This article was published as a part of the Data Science Blogathon.
Introduction
Over the past few years, Snowflake has grown from a virtual unknown to a retailer with thousands of customers. Businesses have adopted Snowflake as migration from on-premise enterprise data warehouses (such as Teradata) or a more flexibly scalable and easier-to-manage alternative to an existing cloud data warehouse (such as Amazon Redshift or Google BigQuery).
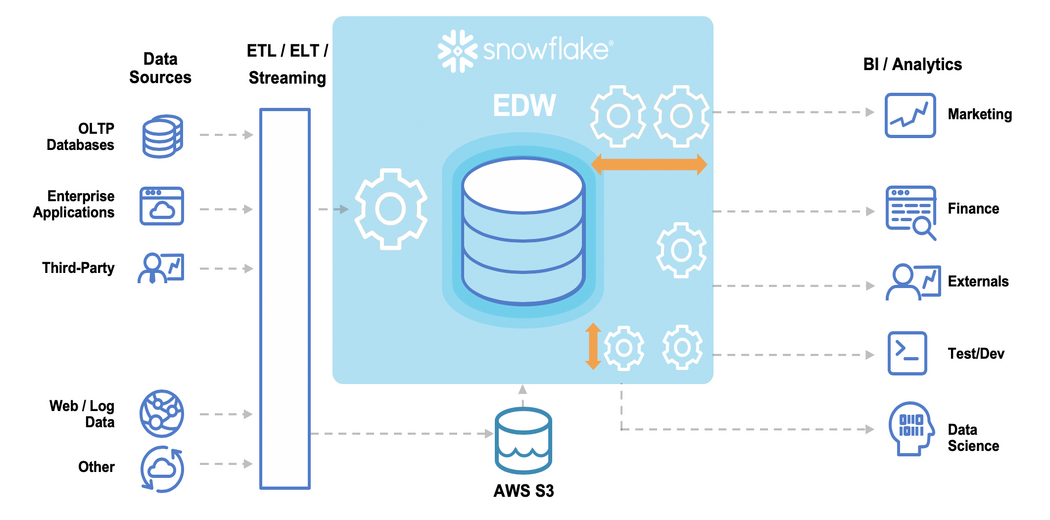
Because of the significant investment that Snowflake often represents, some data teams are considering it for every use case. This inevitably leads organizations to compare data lakes to Snowflake and other cloud data warehouses. (The data lake is another data platform that has emerged in the last decade, first as an on-premises installation of Hadoop and now in the cloud, built on natural object storage.)
Snowflake: Data lake or Data Warehouse?
Data lakes offer low-cost object storage of raw data and rely on external query tools to analyze large datasets using highly available computing resources. Because they access a file system rather than a structured format, data lakes are not highly performant without optimization. But once optimized, they can be extremely cost-effective, especially at scale. They are also well equipped to process streaming data.
The Data warehouse stores structured data in a proprietary format for analytical access through a tightly coupled query layer. Computational speed is high compared to a non-optimized data lake but is also more expensive.
So, where does the Snowflake fit?
With other data warehouses, Snowflake requires a proper data format, works with structured and semi-structured (but not unstructured) data, and requires its query engine. However, it differs from a traditional data warehouse in two key aspects:
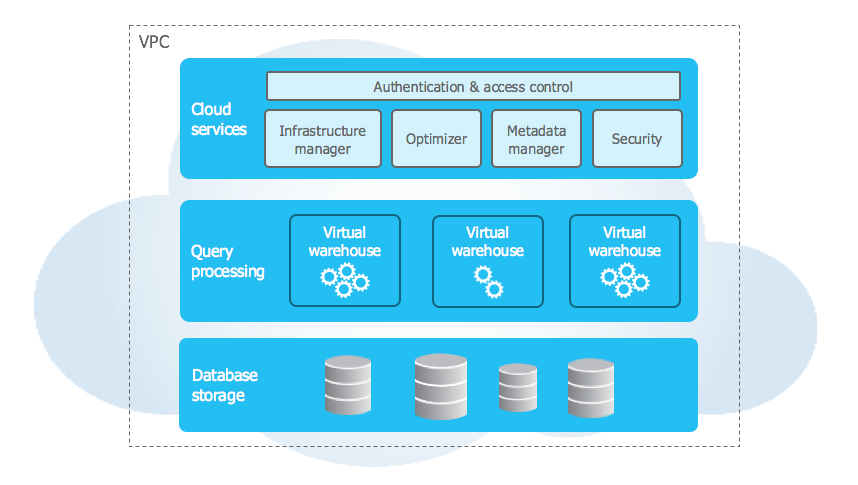
1. It is only offered in the cloud
2. It separates the storage from the elastic compute layer
These improvements initially differentiated Snowflake in the market from Teradata and Redshift. However, each has tried to match those attributes—Teradata with its Vantage cloud service and Amazon with Redshift, which separates compute and storage. As a result, these services now share these two properties with cloud data lakes, which can add to the flurry of confusion about when to use which.
Bottom Line: While Snowflake offers some separation of storage from computing, it cannot be considered a data lake due to its reliance on proprietary data formats and structured storage. A data lake is built on broad access to data and the ability to choose between different compute queries and data tools; despite all Snowflake’s advantages as a warehouse, it doesn’t offer some features.
Where to store the data for cost optimization?
So Snowflake is not a data lake. But is there any reason not to store all your information on it and rely on its ability to process data with SQL quickly? One reason you should consider it is the cost.
Of course, the cost is essential when deciding how to use different analytics platforms. Using Snowflake to run complex queries on large volumes of data at high speed can significantly increase costs.
- Snowflake charges based on how long the Virtual Data Warehouse (VDW) is running, plus VDW size (number of cores) and prepaid feature set (Enterprise, Standard, or Business-Critical). A given VDW, the rates are identical to the load on the VDW. This differs from the data lake, which offers spot pricing; a cheaper instance can handle a smaller bag.
- Snowflake processes data in its proprietary format, and data transformation for Snowflake acceptance can be costly. Because receiving data streams creates a continuous load, it can keep the Snowflake VDW meter running 24/7. Since Snowflake does not charge differently for a 5% or 80% load of a given virtual datastore size, these costs can be high.
• Computing snowflakes is more expensive than running the same job in a data lake.
So there is a real risk of Snowflake running into an inexorable cost scenario. When you realize that you may have too much data stored in Snowflake, it can become even more expensive to get the data out because it needs to be transformed into a different format.
A similar scenario could arise involving your data scientists, who may repeatedly analyze the same or similar data sets as they experiment with different models and test various hypotheses. This is highly computationally intensive. They must be able to connect to the ML or AI tools of their choice and not be locked into a single technology just because a proprietary data format requires it.
For these reasons, relying on Snowflake for all your data analysis needs can be inefficient and expensive. From a business perspective, it may be better to supplement Snowflake with a data lake.
Compare Snowflake and Databricks
There are a lot of people who are confused between snowflake and Databricks. How does the Snowflake approach compare to Databricks’ self-proclaimed Lakehouse tool, and how stark are the differences between the two? Check out our Databricks vs Snowflake comparison to find out.
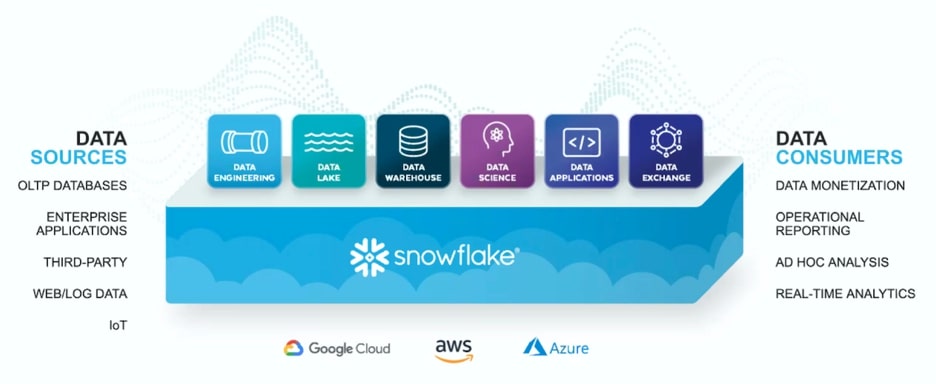
Snowflake + optimized cloud data lake = flexible and affordable analytics
None of the above is meant to disparage Snowflake or to suggest that it shouldn’t be part of your overall solution. Snowflake is a handy data warehouse and should be considered a way to provide predictable and fast analytics performance. However, by incorporating it as part of an open, optimized data lake architecture, you can ensure that you get all (or most) of Snowflake’s benefits while keeping your cloud costs under control.
Using an optimized data lake and cloud data warehouse like Snowflake allows companies to apply different patterns to different use cases based on cost and performance requirements.
- You can use cheap data lake storage and keep all your data – not just recent or structured data.
- Data transformation and preparation are likely much cheaper in a data lake than in Snowflake, especially for streaming data.
- You are not limited in choice of query tools and can query the data lake directly or send it to Snowflake as needed. With additional tools such as search engines, time series databases, or ML/AI tools, you retain maximum flexibility and agility to work with the rest of the data as you please.
Prepare your Data Lake for Analysis
Manually preparing data in a data lake using tools like AWS Glue or Apache Spark is usually resource-intensive. Here we will use Upsolver’s Data Lake engineering platform. Upsolver provides a low-code, self-service, optimized compute layer on top of your data lake, making it powerful to serve as a cost-effective repository for analytics services.
Upsolver includes data lake engineering best practices to make processing efficient, automating the essential but time-consuming data pipeline work that every data lake requires to function well. It includes:
- Converting data into columnar formats with efficient querying like Apache Parquet instead of requiring engines to query raw data.
- Continuous file compression ensures performance by avoiding the “small file problem.”
- Appropriate data partitioning to speed up query response.
Upsolver uses low-cost compute options such as AWS Spot EC2 instances whenever possible to reduce query costs. This can reduce calculation costs by 10X compared to standard EC2, which is much cheaper than a data warehouse.
Upsolver handles UPSERTS tables correctly, meaning you can continuously load tables from streaming data that stay current as the data and even the schema change.
Use Upsolver to normalize, filter, aggregate, and join data to your liking through a visual SQL IDE to create transformations. Then run these transformations directly in the data lake before writing them to Snowflake (including joins, aggregations, enrichments, etc.) or querying them as an external table from Snowflake’s SQL query engine.
Combining Snowflake with Upsolver’s data-rich data lake gives you the flexibility to run processing where it makes the most sense in terms of cost and choice of analytics tools.
You can even use Upsolver to continuously transform and stream data directly to Snowflake.
How to build a real-time streaming architecture using Snowflake, Data Lake Storage, and Upsolver on AWS?
First, and most importantly, be clear about which of your data streams must go to Snowflake and which can be stored in raw format in a lake for other purposes. (Remember not to keep ancient data on Snowflake; Athena is a much better tool for querying large datasets.) Then design the architecture so that the transformed streaming data is automatically sent to Snowflake.
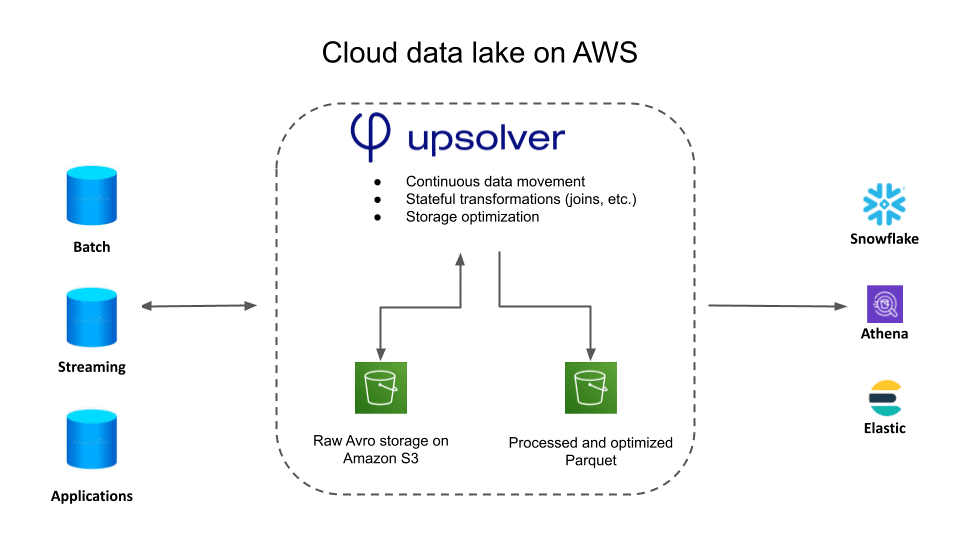
In this reference architecture, Snowflake is only one of several data consumers. Data is optimized (sometimes significantly) for each consumer. In some cases, prepared data is most economically queried on a data lake with a query tool such as Athena; in others, the output is to a specialized data store:
• search analysis or logging (Elasticsearch)
• OLAP (Snowflake) querying
• chart analysis (Neptune)
With an open data lake architecture like this, you keep a single version of the truth in the data lake as raw data, plus you can refine and distribute the data for specific purposes.
1. Upsolver receives data streams and stores them in raw format in a data lake.
2. Data intended for OLAP or ad hoc queries are prepared, cleaned, aggregated, and formatted for direct question by Athena and output to Snowflake for processing and processing.
3. As requests come in from other analytics services, the data is prepared and then delivered to the service.
Conclusion
Snowflake is a new kind of data warehouse. It offers advantages over traditional approaches through a consumption-based pricing model and separation of storage and computing. However, it is not the best tool for every task, especially regarding costs, such as running continuous errands on streaming data. It is also a closed system, which reduces the long-term flexibility of the analysis.
Data lakes are open, more scalable, cost-effective, and can support a broader range of business cases. Now, you can use a codeless data lake engineering platform to create a pipeline to receive, prepare quickly, and format unlimited amounts of streaming data. You can then directly query or send to Snowflake—the best of both worlds.
- The Data warehouse stores structured data in a proprietary format for analytical access through a tightly coupled query layer. Computational speed is high compared to a non-optimized data lake but is also more expensive.
- Snowflake offers some separation of storage from computing. It cannot be considered a data lake due to its reliance on proprietary data formats and structured storage. A data lake is built on broad access to data and the ability to choose between different compute queries and data tools;
- Snowflake charges based on how long the Virtual Data Warehouse (VDW) is running, plus VDW size (number of cores) and prepaid feature set (Enterprise, Standard, or Business-Critical). A given VDW, the rates are identical to the load on the VDW.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





