This article was published as a part of the Data Science Blogathon.
Introduction
DevOps practices include continuous integration and deployment, which are CI/CD. MLOps talks about CI/CD and ongoing training, which is why DevOps practices aren’t enough to produce machine learning applications. In this article, I explained the important features of MLOps and the key differences from traditional DevOps practices.
.png)
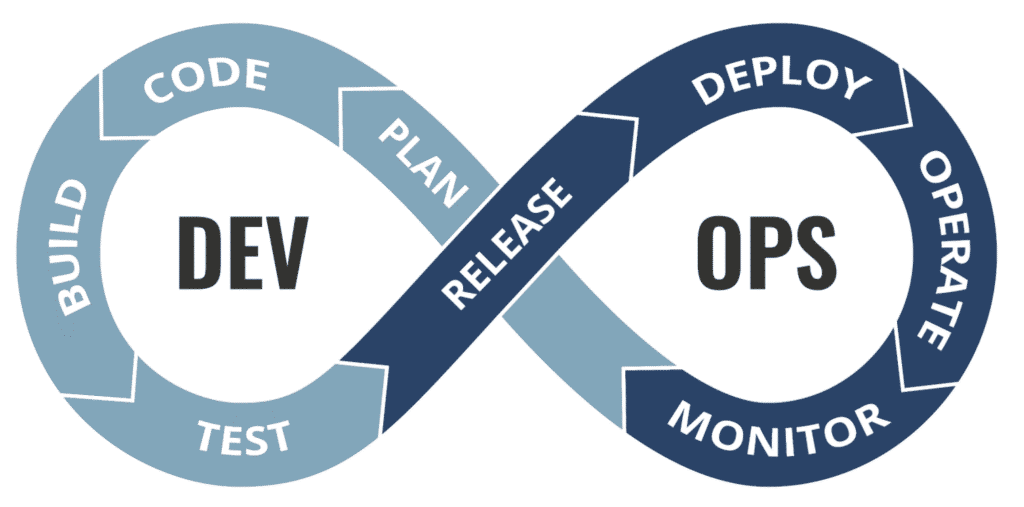
DevOps – Development and Operations
Today’s competitive world is about how quickly you make your features available to the end user. DevOps helps the project team quickly integrate new features and make them available to end users using an automated DevOps pipeline.
DevOps uses two key components throughout its lifecycle:
1. Continuous Integration: Merging the code base into a central code repository such as git and bitbucket, automating the software system build process with Jenkins, and running automated test cases.
2. Continuous Delivery: Once new features are developed, tested, and integrated into the continuous integration phase, they must be automatically deployed to make them available to end users. This automated build and deployment are done in the developer’s continuous delivery phase.
When a project is deployed, and users start using it, it’s important to track various metrics. Under DevOps monitoring, an engineer takes care of several things like application monitoring, usage monitoring, visualization of key metrics, etc.
Machine Learning Vs. Traditional Software Development
According to the paper “Hidden Technical Debt in Machine Learning Systems,” Only a fraction of a real ML system consists of ML code. Along with the ML code, we need to consider data cleaning, data versioning, model versioning, and continuous training of models on a new data set. Machine learning system testing is different from the traditional software testing mechanism. Testing a Machine Learning application is more than just unit testing. We must consider data checks and data drift, model drift, and performance evaluation of the model deployed to production.
• Machine learning systems are highly experimental. You can’t guarantee that an algorithm will work in advance without doing some experiments first. Therefore, there is a need to track various experiments, feature engineering steps, model parameters, metrics, etc., to know which experimental algorithm the optimal results are achieved in the future.
• The deployment of machine learning models is particular, depending on the problem they are trying to solve. Most parts of the machine learning process involve things related to data. And therefore, the machine learning pipeline has several steps, including data processing, feature engineering, model training, model registry, and model deployment.
• Model output should be consistent over time. Therefore, we need to track data distribution and other statistical measurements related to data over a period. The live data should be similar to the data used to train the model.
• People who develop machine learning models do not focus on software practices because they often do not come from a software background.
MLOps – Operations in Machine Learning
MLOps or ML Ops is a set of practices that aim to reliably and efficiently deploy and maintain machine learning models in production. The word is a portmanteau of “machine learning” and the continuous development of DevOps in software.
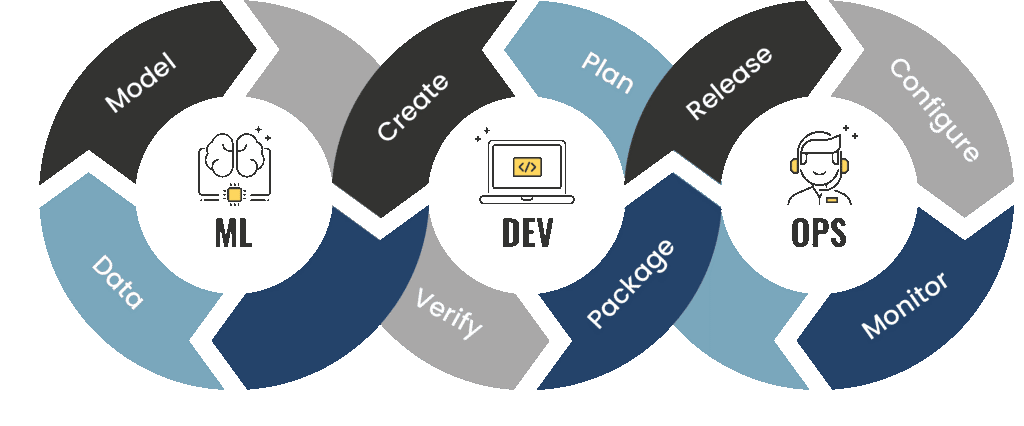
MLS is a combination of DevOps, machine learning, and data engineering. Building on the existing DevOps approach, MLOps solutions are developed to increase reusability, facilitate automation, data shift management, model versioning, experiment tracking, ongoing training, and obtain richer and more consistent insights in a machine learning project.
Andrew Ng recently talked about how the machine learning community can use MLOps to build high-quality datasets and AI systems that are repeatable and systematic. He called for a shift in focus from model-centric machine learning to data-centric development. Andrew also said that going forward, MLOps can play an important role in ensuring high-quality and consistent data flow at all project stages.
This MLOps setup includes the following components:
• Source control
• Test and build services
• Deployment services
• Register models
• Store features
• ML metadata repository
• ML pipeline orchestrator
A more detailed architecture, including an automated pipeline for ongoing training is provided below:
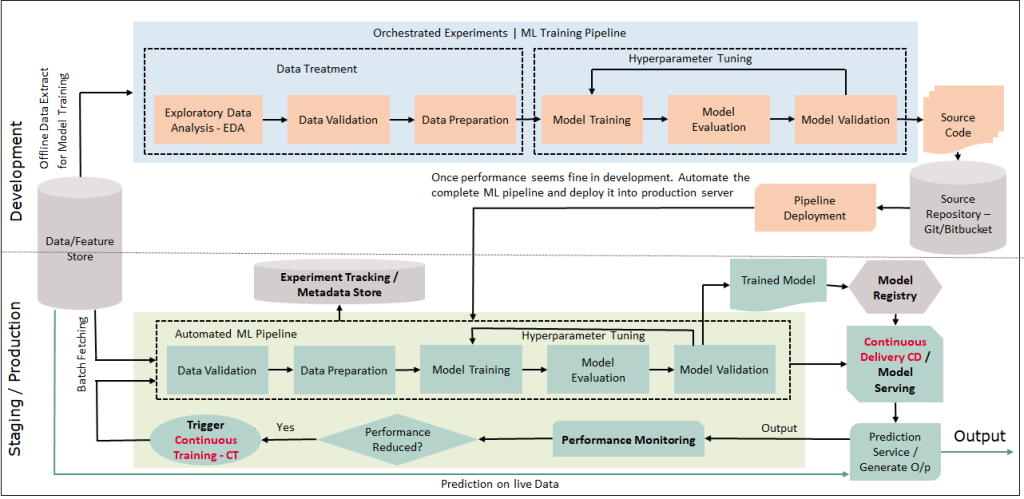
Key Benefits of Using MLOps
• Continuous training: With MLOps, we can set up continuous training of models. Continuous training is essential, as with changes in time data, and it also affects the model’s output. Therefore, for the model output to be consistent, it is necessary to have continuous training with new incoming data.
• Watching experiments: When we develop a machine learning model, we run many experiments, such as hyperparameter tuning, different sampling of training data, and different model outputs concerning different parameters. So after many experiments, we get the best output model. But we don’t know which experiment gives the optimal result because we didn’t save those experiments. And now, when we return a few weeks later, we have to run everything again to get the optimal result. Here experiment tracking helps us to record small configuration experiments automatically.
• Data Drift: When an ML model is first deployed in production, data scientists are primarily concerned with how well the model will perform over time. The main question they ask is, does the model still capture the pattern of new incoming data as effectively as it did during the design phase? So if the data changes over time, the model’s performance will decrease because it is trained on data that is not the same as the new incoming data in statistical measures. And this change in the data is known as data drift, which directly affects the model’s performance and therefore needs to be watched out for. There are several statistical techniques to check data drift, such as the Kolmogorov-Smirnov test, but in MLOps they provide some ready-made tools that you can use for this purpose. Example: Hydrosphere and Fiddler
• Model registry: With a model registry, you can ensure that all key values (including data, configurations, environment variables, model code, versions, and documents) are in one place that everyone responsible can access. It helps in model versioning and faster deployment. Tools that support model registry out of the box like MLFlow, Azure Machine Learning Studio, Neptune AI, etc.
• Visualization: When you plot data, it is much more understandable than presented in table numbers. This is where visualization of various machine learning metrics, performance scores, and experiments becomes essential. You can do all of these (or most of them) yourself, but there are tools you can use to help speed up your machine learning development.
• Monitoring: You collect statistical data on model performance based on current data. The output of this phase is a trigger to execute a pipeline or a new experimental cycle. It helps start a continuous training channel. In addition, there could be many more things to monitor, like usage statistics, performance monitoring, application, system-level logging, etc. Various monitoring tools are available, such as Prometheus, open telemetry, etc.
Similarities of MLOps and DevOps
1. The two main components of DevOps, Continuous Integration and Continuous Delivery, are also needed in MLOps.
2. ML code testing is the same as in DevOps. Because it will be python code where DevOps testing methodologies can be applied. [There is also model testing and data validation testing that is new to MLOps]
What is different in MLOps compared to DevOps?
1. Data quality and drift: In MLOps, in addition to code testing, you also need to ensure that data quality is maintained throughout the lifecycle of a machine learning project. Make sure the data doesn’t change over time. Otherwise, the model needs to be retrained.
2. More than traditional deployment: In MLOps, you don’t necessarily deploy only the model artefact. You may need to deploy a complete machine-learning pipeline that includes data extraction, data processing, feature engineering, model training, model registry, and model deployment.
3. Continuous Training: There is a third concept in MLOps that does not exist in DevOps: continuous training (CT). We have to check for data drift and concept drift constantly; whenever there is a change, it will affect the model’s performance. So if the model’s performance decreases over time, we need to start the training pipeline automatically.
4. Model testing: A fraction of a real ML system consists of ML code. The surrounding elements required are extensive and complex. We need to consider data checks and data movement, model movement, testing, and performance validation of the model deployed to production.
5. Versioning of data and models: In DevOps, we consider versioning of code, but in machine learning, we deal with different samples of data and create different versions while training the model. We also generate different versions of the models concerning different hyperparameters. So, in MLOps, you must version both the data, the model, and the code.
Conclusion
In recent years, there have been drastic changes in the speed of data generation. Almost 90 per cent of the data available today comes from just the last few years. If you are reading this post, I assume it would be abundantly clear that while big data helps develop actionable insights, it also presents several challenges. These challenges include acquiring and cleaning big data, tracking and versioning for models, deploying monitoring pipelines for production, scaling machine learning operations, etc. That’s where MLOps can help the Machine Learning community tackle all the problems that can’t be solved with DevOps alone.
- Machine learning system testing is different from the traditional software testing mechanism. Testing a Machine Learning application is more than just unit testing. We must consider data checks and data drift, model drift, and performance evaluation of the model deployed to production.
- In MLOps, in addition to code testing, you also need to ensure that data quality is maintained throughout the lifecycle of a machine learning project. Ensure the data doesn’t change over time; otherwise, the model must be retrained.
- ML model is first deployed in production; data scientists are primarily concerned with how well the model will perform over time. The main question they ask is, does the model still capture the pattern of new incoming data as effectively as it did during the design phase?
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a Machine Learning Enthusiast. Done some Industry level projects on Data Science and Machine Learning. Have Certifications in Python and ML from trusted sources like data camp and Skills vertex. My Goal in life is to perceive a career in Data Industry.





