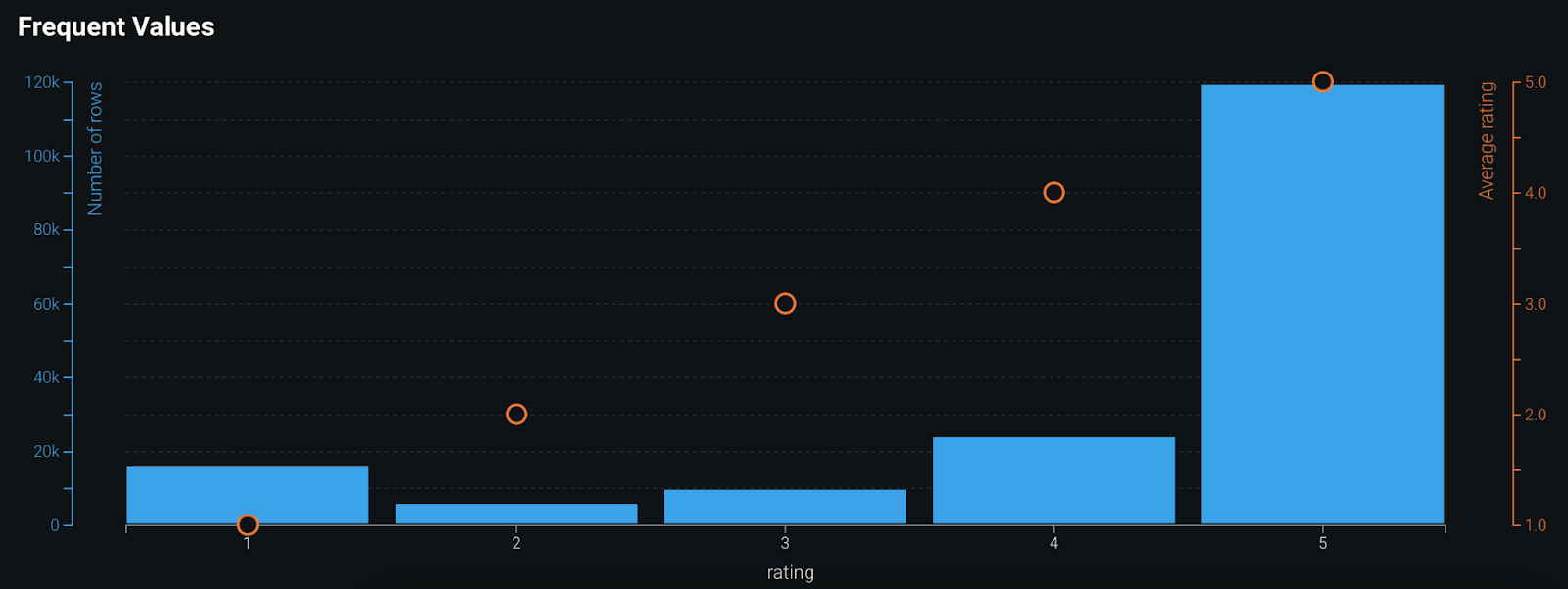
Figure 3: Distribution of customer ratings over a period of time
The overall approach to this problem is summed up in the workflow shown in Figure 4. Amazon reviews are combined with some macroeconomic features per zip code corresponding to the reviewer’s location for those reviews. This shows an example of combining topic models with other factors influencing a particular sentiment. For instance, high-income areas will have more willingness to pay; high-education regions will be more correlated to sales of organic products and will have a higher sensitivity to certain marketing around the product; and so on.
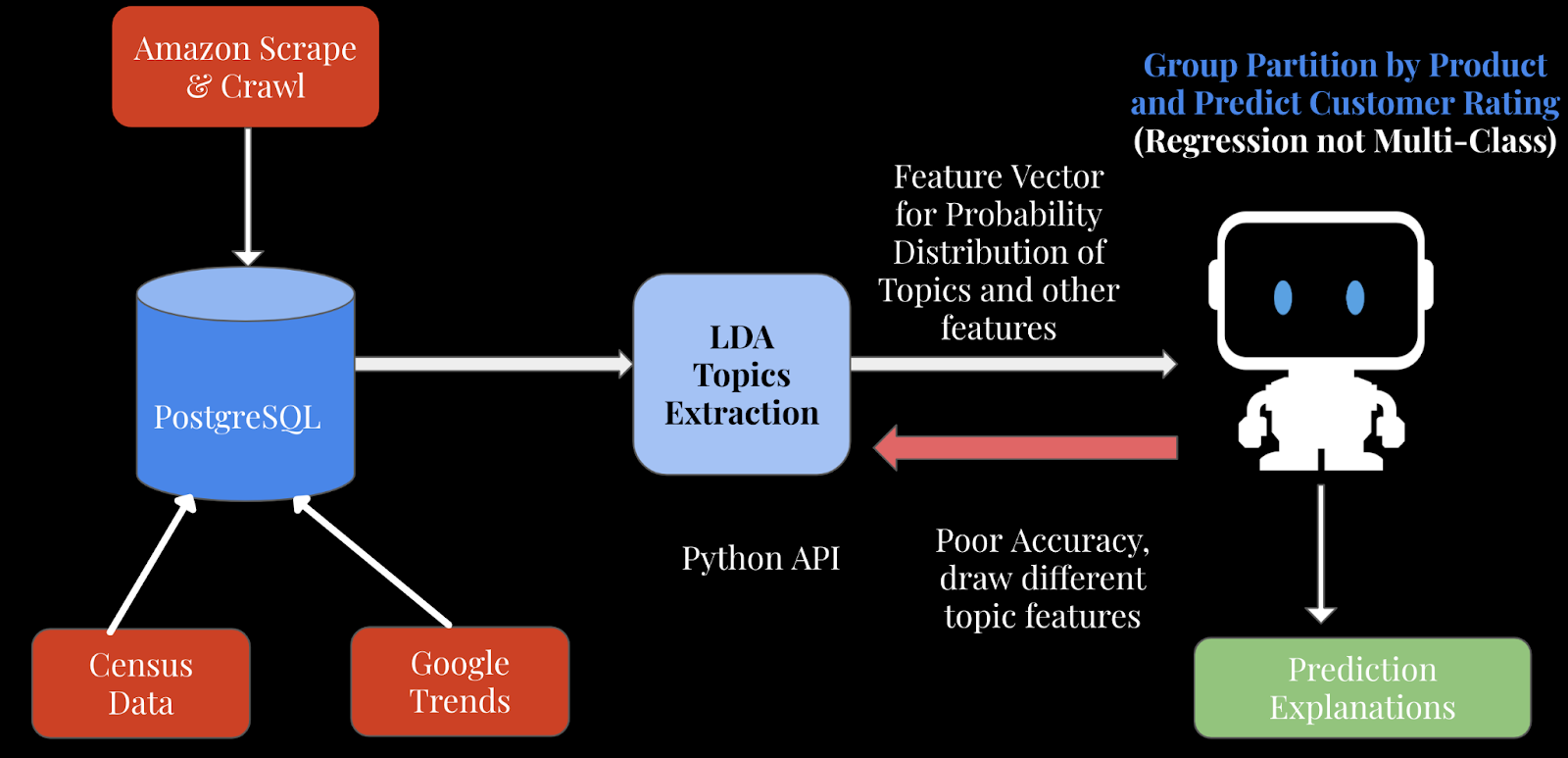
Figure 4: Overall approach for the supervised topic models
The key feature of this approach is the recursive construction of models to identify the topic’s probability distribution to their ability to predict ratings over time. There could be a lot of topics, but not all cases will help you correctly predict ratings, as noted above. Below, Figure 5 shows the data setup to run machine learning models with the topic vector features combined with other features like the cost of toothpaste and macroeconomic and demographic features.
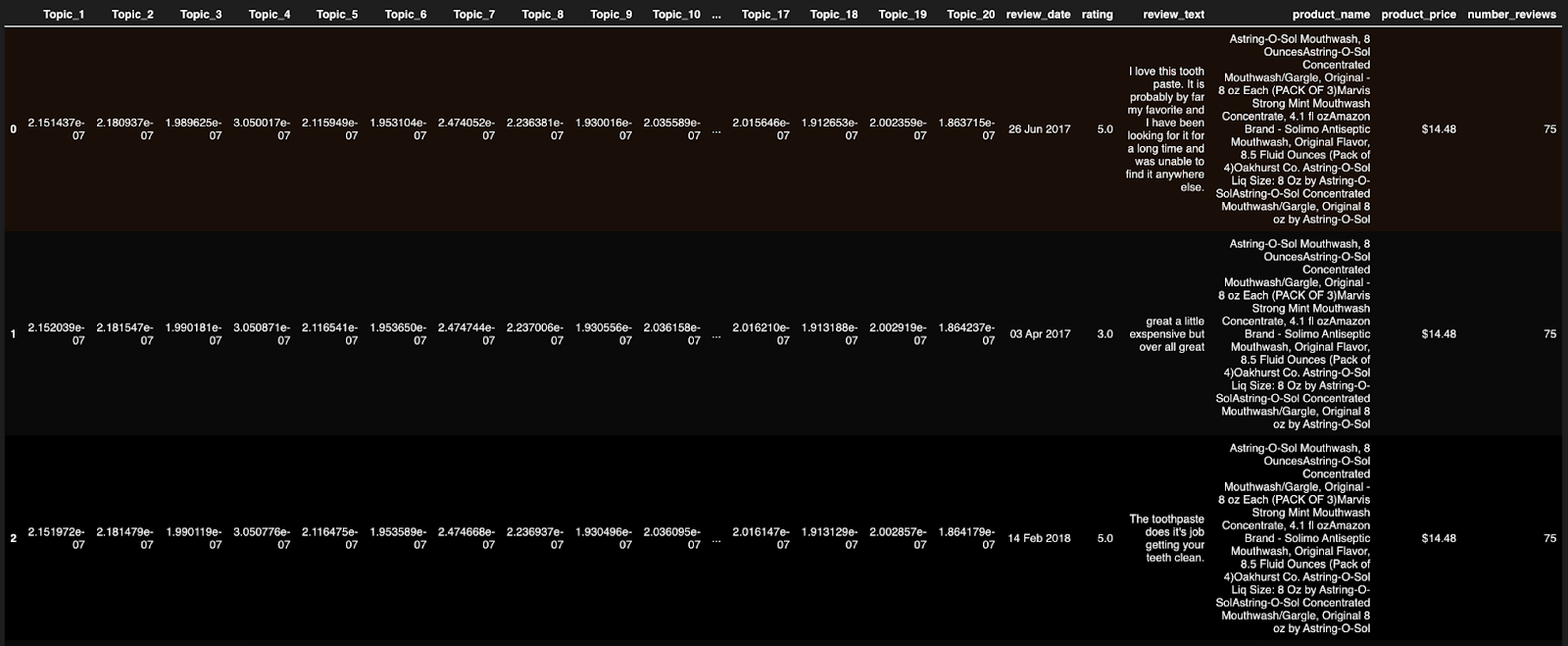
Figure 5: Data set for supervised machine learning models with topic vector features
Model Insights and Interpreting Extracted Topics
One of the main goals of this approach, besides improving the ability of topics to predict how customer ratings for a product will change, is to enhance the insights you get from such topic models.
In this example, we have extracted 27 distinct topics from the set of reviews and then used topic vectors as features for the model, along with other features like price and demographics. As noted above, LDA models produce topics that are “bag of words” style models. This can be seen in these bags of words corresponding to Topic 19, Topic 5, and Topic 27 in our example. A glance at these topics suggests that they refer to
Topic 19: Low cost vs. high quality
Topic 5: Toothpaste flavor and quality
Topic 27: Favorable comparison against a competitor

To understand how this approach helps in improving the insights, let’s look at 5 different examples:
Insight 1: Identify Correlated topics via Feature Associations and reduce the dimensionality
Figure 6 shows a high correlation between these 27 identified topics and the 4 key topic clusters. Along with that, it can be seen that certain issues have stronger pairwise correlations. One is to reduce the number of topics by choosing the ones that represent each of the 4 topic clusters the best; and second, it can be used to identify which topics are correlated between different customers (“Which customers in which location talk about price and quality topics together?”).
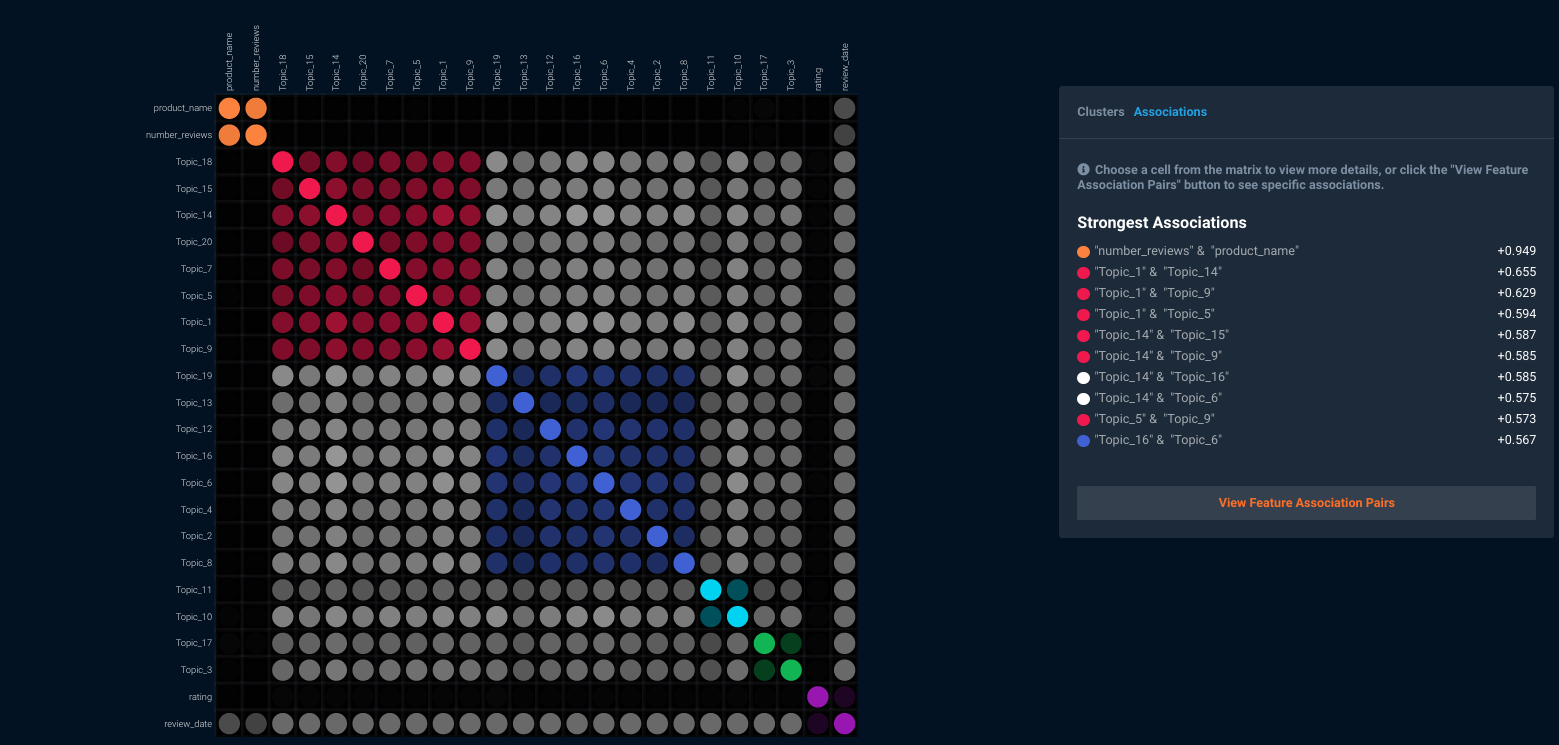
Figure 6: Correlation of topics and pairwise associations
Insight 2: Identify Relative Ranking of Topics in predicting aggregate customer ratings over time
In Figure 7, we can rank these topics relatively based on permutation importance to identify which topics predict the ratings along with other features. This utility is to identify topics that are the most important predictors.

Figure 7: Relative ranking of topics based on permutation importance
Insight 3: Identify Marginal Effects corresponding to each topic.
Partial dependence plots are one of the most effective ways to control for different features and identify the marginal effects of a feature. As we can see above, Topic 8 The below Figure 8 shows how Topic 8 affects the customer ratings in terms of its marginal effect. Here’s the interpretation: “As there is less Topic 8 in a review, the customer rating drops from 4.5 to 3.7, controlling for everything else.” Looking at Topic 8, we can see that it refers to “great breath and worth the money,” so it makes sense to see the downward sloping curve for partial dependence.
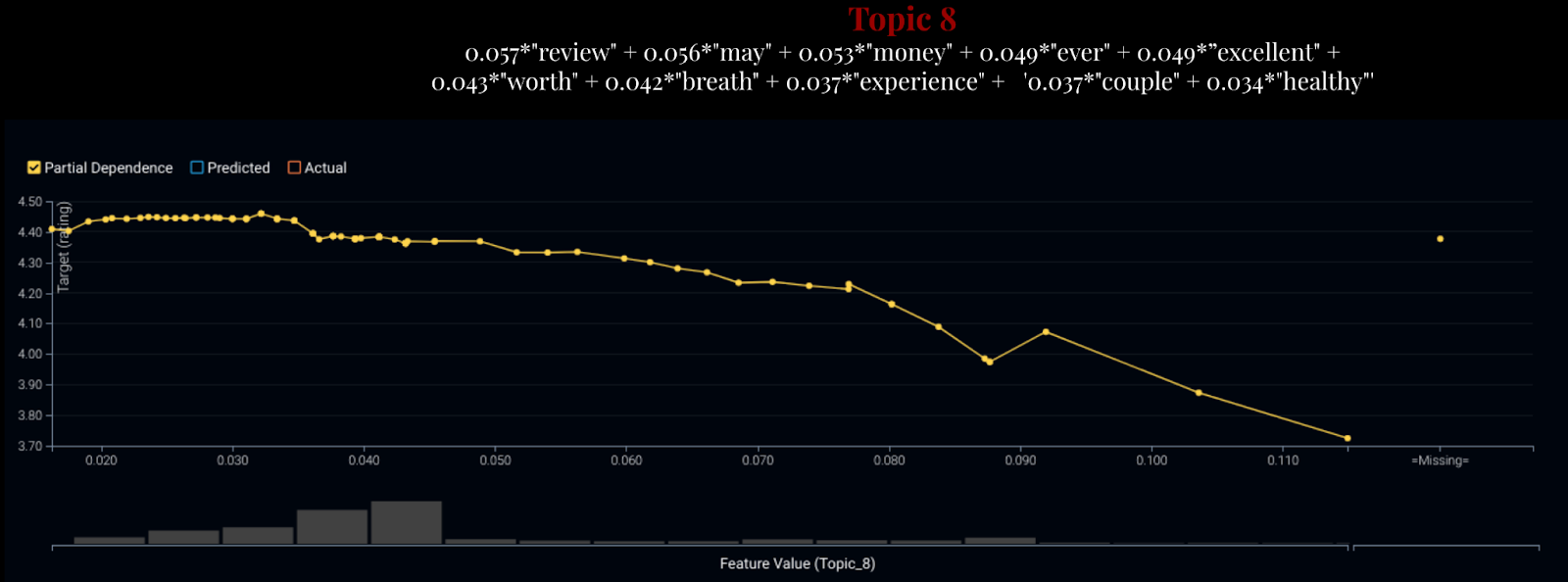
Figure 8: Marginal Effects of topics and their interpretation
Insight 4: Explain the ratings for each consumer via their topic features leveraging prediction explanation techniques
Some techniques help us to analyze every prediction made, Shapley value explanations, LIME, or XEMP. A comprehensive review of these techniques is outside the scope of this article, but in Figures 9 and 10, we can see that each customer can be explained by their respective Topic Features. The “+” sign denotes topics that predict a high rating, and the “-” sign denotes those topics that negatively affect that particular customer’s rating.
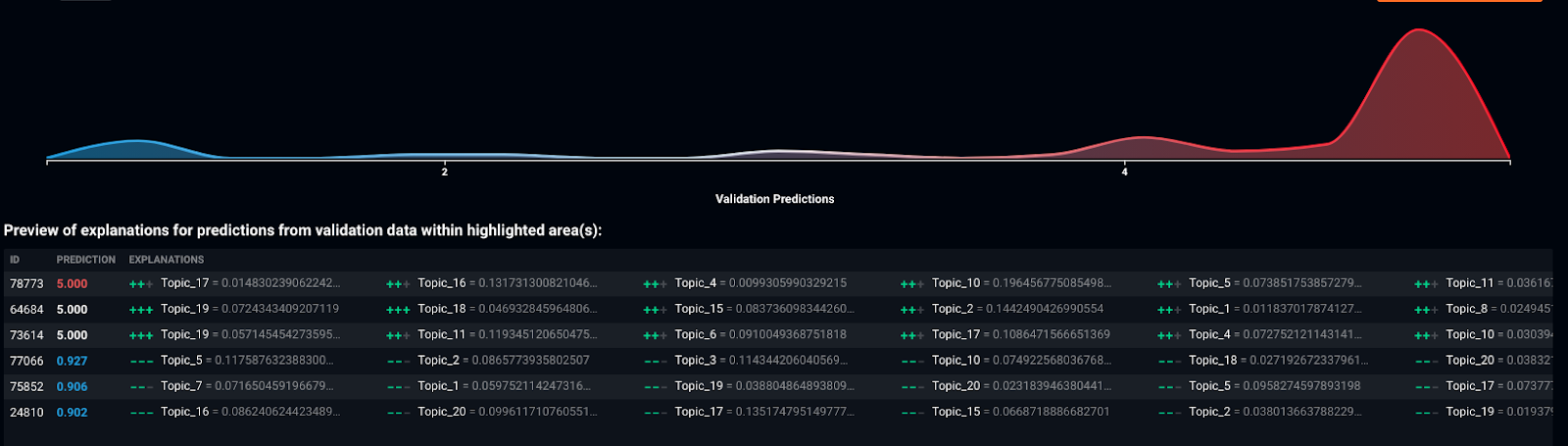
Figure 9: Explain customer rating via various prediction explanation techniques
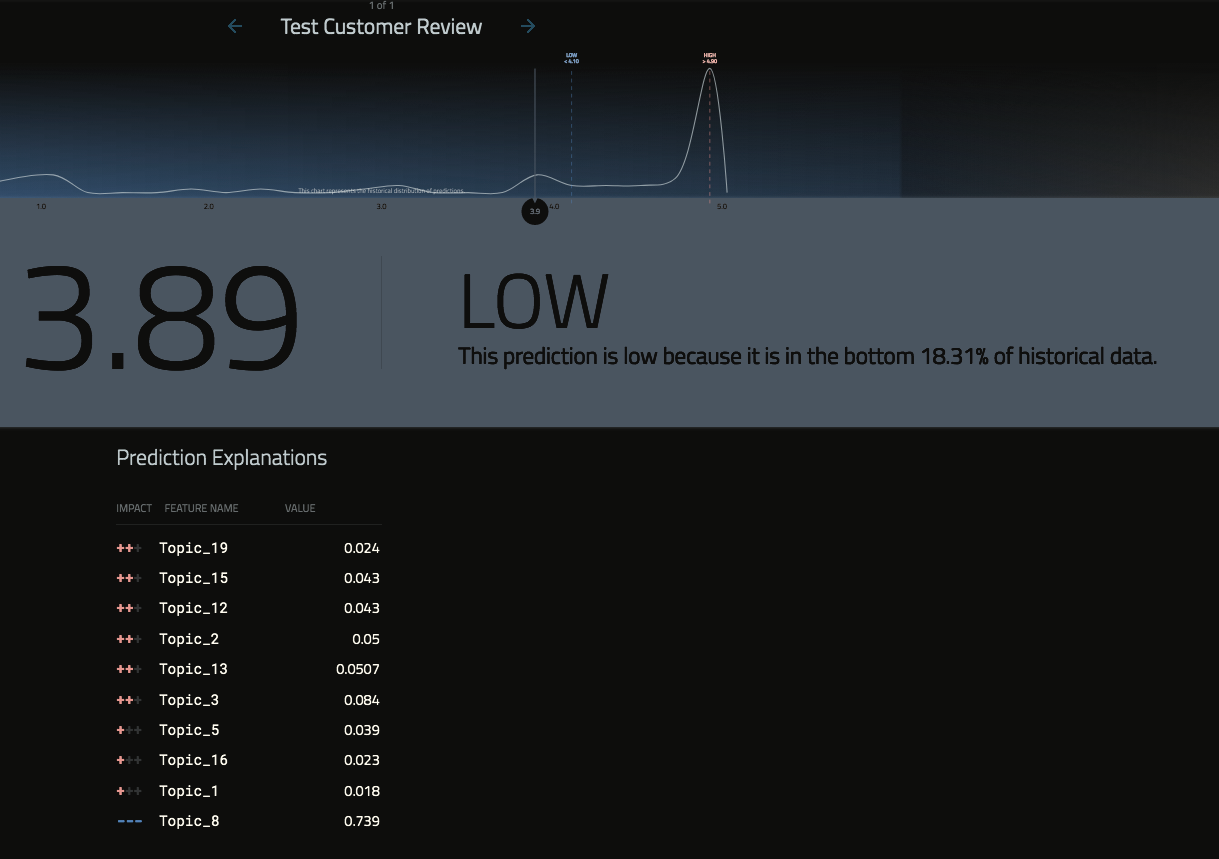
Figure 10: Explain customer rating via various prediction explanation techniques
Conclusion
In this article, we looked at an approach utilizing a large corpus of customer reviews to develop a supervised topic model workflow.
The benefits are:
- Improved predictability of customer ratings over time
- Improvement in interpretability by utilizing machine learning insights for supervised models
- Being able to model interaction effects with other features other than just topics like demographics and customer behaviors.
We live in the era of deep and targeted marketing segmentation. All these insights can be aggregated to ask questions like “What are the topics that correlate the most with positive and negative ratings?”, “How many customers are complaining about higher prices and low quality?” and so on.
-
These insights can then be used to design marketing campaigns, promotions, discounts, and other intervention strategies; and determine willingness to pay
References:
[1] Blei, David M., and Jon D. McAuliffe. Supervised topic models. In Proceedings of NIPS. 2007.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.






