Source: Canva
Introduction
Contextual ASR, which uses a list of biasing terms as input and audio, has gained popularity as virtual assistant (VA) devices with speech interfaces is increasing. I’m sure many of us have had experiences with virtual assistants where the virtual assistant did not understand the spoken audio/word correctly about the context. For example, if the word “Apple” in the sentence “I like the interface provided by Apple” is interpreted in the context of a fruit by the VA, then this interpretation would be incorrect based on the context (interface) in this instance. Scenarios like this highlight the importance of devising robust ASR solutions which could decipher the spoken audio correctly based on context.
In light of this, we will look at one such technique for contextual biasing in this article, which entails adding a contextual spelling correction model on top of the end-to-end ASR system. This method is proposed by Xiaoqiang Wang et. al.
To begin, we will go over the highlights of this article, followed by a detailed discussion of the proposed methods in the following sections. Now, let’s get started!
Highlights
-
To make intelligent and competitive contextual ASR systems, a method for contextual biasing that involves adding a contextual spelling correction model on top of the end-to-end ASR system is proposed.
-
The proposed model includes the autoregressive contextual spelling correction (CSC) model and the non-autoregressive Fast Contextual Spelling Correction (FCSC) model.
-
Effective filtering algorithms for large-size context lists and performance balancing mechanisms to control the biasing degree of the model were also put forth.
-
Experiments suggest that the proposed method reduces the ASR system’s relative word error rate (WER) by up to 51% and outperforms traditional biasing methods. The FCSC (NAR) model decreases the model’s size by 43.2% and accelerates inference by 2.1 times compared to the CSC (AR) solution.
What is Contextual Biasing?
Contextual biasing is a crucial and challenging task for end-to-end automatic speech recognition (ASR) systems, which aims to achieve better recognition performance by biasing the ASR system with a user-defined list of important words and phrases, including person names, music lists, proper nouns, etc. that are submitted along with the audio to be transcribed.
Contextual ASR is most often studied for virtual assistant devices with speech interfaces, given that these systems must recognize the names of a user’s contacts when that user wants to dial the phone number or the names of artists in a user’s music library when that user wants to listen to a certain song.
Traditionally, there are two main methods for adding contextual knowledge to E2E ASR systems. First, an external contextual language model (LM) could be added to the E2E decoding framework to bias the recognition results towards a context phrase list. Typically, this is done using shallow fusion with a contextual finite state transducer (FST). Second, including a context encoder that incorporates contextual information into E2E ASR systems. However, this method changes the source ASR model and has scalability issues with a large biasing phrase list.
In contrast to these traditional methods, a new method was proposed to do contextual biasing on the ASR output with a contextual spelling correction model, which we will discuss in the following section.
Model Architectures
To have reliable ASR output, contextual biasing is done on the ASR output using a contextual spelling correction model. The proposed model includes two mechanisms: autoregressive (AR) and non-autoregressive (NAR).
1. Autoregressive contextual spelling correction (CSC) model:
-
As depicted in Figure 1, the autoregressive contextual spelling correction model, also known as Contextual Spelling Correction (CSC), is a seq2seq model with a text encoder, a context encoder, and a decoder, which uses the ASR hypothesis as the text encoder input and the context phrase list as the context encoder input, respectively.
-
The context encoder encodes each context phrase as hidden states, and the context embedding generator then averages these hidden states to generate context embedding.
-
The decoder uses the output of the previous step as input auto-regressively and subsequently attends to the outputs of both the encoders. These attentions are then added to generate the final attention, from which the decoder obtains information from the ASR hypothesis and context phrase embeddings to correct contextual misspelling errors.
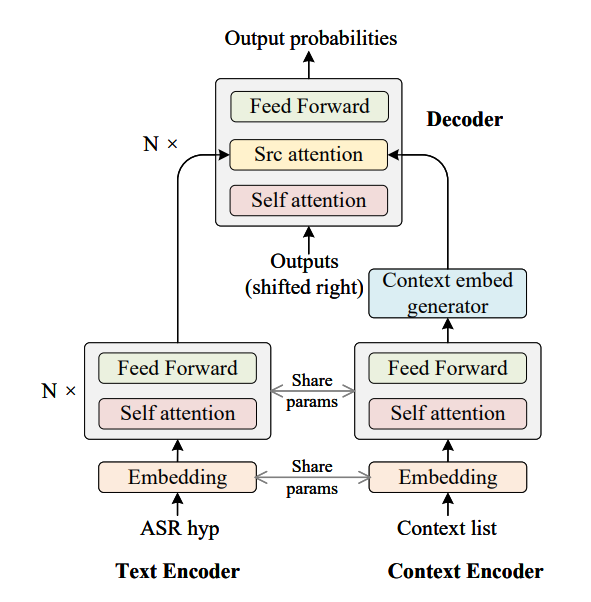
Fig. 1. Autoregressive contextual spelling correction (CSC) model (Source: Arxiv)
-
Since both the text encoder and the context encoder use transcriptions as inputs, it makes sense that their parameters would be shared, reducing the model size and facilitating context encoder training.
-
The final loss is the cross entropy of the ground truth label and output probabilities.
2. Non-autoregressive contextual spelling correction (FCSC) model:
-
As shown in Figure 2, similar to the Autoregressive CSC model, the proposed NAR model, denoted as Fast Contextual Spelling Correction (FCSC), consists of a text (ASR hypothesis) encoder, a context encoder, and a decoder, where the text encoder uses ASR decoding results as input. In contrast, the context encoder takes biasing phrase list as input.
-
Both the encoders share the parameters. The decoder effectively takes the output of the text encoder as an input and attends to the context encoder to determine where corrections need to be made.
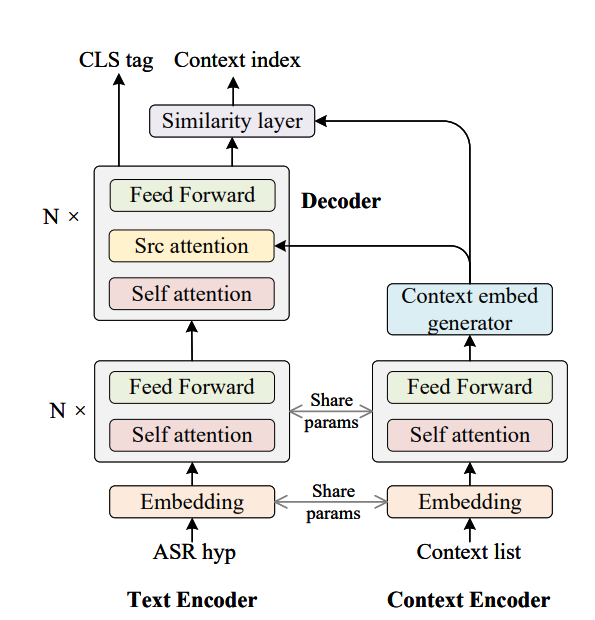
Fig. 2. Non-autoregressive contextual spelling correction (FCSC) model (Source: Arxiv)
-
The output hidden states of each context phrase are averaged to generate the context phrase embedding by the context embedding generator. The similarity layer determines how similar hidden states in decoder output are to context embeddings by an inner product operation:
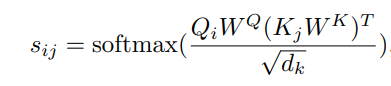
Where Qi is the hidden state of the decoder at the i-th position, Kj is j-th context phrase embedding, and dk is the dimension of K.
-
CLS tag (cls): The CLS tag has the same sequence length as the input ASR hypothesis, which determines whether to correct the token at this position. It employs a “BILO” representation in which “B”, “I” and “L” represent the beginning, inside, and the last position of a context phrase, respectively, and “O” represents a general position outside of a context phrase.
-
Context index (cind): It is the output of the similarity layer, which is the expected index of the ground-truth context phrase in the bias list. Since an empty context precedes the bias list, the context index for general tokens, which should not be corrected, is 0. As indicated by the following equation, the output hid dimension of the similarity layer at each position i is the same as the input bias list size, and the context phrase corresponding to the largest
value in si is selected during decoding for this position:
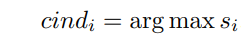
-
Based on the output CLS tag and context index, the final correction results are determined by changing the words tagged by the CLS tag with the context phrase selected by the context index cind.
-
Filter mechanisms for the context list are suggested during inference to increase inference effectiveness and address scalability problems for large context lists.
-
The key difference between the CSC and FCSC is that the FCSC focuses on biasing phrases, while the CSC has the potential to correct errors made by the ASR system. Also, FCSC generates results in parallel, and label-by-label prediction is not required, which speeds up the decoding speed.
Results
On testing, the following outcomes were observed:
1. WER Reduction: Table 1 illustrates that the NAR (FCSC) solution outperforms the autoregressive CSC model among all the test sets. This may be because the former doesn’t have to align the encoder and decoder by using a length or duration predictor to avoid the possibility of error accumulation.
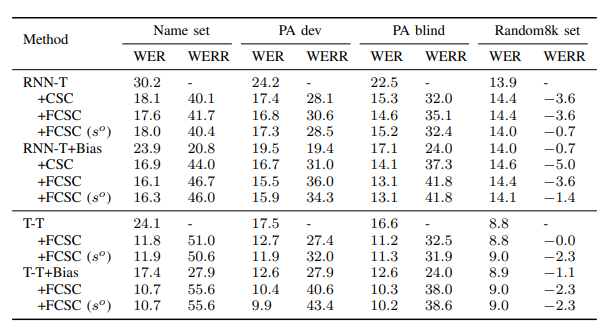
Table 1: Model performance on the name domain (Source: Arxiv)
Furthermore, the model performance on the two general biasing sets is shown in Table 2 from which it can be inferred that the model achieves approximately 50.7% relative WER improvement compared to baseline RNN-T.
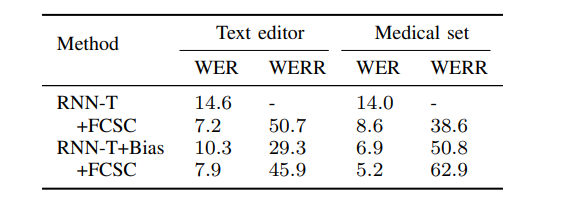
Table 2: Model performance on general biasing sets (Source: Arxiv)
2. Latency improvement: The NAR model decreases the model’s size by 43.2% and speeds up the inference by 2.1 times, which makes the on-device deployment of the NAR model advantageous over the AR solution. Moreover, this latency can be further reduced and optimized in runtime by calculating context phrase encoding in advance and loading as a cache in the real application.
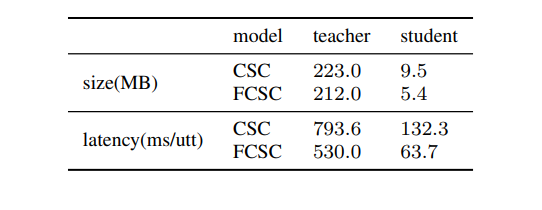
Table 3: Model size and latency (Source: Arxiv)
3. Influence of Context List Size: WER tends to increase with Kr in a concave curve for both CSC and FCSC, indicating that raw context list size has little effect on model performance when it is large enough, and the proposed method can handle the scalability problem well. Figure 3 also illustrates that the WER curve of FCSC mostly lies below CSC for both Kr and Kf, demonstrating that FCSC consistently outperforms CSC with the change in decoding parameter.
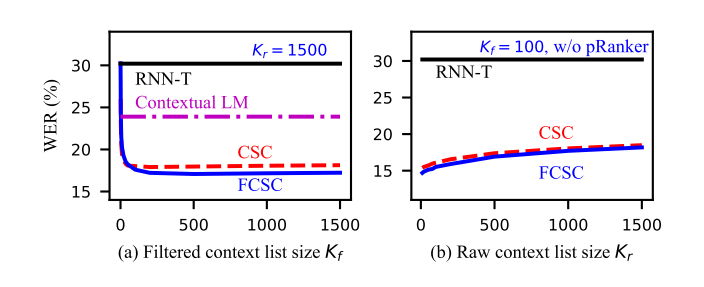 Fig. 3. Effect of filtered context list size (Kf) and raw context list size (Kr) on model performance. (Source: Arxiv)
Fig. 3. Effect of filtered context list size (Kf) and raw context list size (Kr) on model performance. (Source: Arxiv)4. Performance balancing of FCSC: When the model is overly biased, it can suffer from regressions in anti-context scenarios. To effectively control the regression on anti-context cases, a portion of the training set is general scripts without context phrases which teaches the model to decide when to make corrections based on the context phrase list and the input ASR hypothesis. Nevertheless, regressions still occur in some cases.
To navigate this, performance balancing mechanisms are proposed to modify biasing degree and control any WER regressions on general utterances that we don’t want to bias. For FCSC, a regression control mechanism is put forth that uses a controllable threshold parameter so to balance model performance between biasing set and anti-context cases.
The relative WER gap narrowing ratio (r) is defined as follows:
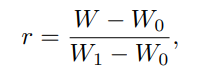
Where W represents WER, W0 and W1 represent the WER
for so = 0 and so = 1, respectively. Figure 5 shows the variation of r with the change in so. We can see that the WER on the Name set experiences a protracted flat period when it is small and then experiences a steep increase only when close to 1.0, indicating that the majority of the cases in the Name set are corrected with sufficient confidence to provide enough of a safe environment for us to carry out performance balancing.
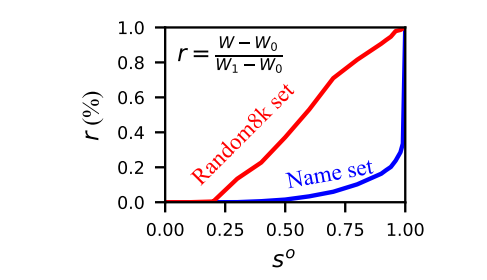
Fig. 4. WER relative change with so (Source: Arxiv)
Conclusion
To summarize, in this article, we learned the following:
1. A method for a general contextual biasing solution that is domain-insensitive that involves adding a contextual spelling correction model on top of the end-to-end ASR system is proposed. The proposed method includes two variants: i) Autoregressive contextual spelling correction (CSC) model and ii) Non-autoregressive Fast Contextual Spelling Correction (FCSC) model.
2. CSC model consists of a text encoder, a context encoder, and a decoder. This design augments a context encoder into an AR E2E spelling correction model. The contextual information is added to the decoder by attending to the hidden representations from the context encoder using an attention mechanism.
3. For the FCSC model, the output of the text encoder is directly fed into the decoder. The decoder attends to the context encoder and determines the locations that need to be corrected and the candidate context index.
4. The NAR (FCSC) solution reduces the model size by 43.2% and speeds up the inference by 2.1 times while achieving WER improvement. Moreover, the results are generated in parallel and don’t need to conduct label-by-label prediction in AR; hence, the decoding speed is fast.
5. Effective performance balancing mechanisms to balance model performance on anti-context terms and filtering algorithms to handle large-size context lists were also implemented.
That concludes this article. Thanks for reading. If you have any questions or concerns, please post them in the comments section below. Happy learning!
Link to the Research Paper: https://arxiv.org/pdf/2203.00888.pdf
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]




