This article was published as a part of the Data Science Blogathon.
Introduction
Impala is an open-source and native analytics database for Hadoop. Vendors such as Cloudera, Oracle, MapReduce, and Amazon have shipped Impala. If you want to learn all things Impala, you’ve come to the right place.

It rapidly processes large amounts of data using traditional SQL knowledge. You should know the basics of Apache Hadoop and HDFS commands to learn Impala. Basic knowledge of SQL is an advantage when learning Impala.
What is Impala?
Impala is an open-source and native analytics database for Hadoop. It is a Massive Parallel Processing (MPP) SQL query engine that processes massive amounts of data stored in a Hadoop cluster.
Impala provides high performance and low latency compared to other SQL engines for Apache Hadoop, such as Hive.
In simpler terms, we can say that Impala is the most powerful SQL engine that provides the fastest way to access data stored in HDFS (Hadoop Distributed File System). Impala is written in Java & C++.
Apache Impala raises the bar for SQL query performance on Hadoop while maintaining a familiar user experience. We can query data stored in either HDFS or Apache HBase with Apache Impala. We can perform real-time operations like SELECT, JOIN, and aggregation functions with Impala.
Apache Impala uses the same Hive Query Language (SQL) syntax, metadata, user interface, and ODBC drivers as Apache Hive, providing a familiar and unified platform for batch-oriented or real-time queries.
This allows Hive users to use Apache Impala with little setup overhead. However, Impala does not support all SQL queries; some syntax changes may occur. Impala Query Language is a subset of Hive Query Language with some functional limitations such as transformations.
Reasons to Use Apache Impala
1. Apache Impala combines the flexibility and scalability of Hadoop with the SQL support and multi-user performance of a traditional analytics database using components such as HDFS, Meta store, HBase, Sentry, and YARN.
2. With Apache Impala, users can easily interact with HDFS or HBase using SQL-like queries faster than other SQL engines like Apache Hive.
3. Apache Impala can read almost all file formats like Parquet, RCFiand le, and Avro, which Apache Hadoop uses.
4. Additionally, it uses the same SQL (Hive SQL) syntax, metadata, user interface, and ODBC driver as Apache Hive, providing a familiar and unified platform for batch-oriented or real-time queries.
5. Impala is also not based on MapReduce algorithms like Apache Hive.
Apache Impala Architecture
The image above shows the Impala architecture. Apache Impala runs several systems in an Apache Hadoop cluster. Unlike traditional storage systems, Apache impala is not tied to its storage core.
It is separate from its storage engine. Impala has three core components: the Impala daemon (Impala), the Imp state store, and the Impala Catalog services.
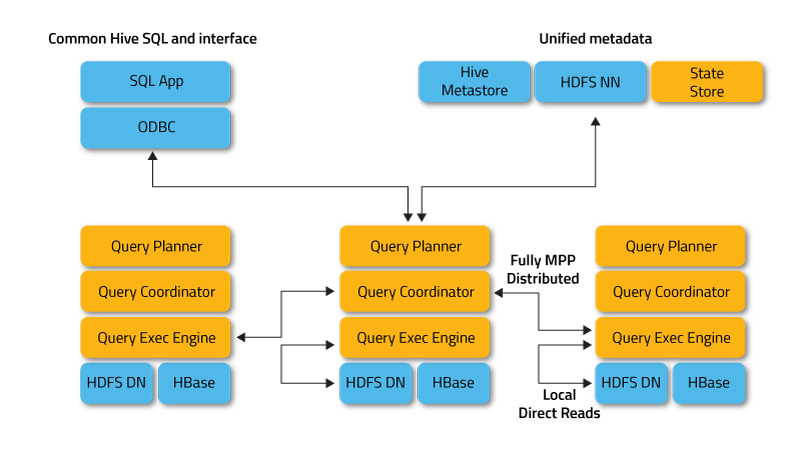
source: https://impala.apache.org
1. Impala Demon
The Impala daemon is a core component of Apache Impala. The impalad process physically represents it. The Impala daemon runs on every computer where Impala is installed. The main functions of the Impala daemon are:
- Reads and writes to data files.
- Accepts queries passed from impala-shell, JDBC, Hue, or ODBC.
- Impala Daemon parallelizes queries and distributes work across the Hadoop cluster.
- Transmits ongoing query results back to the central coordinator.
- Impala daemons constantly communicate with the StateStore to confirm which daemons are healthy and ready to accept new work.
- Impala daemons also receive broadcast messages from the cataloged daemon (discussed below) at any time
- Any Impala daemons will create, drop, or modify any type of object.
- When Impala processes an INSERT or LOAD DATA statement.
- For Implementing impala, we can use one of these methods:
- Locate HDFS and Impala together, and each Impala daemon should be running on the same host as the DataNode.
- Deploy Impala alone in a compute cluster that can remotely read data from HDFS, S3, ADLS, etc.
2. Impstatestoretore
The Impstatestoretore is the one that checks the health of all the Impala daemons in the cluster and continuously communicates its findings to each of the Impala daemons. The Impstatestoretore is physically represented by a daemon process cal state stored red.
We only need the state store tore process on one host in the cluster. So if any Impala demagogues are offline due to a network error, hardware failure, software problem, or other reason, the Impala StateStore notifies all the other Impala daemons.
This ensures that future queries do not send requests to the failed Impala daemon.
The Impstatestoretore is not always critical to the normal operation of an Impala cluster. If the StateStore is not running this case, the Impala daemons will also be running and distributing work among themselves as usual.
In this case, the cluster will become less robust when other Impala daemons fail, and the metadata will be less consistent. When the Impala StateStore returns, it resumes communication with all Impala daemons and continues its monitoring and broadcasting functions.
3. Impala Catalog Service
The catalog service is another Impala component that propagates metadata changes from Impala SQL commands to all Impala daemons in the cluster. The Impala catalog service is physically represented by a daemon process named cataloged.
We only need a cataloged process on one host in the cluster. Since requests are passed through the StateStore daemon, running the stateful and cataloged process on the same host is best.
The Impala catalog service avoids the need to issue REFRESH and INVALIDATE METADATA commands when metadata changes have been made by commands issued through Apache Impala.
When we create a table or load data through Apache Hive, we must issue a REFRESH or INVALIDATE METADATA before executing any query on the Impala node.
Apache Impala Features
The key features es of the Impala are –
- Provides support for in-memory data processing; it can access or analyze data stored on Hadoop DataNodes without any data movement.
- Using Impala, we can access data using SQL-like queries.
- Apache Impala provides faster access to data stored in the Hadoop Distributed File System compared to other SQL engines such as Hive.
- Impala helps us to store data in storage systems like Hadoop HBase, HDFS, and Amazon s3.
- We can easily integrate Impala with business intelligence tools such as Tableau, Micro strategy, P, Pentaho, and Zoom data.
- Provides support for various file formats such as LZO, Avro, RCFile, Sequence File, and Parquet.
- Apache Impala uses the ODBC driver, user interface metadata, and SQL syntax as Apache Hive.
Conclusion
In short, we can say that Impala is an open-source and native analytics database for Hadoop. Impala is the most powerful SQL engine that provides the fastest access to data stored in HDFS (Hadoop Distributed File System).
Impala uses the same Hive Query Language (SQL) syntax, metadata, user interface, and ODBC drivers as Apache Hive. Unlike traditional storage systems, Apache impala is not tied to its storage core.
It consists of three core components Impala daemon, Impala state store, and Impala Catalog. The Impala Shell, the Hue browser, and the JDBC/ODBC driver are three query processing interfaces we can use to interact with Apache Impala.
- Impala does not support all SQL queries. Some syntax changes may occur. Impala Query Language is a subset of Hive Query Language with some functional limitations such as transformations.
- Apache Impala combines the flexibility and scalability of Hadoop with the SQL support and multi-user performance of a traditional analytics database using components such as HDFS, Meta store, HBase, Sentry, and YARN.
- Impala is written in Java & C++. Apache Impala raises the bar for SQL query performance on Hadoop while maintaining a familiar user experience. We can query data stored in either HDFS or Apache HBase.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





