This article was published as a part of the Data Science Blogathon.
Introduction
Data scientists, engineers, and BI analysts often need to analyze, process, or query different data sources. This requires developing a lot of ETL jobs and transforming the data to guarantee a consistent structure for making it available at any next step in the data pipeline, such as machine learning jobs or reporting tools.
In this blog post, I would like to provide a rough overview of the Apache Drill query engine. It describes the architecture of Drill, its capabilities, and some problems with its use. This post is for people who are currently in the process of deciding whether or not to use a query engine in their daily work.
Apache Drill
It was inspired by Google’s Dremel system, which is now part of the Google Cloud Platform infrastructure and is better known as Big Query. However, Drill is an open-source version of Dremel. It can be used with various databases, cloud storage systems, and all common Hadoop distributions, such as Apache Hadoop, MapReduce, Cloudera, and Amazon EMR.
Query Engine
The need and requirements for flexible search engines are not unusual these days: data scientists, engineers, and BI analysts often need to analyze, process, or query different data sources. This requires developing a lot of ETL jobs and transforming the data to guarantee a consistent structure for making it available at any next step in the data pipeline, such as machine learning jobs or reporting tools.
Apache Drill solves this problem by providing the ability to query data from various sources and systems out of the box without schemas. In addition, it provides a fast and powerful distributed execution engine for query processing. It supports several NoSQL databases, file systems, and data types that can be read and manipulated. The following table shows what is currently supported without additional configuration.
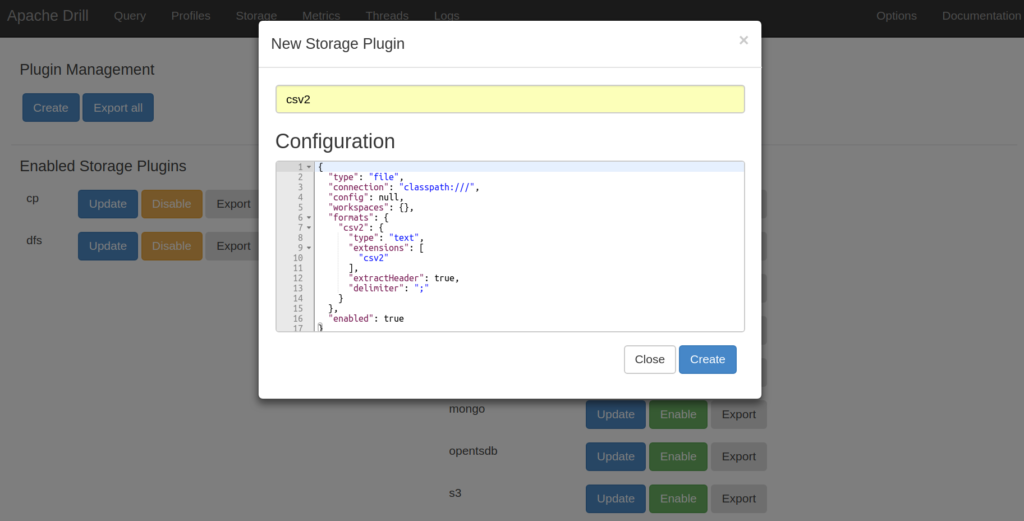
For any other data source, Drill provides the option to create so-called storage modules. These can be defined as JSON files describing the new data source. For example, Drill expects .csv files to be separated by commas. If you now have a semi-delimited file, it can easily be defined as a .csv2 file in the storage module.
 https://drill.apache.org/
https://drill.apache.org/This means that you are not really limited by data types and could potentially write a query that retrieves a .parquet file from HDFS, joins it to a hive table, and merges it with the data coming from MapR-DB (if these technologies are all used in your company):
SELECT customer_id AS c_id From dfs.`/var/inla/tables/customers` c --MapR-DB LEFT JOIN `hive.do.account ac --Hive table ON ac.customer_id = c.c_id UNION OF ALL SELECT d_customer_id FROM dfs.`/data/datahub/transactions` -- Parquet file
Drill supports JDBC/ODBC, so it can be used with any common IDE (eg DBeaver) or BI/analytics tool (eg PowerBI or Tableau) that uses these drivers for query development and data visualization.
That being said, the answer to the question in the title of this section is yes, Drill is just another query engine, but it provides a very high level.
Overview of Apache Drill
In the previous section, we saw the big advantage of Drill is that it can easily process different types of data without incurring much overhead. In addition to its flexibility, Drill also claims to be easy to use in installation and data preparation. There is no need to load data and transform it before Drill can process it, or create and maintain schemas. Users can query raw data in almost any system, regardless of type. The drill will take care of the rest himself.
Therefore, it provides a set of standard SQL functions for querying data. Tables can be created and dropped using the create and drop commands. The same applies to views using the replace command. Drill supports regular table expressions to help you write complex queries. You can also partition tables by column to make loading a subset of the data more efficient and reduce the cost of your queries.
Drill also provides some advanced SQL features, such as merging nested data. Because it can read hierarchical formats such as JSON, it offers a merge function that reduces the complexity of nested data structures. With flatten, you can split fields into separate rows, which makes queries easier and transforms the data in a way that fits better into the structure of the data warehouse.
Unfortunately, there is one shortcoming that I often miss when using Drill. Drill currently does not support inserting, updating, or deleting rows. This means there is no direct way to edit data that Drill has already processed. Every time we want to change a persistent Drill table, we will have to completely delete the table and recreate it with our changed data. Especially when using Drill to run a data warehouse, it can be quite expensive to recreate each table whenever new data is delivered.
This is the first point where we see that Drill’s flexibility comes at a cost. There’s more at the end of this article, but before that, let’s take a quick look at the architecture and how it can be set up.
Query Execution
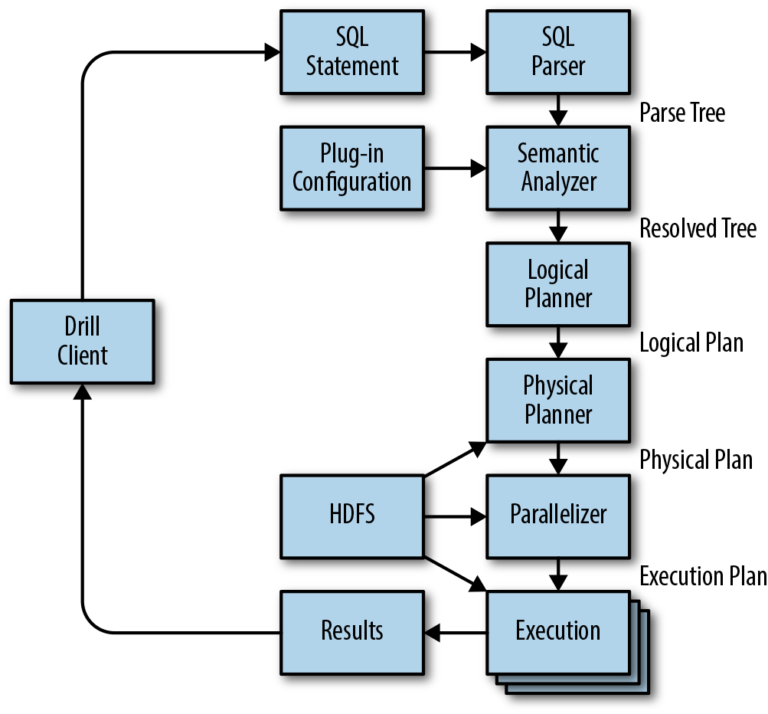
When a client runs a query, it is sent to Drillbits’ Zookeeper quorum. One of the Drillbits accepts the query and thus becomes the so-called foreman for that particular query. For the entire subsequent process, this Drillbit remains the master and has the responsibility of managing the execution of the query. It starts by creating a logical plan by parsing the query using the built-in SQL Parser based on Apache Calcite. The query is then optimized, resulting in the most efficient execution plan. This execution plan also considers the data’s location in the cluster. Therefore, it is recommended to have Drillbit available on every single node in the cluster.
https://drill.apache.org/
The foreman knows through ZooKeeper the availability and location of each Drillbit and is, therefore, able to assign different amounts of execution plan fragments to each one to maximize performance. Each larger fragment is split into several smaller fragments that run optimized SQL code on the data slices. Then the result is sent back to the master, which collects all the results of the other fragments and provides the final result to the client.
Working with Apache Drill
Now that we know what Drill is capable of and how it is built and executes queries, it’s time to talk about how these features work in a real-world scenario.
Let’s start with Drill’s biggest feature:
Maximum Flexibility
As I mentioned above, Drill’s great flexibility comes at a cost. This applies not only to some SQL functions but also to data sources: The great flexibility of Drill only applies if the queried data have the same structural characteristics. For example, if you query a directory containing multiple JSON files that do not all contain the same hierarchical structure, Drill cannot infer the schema of those files and will fail to read them. As a workaround, you would have to create datatypes from JSON files with a fixed schema, such as parquets, for Drill to query the data, making the full benefit of Drill obsolete.
Another issue with Drill’s read schema error approach is the missing data type definition for each column. Drill defines them themselves when reading the data. Due to splitting data into several fragments during query execution, one of these fragments may process a data segment where one column is not filled with any data (NULL values). By default, Drill interprets NULL values as Integer(!). If another fragment has a data segment where the same column contains a string, the column within that fragment will be treated as a string type. As for joining the query results between all the shards, it would cause a schema change exception and the entire query to fail.
Performance Tuning
For using Drill in a production environment, it is of particular interest to know how performance issues can be addressed when querying big data. Drill claims to be fast due to distributed query execution in a cluster. However, this only applies if enough resources are provided for Drill. The main problem is that querying large amounts of data does not lead to longer query durations but to simple failures to execute those queries. To avoid this, ensure that each Drill has enough resources. Drill-on Yarn can be adjusted quite easily by changing the parameters in the drill-on yarn.conf file:
• Direct memory
• Heap memory
• Caches
If basic resource modification does not help, or enough memory is already used for a particular task, Drill still refuses to execute the query correctly; there is only one option left – configuring Drill.
Conclusion
Apart from the points mentioned above, there are still a few minor bugs, which is why I would not recommend using Drill in an IT project. For example, when merging tables, a bug recently produced incorrect numbers in columns with decimal data types. A comma was shifted in these numbers through UNION, resulting in false results. But still, when building a data warehouse, this type of error is not acceptable.
- Apache Drill solves the problems by providing the ability to query data from various sources and systems out of the box without schemas. In addition, it provides a fast and powerful distributed execution engine for query processing.
- Apache Drill is a tool with high ambitions, but unfortunately, it cannot fulfill all. It tries to be the Swiss Army Knife of query engines but falls short on small but important things, making it difficult to use in real-world projects.
- Drill also provides some advanced SQL features, such as merging nested data. Because it can read hierarchical formats such as JSON, it offers a merge function that reduces the complexity of nested data structures.
- Drill also provides some advanced SQL features, such as merging nested data. Because it can read hierarchical formats such as JSON, it offers a merge function that reduces the complexity of nested data structures.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a Machine Learning Enthusiast. Done some Industry level projects on Data Science and Machine Learning. Have Certifications in Python and ML from trusted sources like data camp and Skills vertex. My Goal in life is to perceive a career in Data Industry.





