This article was published as a part of the Data Science Blogathon.

Introduction
The current decade is a time of unprecedented growth in data-driven technologies with unlimited opportunities. Since the last decade, as data science and AI have started appearing in the mainstream production environment, the collection and maintenance of massive data have become inevitable. While most organizations collect large amounts of data from their user base, they often have no idea what to do with it. Having state-of-the-art cloud infrastructure alone cannot solve organizations’ data management issues. Data breaches have become common, regulations and compliances are often not met, security policies are weakly enforced, data silos keep increasing along with substantial technical debt, and finally, the trust in analytics and AI applications has been diminished. The AI applications must be reliable, responsible, and transparent. Like any other technology, AI tools affecting businesses and human lives should deliver the expected outcome. But trustworthy AI cannot be delivered without trustworthy data.
.jpg)
Photo by Andrea De Santis on Unsplash
Without a coherent and robust data strategy, an enterprise data asset is like a ship without a rudder. The organizations keep struggling to orchestrate, govern, analyze the data assets, and develop meaningful data products with trust and transparency. An AI solution built on a weak data strategy can bring temporary values, but no long-term impact exists. Modern data strategies woven into the organization’s processes and workflows are the main driving forces behind developing innovation and trustworthy AI practices.
The Five Key Aspects
The organization needs to craft its data strategy carefully for a mature, innovation-driven analytics practice. Here are the five key aspects the data team should address in their enterprise data strategy to develop a trustworthy AI practice.
1. Democratized Data Assets
Without a standard data policy across the organization, many departments often develop data silos. Each department may have its own data team gathering, storing, and controlling the data assets of the very department. These data silos are not easily accessible by the other departments or at the organizational level in general. These are the biggest obstacles to data-driven collaboration and innovation. They limit the 360-degree view of the data and prevent data integrity and transparency. For developing impactful AI applications and extracting meaningful insights through analytics, democratizing the data is essential. Sometimes it may need to change the company culture, especially if it is of a conservative type and executive-level support is required. Developing a centralized view of the data assets is necessary. Data fusion and data virtualization through data fabric and data mesh-like architecture can solve this problem too. Creating a shared data platform can foster innovation and agility.
Image source: ezdatamunch.com
2. Data Governance at Scale
Most organizations work in a multitenant and multi-technology environment. Gauging the underlying risk and security threats and measuring performance in this kind of landscape is difficult without the constant management of data assets from acquisition to disposal. With proper identity and access management, data granularity, data anonymization, policy enablement, feasibility study, and impact analysis, data governance at scale can be achieved, which would be aligned with business outcomes. Cross-industry data sharing is also gaining traction, and a strong data governance process should exist. Fraud detection in finance, insurance, healthcare, etc., develops novel business use cases. With proper data governance in place, organizations can focus on developing marketable AI applications without concern about compliance, restrictions, and regulatory risks. It also increases the transparency and trust of the AI applications that consume enterprise data. Cloud solutions such as Azure Purview or Collibra on AWS offer data governance solutions with automated data discovery, sensitive data classification, end-to-end data lineage at scale, etc.
3. Automated Data Orchestration
Orchestration helps in combining and organizing data from multiple sources and data silos. Automated data orchestration helps organizations to streamline data-driven decision-making through different pre and post-processing methodologies. Data orchestration readiness achieved through data manipulation, transformation, and load balancing accelerates AI-based decision-making in a secured and trusted manner. It can also be embedded into data engineering pipelines as automated workflows. Cloud platforms come up with data pipeline orchestrator tools with multiple offerings. Azure platform has Azure Data Factory, Oozie on HDInsight, and SQL Server Integration Services (SSIS) available for pipeline orchestration, control flow, and data movement. AWS Step Functions provide serverless data orchestration service to build applications by combining different AWS services. GCP’s Cloud Composer is a fully managed data orchestration service built on Apache Airflow.
4. Robust Data Quality Management
Gartner, Inc. estimates that poor data quality costs organizations an average of $12.9 million annually. Organizations must establish robust data quality management (DQM) frameworks during collection, storage, and transfer. Raw data are usually untrusted with poor quality and lack of meaning. Data integrity and inconsistencies should be regularly checked with clear data profiling, data ownership, and accountability. There should be clearly defined data quality rules, standards, and automated scoring, and the improvement needs to be tracked properly. Quality data build up quality AI applications that are responsible and trustworthy. Gartner Magic Quadrant for Data Quality Solutions published in September 2021 shows Informatica Data Quality (IDQ), IBM InfoSphere, SAP Data Services, Talend Open Studio, Precisely Data360, etc. as market leaders in the Data Quality solutions market.
5. Data Map
With the exponential growth of enterprise data in every sector, organizations have disparate and heterogeneous data sources for their applications. Leveraging the full potential of the enterprise data and viewing their relationships are impossible without properly mapping the data from source to destination. A standardized data mapping process is indispensable in data integration, migration, or transformation work. Data lineage gives a pictorial representation of the enterprise data flow and its operations from source to destination. A proper data catalog can help organize and search data assets and manage metadata. All these processes are useful in building trustworthy AI pipelines. It brings transparency to AI applications by end-to-end mapping of the data sources and data transformations happening on the data assets. While cloud vendors offer data lineage tools as their services, other key players also in this solution area, such as Dremio, Talend, Atlan, OpenLineage, etc.
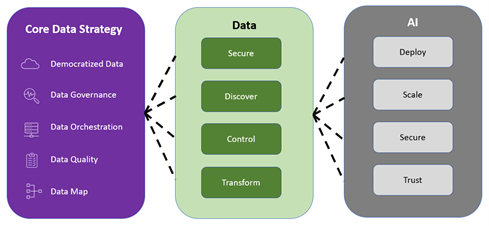
Conclusion
We have discussed the five key aspects of enterprise data strategy for developing trustworthy AI practices. These five aspects can help build quality data products and a reliable ecosystem. We have learned that:
- The enterprise data assets must be democratized by breaking the data silos.
- A scalable data governance practice needs to be there to manage data assets constantly.
- An automated data orchestration service is required to streamline data-driven decision-making.
- Robust Data Quality Management (DQM) and frameworks should be in place for handling data in its entire life cycle.
- A proper data map is needed to leverage the enterprise data’s full potential.
A successful data strategy requires the right tools and technologies in place. An organization may also need to optimize data infrastructure. Do you think that the data in your organization has been democratized? Or are there robust data governance and a data quality check practice in place? Let me know in the comment section.
Connect with me on LinkedIn for further discussion on Data Science or otherwise.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A data scientist with 12 years of industry experience in innovative technical consulting, research and development, statistical modelling, systems design, and application development with the passion for turning raw data into products, actionable insights, and meaningful stories.





