This article was published as a part of the Data Science Blogathon.
Introduction
Transformers were one of the game-changer advancements in Natural language processing in the last decade.
A team at Google Brain developed Transformers in 2017, and they are now replacing RNN models like long short-term memory(LSTM) as the model of choice for NLP issues.
An innovative design called The Transformer in NLP tries to tackle sequence-to-sequence problems while skillfully managing long-range dependencies. It does not use sequence-aligned RNNs or convolution to compute its input and output representations but rather solely on self-attention. In other words, A transformer is a deep learning model that uses the self-attention process and weights the importance of each component of the input data differently.
Almost all companies in the data science domain are now searching for the transformer skills in their candidate’s resume during job interviews.
I will therefore demonstrate and discuss the top ten questions to enhance your Transformer proficiency in this blog. Therefore, before getting started, I hope that this article will be useful for beginners in understanding Transformer architecture. Use this opportunity to enhance your transformer skills if you have prior knowledge of the subject. So let’s begin

Questions to Test your Transformers Library Skills
1 – What are the benefits of transformers architecture in Natural Language Processing? Why should we use this?
Ans: The Transformer is the first transduction model to calculate representations of its input and output only via self-attention, without convolution or sequence-aligned RNNs. It is an NLP deep learning model. Greater parallelization during training was made possible by Transformer, allowing for training on bigger data sets.
Transformers are meant to analyze sequential input data, such as natural language, like recurrent neural networks (RNNs), and have translation and text summarization applications. Transformers, as opposed to RNNs, process the entire input at once. Any place in the input sequence can have context thanks to the attention mechanism. So this will increase the parallelism in data training and reduce the model training time.
Advantages of Transformers
- Showcase the parallelism nature, so it reduces the training time
- Able to understand the context of the natural language sentences
- Capture long-range dependency in the lengthy sentence
- Large language models can be trained using transformers quickly
- Provide open source models trained on Transformers
And many more.
2- What is positional encoding in transformers?
Ans: The position or order of the words and phrases in a sentence in any language is required to get the sentence’s full meaning or context. In earlier days in Recurrent Neural Networks, the text data passed sequentially to the network(LSTM/GRU) to maintain the order of the words in the sentence. This means the words in the sentence are fed to the network one by one. This increases the training time in Recurrent Neural Networks and the Vanishing gradient problem in the case of lengthy sentences.
The transformer architecture for better performance avoids this kind of sequential processing of words and instead integrates the parallel processing. So all the tokens(Words) in the sentence, whether lengthier or not, are passed simultaneously to the transformer module. So for capturing the context or meaning of the whole sentence without sequential processing, the transformer architecture uses positional encoding to understand the dependencies between words.
Positional encoding of a sentence contains positional details of each token in the input sentence. It includes multiple d-dimensional vectors containing information about a sentence’s specific position. These d-dimensional vectors are generated by applying the sin and cos trigonometric functions in the sentence embedding. For more details, check the snapshot from this documentation below.

3- Explain the Attention mechanism. How is it used in transformers?
Ans: The attention mechanism is the successor architecture in the encoder-decoder series. Initially, it was implemented in machine translation tasks. Adding the attention mechanism gave the encoder-decoder model for machine translation a performance boost. By combining all of the encoded input vectors in a weighted manner, with the most pertinent vectors receiving the highest weights, the attention mechanism was designed to enable the decoder to utilize the most pertinent portions of the input sequence in a flexible manner. In other words, the attention mechanism helps the decoder focus only on some input words while inferencing.
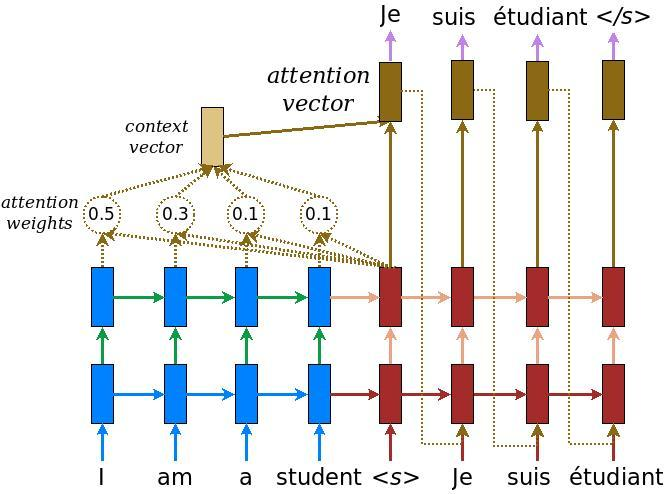
The attention mechanism was introduced by Bahdanau et al. (2014). It was put into place to deal with the bottleneck issue when using a fixed-length encoding vector since the decoder would only have restricted access to the input’s information. The dimensionality of their representation would be compelled to be the same as for shorter or simpler sequences, which is anticipated to become particularly problematic for long and/or complex sequences.
Attention is a method that simulates cognitive attention in neural networks. The purpose of the impact is to encourage the network to give greater attention to the little but significant portions of the input data by enhancing some and reducing others.
Transformer architecture uses the multi-head self-attention to capture the long-term dependencies between the words in the sentences. For more details, check this official documentation here – Attention, all you need.
4 – Explain different attention mechanisms and which attention is generally used in transformer architecture.
Ans: Based on the different constraints, attention mechanisms are broadly classified as follows
- Based on the softness of attention
- Soft attention
- Hard attention
- Local attention
- Global attention
- Based on input features
- Item-wise
- Location-wise
- Based on input representation
- Distinctive attention
- Co-attention
- Parallel
- Alternative
- Fine-grained
- Coarse-grained
- Self-attention – (Query, Key, Value-based)
- Hierarchical attention
- Based on output representation
- Single output attention
- Multi output attention
- Multi-head attention
- Multi-dimensional attention
Generally, transformer architecture is implemented using the Multi-head Self Attention mechanism
5- Explain the different components in transformer architecture
Ans: Here is the transformer architecture
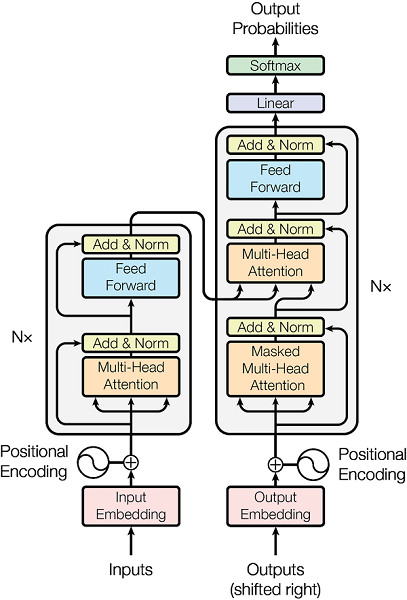
Different components of transformer architecture can be picturized as follows
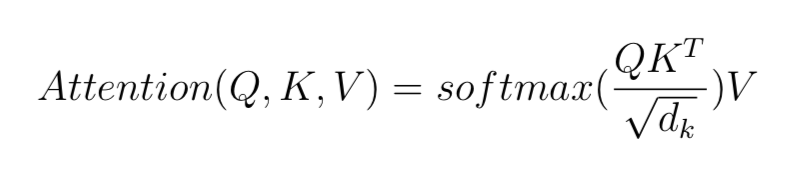
Components
A – Encoder :
The transformer’s encoder is made up of many encoder blocks. The encoder blocks process the input sentence, and the final encoder block’s output becomes the decoder’s input features.
B- Decoder:
The decoder uses the features to produce an output sentence (In the machine translation case). It generates an output sequence using the encoder’s output and the decoder’s output from the preceding time step.
C – Multi-head attention Layer :
A module for attention mechanisms called “Multi-head Attention” cycles repeatedly and simultaneously through an attention mechanism. The predicted dimension is then created by linearly combining the separate attention outputs.
D – Masked Multi-Head Attention Layer:
Attention is focused in the Masked Multi-Head Attention Layer on tokens up to the current position (the index up to which the transformer does prediction) and not on future tokens, which have not yet been predicted. This is a glaring contrast compared to the encoder, where attention is calculated for the entire sequence at once.
E- Feed Forward layer :
It is a position-wise transformation module that includes ReLU and additional linear transformations. This role and goal is to process the output from one attention layer in a way that better fits the input for the following attention layer.
F- Positional encoding:
To give each position a distinct representation, positional encoding represents the location or position of an entity in a sequence.
6 – How many encoders and decoders are used in the vanilla transformers architecture?
Ans: There are six encoder levels (self-attention layer + feed-forward layer) used by Vanilla Transformer, followed by six decoder layers.
7- How is attention calculated in the transformer?
Ans: Attention is working based on Query(Q), Key(K), and Value(V) properties.
The Queries, Keys, and Values of the embedding matrix are the three representations used by the Transformer. These embedding metrics are calculated based on multiplying the embedding vectors with different weight matrices Wk, Wq, and Wv.
K is the encoder embedding vector (the side we are given), V is the encoder embedding vector, and Q is the decoder embedding vector (the side we want). This attention mechanism is all about establishing the relationship (weights) between the Q and all of those Ks. We can then utilize these weights (freshly computed for each Q) to compute a new vector using Vs. (which should be related to Ks).
The attention mechanism formula is given below
The scaled dot-product attention scoring function was used in the original research to express the correlation between two words (the attention weight). Be aware that there are other similar functions that we can use. The division by the root of dk is just used as a scaling factor to prevent the vectors from exploding in this situation.
For more details, please refer to the original paper.
8- What are the differences between cross-attention and self-attention?
Ans: Attention connecting the encoder and the decoder is called cross-attention since a different sequence than queries generates keys and values. If the keys, values, and queries are generated from the same sequence, then we call it self-attention. The attention mechanism allows output to focus attention on input when producing output, while the self-attention model allows inputs to interact with each other.
9- Why are the residual connections needed in transformer architecture?
Ans: The residual connections in the transformer are represented in the figure.
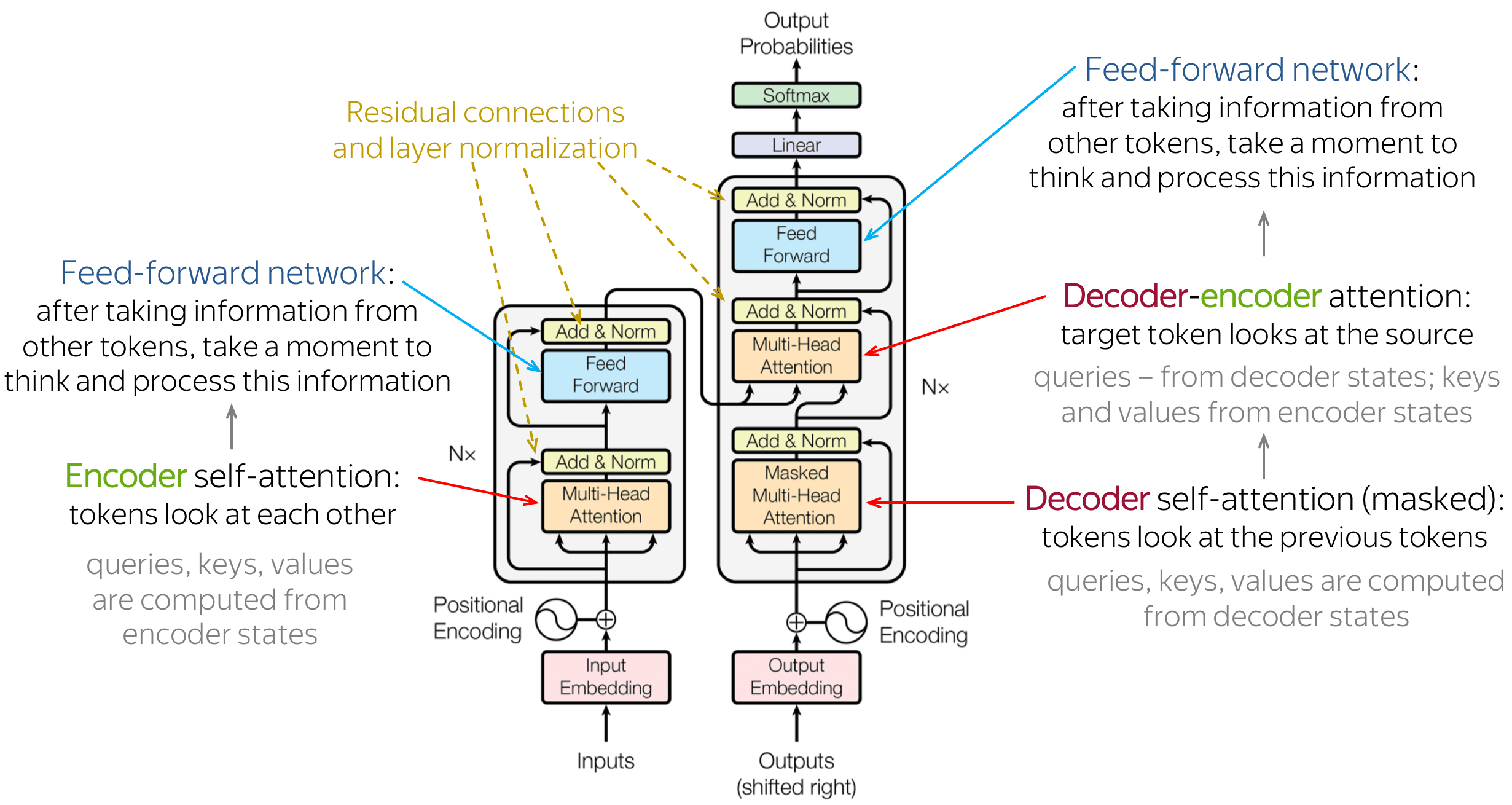
Residual connections mainly mitigate the vanishing gradient issue. The signal is multiplied by the activation function’s derivative during back-propagation. In the case of ReLU, this indicates that the gradient is zero in about 50% of the instances. Without the remaining connections, the training signal would lose significant energy during backpropagation. Because summing is linear concerning derivative and residual connections reduce the effect, the vanishing gradient also receives an unaffected signal. In the computing graphs, the summation operations of residual connections create a path where the gradient does not stray.
The information remains local in the Transformer layer stack due to residual connections. The self-attention technique enables any input token permutation and arbitrary information flow in the network. However, the remaining connections constantly “remind” the representation of the initial state. An assurance that contextual representations of the input tokens accurately depict the tokens is provided to some extent by the residual connections.
Residual connections allow the gradients to flow through the network directly without affecting the activation functions.
10: What is the SentencePiece tokenizer used in the transformer?
Ans: SentencePiece is an unsupervised text tokenizer and detokenizer introduced by Google that is mostly used in neural network-based text production systems when the vocabulary size is chosen before the neural model training. This is one of the most using tokenization methods in transformers. SentencePiece extends direct training from raw sentences to subword units, such as byte-pair-encoding (BPE) and unigram language models. We can create a fully end-to-end system without using language-specific pre/post-processing with the help of SentencePiece. To read more about sentencepiece refer to this official documentation.
Conclusion
The major points I tried to explain in this blog are as follows
- A transformer is a deep learning model that uses the self-attention process and weights the importance of each component of the input data differently.
- It is largely utilized in the fields of computer vision (CV) and natural language processing (NLP)
- Showcase the parallelism nature, so it reduces the training time
- The transformer can capture the context of the lengthy sentences
- Positional encoding using in the transformer to address the order of the tokens in the sequence
- There are different types of attention mechanisms available, but vanilla transformer architecture uses the multi-head self-attention mechanism by nature
I hope this article enabled you to understand better and assess your transformer architecture knowledge. Feel free to leave a remark below if you have any questions, concerns, or recommendations.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A passionate data scientist. I love to explore data and extract insights that can help solve complex problems. With my knowledge of programming languages such as Python, I am proficient in developing models and analyzing large data sets. My passion for learning has led me to continuously expand my skillset and stay up-to-date with the latest trends in the field. I am committed to using data science to make a positive impact on society and believe that the power of data can transform businesses and organizations.





